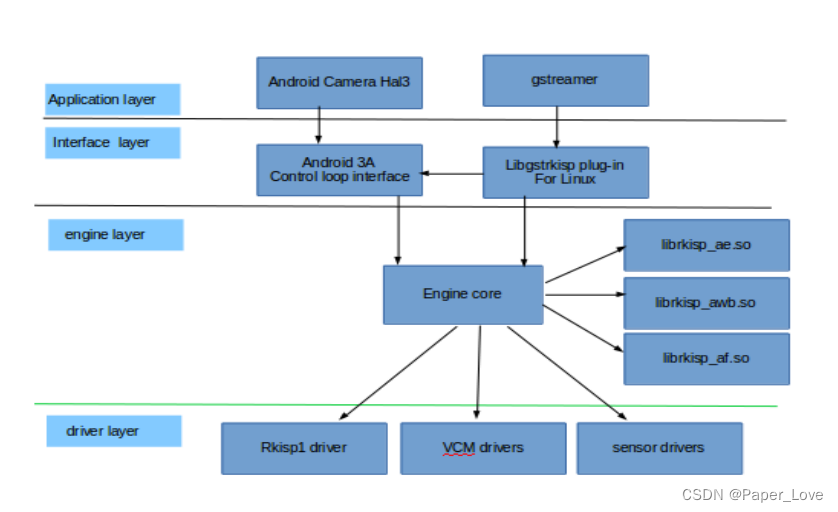
多路转接和高级IO
咳咳,写的时候出了点问题,标点符号全乱了(批量替换了几次),干脆就把全文的逗号和句号都改成英文的了(不然代码块里面的代码都是中文标点就跑不动了)
1.高级IO
1.1 五种IO模型
用钓鱼佬的栗子, 来看看五种不同的IO模型吧
- A, 拿着鱼竿去钓鱼, 一直盯着鱼漂, 鱼漂有动静就收钩
- B, 拿着鱼竿去钓鱼, 时不时看看鱼漂, 有动静就收购
- C, 拿着鱼竿去钓鱼, 在鱼漂上弄个铃铛, 然后干其他的事情, 听到铃铛的声音就收钩
- D, 拿了一大堆鱼竿过来, 都摆弄好, 只要有一个鱼漂有动静, 就收钩
- E是大老板, 直接叫人帮忙钓鱼, 钓到一定数量的🐟后通知自己, 自己过来取🐟(没有参与钓鱼过程)
这五种钓鱼方式, 就对应了五种IO模型
- A, 阻塞等待, 等待到数据就立即读取
- B, 轮询检测, 检测到数据的时候读取
- C, 利用铃铛来作为通知方式, 听到了信号之后, 就去读取数据(信号驱动)
- D, 一次性检测多个文件描述符(多路转接)
- E, 没有自己参与钓鱼过程, 有别人帮忙监控文件描述符, 自己只关心拿走数据(异步IO)
在这五种IO模式中, D的效率是最高的。因为它一次性监控了多个文件描述符, 这些文件描述符的IO在一定程度上重合了, 更容易等到数据。
要知道, D是过来钓鱼的, 他只要能钓到鱼就够了, 并不用关心到底是哪个鱼钩钓上来的鱼。同理, 我们的IO服务器也并不需要关心到底是哪个文件描述符在给自己传递信息, 我们只要每时每刻都在处理信息(都能钓到鱼)才是最高效率的体现。
换句话说, 在钓鱼(处理IO)的时候, 等的时间比例越低, 效率越高!
1.2 阻塞和非阻塞
这两个概念我们在先前对IO的学习中已经见过了
- 阻塞:进程会在函数调用中卡住, 在没有成功调用之前不会继续向后运行
- 非阻塞:不管能否获取到数据, 函数都是直接返回结果;
1.3 异步与同步通信
- 异步通信:在调用发出后, 这个调用直接返回, 并没有携带结果;类似
std::async/future, 在调用发出后, 被调用着通过状态或通知来告知调用者, 亦或者是用回调函数来处理这个异步调用 - 同步通信:在发出调用后, 没有得到结果前, 该调用不返回;一旦返回就表明该调用成功获取到了返回值(调用者主动等待调用结果)
这里的同步和线程/进程同步并不是一个概念:
- 线程和进程的同步指的是线程和进程之间有相互制约的关系, 需要在某些情况中协调他们的工作次序而进行等待
了解完IO模型和上方的知识后, 下面就让我们来认识一下第一个接口吧!
