进阶图论
I. 割点与桥
首先,我们得了解割点的含义
割点
对于一个无向图,如果把一个点删除后这个图的极大连通分量数增加了,那么这个点就是这个图的割点(又称割顶)。
通俗点说,就是连接两个或多个连通分量的公共点。
如何求割点呢,这里引用一个算法:Ttarjan
定义 dfn[i] 为 i 点DFS访问的顺序 , low[i] 为 i 点不经过其父亲能到达的最小的DFS序。
接着,我们开始DFS。
怎样判断割点呢, 对于一个顶点u,如果存在至少一个顶点 v (u的儿子),使得 low[v] > low[u] ,即不能回到祖先,那么u点为割点。(为什么自己想)
当然,此根据不适用搜索的起始点。(也是自己想)
更新low的代码:
if(!dfn[v])low[u] = min(low[u], low[v]);
else if(instack[i])low[u] = min(low[u], dfn[v]);
instack[i] 表示 i 点有没有被处理。u 是当前节点, v 是这个节点的所有邻居。
最后就是整体代码。
/*
洛谷 P3388 【模板】割点(割顶)
*/
#include <iostream>
#include <vector>
using namespace std;
int n, m; // n:点数 m:边数
int dfn[100001], low[100001], idx, res;
// dfn:记录每个点的时间戳
// low:能不经过父亲到达最小的编号,idx:时间戳,res:答案数量
bool vis[100001], flag[100001]; // flag: 答案 vis:标记是否重复
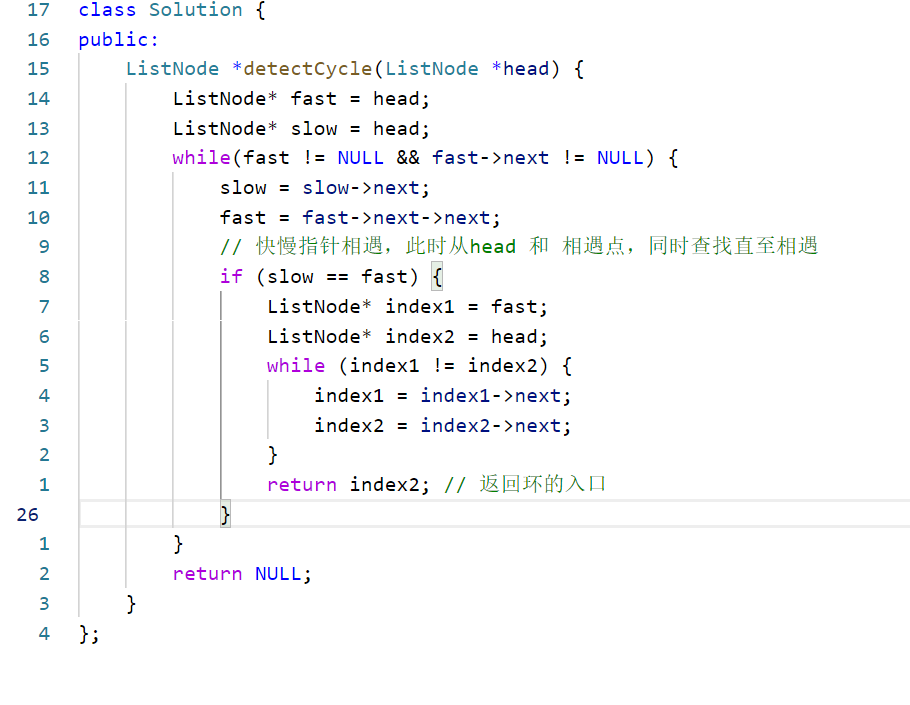
vector<int> edge[100001]; // 存图用的void Tarjan(int u, int fa) { // u 当前点的编号,fa 自己爸爸的编号vis[u] = true; // 标记low[u] = dfn[u] = ++idx; // 打上时间戳int child = 0; // 每一个点儿子数量for (const auto &v : edge[u]) { // 访问这个点的所有邻居 (C++11)if (!vis[v]) {child++; // 多了一个儿子Tarjan(v, u); // 继续low[u] = min(low[u], low[v]); // 更新能到的最小节点编号if (fa != u && low[v] >= dfn[u] && !flag[u]) { // 主要代码// 如果不是自己,且不通过父亲返回的最小点符合割点的要求,并且没有被标记过// 要求即为:删了父亲连不上去了,即为最多连到父亲flag[u] = true;res++; // 记录答案}} else if (v != fa) {// 如果这个点不是自己的父亲,更新能到的最小节点编号low[u] = min(low[u], dfn[v]);}}// 主要代码,自己的话需要 2 个儿子才可以if (fa == u && child >= 2 && !flag[u]) {flag[u] = true;res++; // 记录答案}
}int main() {cin >> n >> m; // 读入数据for (int i = 1; i <= m; i++) { // 注意点是从 1 开始的int x, y;cin >> x >> y;edge[x].push_back(y);edge[y].push_back(x);} // 使用 vector 存图for (int i = 1; i <= n; i++) // 因为 Tarjan 图不一定连通if (!vis[i]) {idx = 0; // 时间戳初始为 0Tarjan(i, i); // 从第 i 个点开始,父亲为自己}cout << res << endl;for (int i = 1; i <= n; i++)if (flag[i]) cout << i << " "; // 输出结果return 0;
