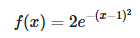完结撒花!记录一下 Bustub Concurrency Control 的实现过程。
Resources
- https://15445.courses.cs.cmu.edu/fall2022 课程官网
- https://github.com/cmu-db/bustub Bustub Github Repo
- https://www.gradescope.com/ 自动测评网站 GradeScope,course entry code: PXWVR5
- https://discord.gg/YF7dMCg Discord 论坛,课程交流用
- bilibili 有搬运的课程视频,自寻。
请不要将实现代码公开,尊重 Andy 和 TAs 的劳动成果!
Overview
Project 4 是 15-445 2022Fall 的最后一个部分了,在这里我们将为 Bustub 实现关系数据库中极其重要的 transaction 概念。
- Lock Manager:锁管理器,利用 2PL 实现并发控制。支持
REPEATABLE_READ、READ_COMMITTED和READ_UNCOMMITTED三种隔离级别,支持SHARED、EXCLUSIVE、INTENTION_SHARED、INTENTION_EXCLUSIVE和SHARED_INTENTION_EXCLUSIVE五种锁,支持 table 和 row 两种锁粒度,支持锁升级。Project 4 重点部分。 - Deadlock Detection:死锁检测,运行在一个 background 线程,每间隔一定时间检测当前是否出现死锁,并挑选合适的事务将其 abort 以解开死锁。
- Concurrent Query Execution:修改之前实现的
SeqScan、Insert和Delete算子,加上适当的锁以实现并发的查询。
4.1 Lock Manager
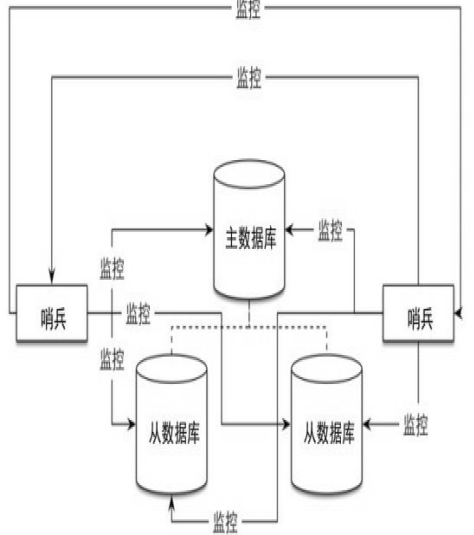
为了保证事务操作的正确交错执行,DBMS使用锁管理器Lock Manager来控制何时允许事务访问数据项。LM(Lock Manager) 的基本思想是,维护一个关于活动事务当前持有的锁的内部数据结构,然后事务在访问数据项之前向LM发出锁请求,并记录,当其他事务访问相同数据时,根据隔离级别决定是否允许。
Bustub要求实现一个表级和元组级的LM,支持三个常见的隔离级别:READ_UNCOMMITED、READ_COMMITTED和READ_COMMITTED,相关的知识在这里不再赘述,可以自行了解。说回到Task 1,这里的LM可以视为一个独立的模块,并不与其他的模块有较多的联系。可以先看 lock_manager.h 文件,把这里的所有数据结构以及注释都梳理一遍:
首先是锁类型,总共有五种:
enum class LockMode { SHARED, EXCLUSIVE, INTENTION_SHARED, INTENTION_EXCLUSIVE, SHARED_INTENTION_EXCLUSIVE };
各自的含义也不难理解,不清楚的可以参考讲义,值得注意的是,这里SIX锁是S+IX锁。然后是锁记录结构 LockRequest,相关成员有
txn_id_:申请锁的事务id;lock_mode_:申请的锁的类型;oid_:申请访问数据的table id;rid_:仅在 row 粒度锁请求中有效,指 tuple (row) 对应的 rid;granted_:该锁是否被授予;
所有的锁记录都存放在 LockRequestQueue 锁请求队列中,它的相关成员有:
request_queue_:存放锁记录的队列,为了Modern的效果,这里我修改了原始定义,使用智能指针shared_ptr,也就是std::list<std::shared_ptr<LockRequest>>类型;cv_:条件变量;upgrading_:正在该资源上尝试锁升级的事务 id;latch_:锁;
所有的表锁记录用 table_lock_map_ 保存,行锁记录用 row_lock_map_ 保存;当调用 LockTable 的时候,会往 table_lock_map_ 中插入记录,相反则删除。
4.1.1 LockTable
下面直接分析对表加锁的步骤:
1. 检查事务的状态以及支持的隔离级别
首先,如果事务处于Abort/Commit状态,则可以直接返回,因为这种状态下不可能加锁;
然后根据2PL在不同隔离级别的实现,检查事务的隔离级别和当前锁的请求类型是否兼容,在代码注释和讲义中都是有提到的:
/*
* REPEATABLE_READ:
* The transaction is required to take all locks.
