C++数据结构与算法实现(目录)
1 什么是HashMap?
我们这里要实现的HashMap接口不会超过标准库的版本(是一个子集)。
HashMap是一种键值对容器(关联容器),又叫字典。
和其他容易一样,它可以对存储的元素进行增删改查操作。
它之所以叫关联容器,是因为它的每个元素都是一对(键 key 和值 value)。
比如:
HashMap h;
h[123] = string("张三");//每个元素包括一个键(123)和值("张三")这种容器可以快速的访问容器中的任何一个元素。
2 为何可以快速访问元素?桶
它之所以能快速的做到这一点,是因为可以快速的知道这个容器里有没有这个元素。
而快速知道容器里有没有这个元素的关键就在于拿到一个key,就知道这个元素会在哪个桶里面。
这里使用一个函数,也叫hash函数,计算key对应的桶:
auto index = hashFunction(key);
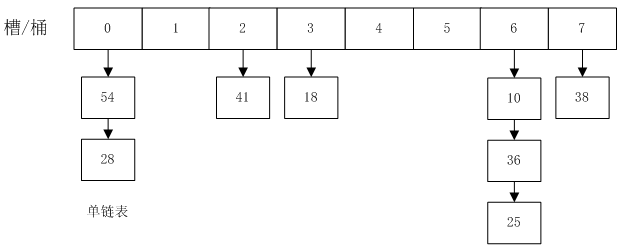
HashMap的结构如下图所示:
槽桶是一个vector数组,每个数组里是一个list链表。
3 冲突与解决
不同的 key 如果都映射到同一个index怎么让同一个桶存两个value呢?
hashFun(key1) == hashFun(key2)
可以使用一个单链表,将相同 hash 值的 key 放到同一个桶里。
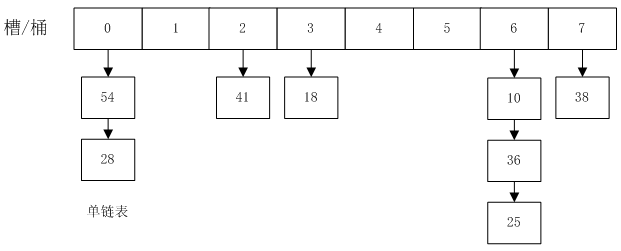
4 元素的均匀分布
怎么样设计hashFun使得元素会均匀的落到每个链表里?
使得每个链表里都有大概n/N个元素。其中,n是元素总数,N是槽的个数。是我们需要重点考虑的。
为了解决这个问题,我们要求hashFunction 对每一个key,都能均匀的分散到各个桶里,最简单有效的办法就是将key看成(转换成)整数,对vector 桶的数量求余数,余数作为桶的索引(本文我们就使用这种方法)。
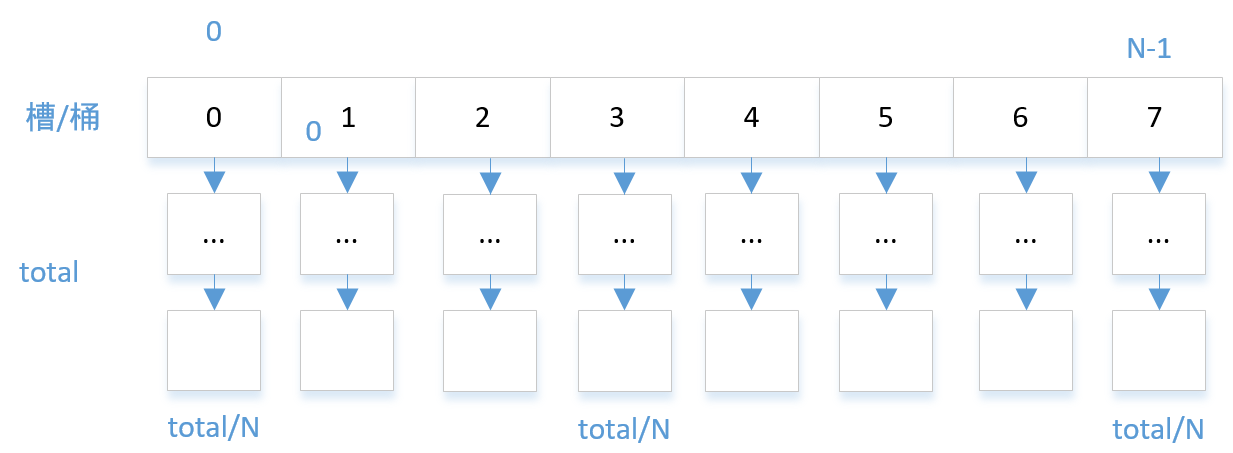
5 再哈希 rehash
如果随着元素数量越来越多,元素都堆积在某一个或几个链表里,其他链表都空着。这样HashMap又退化成链表了:
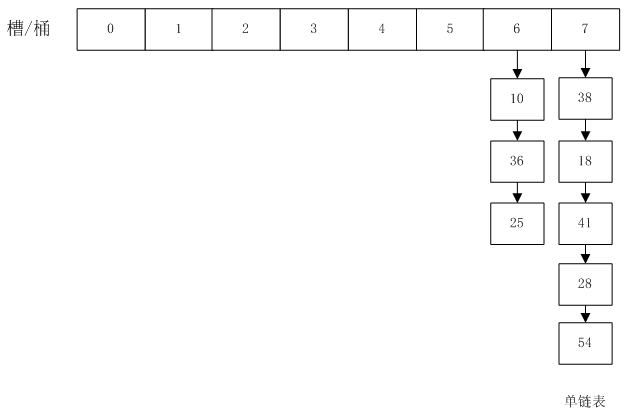
解决了元素的均匀分布之后,我们还会遇到下一个问题。
元素越来越多以后,桶bucket的数量应该要增加,不然每个链表都很长,效率还是会降低。

这时候就要再hash。
判断什么时候应该rehash的机制就是看装载因子load_factor 的大小。
load_factor 来表示现在是不是元素数量已经很多了,如果这个值 大于0.8,就表示每个桶里堆积的元素都比较多了。就要使用更多的桶来存放元素了。
装载因子的计算方法,有个很简单的办法,就是让每个vector里的链表尽量的短。那就是容器元素接近vector元素的数量:
load_factor = n/N
其中,n 是元素总数,N是槽的个数。
比如, n/N > 0.8 ,我们就再 hash 一次。
6 成员函数设计要点
我们将使用vector 和 list 来实现这个容器,让大家感受一下用轮子造轮子到底有多爽。
感受软件复用的力量。
感受抽象的力量。
1) clear
这个函数负责清空元素,回到初始状态,也就是对象被构造出来的状态。
但是,由于我们的HashMap 在初始状态就开辟了8个空间为未来存放元素使用,所以clear会涉及到调用reset。
而 reset需要记得初始化一切数据,包括将容量设置为8.

2) reset
reset是给默认构造函数调用的,其具体行为参考 clear部分的介绍。
同时,reset也会被clear调用。那直接用clear一个函数不就好了吗?实际上是为了代码更容易阅读理解。
reset为了初始化, clear是用户调用的,用户只知道清空容器,并不关心reset。
3) copy
copy函数负责拷贝另一个对象的数据给当前对象。
主要是拷贝构造函数和赋值操作符会调用。
首先,需要先清空当前对象的数据。然后再做深拷贝即可。
4) rehash 再哈希
这个函数是最复杂的,它主要分为如下几个部分:
(1)创建一个新的HashMap对象
(2)新对象的桶数量要翻倍(rehash的主要作用就是横向扩展,让每个list变短)
(3)把原来的元素装到新的HashMap对象里
(4)交换新旧对象的资源实现接管新场所,释放旧空间的目的
5) operator[]
这个函数会添加元素(如果元素不存在的话),而如果此时容器已经比较拥挤了,就是扩容的时机。
4) 其他函数
更多函数设计的实现细节思路,参考下面代码中的注释部分。
C++实现
下面我们将实现一个 key 类型为 int,value 类型为 std::string 的HashMap。
HashMap.h 头文件
#pragma once
#include<string>
#include<list>
#include<memory>
#include<vector>
#include<utility>
using namespace std;
class HashMap
{
public:HashMap(void);~HashMap(void);HashMap(const HashMap& from);HashMap& operator=(const HashMap& from);
public:bool empty(void) const { return m_size == 0; }size_t size(void) const;bool contains(const int& key) const;std::string& operator[](const int& key);void erase(const int& key);
public:using value_type = std::pair<int, std::string>;
