以下文章来源于爱可生开源社区 ,作者张乾

爱可生开源社区.
爱可生开源社区,提供稳定的MySQL企业级开源工具及服务,每年1024开源一款优良组件,并持续运营维护。
测试在做 OceanBase 纯读性能压测的时候,发现对数据做过更新操作后,读性能会有较为明显的下降。具体复现步骤如下。

复现方式
1. 环境预备
部署 OceanBase
使用 OBD 部署单节点 OceanBase。
| 版本 | IP | |
|---|---|---|
| OceanBase | 4.0.0.0 CE | 10.186.16.122 |
参数均为默认值,其中内存以及转储合并等和本次实验相关的重要参数值具体如下:
| 参数名 | 含义 | 默认值 |
|---|---|---|
memstore_limit_percentage | 设置租户使用 memstore 的内存占其总可用内存的百分比。 | 50 |
freeze_trigger_percentage | 触发全局冻结的租户使用内存阈值。 | 20 |
major_compact_trigger | 设置多少次小合并触发一次全局合并。 | 0 |
minor_compact_trigger | 控制分层转储触发向下一层下压的阈值。当该层的 Mini SSTable 总数达到设定的阈值时,所有 SSTable 都会被下压到下一层,组成新的 Minor SSTable。 | 2 |
创建 sysbench 租户
create resource unit sysbench_unit max_cpu 26, memory_size '21g';create resource pool sysbench_pool unit = 'sysbench_unit', unit_num = 1, zone_list=('zone1');create tenant sysbench_tenant resource_pool_list=('sysbench_pool'), charset=utf8mb4, zone_list=('zone1'), primary_zone=RANDOM set variables ob_compatibility_mode='mysql', ob_tcp_invited_nodes='%';
2. 数据预备
创建 30 张 100 万行数据的表。
sysbench ./oltp_read_only.lua --mysql-host=10.186.16.122 --mysql-port=12881 --mysql-db=sysbenchdb --mysql-user="sysbench@sysbench_tenant" --mysql-password=sysbench --tables=30 --table_size=1000000 --threads=256 --time=60 --report-interval=10 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 prepare3. 环境调优
手动触发大合并
ALTER SYSTEM MAJOR FREEZE TENANT=ALL;# 查看合并进度SELECT * FROM oceanbase.CDB_OB_ZONE_MAJOR_COMPACTION\G
数据更新前的纯读 QPS
