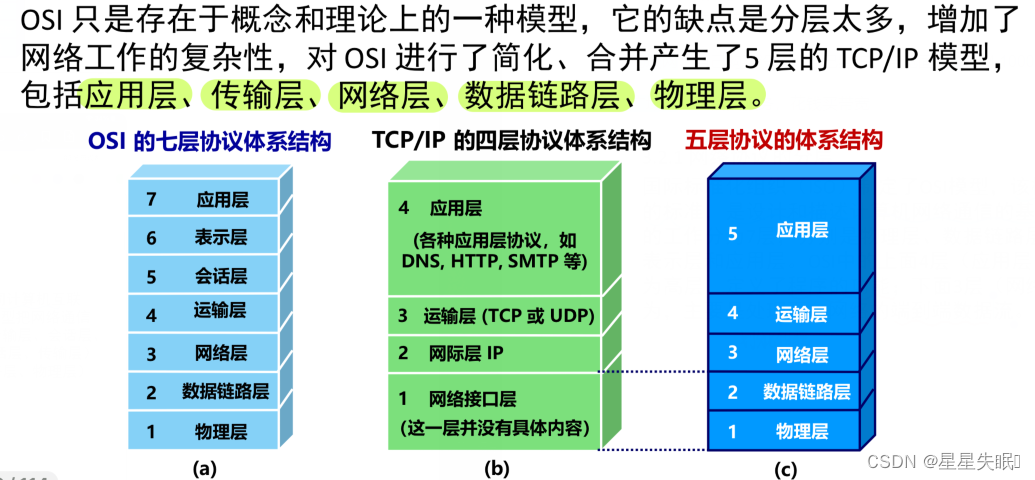
调度模型
传统构建系统有很多是基于任务的,例如 Ant,Maven,Gradle。用户可以自定义"任务"(Task),例如执行一段 shell 脚本。用户配置它们的依赖关系,构建系统则按照顺序调度。
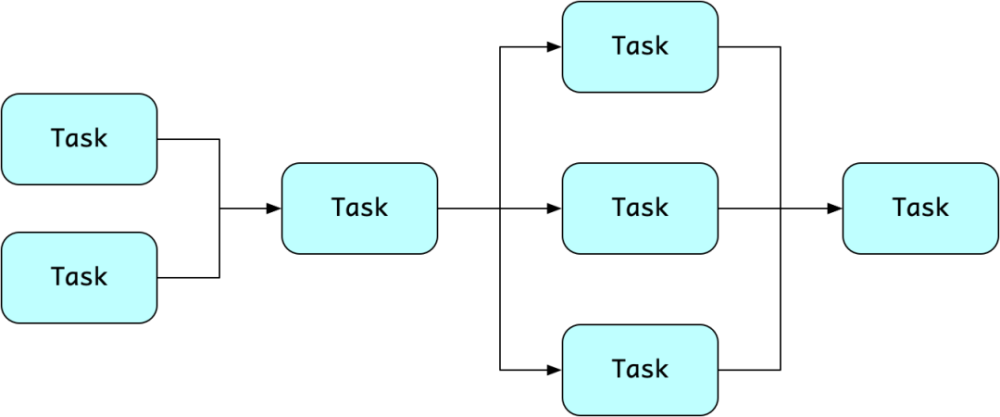
基于 Task 的调度模型
这种模式对使用者很友好,他可以专注任务的定义,而不用关心复杂的调度逻辑。构建系统通常给予任务制定者极大的"权利",比如 Gradle 允许用户用 Java 代码编写任务,原则上可以做任何事。
如果一个任务,在输入条件不变的情况下,永远输出相同的结果,我们就认为这个任务是"封闭"(Hermeticity) 的。构建系统可以利用封闭性提升构建效率,例如第二次构建时,跳过某些输入没变的 Task,这种方式也称为 增量构建。
不满足封闭性的任务,则会导致增量构建失效,例如 Task 访问某个互联网资源,或者 Task 在执行时依赖随机数或时间戳这样的动态特征,这些都会导致多次执行 Task 得到不同的结果。
Bazel 采用了不同的调度模型,它是基于目标Target【制品 (Artifact) 的】。Bazel 官方定义了一些规则 (rule),用于构建某些特定产物,例如 c++ 的 library 或者 go 语言的 package,用户配置和调用这些规则。他仅仅需要告诉 Bazel 要构建什么 target,而由 Bazel 来决定如何构建它。
规则由官方和可信赖第三方维护,规则产生的任务,满足封闭性需求,这使得用户可以信赖系统的增量构建能力。
bazel基于 Target 的调度模型如下图所示:
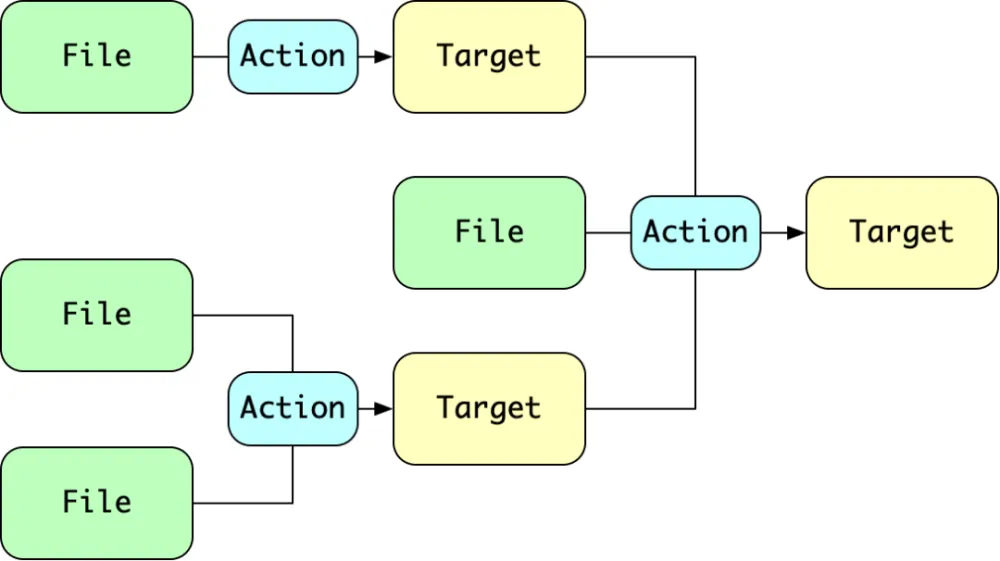
基于 Target 的调度模型
File 表示原始文件,Target 表示构建时生成的文件。当用户告诉 Bazel 要构建某个 Target 的时候,Bazel 会分析这个文件如何构建(构建动作定义为 Action,和其他构建系统的 Task 大同小异),如果 Target 依赖了其他 Target,Bazel 会进一步分析依赖的 Target 又是如何构建生成的,这样一层层分析下去,最终绘制出完整的执行计划。
并行编译
Bazel 精准的知道每个 Action 依赖哪些文件,这使得没有相互依赖关系的 Action 可以并行执行,而不用担心竞争问题。基于任务的构建系统则存在这样的问题:
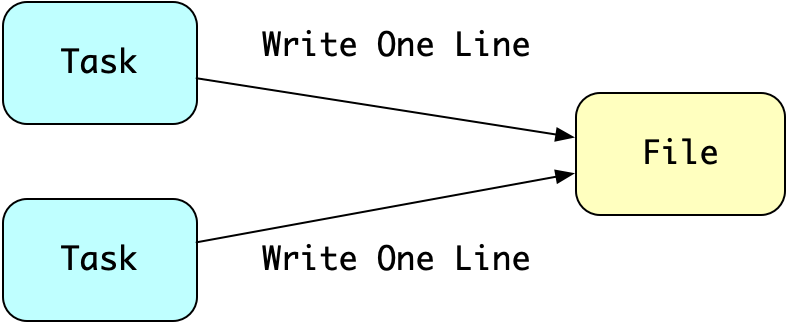
基于任务的构建系统存在竞争问题