* All locks are allowed in the GROWING state
* No locks are allowed in the SHRINKING state
*
* READ_COMMITTED:
* The transaction is required to take all locks.
* All locks are allowed in the GROWING state
* Only IS, S locks are allowed in the SHRINKING state
*
* READ_UNCOMMITTED:
* The transaction is required to take only IX, X locks.
* X, IX locks are allowed in the GROWING state.
* S, IS, SIX locks are never allowed
*/
稍微简化一下描述:
- 如果事务是读未提交,若锁不是X/IX类型,抛
LOCK_SHARED_ON_READ_UNCOMMITTED异常; - 如果当前事务处于SHRINKING状态,除非是读提交隔离级别 + 申请S/IS锁,否则都抛
LOCK_ON_SHRINKING异常;
2. 获取table id对应的锁记录队列
从 table_lock_map_ 中获取 table id对应的锁记录队列 lock request queue;注意需要对该操作加锁,并且在获取完队列后及时释放锁。
此外,如果不存在对应的锁记录队列,那么就创建,同时也创建 LockRequest 类型的数据,granted_ 标记为true,然后创建 LockRequestQueue,并把锁申请记录添加到该队列,同时将锁记录队列emplace到 ``table_lock_map_ 中,直接返回。
3. 检查是否存在锁升级
从第二步获取到的lock queue中拿到request_queue,遍历查看是否存在和当前事务id相等的申请记录;如果存在,说明有可能会发生锁升级,进行下一步判断。
需要注意一点,在request_queue中的和当前事务id相等的申请记录,它肯定是被授予锁的;因为如果没有被授予锁,那么会阻塞在当前函数(不能返回),那么就不可能再次申请锁 (也就是此刻状态)。
- 如果该授予的锁类型和当前申请的锁类型相同,那么直接返回true;
- 如果有其他事务也在升级锁,即
upgrading_ != INVALID_TXN_ID,那么抛异常,因为不允许多个事务在同一资源上升级锁 (至于这样的原因,个人认为是,如果存在多个事务同时升级锁,那么要把锁分配给哪个事务呢?这一点并不好决择,如果按照申请的先后顺序升级,不失为一种方案,且需要主动阻塞当前线程,但是在本项目中并不需要考虑); - 检查申请的锁是否兼容已持有的锁,检查的方法在注释中也有提到IS -> [S, X, IX, SIX]、S -> [X, SIX]、IX -> [X, SIX]、SIX -> [X];如果不兼容,抛异常。
- 更新