sysbench ./oltp_read_only.lua --mysql-host=10.186.16.122 --mysql-port=12881 --mysql-db=sysbenchdb --mysql-user="sysbench@sysbench_tenant" --mysql-password=sysbench --tables=30 --table_size=1000000 --threads=256 --time=60 --report-interval=10 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 runread_only 的 QPS 表现如下:
| 第一次 | 第二次 | 第三次 | 第四次 | 第五次 |
|---|---|---|---|---|
| 344727.36 | 325128.58 | 353141.76 | 330873.54 | 340936.48 |
数据更新后的纯读 QPS
执行三次 write_only 脚本,其中包括了 update/delete/insert 操作,命令如下:
sysbench ./oltp_write_only.lua --mysql-host=10.186.16.122 --mysql-port=12881 --mysql-db=sysbenchdb --mysql-user="sysbench@sysbench_tenant" --mysql-password=sysbench --tables=30 --table_size=1000000 --threads=256 --time=60 --report-interval=10 --db-driver=mysql --db-ps-mode=disable --skip-trx=on --mysql-ignore-errors=6002,6004,4012,2013,4016,1062 run再执行 read_only 的 QPS 表现如下:
| 第一次 | 第二次 | 第三次 | 第四次 | 第五次 |
|---|---|---|---|---|
| 170718.07 | 175209.29 | 173451.38 | 169685.38 | 166640.62 |
数据做一次大合并后纯读 QPS
手动触发大合并,执行命令:
ALTER SYSTEM MAJOR FREEZE TENANT=ALL;# 查看合并进度SELECT * FROM oceanbase.CDB_OB_ZONE_MAJOR_COMPACTION\G
再次执行 read_only ,QPS 表现如下,可以看到读的 QPS 恢复至初始水平。
| 第一次 | 第二次 | 第三次 | 第四次 | 第五次 |
|---|---|---|---|---|
| 325864.95 | 354866.82 | 331337.10 | 326113.78 | 340183.18 |
4. 现象总结
对比数据更新前后的纯读 QPS,发现在做过批量更新操作后,读性能下降 17W 左右,做一次大合并后性能又可以提升回来。

排查过程
手法1:火焰图
火焰图差异对比
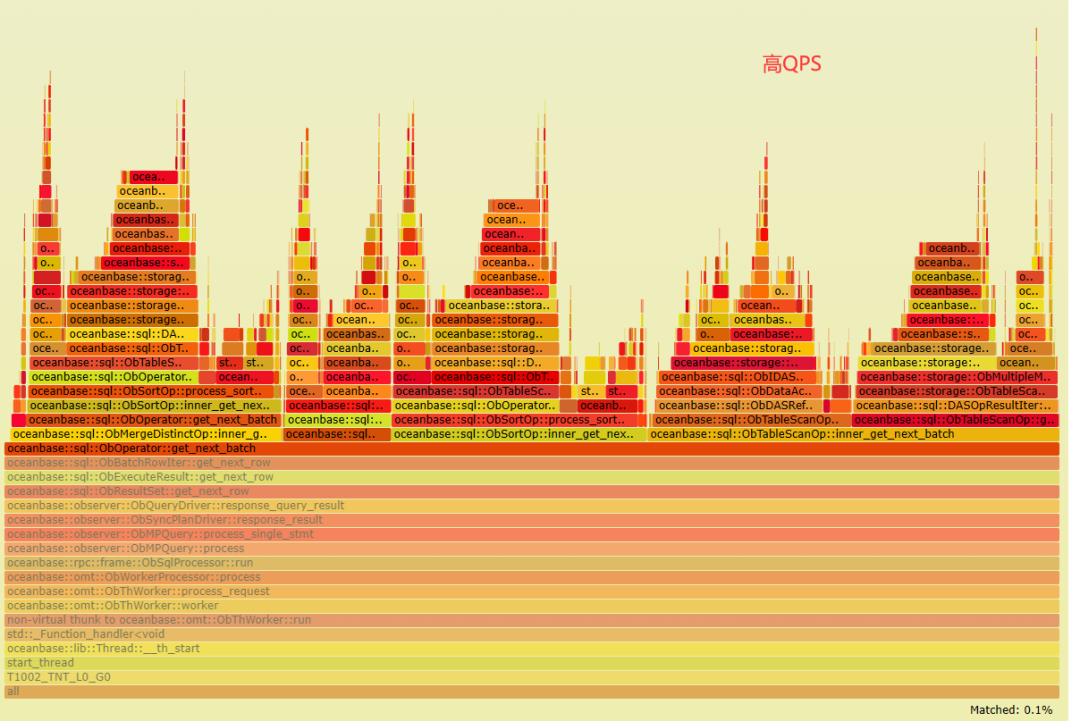
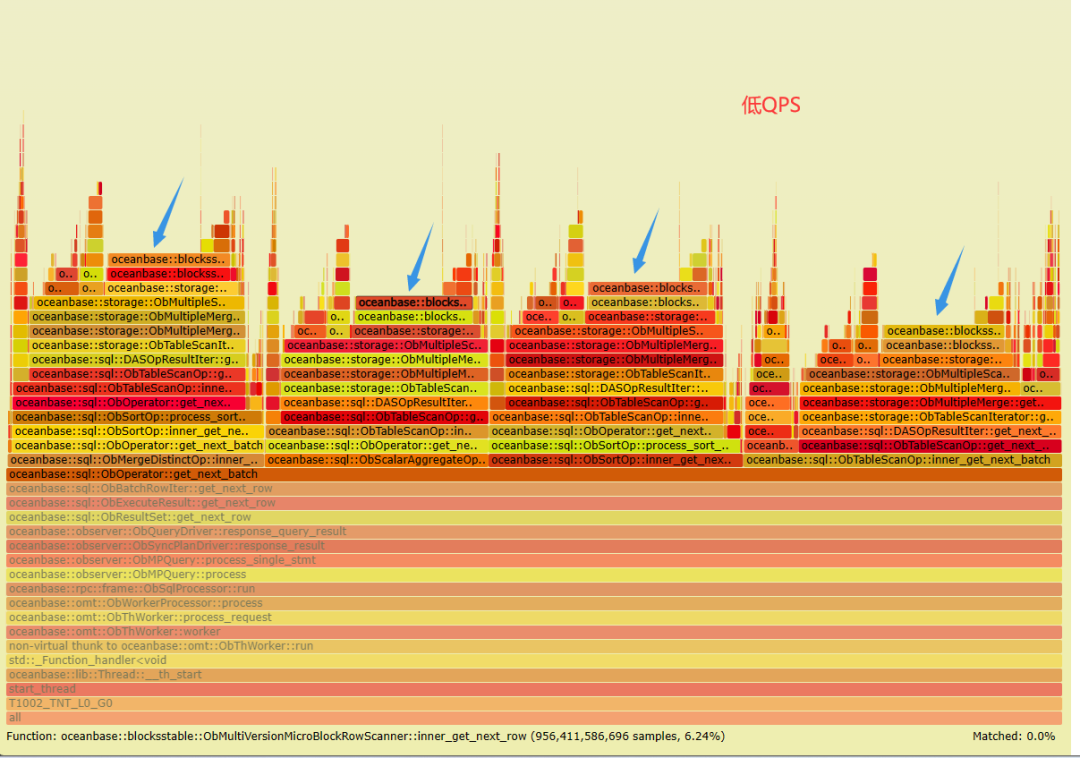
收集数据更新前后进行压测时的火焰图,对比的不同点集中在下面标注的蓝框中。
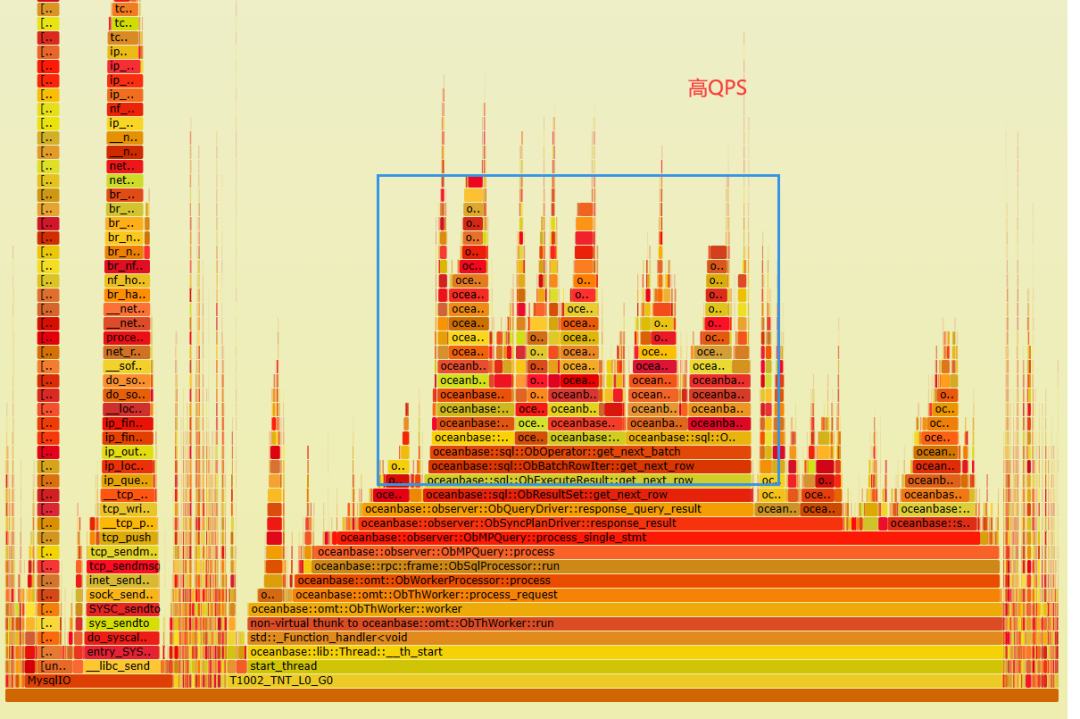
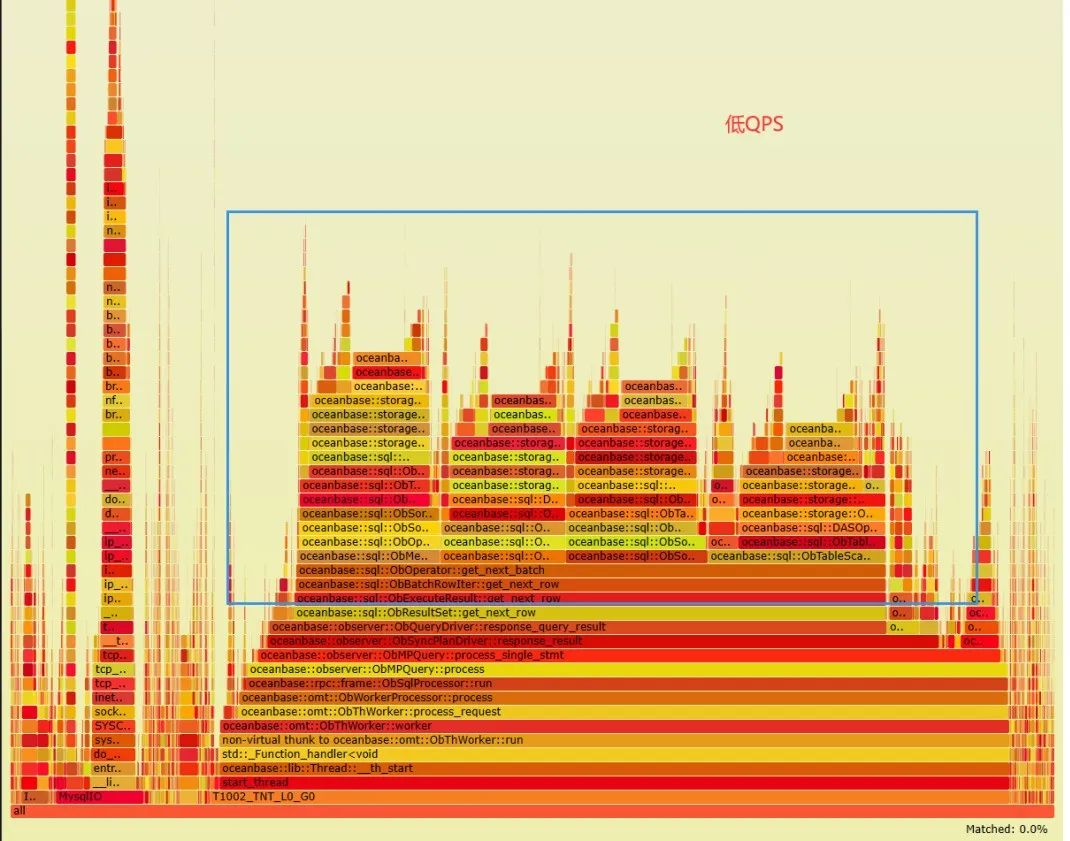
放大到方法里进一步查看,发现低 QPS 火焰图顶部多了几个 '平台',指向同一个方法 oceanbase::blocksstable::ObMultiVersionMicroBlockRowScanner::inner_get_next_row。
查看源码