public:class iterator{friend class HashMap;public:iterator& operator++(void);//++itrbool operator==(const iterator& itr);bool operator!=(const iterator& itr);value_type& operator*(void);private:iterator(HashMap* hashmap, size_t bucket_index, std::list<value_type>::iterator itr);private:std::list<value_type>::iterator m_itr;size_t m_bucket_index;//-1 for end()HashMap* m_hashmap;};iterator begin(void);iterator end(void);void clear(void);
private:size_t hash(const int& key) const;void copy(const HashMap& from);//装载因子double load_factor(void) const { return (double)m_size / m_bucket_array_length; };void re_hash(void);//扩大容量void reset(void);
private:std::vector<std::list<value_type>> m_bucket_array;size_t m_size = 0;size_t m_bucket_array_length = 8;
};
实现特点:增删改查、迭代器、再哈希、复制控制、基于std::vector、std::list (复用、模块化)
HashMap.cpp 源文件
#include "HashMap.h"
#include <algorithm>
#include <iostream>
#include <cassert>
using namespace std;HashMap::HashMap(void)
{//(1) your code 直接调用reset完成默认开辟8个元素空间cout << "HashMap()" << endl;
}HashMap::~HashMap(void)
{// 析构函数什么也不用做,因为存放数据的容器 vector list 会自动释放其拥有的元素cout << "~HashMap()" << endl;
}HashMap::HashMap(const HashMap& from)
{//(2) your code 直接调用 copy 即可完成拷贝cout << "HashMap(const HashMap &)" << endl;
}HashMap& HashMap::operator=(const HashMap& from)
{//(2) your code 直接调用 copy 即可完成拷贝cout << "HashMap::operator=(const HashMap & from)" << endl;return *this;
}size_t HashMap::size(void) const
{return m_size;
}bool HashMap::contains(const int& key) const
{//(3) your code 通过hash(key) 得到数据如果存在应该在哪个桶里//(4) your code 再到桶里 list 查找有没有这个元素 ,在链表中 线性查找return false;//这里需要改成真正的查找结果
}std::string& HashMap::operator[](const int& key)
{//(5) your code 如果装载因子 大于了 0.8 就 re_hash 扩大容量//通过hash(key) 得到数据如果存在应该在哪个桶里auto index = hash(key);assert(m_bucket_array.size() > index);auto& bucket = m_bucket_array[index];//再到桶里 list 查找有没有这个元素 ,在链表中 线性查找。返回 list<T>::iteratorauto itr = std::find_if(bucket.begin(), bucket.end(), [key](const value_type& value) {return value.first == key;});if (itr == bucket.end()){//(6) your code. key not exist, insert empty std::string as default value//(7) your code. increase the size of current hash map.//(8) your code. return elementstatic string s_bad;//请删除return s_bad;//请重写}else{//(9) your code. return elementstatic string s_bad;//请删除return s_bad;//请重写}
}void HashMap::erase(const int& key)
{auto index = hash(key);auto& bucket = m_bucket_array[index];auto itr = std::find_if(bucket.begin(), bucket.end(), [key](const value_type& value) {return value.first == key;});if (itr == bucket.end()){throw std::runtime_error("erasing not exist key!");}else{--m_size;bucket.erase(itr);}
}HashMap::iterator HashMap::begin(void)
{for (size_t i = 0; i < m_bucket_array_length; i++){if (!m_bucket_array[i].empty()){return HashMap::iterator(this, i, m_bucket_array[i].begin());}}return end();
}HashMap::iterator HashMap::end(void)
{return HashMap::iterator(this, -1, std::list<value_type>::iterator());
}size_t HashMap::hash(const int& key) const