upgrading_,释放当前事务持有的该锁,删除该授予锁的记录,更改锁类型,并把该记录添加到最高级别, 即插入到第一个未授予锁的请求的前面;
如果不存在锁的升级,那么就是一个普通的加锁请求,直接构造锁申请记录,并加到request_queue后面。
4. 阻塞直至获取锁
现在锁申请记录已经添加到队列request_queue中,但是有可能该表锁被其他事务占用着,需要排队等待。
首先C++中线程阻塞等待的写法是这样的:
lock_queue->cv_.wait(queue_lock, [&]() { return GrantLock(txn, lock_mode, lock_queue, target); });
可以视为一种语法糖,wait的第二个参数是谓词,如果该函数结果返回true结束阻塞并向下执行,否则一直阻塞在此处 (C++11的内容,比较简单不多描述)。那么我们需要在这里传入一个函数,用来判断当前是否可以授予申请的锁。
判断的方法也不复杂,遍历当前锁申请记录前面的所有记录,查看它们的锁是否兼容(稍后解释);
如何判断锁的兼容(注意这和锁升级时候的兼容不一样,锁升级时的兼容代表升级后的锁包含升级前的锁,但是这里的兼容代表,不同的事务之间,锁是否可以共用,最简单的例子读读兼容,读写排斥)?在讲义中也有说到,请看下图:
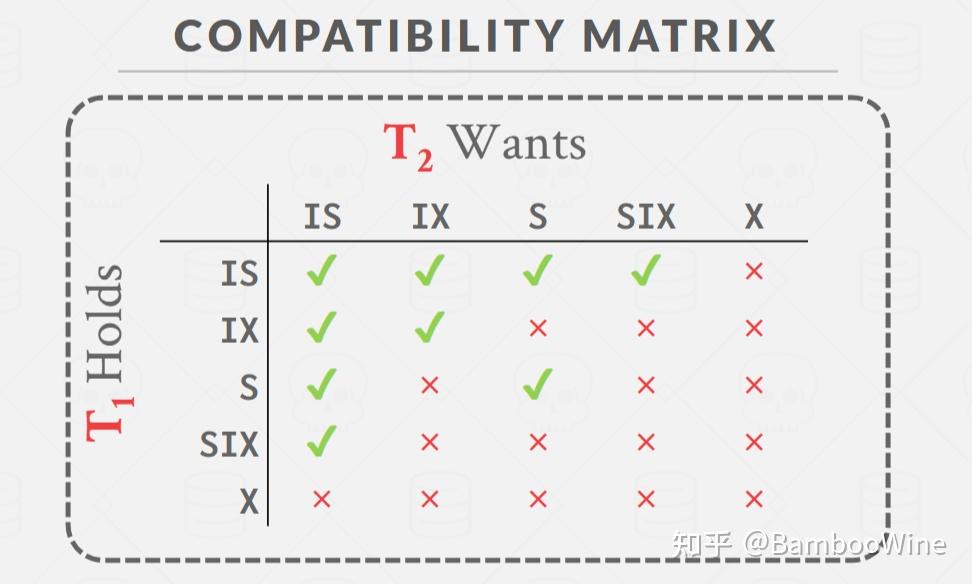
只需要把这张图翻译一下即可。
然后解释一下,我们是遍历当前锁申请记录前面的所有记录,查看它们的锁是否兼容。
首先“判断已授予的锁和当前申请的锁是否兼容”这一点肯定是没问题;
但是我们还会“判断排在前面的且未授予的锁是否也兼容”,关于这一点的解释,也很好说明。因为不同事务不是同时被唤醒的,如果锁记录排在后面的事务先被唤醒(假设排它前面的锁都可以被授予,且和它也兼容),那么我们也应该授予当前事务申请的锁。这仅仅是因为不同的唤醒顺序。
下一步就是 granted_ 标记为true,锁记录push到该事务的锁记录集合中;如果发生锁升级,那么还需要将 upgrading_ 重新设置。
4.1.2 UnlockTable
和LockTable相比,解锁的步骤要简单得多。
1. 检查表中是否还存在行锁
在释放表锁时,要先检查是否该表不存在行锁,如果存在,抛异常。
2. 检查是否存在表锁
如果该表本就没有加锁,那么抛异常。
3. 检查该事务是否存在该表锁
根据table id拿到锁记录队列request_queue,遍历,是否存在事务id等于当前id且已授予锁的记录;
如果不存在,抛异常 ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD;
特别注意,释放锁可能引起事务状态的改变;在注释中也有关于状态改变的描述,代码翻译一下即可:
/*
* TRANSACTION STATE UPDATE
* Unlock should update the transaction state appropriately (depending upon the ISOLATION LEVEL)
* Only unlocking S or X locks changes transaction state.