火焰图中指向的方法,会进一步调用 ObMultiVersionMicroBlockRowScanner::inner_get_next_row_impl。后者的主要作用是借嵌套 while 循环进行多版本数据行的读取,并将符合条件的行合并融合(do_compact 中会调用 fuse_row),返回一个合并后的行(ret_row)作为最终结果,源码如下:
int ObMultiVersionMicroBlockRowScanner::inner_get_next_row_impl(const ObDatumRow *&ret_row){int ret = OB_SUCCESS;// TRUE:For the multi-version row of the current rowkey, when there is no row to be read in this micro_blockbool final_result = false;// TRUE:For reverse scanning, if this micro_block has the last row of the previous rowkeybool found_first_row = false;bool have_uncommited_row = false;const ObDatumRow *multi_version_row = NULL;ret_row = NULL;while (OB_SUCC(ret)) {final_result = false;found_first_row = false;// 定位到当前要读取的位置if (OB_FAIL(locate_cursor_to_read(found_first_row))) {if (OB_UNLIKELY(OB_ITER_END != ret)) {LOG_WARN("failed to locate cursor to read", K(ret), K_(macro_id));}}LOG_DEBUG("locate cursor to read", K(ret), K(finish_scanning_cur_rowkey_),K(found_first_row), K(current_), K(reserved_pos_), K(last_), K_(macro_id));while (OB_SUCC(ret)) {multi_version_row = NULL;bool version_fit = false;// 读取下一行if (read_row_direct_flag_) {if (OB_FAIL(inner_get_next_row_directly(multi_version_row, version_fit, final_result))) {if (OB_UNLIKELY(OB_ITER_END != ret)) {LOG_WARN("failed to inner get next row directly", K(ret), K_(macro_id));}}} else if (OB_FAIL(inner_inner_get_next_row(multi_version_row, version_fit, final_result, have_uncommited_row))) {if (OB_UNLIKELY(OB_ITER_END != ret)) {LOG_WARN("failed to inner get next row", K(ret), K_(macro_id));}}if (OB_SUCC(ret)) {// 如果读取到的行版本不匹配,则不进行任何操作if (!version_fit) {// do nothing}// 如果匹配,则进行合并融合else if (OB_FAIL(do_compact(multi_version_row, row_, final_result))) {LOG_WARN("failed to do compact", K(ret));} else {// 记录物理读取次数if (OB_NOT_NULL(context_)) {++context_->table_store_stat_.physical_read_cnt_;}if (have_uncommited_row) {row_.set_have_uncommited_row();}}}LOG_DEBUG("do compact", K(ret), K(current_), K(version_fit), K(final_result), K(finish_scanning_cur_rowkey_),"cur_row", is_row_empty(row_) ? "empty" : to_cstring(row_),"multi_version_row", to_cstring(multi_version_row), K_(macro_id));// 该行多版本如果在当前微块已经全部读取完毕,就将当前微块的行缓存并跳出内层循环if ((OB_SUCC(ret) && final_result) || OB_ITER_END == ret) {ret = OB_SUCCESS;if (OB_FAIL(cache_cur_micro_row(found_first_row, final_result))) {LOG_WARN("failed to cache cur micro row", K(ret), K_(macro_id));}LOG_DEBUG("cache cur micro row", K(ret), K(finish_scanning_cur_rowkey_),"cur_row", is_row_empty(row_) ? "empty" : to_cstring(row_),"prev_row", is_row_empty(prev_micro_row_) ? "empty" : to_cstring(prev_micro_row_),K_(macro_id));break;}}// 结束扫描,将最终结果放到ret_row,跳出外层循环。if (OB_SUCC(ret) && finish_scanning_cur_rowkey_) {if (!is_row_empty(prev_micro_row_)) {ret_row = &prev_micro_row_;} else if (!is_row_empty(row_)) {ret_row = &row_;}// If row is NULL, means no multi_version row of current rowkey in [base_version, snapshot_version) rangeif (NULL != ret_row) {(const_cast<ObDatumRow *>(ret_row))->mvcc_row_flag_.set_uncommitted_row(false);const_cast<ObDatumRow *>(ret_row)->trans_id_.reset();break;}}}if (OB_NOT_NULL(ret_row)) {if (!ret_row->is_valid()) {LOG_ERROR("row is invalid", KPC(ret_row));} else {LOG_DEBUG("row is valid", KPC(ret_row));if (OB_NOT_NULL(context_)) {++context_->table_store_stat_.logical_read_cnt_;}}}return ret;}