{// 使用key 得到元素在哪个桶里。使用求余数来得到。// 这种算法可以认为是足够简单而且元素会均匀分布在各个桶里的int index = key % m_bucket_array_length;return index;
}void HashMap::clear(void)
{reset();
}void HashMap::copy(const HashMap& from)
{clear();m_bucket_array.resize(from.m_bucket_array_length);for (size_t i = 0; i < m_bucket_array_length; i++){//10 your code. 使用链表的赋值操作符直接拷贝链表}m_size = from.m_size;
}void HashMap::re_hash(void)
{//另起炉灶,新创建一个HashMapHashMap re_hashmap;//将新的炉灶扩大容量re_hashmap.m_bucket_array_length = this->m_bucket_array_length * 2 + 1;//11 your code. 将新的炉灶实际的桶开辟出来//使用迭代器,遍历原来的(this)所有元素,将所有元素拷贝到新的炉灶里for (auto itr = begin(); itr != end(); ++itr){//12 your code. 先根据key获得桶,再把value追加到桶里list的末尾}//交换新旧两个容器的内容,接管新炉灶std::swap(re_hashmap.m_bucket_array, m_bucket_array);//其他成员变量更新this->m_bucket_array_length = re_hashmap.m_bucket_array_length;re_hashmap.m_size = this->m_size;
}void HashMap::reset(void)
{m_size = 0;m_bucket_array.clear();m_bucket_array_length = 8;m_bucket_array.resize(m_bucket_array_length);
}HashMap::iterator& HashMap::iterator::operator++(void)
{//valid itr can always do ++itrauto index = m_hashmap->hash(m_itr->first);auto& bucket = m_hashmap->m_bucket_array[index];++m_itr;//find next list or the end() occorif (m_itr == bucket.end()){for (size_t i = m_bucket_index + 1; i < m_hashmap->m_bucket_array_length; i++){if (!m_hashmap->m_bucket_array[i].empty()){m_bucket_index = i;m_itr = m_hashmap->m_bucket_array[i].begin();return *this;}}m_bucket_index = -1;//end()}return *this;
}bool HashMap::iterator::operator==(const iterator& itr)
{if (itr.m_bucket_index != this->m_bucket_index){return false;}if (itr.m_bucket_index == -1 && this->m_bucket_index == -1){return true;//both end()}else{bool equal = &*(m_itr) == &*(itr.m_itr);return equal;//pointed to the same value address}
}bool HashMap::iterator::operator!=(const iterator& itr)
{bool equal = (*this == itr);return !equal;
}HashMap::value_type& HashMap::iterator::operator*(void)
{return *m_itr;
}HashMap::iterator::iterator(HashMap* hashmap, size_t bucket_index, std::list<value_type>::iterator itr)
{m_hashmap = hashmap;m_itr = itr;m_bucket_index = bucket_index;
}
main.cpp
#include <iostream>
#include "HashMap.h"
#include <cassert>
#include <unordered_map>
#include <set>
using namespace std;//------下面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------
#include <algorithm>
#include <cstdlib>
#include <iostream>
#include <vector>
#include <utility>
using namespace std;