*
* REPEATABLE_READ:
* Unlocking S/X locks should set the transaction state to SHRINKING
*
* READ_COMMITTED:
* Unlocking X locks should set the transaction state to SHRINKING.
* Unlocking S locks does not affect transaction state.
*
* READ_UNCOMMITTED:
* Unlocking X locks should set the transaction state to SHRINKING.
* S locks are not permitted under READ_UNCOMMITTED.
* The behaviour upon unlocking an S lock under this isolation level is undefined.
*/
同时,可以结合讲义,对2PL和事务隔离级别有更深的理解。
然后就是需要从request_queue删除锁记录,同时事务的锁记录集合也要删除;最后,在释放锁之后,调用2 lock_queue->cv_.notify_all() 唤醒阻塞在该锁上的其他事务。
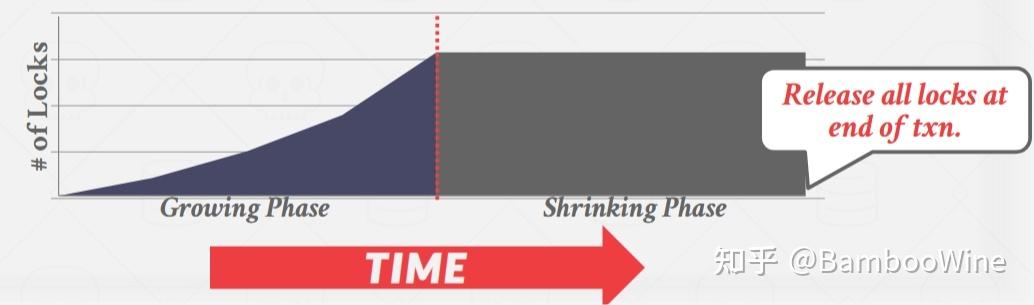
解锁的步骤分析完毕,不过还是想再解读一下2PL。首先两阶段锁(2PL)是一种并发控制协议,用于确定事务是否可以在运行时访问数据库中的对象。
- 阶段1:Growing,每一个事务都可以申请锁,锁管理器LM决定授予或者拒绝该请求;
- 阶段2:Shrinking,事务仅仅允许释放或者降级锁(已申请的),不能申请新的锁。

2PL本身足以保证冲突的可串行性,因为它生成的调度的优先级时非循环的。但是它有可能导致级联中止,举一个简单的例子,看下图:

对于这样的事务,T2穿插着T1执行,如果此时事务T1 abort,需要撤回已修改的数据,那么事务T2也需要被 abort,因为它也修改了记录A。
此外2PL有可能引起“脏读”现象,而解决方案是:强严格2PL(Strong Strict 2PL),它的含义是事务仅仅能在Commit或者Abort之后,才被允许释放锁,同时也可以避免级联中止的问题(因为其他事务申请不到该事务已拥有的锁)。
然后再结合不同的隔离级别进一步分析:
- 读未提交:不加读锁,只加写锁X/IX;由于不加读锁,所以可以读到其他事务未提交的数据;
- 读提交:在Growing阶段可以申请任意锁,在Shrinking阶段只能申请IS/S锁,所以只能读到其他事务提交了的数据(写锁最后才释放);释放X锁会引起事务状态的改变,但是S锁不会;
