t_warmup, _ = timed(lambda:model(**inputs), n_warmup, dtype)
t_test, output = timed(lambda:model(**inputs), n_test, dtype)
print(f"平均推理时间ViT(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间ViT(test): dt_test={t_test} ms")
inference_time.append(t_test)
mode.append("eager")
# 该模型预测了1000个ImageNet类中的一个
predicted_class_idx = output.logits.argmax(-1).item()
print("预测类:", model.config.id2label[predicted_class_idx])
输出:
平均推理时间ViT(warmup): dt_test=8.17105770111084 ms
平均推理时间ViT(test): dt_test=7.561385631561279 ms
预测类: 埃及猫
评估视觉Transformer模型在 torch.compile(default) 模式下的性能
torch._dynamo.reset()
model_opt1 = torch.compile(model, fullgraph=True)
t_compilation, _ = timed(lambda:model_opt1(**inputs), 1, dtype)
t_warmup, _ = timed(lambda:model_opt1(**inputs), n_warmup, dtype)
t_test, output = timed(lambda:model_opt1(**inputs), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"平均推理时间ViT(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间ViT(test): dt_test={t_test} ms")
inference_time.append(t_test)
mode.append("default")
# 该模型预测了1000个ImageNet类中的一个
predicted_class_idx = output.logits.argmax(-1).item()
print("预测类:", model.config.id2label[predicted_class_idx])
输出:
编译时间: dt_compilation=13211.912631988525 ms
平均推理时间ViT(warmup): dt_test=7.065939903259277 ms
平均推理时间ViT(test): dt_test=7.033288478851318 ms
预测类: 埃及猫
评估视觉Transformer模型在 torch.compile(reduce-overhead) 模式下的性能
torch._dynamo.reset()
model_opt2 = torch.compile(model, mode="reduce-overhead", fullgraph=True)
t_compilation, _ = timed(lambda:model_opt2(**inputs), 1, dtype)
t_warmup, _ = timed(lambda:model_opt2(**inputs), n_warmup, dtype)
t_test, output = timed(lambda:model_opt2(**inputs), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"平均推理时间ViT(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间ViT(test): dt_test={t_test} ms")
inference_time.append(t_test)
mode.append("reduce-overhead")
# 该模型预测了1000个ImageNet类中的一个
predicted_class_idx = output.logits.argmax(-1).item()
print("预测类:", model.config.id2label[predicted_class_idx])
输出:
编译时间: dt_compilation=10051.868438720703 ms
平均推理时间ViT(warmup): dt_test=30.241727828979492 ms
平均推理时间ViT(test): dt_test=3.2375097274780273 ms
预测类: 埃及猫
评估视觉Transformer模型在 torch.compile(最大自动调谐) 模式下的性能
torch._dynamo.reset()
model_opt3 = torch.compile(model, mode="最大自动调谐", fullgraph=True)
t_compilation, _ = timed(lambda:model_opt3(**inputs), 1, dtype)
t_warmup, _ = timed(lambda:model_opt3(**inputs), n_warmup, dtype)
t_test, output = timed(lambda:model_opt3(**inputs), n_test, dtype)
print(f"编译时间: dt_compilation={t_compilation} ms")
print(f"平均推理时间ViT(warmup): dt_test={t_warmup} ms")
print(f"平均推理时间ViT(test): dt_test={t_test} ms")
inference_time.append(t_test)
mode.append("最大自动调谐")
# 该模型预测了1000个ImageNet类中的一个
predicted_class_idx = output.logits.argmax(-1).item()
print("预测类:", model.config.id2label[predicted_class_idx])
输出:
AUTOTUNE convolution(1x3x224x224, 768x3x16x16)
convolution 0.0995 ms 100.0%
triton_convolution_2191 0.2939 ms 33.9%
triton_convolution_2190 0.3046 ms 32.7%
triton_convolution_2194 0.3840 ms 25.9%
triton_convolution_2195 0.4038 ms 24.6%
triton_convolution_2188 0.4170 ms 23.9%
...
AUTOTUNE addmm(197x768, 197x768, 768x768)
bias_addmm 0.0278 ms 100.0%
addmm 0.0278 ms 100.0%
triton_mm_2213 0.0363 ms 76.7%
triton_mm_2212 0.0392 ms 71.0%
triton_mm_2207 0.0438 ms 63.5%
triton_mm_2209 0.0450 ms 61.9%
triton_mm_2206 0.0478 ms 58.2%
triton_mm_2197 0.0514 ms 54.2%
triton_mm_2208 0.0533 ms 52.3%
triton_mm_2196 0.0538 ms 51.8%
...
AUTOTUNE addmm(1x1000, 1x768, 768x1000)
bias_addmm 0.0229 ms 100.0%
addmm 0.0229 ms 100.0%
triton_mm_4268 0.0338 ms 67.8%
triton_mm_4269 0.0338 ms 67.8%
triton_mm_4266 0.0382 ms 59.8%
triton_mm_4267 0.0382 ms 59.8%
triton_mm_4272 0.0413 ms 55.4%
triton_mm_4273 0.0413 ms 55.4%
triton_mm_4260 0.0466 ms 49.1%
triton_mm_4261 0.0466 ms 49.1%
SingleProcess自动调谐需要8.9279秒。
编译时间: dt_compilation=103891.38770103455 ms
平均推理时间ViT(warmup): dt_test=31.742525100708004 ms
平均推理时间ViT(test): dt_test=3.2366156578063965 ms
预测类: 埃及猫
比较在上述四种模式下获得的 ViT 推理时间。
# 绘制条形图
plt.bar(mode, inference_time)
print(inference_time)
print(mode)
# 添加标签和标题
plt.xlabel('mode')
plt.ylabel('推理时间 (ms)')
plt.title('ViT')
# 显示绘图
plt.show()
输出:
[7.561385631561279, 7.033288478851318, 3.2375097274780273, 3.2366156578063965]
['eager', 'default', 'reduce-overhead', '最大自动调谐']
torch.compile 显著提升了 ViT 的性能,在 AMD MI210 上通过 ROCm 提升了超过 2.3 倍,如图5-3所示。
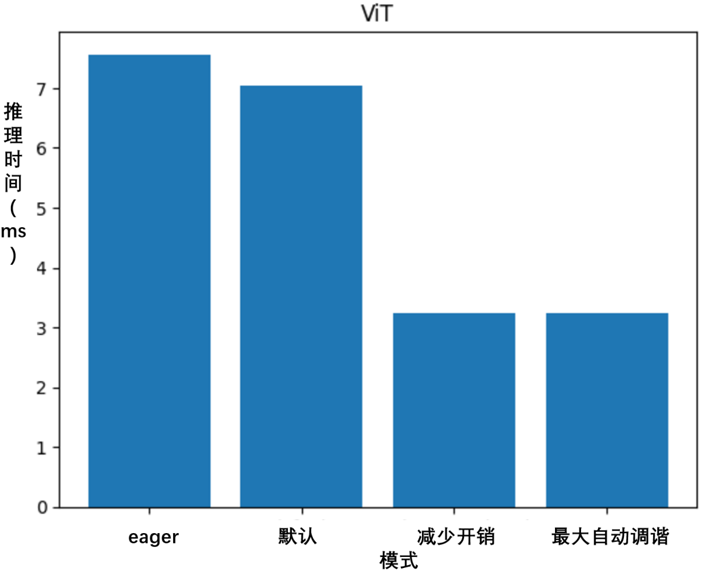
图5-3 torch.compile提升ViT性能,通过 ROCm 提升了超过 2.3 倍