目录
二叉树节点结构:
1.1 前序遍历(Preorder Traversal):
递归实现(preorderRecursive函数):首先访问当前节点,然后递归遍历左子树,最后递归遍历右子树。这种遍历方式可以用于深度优先搜索。
非递归实现(preorderIterative函数):
2中序遍历(Inorder Traversal):中序遍历的顺序是左子树 -> 根节点 -> 右子树。
3后序遍历(Postorder Traversal):后序遍历的顺序是左子树 -> 右子树 -> 根节点。
4层序遍历(Level Order Traversal):层序遍历按照从上到下、从左到右的顺序遍历每一层的节点。
5深度优先遍历(Depth-First Traversal):深度优先遍历是一种通用的遍历方式,可以根据需要选择前序、中序、后序遍历方式。
以下是C++中二叉树前序、中序、后序遍历的递归和非递归实现,以及层序遍历和深度优先遍历的代码和讲解。
二叉树节点结构:
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
1.1 前序遍历(Preorder Traversal):
前序遍历的顺序是根节点 -> 左子树 -> 右子树。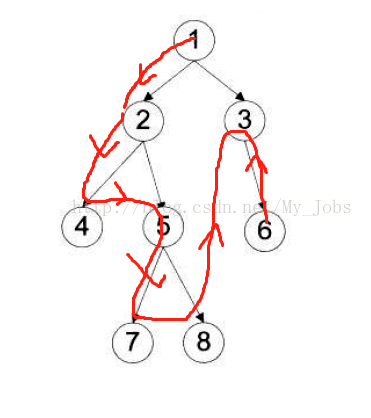
-
递归实现(
preorderRecursive函数):首先访问当前节点,然后递归遍历左子树,最后递归遍历右子树。这种遍历方式可以用于深度优先搜索。 -
void preorderRecursive(TreeNode* root) {if (root == NULL) return;cout << root->val << " ";preorderRecursive(root->left);preorderRecursive(root->right); } -
非递归实现(
preorderIterative函数): - 使用一个栈来模拟递归,首先将根节点入栈,然后循环直到栈为空。在循环内,将栈顶节点出栈并访问,然后将右子节点和左子节点(如果存在)依次入栈,以确保下一次出栈的是左子节点。这样可以按照根-左-右的顺序遍历树。
void preorderIterative(TreeNode* root) {if (root == NULL) return;stack<TreeNode*> s;s.push(root);while (!s.empty()) {TreeNode* node = s.top();s.pop();cout << node->val << " ";if (node->right) s.push(node->right);if (node->left) s.push(node->left);}
}
-
2中序遍历(Inorder Traversal):中序遍历的顺序是左子树 -> 根节点 -> 右子树。
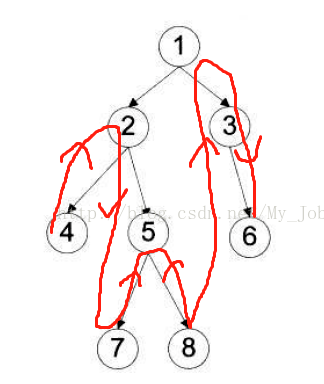
- 递归实现(
inorderRecursive函数):首先递归遍历左子树,然后访问当前节点,最后递归遍历右子树。中序遍历可以按照从小到大的顺序遍历二叉搜索树的所有节点。void inorderRecursive(TreeNode* root) {if (root == NULL) return;inorderRecursive(root->left);cout << root->val << " ";inorderRecursive(root->right); } - 非递归实现(
inorderIterative函数):使用一个栈来模拟递归,从根节点出发,每次将当前节点以及所有左子节点入栈,然后出栈并访问节点,再处理右子节点。这样可以按照左-根-右的顺序遍历树。void inorderIterative(TreeNode* root) {stack<TreeNode*> s;TreeNode* curr = root;while (curr || !s.empty()) {while (curr) {s.push(curr);curr = curr->left;}curr = s.top();s.pop();cout << curr->val << " ";curr = curr->right;} }
- 递归实现(
-
3后序遍历(Postorder Traversal):后序遍历的顺序是左子树 -> 右子树 -> 根节点。
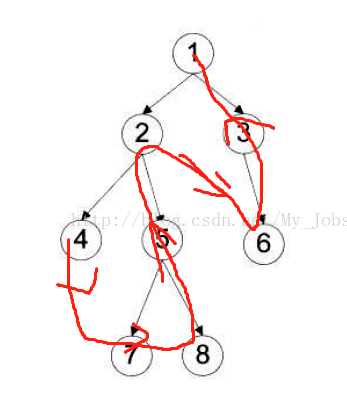
- 递归实现(
postorderRecursive函数):首先递归遍历左子树,然后递归遍历右子树,最后访问当前节点。后序遍历通常用于内存管理和资源释放。void postorderRecursive(TreeNode* root) {if (root == NULL) return;postorderRecursive(root->left);postorderRecursive(root->right);cout << root->val << " "; } - 非递归实现(
postorderIterative函数):需要两个栈,一个用于遍历,另一个用于输出。首先将根节点入遍历栈,然后在循环中,出栈并压入输出栈,然后将左子节点和右子节点分别压入遍历栈。最后,从输出栈中依次出栈并访问节点,得到后序遍历的结果。void postorderIterative(TreeNode* root) {if (root == NULL) return;stack<TreeNode*> s;stack<TreeNode*> output;s.push(root);while (!s.empty()) {TreeNode* node = s.top();s.pop();output.push(node);if (node->left) s.push(node->left);if (node->right) s.push(node->right);}while (!output.empty()) {TreeNode* node = output.top();output.pop();cout << node->val << " ";} }
- 递归实现(
-
4层序遍历(Level Order Traversal):层序遍历按照从上到下、从左到右的顺序遍历每一层的节点。

- 使用队列来实现。从根节点开始,将节点入队列,然后在循环中出队列并访问节点,同时将其子节点入队列。这样可以按照树的层级顺序遍历。
void levelOrder(TreeNode* root) {if (root == NULL) return;queue<TreeNode*> q;q.push(root);while (!q.empty()) {TreeNode* node = q.front();q.pop();cout << node->val << " ";if (node->left) q.push(node->left);if (node->right) q.push(node->right);} }
- 使用队列来实现。从根节点开始,将节点入队列,然后在循环中出队列并访问节点,同时将其子节点入队列。这样可以按照树的层级顺序遍历。
-
5深度优先遍历(Depth-First Traversal):深度优先遍历是一种通用的遍历方式,可以根据需要选择前序、中序、后序遍历方式。
- 深度优先遍历是一种通用的遍历方法,可以根据需要选择前序、中序、后序遍历方式。在示例中,使用前序遍历的方式进行深度优先遍历。深度优先遍历通过栈来实现,首先将根节点入栈,然后在循环中出栈并访问节点,同时将右子节点和左子节点(按照栈的特性,右子节点先入栈)依次入栈,以确保下一次出栈的是左子节点。
void depthFirst(TreeNode* root) {if (root == NULL) return;stack<TreeNode*> s;s.push(root);while (!s.empty()) {TreeNode* node = s.top();s.pop();cout << node->val << " ";if (node->right) s.push(node->right);if (node->left) s.push(node->left);} }
- 深度优先遍历是一种通用的遍历方法,可以根据需要选择前序、中序、后序遍历方式。在示例中,使用前序遍历的方式进行深度优先遍历。深度优先遍历通过栈来实现,首先将根节点入栈,然后在循环中出栈并访问节点,同时将右子节点和左子节点(按照栈的特性,右子节点先入栈)依次入栈,以确保下一次出栈的是左子节点。