- 可重复读:在Growing阶段可以申请任意锁,在Shrinking阶段不允许获取锁,也就是在事务开始前获取全部锁,最后才释放,因此可重复读,别的事务修改不了;释放任何锁(包括读锁)都会改变事务状态;
4.1.3 LockRow & UnlockRow
对行数据加锁和解锁,步骤与表锁并没有太大的区别。
先说LockRow,在 检查事务的状态以及支持的隔离级别后,还需要检查当前事务是否持有该表的锁。说到这里,还想谈一谈本Project并发控制的方式,将一把大锁,分解为不同层次的锁,从而提高系统吞吐量:
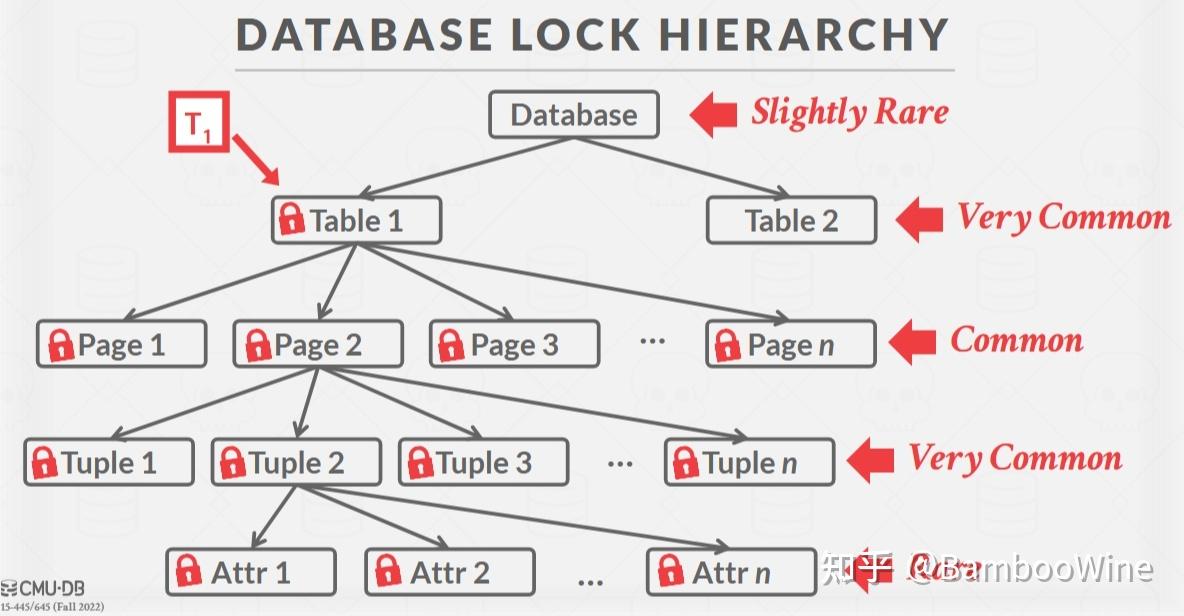
- 如果想获取一个节点的S/IS锁,那么这个事务必须至少持有父节点的IS锁;
- 如果想获取一个节点的X/IX/SIX锁,那么这个事务必须至少持有父节点的IX锁;
由于在给Row加锁时,只会加S/X锁,那么当申请S锁时,该表至少需要持有IS锁;否则至少需要IX锁。如果不存在这样的锁,那么就抛出异常 TABLE_LOCK_NOT_PRESENT。
此外也要注意,行锁的升级,只可能存在S锁到X锁升级的情况。UnlockRow和表锁的unlock步骤几乎一样。
4.2 Deadlock Detection
这种加锁方式,很可能会造成多个事务的循环等待,引发死锁,死锁的形成条件可以思考一下。在Project中,开启一个线程,不断检测是否存在死锁。在lock_manager.h文件中,有这样的数据结构 waits_for_,本质是一个哈希表,t1->t2代表事务t1正在等待t2释放锁(这里的写法和讲义有些差别,影响不大)。
首先 AddEdge、RemoveEdge、GetEdgeList 函数都是非常简单的,记得加锁即可。
然后是 HasCycle函数,根据waits_for_有向图,查看其是否存在环,并且返回环中最新的事务id。在算法学习中,判断一个有向图是否有环的方法,可以用DFS或者拓扑排序。拓扑排序判断一个图是否有环确实比较方便,但是个人认为,对于找到图中所有的环,采用DFS更加方便。
不过,我个人感觉Project这里并没有说太清楚;经过测试,似乎是这样的,对于每一个环,找到最大的事务id,记为mx_id;然后从所有的环中,找到最小的mx_id
考虑一些同学可能没太学过算法,这里简单讲一下DFS的做法:
- 定义一个哈希表,代表每个图中每个节点的访问标志;-1代表还未访问,1代表正在访问中,2代表访问已经结束;
- 在DFS函数中,先将当前所处的节点标志置1,然后访问邻居节点;如果邻居的标志为-1,递归访问;如果标志为1,代表发生了循环;为了找到环,还需要定义一个path数组,保存访问的路径,在每次迭代的时候push每一个节点到该数组中。然后发生循环时,从path数组中找到环(首位节点相同),并保存最大的id;访问完所有的邻居后,可以将当前节点标志置为2,代表访问结束。
- 对图中每一个节点,都调用一次DFS函数,从所有环的id(就是之前保存的最大id)中找最小的id,并返回。