分析
从火焰图来看,QPS 降低,消耗集中在对多版本数据行的处理上,也就是一行数据的频繁更新操作对应到存储引擎里是多条记录,查询的 SQL 在内部处理时,实际可能需要扫描的行数量可能远大于本身的行数。
手法2:分析 SQL 执行过程
通过 GV$OB_SQL_AUDIT 审计表,可以查看每次请求客户端来源、执行服务器信息、执行状态信息、等待事件以及执行各阶段耗时等。
GV$OB_SQL_AUDIT用法参考:https://www.oceanbase.com/docs/common-oceanbase-database-cn-10000000001699453
对比性能下降前后相同 SQL 的执行信息
由于本文场景没有实际的慢 SQL,这里选择在 GV$OB_SQL_AUDIT 中,根据 SQL 执行耗时(elapsed_time)筛出 TOP10,取一条进行排查:SELECT c FROM sbtest% WHERE id BETWEEN ? AND ? ORDER BY c 。
执行更新操作前(也就是高 QPS 时):
MySQL [oceanbase]> select TRACE_ID,TENANT_NAME,USER_NAME,DB_NAME,QUERY_SQL,RETURN_ROWS,IS_HIT_PLAN,ELAPSED_TIME,EXECUTE_TIME,MEMSTORE_READ_ROW_COUNT,SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT from GV$OB_SQL_AUDIT where TRACE_ID='YB42AC110005-0005F9ADDCDF0240-0-0' \G*************************** 1. row ***************************TRACE_ID: YB42AC110005-0005F9ADDCDF0240-0-0TENANT_NAME: sysbench_tenantUSER_NAME: sysbenchDB_NAME: sysbenchdbQUERY_SQL: SELECT c FROM sbtest20 WHERE id BETWEEN 498915 AND 499014 ORDER BY cPLAN_ID: 10776RETURN_ROWS: 100IS_HIT_PLAN: 1ELAPSED_TIME: 16037EXECUTE_TIME: 15764MEMSTORE_READ_ROW_COUNT: 0SSSTORE_READ_ROW_COUNT: 100DATA_BLOCK_READ_CNT: 2DATA_BLOCK_CACHE_HIT: 2INDEX_BLOCK_READ_CNT: 2INDEX_BLOCK_CACHE_HIT: 11 row in set (0.255 sec)
执行更新操作后(低 QPS 值时):