两个 Task 都会向同一个文件写一行字符串,这就造成两个 Task 的执行顺序会影响最终的结果。要想得到稳定的结果,就需要定义这两个 Task 之间的依赖关系。
Bazel 的 Action 由构建系统本身设计,更加安全,也不会出现类似的竞争问题。因此我们可以充分利用多核 CPU 的特性,让 Action 并行执行。
通常我们采用 CPU 逻辑核心数作为 Action 执行的并发度,如果开启了远端执行 (后面会提到),则可以开启更高的并发度。
增量编译
Bazel 将构建拆分为独立的步骤,这些步骤称为操作(Action)。每项操作都有输入、输出名称、命令行和环境变量。系统会为每个操作明确声明所需的输入和预期输出。
对 Bazel 来说,每个 Target 的构建过程,都对应若干 Action 的执行。Action 的执行本质上就是"输入文件 + 编译命令 + 环境信息 = 输出文件"的过程。

Action 的描述
如果本地文件系统保留着上一次构建的 outputs,此时 Bazel 只需要分析 inputs, commands 和 envs 和上次相比有没有改变,没有改变就直接跳过该 Action 的执行。
这对于本地开发非常有用,如果你只修改了少量代码,Bazel 会自动分析哪些 Action 的 inputs 发生了变化,并只构建这些 Action,整体的构建时间会非常快。
不过增量构建并不是 Bazel 独有的能力,大部分的构建系统都具备。但对于几万个文件的大型工程,如果不修改一行代码,只有 Bazel 能在一秒以内构建完毕,其他系统都至少需要几十秒的时间,这简直就是 降维打击 了。
Bazel 是如何做到的呢?
首先,Bazel 采用了 Client/Server 架构,当用户键入 bazel build 命令时,调用的是 bazel 的 client 工具,而 client 会拉起 server,并通过 grpc 协议将请求 (buildRequest) 发送给它。由 server 负责配置的加载,ActionGraph 的生成和执行。

Bazel 的 C/S 架构
构建结束后,Server 并不会立即销毁,而 ActionGraph 也会一直保存在内存中。当用户第二次发起构建时,Bazel 会检测工作空间的哪些文件发生了改变,并更新 ActionGraph。如果没有文件改变,就会直接复用上一次的 ActionGraph 进行分析。
这个分析过程完全在内存中完成,所以如果整个工程无需重新构建,即便是几万个 Action,也能在一秒以内分析完毕。而其他系统,至少需要花费几十秒的时间来重新构建 ActionGraph。
本文属于如下文章中的子章节
bazel学习系列章节汇总_m0_74043383的博客-CSDN博客