接下来是 RunCycleDetection 函数:
- 首先需要构建
waits_for_图,具体的方法是,遍历table_lock_map和row_lock_map中所有的请求队列,找到所有的等待关系(即未授予锁的事务等待已授予锁的事务释放资源,可以采用两重循环),并添加到waits_for_中。 - 下一步环检测,如果存在环,找到最年轻的事务id,
youngest_id,可以用事务管理器提供的静态方法找到具体事务对象,即TransactionManager::GetTransaction;将此事务设置为Abort,并从所有的锁请求队列中,删除有关该事务的记录,同时删除该事务拥有的锁(事务本身的锁集合);接着调用相应的请求队列的cv.notify_all唤醒所有等待的事务。 - 此外,还有一点需要强调,在Task 1中我们实现了锁的阻塞等待,查看是否可以授予当前事务锁,也就是
GrantLock函数;但是在添加了死锁检测后,会主动将某事务设置为Abort,当事务被唤醒并且往下执行时,如果发现当前事务为Abort,那么仍然需要从请求队列中删除该事务相关的记录,并且notify_all唤醒其他事务。其实我个人感觉这里的实现可能有些问题,至少写出来挺丑陋的,大家可以实当参考。
4.3 Concurrent Query Execution
Task 3是要将实现的并发控制应用在实际的Query查询执行中,只涉及 SeqScan 、Insert 和 Delete 三种算子。
首先是 SeqScan 算子,需要根据不同的隔离级别不同考虑:
- 读未提交,不需要加锁;
- 读提交,先加意向表锁IS,再加行锁S;在
Next函数中,如果已经遍历完了所有数据,那么需要释放全部的锁; - 可重复读,先加意向表锁IS,再加行锁S,不释放锁(因为释放S锁会进入Shrinking状态);
值得分析的是,这里加表锁IS还是S锁,肯定都是符合逻辑的;但是似乎只有先加IS,才可以顺利通过测试,对此不用在意,这或许是刻意为之(例如先delete操作加IX锁, 再seqscan加S锁,但是锁并不兼容,导致seqscan阻塞,但是这并不意味着错误,只是在这个Project中测试不过)。一定要知道,这毕竟只是学习的Demo,以通过测试为主,太细节的地方不要深揪,不然这个Bustub并没有真正实现刷盘也得钻牛角尖么?
然后是 Insert 算子:
- 先给表加IX锁,再在
Next中为行加X锁;无论哪一种隔离级别,不需要释放锁,因为释放X锁会引起事务状态的改变; - 此外我们需要保存修改tuple的历史,其中
InsertTuple已经实现了 write set的push,但是Insert算子还有可能引起index的改变,所以也有必要对IndexWriteSet也进行维护。
Delete 算子和 Insert 算子几乎完全一样。