struct Record { Record(void* ptr1, size_t count1, const char* location1, int line1, bool is) :ptr(ptr1), count(count1), line(line1), is_array(is) { int i = 0; while ((location[i] = location1[i]) && i < 100) { ++i; } }void* ptr; size_t count; char location[100] = { 0 }; int line; bool is_array = false; bool not_use_right_delete = false; }; bool operator==(const Record& lhs, const Record& rhs) { return lhs.ptr == rhs.ptr; }std::vector<Record> myAllocStatistic; void* newFunctionImpl(std::size_t sz, char const* file, int line, bool is) { void* ptr = std::malloc(sz); myAllocStatistic.push_back({ ptr,sz, file, line , is }); return ptr; }void* operator new(std::size_t sz, char const* file, int line) { return newFunctionImpl(sz, file, line, false); }void* operator new [](std::size_t sz, char const* file, int line)
{return newFunctionImpl(sz, file, line, true);
}void operator delete(void* ptr) noexcept { Record item{ ptr, 0, "", 0, false }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }void operator delete[](void* ptr) noexcept { Record item{ ptr, 0, "", 0, true }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (!itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }
#define new new(__FILE__, __LINE__)
struct MyStruct { void ReportMemoryLeak() { std::cout << "Memory leak report: " << std::endl; bool leak = false; for (auto& i : myAllocStatistic) { if (i.count != 0) { leak = true; std::cout << "leak count " << i.count << " Byte" << ", file " << i.location << ", line " << i.line; if (i.not_use_right_delete) { cout << ", not use right delete. "; } cout << std::endl; } }if (!leak) { cout << "No memory leak." << endl; } }~MyStruct() { ReportMemoryLeak(); } }; static MyStruct my; void check_do(bool b, int line = __LINE__) { if (b) { cout << "line:" << line << " Pass" << endl; } else { cout << "line:" << line << " Ohh! not passed!!!!!!!!!!!!!!!!!!!!!!!!!!!" << " " << endl; exit(0); } }
#define check(msg) check_do(msg, __LINE__);
//------上面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------int main()
{//create insert find{HashMap students;check(students.empty());check(students.size() == 0);int id = 123;check(students.contains(id) == false);std::string name("zhangsan");students[id] = name;check(!students.empty());check(students.size() == 1);check(students.contains(id));check(students[id] == name);}//modify value{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;std::string name2("lisi");students[id] = name2;check(students[id] == name2);check(students.size() == 1);}//erase{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;students.erase(id);check(!students.contains(id));check(students.size() == 0);}//clear value{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;std::string name2("lisi");students[id] = name2;check(students[id] == name2);check(students.size() == 1);students.clear();check(students.size() == 0);students.clear();}//copy{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;HashMap students2(students);//copy constructorcheck(students.contains(id));check(students.size() == 