2.fcntl
这个是一个系统调用, 可以给文件描述符进行不同的策略设置。
当我们在linux中创建一个文件描述符的时候, 默认创建的都是阻塞的文件描述符。我们可以使用fcntl来将文件描述符设置成非阻塞的。
2.1 接口
该函数的原型如下
#include <unistd.h>#include <fcntl.h>int fcntl(int fd, int cmd, ... /* arg */ );
其中cmd是我们需要执行的策略, 下面是常见的几种选项
- 复制一个现有的描述符(cmd=F_DUPFD)
- 获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD)
- 获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)
- 获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)
- 获得/设置记录锁(cmd=F_GETLK, F_SETLK或F_SETLKW)
这里我们使用的是第三个功能, 来获取和设置文件的状态标记, 就可以将文件描述符设置为非阻塞(这里要注意, 不是用第二种)
2.2 设置非阻塞
我们需要先将文件描述符原本的属性给取出来, 然后再加上非阻塞的状态, 使用fcntl设置属性。
void SetNoBlock(int fd)
{ int fl = fcntl(fd, F_GETFL); // 先获取文件已有状态if (fl < 0) { perror("fcntl error");return;}// 在已有状态的基础上, 设置O_NONBLOCK非阻塞fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}
2.3 stdin测试
然后, 我们还需要一个会出现阻塞的文件描述符来作为测试。但是, 如果是直接打开一个本地文件, 并不会出现阻塞态(因为文件流会被一次性读取出来)
不过, 在我们最常用的3个默认文件描述符中, 就有一个是能够实现进程阻塞的, 它就是stdin, 因为在控制台里面等待用户输入的时候, 进程就是处于阻塞状态的!
$ ./test
请输入:
所以我们就可以尝试将stdin设置为非阻塞, 来观察一下结果
int main()
{SetNoBlock(stdin->_fileno);char buf[1024];while(true){ssize_t read_size = read(stdin->_fileno, buf, sizeof(buf) - 1);if(read_size < 0){perror("read err");sleep(2);continue;}printf("input:%s\n", buf);buf[0] = '\0';}return 0;
}
编译运行, 当没有读取到输入内容的时候, 并不会在stdin中阻塞, 而是会通过perror打印出资源暂时不可用的警告信息。
$ ./test
read err: Resource temporarily unavailable
asdlfjklaf
input:asdlfjklafread err: Resource temporarily unavailable
adslfkjaldfjklasjfa
input:adslfkjaldfjklasjfa
a
read err: Resource temporarily unavailable
ewqrqreqqrwer
input:ewqrqreqqrwer
asjfa
a
read err: Resource temporarily unavailable
qweioruqoruioqewur
input:qweioruqoruioqewura
read err: Resource temporarily unavailable
weqioruqoieuotqitqwertq
input:weqioruqoieuotqitqwertq
����a
read err: Resource temporarily unavailable
^C
3.多路转接之select
接下来就要进入我们的正题了, 关于多路转接的知识。
在之前的时候, 我们如果想在一个进程里面维护多个tcp链接, 就需要用到子线程或者子进程来单独为每一个用户提供服务。但一个进程可以开的线程是有数量限制的, 在32位系统中, 这个数字大概是2000。
对于一个高并发的服务器来说, 这点线程数是完全不够用的!如果你的网站一次性有2000个人访问, 你的服务器就会因为开不出更多的线程而无法为更多的用户提供服务!
所以, 多路转接就出现了, 他能帮我们实现单个进程监控多个文件描述符, 同时为多个socket链接提供服务的操作!
普通的本地文件描述符也是可以托管给多路转接的!
