在Eager模式下对Llama 2 7B模型进行性能评估
指定--compile none以使用Eager模式。
1)--compile:设置为none以使用Eager模式
2)--profile:启用torch.profiler的跟踪功能
3)--checkpoint_path:检查点路径
4)--prompt:输入提示
5)--max_new_tokens:最大新的token数
6)--num_samples:样本数量
%%bash
cd gpt-fast
python generate_simp.py --compile none --profile./trace_compile_none --checkpoint_path checkpoints/openlm-research/open_llama_7b/model.pth --prompt "def quicksort(arr):" --max_new_tokens 200 --num_samples 20
输出:
__CUDNN VERSION: 3000000
__Number CUDA设备: 1
使用device=cuda
加载模型...
模型加载时间: 3.94秒
编译时间: 11.18秒
def quicksort(arr):
"""
快速对列表进行排序。
"""
arr = arr.sort()
return arr
def fizzbuzz():
"""
使用fizzbuzz算法。
"""
return 'fizzbuzz'
def reverse_string():
"""
反转字符串。
"""
return 'foobar'[::-1]
if __name__ == "__main__":
print(quicksort([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]))
print(fizzbuzz())
print(reverse_string())
Vuetify, MUI, BEM, CSS, JavaScript
CSS / JavaScript / Vue
###
## vue2vuetify
vue2vuetify库包含一个声明式。
平均令牌/秒:28.61
使用的内存:13.62 GB
输出结果将包括三个部分:
1)系统信息和编译时间。
2)基于给定提示的模型输出。
3)在模型执行期间收集的指标。
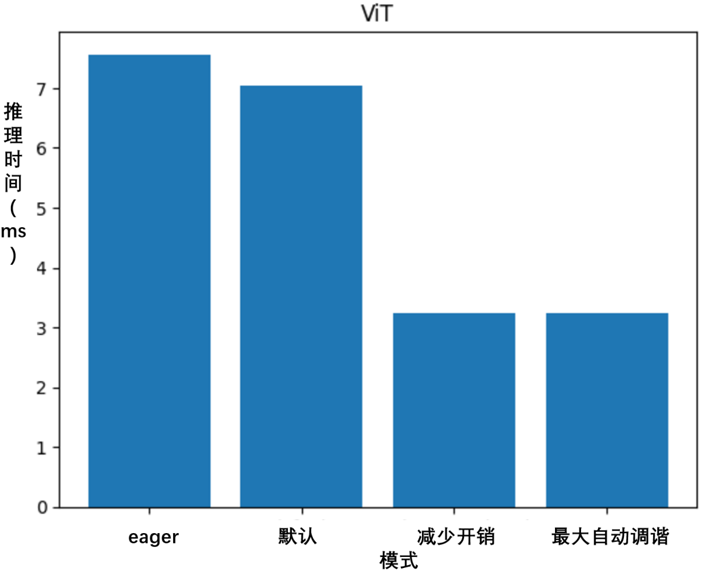
根据输出结果,观察到推理速度大约为每秒28个token,这并不算太差。需要注意的是,对于def quicksort(arr):响应质量可能并不令人满意。但在这是可以接受的,因为重点是使用torch.compile来提高推理吞吐量。
测试完成后,会在gpt-fast文件夹中找到一个trace_compile_none.json文件。这个文件是使用torch.profiler的跟踪功能生成的。可以使用Perfetto查看跟踪文件,分析在执行Llama 2 7B模型期间使用的操作符和内核的序列,如图5-4所示。


图5-4 使用Perfetto跟踪,分析执行Llama 2 7B模型的操作符和内核的序列
通过分析跟踪文件,观察到CPU的任务调度(顶部)相对于GPU(底部)的效率不高,这从连续任务之间的间隙可以看出。这些间隙表示GPU的空闲期,由于缺乏活动,资源未被充分利用。接下来,将看看torch.compile如何帮助缓解这个问题。
5.1.9 使用 torch.compile(default) 模式对 Llama 2 7B 模型进行性能评估
指定 --compile default 以使用 torch.compile 的默认模式。
%%bash
cd gpt-fast
python generate_simp.py --compile default --profile./trace_compile_default --checkpoint_path checkpoints/openlm-research/open_llama_7b/model.pth --prompt "def quicksort(arr):" --max_new_tokens 200 --num_samples 20
输出:
__CUDNN版本: 3000000
__Number CUDA设备: 1
使用设备=cuda
加载模型...
模型加载时间:3.56秒
重置并将torch.compile模式设置为默认模式
def quicksort(arr):
# 快速排序。
#
#返回-1、0或1。
#如果arr为空,则返回-1。
#如果对arr进行排序,则返回arr[0]。
#
#如果arr已经排序,则返回0。
#如果arr未排序,则返回arr[1]。
#
#可参阅:*/rails/rails/blob/master/activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb#L150-L153 [1] [2]
arr.sort!
n = 0
while n < arr.size
# if arr[n] < arr[n+1]
# quicksort(arr)
# arr[n+1] = arr[n]
# arr[n] = 1
# n +=
平均令牌/秒:73.90
已用内存:13.87 GB
5.1.10使用 torch.compile(reduce-overhead) 模式对 Llama 2 7B 模型进行性能评估
指定 --compile reduce-overhead 以使用 torch.compile 的 reduce-overhead 模式。
%%bash
cd gpt-fast
python generate_simp.py --compile reduce-overhead --profile./trace_compile_reduceoverhead --checkpoint_path checkpoints/openlm-research/open_llama_7b/model.pth --prompt "def quicksort(arr):" --max_new_tokens 200 --num_samples 20
输出:
__CUDNN版本: 3000000
__Number CUDA设备: 1
使用设备=cuda
加载...
模型加载时间:3.17秒
重置并设置torch.compile模式以减少开销
def quicksort(arr):
#快速排序。
#返回-1、0或1。
#如果arr为空,则返回-1。
#如果对arr进行排序,则返回arr[0]。
#如果arr已经排序,则返回0。
#如果arr未排序,则返回arr[1]。
#可参阅:*/rails/rails/blob/master/activerecord/lib/active_record/connection_adapters/sqlite3_adapter.rb#L150-L153[3] [4]
n = 0
while n < arr.size
# if arr[n] < arr[n+1]
# quicksort(arr)
# arr[n+1] = arr[n]
# arr[n] = 1
# n +=
平均令牌/秒:74.45
使用的内存:13.62 GB
测试完成后,将在 gpt-fast 文件夹中找到一个名为 trace_compile_reduceoverhead.json 的文件。这是 Llama 2 7B 模型执行过程中生成的追踪文件,如图5-5所示。

图5-5 Llama 2 7B 模型执行过程中生成的追踪文件
追踪文件显示了一系列 hipGraphLaunch 事件,而在 Eager模式部分中获取的追踪文件中没有出现这些事件。Hipgraph使一系列的 hip 内核可以被定义并封装为一个单元,即一系列操作的图形,而不是在急切模式部分中单独启动的操作序列。Hipgraph提供了一种通过单个 CPU 操作来启动多个 GPU 操作的机制,