MySQL [oceanbase]> select TRACE_ID,TENANT_NAME,USER_NAME,DB_NAME,QUERY_SQL,RETURN_ROWS,IS_HIT_PLAN,ELAPSED_TIME,EXECUTE_TIME,MEMSTORE_READ_ROW_COUNT,SSSTORE_READ_ROW_COUNT,DATA_BLOCK_READ_CNT,DATA_BLOCK_CACHE_HIT,INDEX_BLOCK_READ_CNT,INDEX_BLOCK_CACHE_HIT from GV$OB_SQL_AUDIT where TRACE_ID='YB42AC110005-0005F9ADE2E77EC0-0-0' \G*************************** 1. row ***************************TRACE_ID: YB42AC110005-0005F9ADE2E77EC0-0-0TENANT_NAME: sysbench_tenantUSER_NAME: sysbenchDB_NAME: sysbenchdbQUERY_SQL: SELECT c FROM sbtest7 WHERE id BETWEEN 501338 AND 501437 ORDER BY cPLAN_ID: 10848RETURN_ROWS: 100IS_HIT_PLAN: 1ELAPSED_TIME: 36960EXECUTE_TIME: 36828MEMSTORE_READ_ROW_COUNT: 33SSSTORE_READ_ROW_COUNT: 200DATA_BLOCK_READ_CNT: 63DATA_BLOCK_CACHE_HIT: 63INDEX_BLOCK_READ_CNT: 6INDEX_BLOCK_CACHE_HIT: 41 row in set (0.351 sec)
分析
上面查询结果显示字段 IS_HIT_PLAN 的值为 1,说明 SQL 命中了执行计划缓存,没有走物理生成执行计划的路径。我们根据 PLAN_ID 进一步到 V$OB_PLAN_CACHE_PLAN_EXPLAIN 查看物理执行计划(数据更新前后执行计划相同,下面仅列出数据更新后的执行计划)。
注:访问 V$OB_PLAN_CACHE_PLAN_EXPLAIN,必须给定 tenant_id 和 plan_id 的值,否则系统将返回空集。
MySQceanbase]> SELECT * FROM V$OB_PLAN_CACHE_PLAN_EXPLAIN WHERE tenant_id = 1002 AND plan_id=10848 \G*************************** 1. row ***************************TENANT_ID: 1002SVR_IP: 172.17.0.5SVR_PORT: 2882PLAN_ID: 10848PLAN_DEPTH: 0PLAN_LINE_ID: 0OPERATOR: PHY_SORTNAME: NULLROWS: 100COST: 51PROPERTY: NULL*************************** 2. row ***************************TENANT_ID: 1002SVR_IP: 172.17.0.5SVR_PORT: 2882PLAN_ID: 10848PLAN_DEPTH: 1PLAN_LINE_ID: 1OPERATOR: PHY_TABLE_SCANNAME: sbtest20ROWS: 100COST: 6PROPERTY: table_rows:1000000, physical_range_rows:100, logical_range_rows:100, index_back_rows:0, output_rows:100, est_method:local_storage, avaiable_index_name[sbtest20], pruned_index_name[k_20], estimation info[table_id:500294, (table_type:12, version:-1--1--1, logical_rc:100, physical_rc:100)]2 rows in set (0.001 sec)