3.1 认识select
select的函数原型和我们之前接触过的linux系统调用接口都不大相似, 它的所有参数都是输入输出型参数, 而且还用到了一个我们平时较少接触的数据结构——位图
/* According to POSIX.1-2001, POSIX.1-2008 */#include <sys/select.h>int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
先来依次说明一下每一个参数的作用吧
nfds:需要select帮我们监视的最大文件描述符+1readfds/writefds/exceptfds, 需要select帮我们检测的读/写/异常文件描述符(通过位图来设定)timeout:阻塞监控的时长, 用来设置select单次阻塞等待的时间
3.1.1 timeval
首先来看看timeout的这个参数的struct timeval结构体框架, 内部包含两个成员变量, 一个表示秒数, 一个表示微秒数。最终select等待的时间是这两个参数的和
struct timeval {long tv_sec; /* seconds */long tv_usec; /* microseconds */
};
- 如果设置成0, 则仅检测文件描述符的状态, 不管什么情况都会立即返回(完全非阻塞)
- 如果设置成指定的时间, 则会阻塞等待这端时间, 如果有文件事件则返回;如果没有等到文件时间, 那么时间到了就会返回
- 如果将
timeout参数设置成nullptr, 则会阻塞等待
这个参数也是一个输入输出型参数, 返回值为剩余的秒数(如果等待成功的话)
3.1.2 fd_set
函数中有3个参数都是用到了这个fd_set结构, 它是一个位图结构, 同时也是一个输入输出参数
- 输入:用户告诉操作系统, 需要帮我监控那几个文件描述符, 在需要监控的文件描述符上置1
- 输出:系统告诉用户, 那些文件描述符的相关事件就绪了
虽然这是一个位图结构, 但其并不需要我们手动去设置, 操作系统顺便帮我们封装了相关的设置“函数”, 只需要传入fd和该结构体即可
void FD_CLR(int fd, fd_set *set); // 清空位图中对该文件描述符的设置
int FD_ISSET(int fd, fd_set *set);// 判断是否被设置了
void FD_SET(int fd, fd_set *set); // 设置对应位置的文件描述符
void FD_ZERO(fd_set *set); // 清空整个位图
你可能回觉得奇怪, 为什么这些“函数”是大写的呢?Linux中大写的应该是宏才对吧?
答对了!这里的设置函数其实都是宏定义!
/* Access macros for `fd_set'. */
#define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp)
#define FD_CLR(fd, fdsetp) __FD_CLR (fd, fdsetp)
#define FD_ISSET(fd, fdsetp) __FD_ISSET (fd, fdsetp)
#define FD_ZERO(fdsetp) __FD_ZERO (fdsetp)
既然是一个预定义好的位图, 那么它的长度就会收到操作系统底层的一定限制, 以下为源代码中fd_set结构体的定义
// 路径 usr/include/sys/select.h
/* The fd_set member is required to be an array of longs. */
typedef long int __fd_mask;/* Some versions of <linux/posix_types.h> define this macros. */
#undef __NFDBITS
/* It's easier to assume 8-bit bytes than to get CHAR_BIT. */
#define __NFDBITS (8 * (int) sizeof (__fd_mask))
#define __FD_ELT(d) ((d) / __NFDBITS)
#define __FD_MASK(d) ((__fd_mask) (1UL << ((d) % __NFDBITS)))/* fd_set for select and pselect. */
typedef struct{/* XPG4.2 requires this member name. Otherwise avoid the namefrom the global namespace. */
#ifdef __USE_XOPEN__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->fds_bits)
#else__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->__fds_bits)
#endif} fd_set;
在另外一个头文件中, 可以找到__FD_SETSIZE这个宏的定义, 是1024;也就是说, fd_set这个位图最大的长度只有1024个比特位, 我们也只能监看这么多文件描述符!
// 路径 usr/include/bits/typesizes.h
/* Number of descriptors that can fit in an `fd_set'. */
#define __FD_SETSIZE 1024
这也是select的缺点之一, 同时监看的文件描述符数量是有限制的!
3.1.3 nfds
这个参数是select需要帮我们监看的最大文件描述符+1, 这是因为select在监看的过程中需要用循环来进行检测, 这个最大文件描述符+1相当于是一个循环的边界条件;
你只需根据当前已有的文件描述符号, 计算出最大文件描述符, 再加一传给这个函数即可。
3.1.4 返回值
man手册中对返回值的描述如下
- 成功的时候, 返回事件就绪的文件描述符数量
- 失败的时候返回
-1, 并设置errno - 如果已经
timeout了还没有事件就绪, 返回0
RETURN VALUEOn success, select() and pselect() return the number of file descriptors contained in the three returned descriptor sets (that is, the total number of bits that are set in readfds, writefds, exceptfds) which may be zero if the timeout expires before anything interesting happens. On error, -1 is returned, and errno is set to indicate the error; the file descriptor sets are unmodified, and timeout becomes undefined.
3.2 实例
函数原型看完了, 得从实例出发来试试了
3.2.1 socket
这里先对socket做了一个简单的封装, 包括初始化, 绑定相关的接口, 只需要在另外一个文件里面调用这个头文件即可 !