}
割边(无重边)
和割点差不多,叫做桥(点换成边嘛)。不做解释。
更新的方法和割点差不多, 只需改一处low[v] > dfn[u],也就是不用判断根节点了。
下面代码实现了对 无重边 的无向图求割边,其中,当 isbridge[x] 为真时,(father[x],x) 为一条割边。
int low[MAXN], dfn[MAXN], idx;
bool isbridge[MAXN];
vector<int> G[MAXN];
int cnt_bridge;
int father[MAXN];void tarjan(int u, int fa) {father[u] = fa;low[u] = dfn[u] = ++idx;for (const auto &v : G[u]) {if (!dfn[v]) {tarjan(v, u);low[u] = min(low[u], low[v]);if (low[v] > dfn[u]) {isbridge[v] = true;++cnt_bridge;}} else if (v != fa) {low[u] = min(low[u], dfn[v]);}}
}
en就这么多。
圆方树
点双联通分量不是很好缩点,但是我们可以建立圆方树:每个点双建一个点,称之为方点,原图中每个点也建一个新点,称之为原点。每个方点与属于他的圆点连边,就构成了一棵树,称为圆方树。
图例
下面的图显示了一张图对应的点双和圆方树形态



因为圆方树是基于割点的,所以只需要用类似求割点的方法构建圆方树。
void Tarjan(int u) {low[u] = dfn[u] = ++dfc; // low 初始化为当前节点 dfnfor (int v : G[u]) { // 遍历 u 的相邻节点if (!dfn[v]) { // 如果未访问过Tarjan(v); // 递归low[u] = min(low[u], low[v]) // 未访问的和 low 取 minif (low[v] == dfn[u]) // 标志着找到一个以 u 为根的点双连通分量++cnt; // 增加方点个数// 将点双中除了 u 的点退栈,并在圆方树中连边for (int x = 0; x != v; --tp) {x = stk[tp];T[cnt].push_back(x);T[x].push_back(cnt);}// 注意 u 自身也要连边(但不退栈)T[cnt].push_back(u);T[u].push_back(cnt);elselow[u] = min(low[u], dfn[v]); // 已访问的和 dfn 取 min}
}
II.网络流
网络流是指一个特殊的有向图。
这个图的特殊点在于有两个特殊的点,源点和汇点,还有一个类似边权的容量
网络流满足以下限制
1.容量限制:对于每条边,流经该边的流量不得超过该边的容量
2.流守恒性:除源汇点外,任意结点 u的净流量为0.(也就是流入和流出的流量一样)
最大流
定义:
给定网络G及G上的流 f.
对于边(u, v),我们将其容量与流量之差称为剩余容量c(u,v)
我们将G中所有结点和剩余容量大于0的边构成的子图称为残量网络.
我们将G上一条从源点s到
Edmonds–Karp算法(简称EK)
对于每一个容量