从 V$OB_PLAN_CACHE_PLAN_EXPLAIN 查询结果看,执行计划涉及两个算子:范围扫描算子 PHY_TABLE_SCAN 和排序算子 PHY_SORT。根据范围扫描算子 PHY_TABLE_SCAN 中的 PROPERTY 信息,可以看出该算子使用的是主键索引,不涉及回表,行数为 100。综上来看,该 SQL 的执行计划正确且已是最优,没有调整的空间。
再对比两次性能压测下 GV$OB_SQL_AUDIT 表,当性能下降后,MEMSTORE_READ_ROW_COUNT(MemStore 中读的行数)和 SSSTORE_READ_ROW_COUNT (SSSTORE 中读的行数)加起来读的总行数为 233,是实际返回行数的两倍多。符合上面观察到的火焰图上的问题,即实际读的行数大于本身的行数,该处消耗了系统更多的资源,导致性能下降。

结论
OceanBase 数据库的存储引擎基于 LSM-Tree 架构,以基线加增量的方式进行存储,当在一个表中进行大量的插入、删除、更新操作后,查询每一行数据的时候需要根据版本从新到旧遍历所有的 MemTable 以及 SSTable,将每个 Table 中对应主键的数据融合在一起返回,此时表现出来的就是查询性能明显下降,即读放大。
性能改善方式
对于已经运行在线上的 buffer 表问题,官方文档中给出的应急处理方案如下:
-
对于存在可用索引,但 OceanBase 优化器计划生成为全表扫描的场景。需要进行执行计划 binding 来固定计划。
-
如果 SQL 查询的主要过滤字段无可用索引,此时推荐在线创建可用索引并绑定该计划。
-
如果业务场景暂时无法创建索引,或者执行的 SQL 多为范围扫描,此时可根据业务场景需要决定是否手动触发合并,将删除或更新的数据版本进行清理,降低全表扫描的数据量,提升速度。
另外,从 2.2.7 版本开始,OceanBase 引入了 buffer minor merge 设计,实现对 Queuing 表的特殊转储机制,彻底解决无效扫描问题,通过将表的模式设置为 queuing 来开启。对于设计阶段已经明确的 Queuing 表场景,推荐开启该特性作为长期解决方案。
ALTER TABLE table_name TABLE_MODE = 'queuing';但是社区版 4.0.0.0 的发布记录中看到,不再支持 Queuing 表。后查询社区有解释:OceanBase 在 4.x 版本(预计 4.1 完成)采用自适应的方式支持 Queuing 表的这种场景,不需要再人为指定,也就是 Release Note 中提到的不再支持 Queuing 表。
参考资料:
1. 《Queuing 表查询缓慢问题》
https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000945692
2. 《大批量数据处理后访问慢问题处理》
https://ask.oceanbase.com/t/topic/35602375
3. 《OceanBase Queuing 表(buffer 表)处理最佳实践》
https://open.oceanbase.com/blog/2239494400
4. 《ob4.0 确定不支持 Queuing 表了吗?》
https://ask.oceanbase.com/t/topic/35601606