//Sock.hpp
#pragma once#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <cstdio>
#include <cstring>
#include <signal.h>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/stat.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <pthread.h>
#include <cerrno>
#include <cassert>class Sock
{
public:static const int gbacklog = 20;static int SocketInit(){int listenSock = socket(PF_INET, SOCK_STREAM, 0);if (listenSock < 0){exit(1);}// 设置端口复用, 避免timewait阻塞端口int opt = 1;setsockopt(listenSock, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));return listenSock;}static void Bind(int socket, uint16_t port){struct sockaddr_in local; // 用户栈memset(&local, 0, sizeof local);local.sin_family = PF_INET;local.sin_port = htons(port);local.sin_addr.s_addr = INADDR_ANY;// 2.2 本地socket信息, 写入sock_对应的内核区域if (bind(socket, (const struct sockaddr *)&local, sizeof(local)) < 0){exit(2);}}static void Listen(int socket){if (listen(socket, gbacklog) < 0){exit(3);}}static int Accept(int socket, std::string *clientip, uint16_t *clientport){struct sockaddr_in peer;socklen_t len = sizeof(peer);int serviceSock = accept(socket, (struct sockaddr *)&peer, &len);if (serviceSock < 0){// 获取链接失败return -1;}if(clientport) *clientport = ntohs(peer.sin_port);if(clientip) *clientip = inet_ntoa(peer.sin_addr);return serviceSock;}
};
另外重点说明一下这两行, 在之前学习tcp服务器的时候就提到过, 这里的SO_REUSEADDR是让端口可以被复用, 不会因为存在TIME_WAIT的链接而无法绑定端口。适用于服务器快速重启的情况。
// 设置端口复用, 避免timewait阻塞端口
int opt = 1;
setsockopt(listenSock, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
3.2.2 初始化
还是老一套, 通过命令行参数获取到端口号, 创建socket_fd并绑定端口和开始listen
int main(int argc, char *argv[])
{if (argc != 2) {cmd_usage(argv[0]);exit(1);} // 初始化socket, 获取socket fd并绑定端口int listensock = Sock::SocketInit();Sock::Bind(listensock, atoi(argv[1]));Sock::Listen(listensock); // 开始监听
}
需要注意的是, 在select中的文件描述符都只剩位图了, 所以我们必须要有一个单独的文件描述符数组来协助我们管理正在维护的文件描述符。
这里为了方便, 我设立了一个全局的数组变量, 长度为sizeof(fd_set) * 8, 是fd_set这个位图结构体能够支持的最大socket数量
int fdsArray[sizeof(fd_set) * 8] = {0}; // 保存历史上所有的合法fd
int fdsArraySz = sizeof(fdsArray) / sizeof(fdsArray[0]);
#define DFL_FD -1 // 数组中默认值
在main函数中, 我们需要通过遍历来将这个数组设置为默认的文件描述符-1来表明当前位置没有被使用, 并将0下标处设置为listensock;如果你使用的是vector, 则可以直接用构造函数来初始化;
// 将数组里面的文件描述符都初始化为默认值, 并将第一个下标设置为listensocket
for (int i = 0; i < fdsArraySz; i++){fdsArray[i] = DFL_FD;
}
fdsArray[0] = listensock;
3.2.3 监听
初始化完毕数组后, 就可以开始循环调用select来进行监听了。
需要注意的是, 因为select的fd_set是一个位图, 而且是输入输出参数。每次的select调用之后, 这些位图就会被操作系统修改为已经就绪的文件描述符(即参数本身会被修改)所以我们下一次调用之前, 需要重新设置位图参数!