1);students[456] = "lisi";check(students.contains(456));check(!students2.contains(456));students2[789] = "wanger";check(!students.contains(789));check(students2.contains(789));check(students.size() == 2);check(students2.size() == 2);}//assignment{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;students[456] = "lisi";HashMap students2;students2 = students;check(students2.contains(id));check(students2.contains(456));check(students.size() == 2);}//iteratorconst int total = 50;{int id_creator = 1;HashMap students;std::string name("zhangsan");for (int i = 1; i <= total; ++i){students[id_creator++] = name + std::to_string(i);}check(students.size() == total);std::multiset<int> all_keys;for (auto& item : students){all_keys.insert(item.first);cout << item.first << " " << item.second << endl;}int i = 1;for (auto item : all_keys){assert(item == i++);}check(i == total + 1);students.clear();for (int i = 1; i <= total; ++i){students[i] = std::to_string(i);}check(students.contains(1));check(students.contains(total));check(students[1] == "1");check(students[total] == to_string(total));check(students.size() == total);}
}
输出如下:
HashMap()
line:30 Pass
line:31 Pass
line:33 Pass
line:36 Pass
line:37 Pass
line:38 Pass
line:39 Pass
~HashMap()
HashMap()
line:49 Pass
line:50 Pass
~HashMap()
HashMap()
line:59 Pass
line:60 Pass
~HashMap()
HashMap()
line:70 Pass
line:71 Pass
line:73 Pass
~HashMap()
HashMap()
HashMap(const HashMap &)
line:83 Pass
line:84 Pass
line:86 Pass
line:87 Pass
line:89 Pass
line:90 Pass
line:91 Pass
line:92 Pass
~HashMap()
~HashMap()
HashMap()
HashMap()
HashMap::operator=(const HashMap & from)
line:103 Pass
line:104 Pass
line:105 Pass
~HashMap()
~HashMap()
HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
line:117 Pass
1 zhangsan1
2 zhangsan2
3 zhangsan3
4 zhangsan4
5 zhangsan5
6 zhangsan6
7 zhangsan7
8 zhangsan8
9 zhangsan9
10 zhangsan10
11 zhangsan11
12 zhangsan12
13 zhangsan13
14 zhangsan14
15 zhangsan15
16 zhangsan16
17 zhangsan17
18 zhangsan18
19 zhangsan19
20 zhangsan20
21 zhangsan21
22 zhangsan22
23 zhangsan23
24 zhangsan24
25 zhangsan25
26 zhangsan26
27 zhangsan27
28 zhangsan28
29 zhangsan29
30 zhangsan30
31 zhangsan31
32 zhangsan32
33 zhangsan33
34 zhangsan34
35 zhangsan35
36 zhangsan36
37 zhangsan37
38 zhangsan38
39 zhangsan39
40 zhangsan40
41 zhangsan41
42 zhangsan42
43 zhangsan43
44 zhangsan44
45 zhangsan45
46 zhangsan46
47 zhangsan47
48 zhangsan48
49 zhangsan49
50 zhangsan50
line:129 Pass
HashMap()
~HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
line:135 Pass
line:136 Pass
line:137 Pass
line:138 Pass
line:139 Pass
~HashMap()
Memory leak report:
No memory leak.项目下载:start file
链接:百度网盘 请输入提取码
提取码:1234
加油吧!
期待你的pass
答案在此
哈希表HashMap(基于vector和list)(答案)_C++开发者的博客-CSDN博客
![[笔记] 阿里云域名知识](https://img-blog.csdnimg.cn/179fc9a5d06444e3871e325656cb9b67.png)