// 开始监听fd_set readfds;while(true){int maxFd = DFL_FD;FD_ZERO(&readfds); // 清空位图struct timeval timeout = {5, 0}; // 设置超时时间为5秒// 遍历全局数组, 将有效的fd都添加进去, 并更新maxfdfor (int i = 0; i < fdsArraySz; i++){ // 1. 过滤不合法的fdif (fdsArray[i] == DFL_FD) continue; // 2. 添加所有的合法的fd到readfds中, 方便select统一进行就绪监听FD_SET(fdsArray[i], &readfds); if (maxFd < fdsArray[i]) {maxFd = fdsArray[i]; // 3. 更新出fd最大值}}// 调用select开始监听int sret = select(maxFd+1, &readfds, nullptr, nullptr, &timeout);switch (sret){case 0: // 等待超时cout << "time out ... : " << (unsigned long)time(nullptr) << endl;break;case -1:// 等待失败cerr << errno << " : " << strerror(errno) << endl;break;default:// 等待成功cout << "wait success: " << sret << endl;break;}}
基本框架搭起来了, 我们这时候就只需要实现等待成功后取出链接和IO信息的操作了;
先来测试一下当前的手脚架吧
3.2.4 手脚架测试
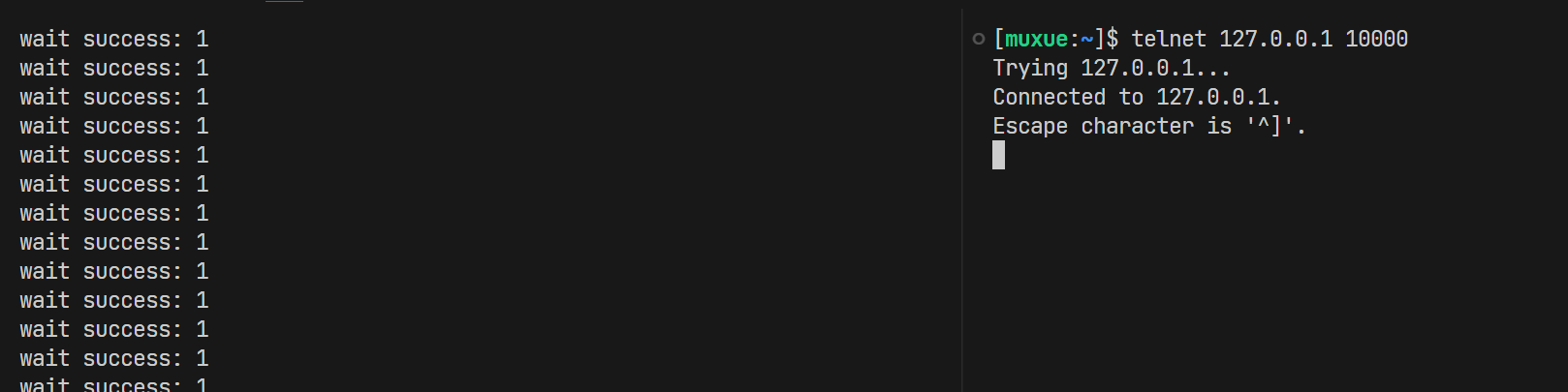
编译启动, 使用命令行参数来绑定端口, 在没有收到数据之前, 进程会在select中阻塞等待5秒, 随后因为超时跳出阻塞态, 返回0并打印当前时间戳
$ g++ main.cpp -o test
$ ./test 10000
time out ... : 1692955522
time out ... : 1692955527
time out ... : 1692955532
time out ... : 1692955537
time out ... : 1692955542使用telnet命令来链接当前服务, select检测到listensock文件描述符就绪, 会立刻返回(对于listensock来说, 来了新链接就是读IO就绪)但因为我们没有写取走新socket的代码, 所以这里会一直打印事件就绪;
返回值为1, 代表有一个文件描述符的事件就绪。
3.2.5 处理新连接
在select事件就绪后, 使用如下函数来处理新的链接
static void HandlerEvent(int listensock, fd_set &readfds);
这里额外写了一个打印数组中元素的函数, 方便我们观察结果。
/// @brief 打印数组中的文件描述符
static void ShowArray(int arr[], int num)
{cout << "当前合法sock list: ";for (int i = 0; i < num; i++){if (arr[i] == DFL_FD )continue;elsecout << arr[i] << " ";}cout << endl;
}
首先我们需要遍历整个链接数组, 并判断当前位置是否是有效的文件描述符。无效直接跳过。
for (int i = 0; i < fdsArraySz; i++){if (fdsArray[i] == DFL_FD)continue;// 处理新连接和已有链接}
遍历的时候, 我们需要对listensock做单独的处理, 毕竟获取新连接和维护已有链接的流程是完全不同的。下面说说流程
- 判断是否有在select中监听该文件描述符
- 有监听, 继续往后执行, 开始进行
accept获取新的链接 - 获取失败, 直接跳出该函数, 结束该轮处理
- 获取成功, 不能直接read/write, 而是应该通过数组交付给select帮我们监听事件
- 下一轮循环中, select便会帮我们监听该新链接的事件是否就绪
因为走到这里的时候, 我们的listensocket里面是一定有新连接的, 所以对accept的调用是不会阻塞线程的!
if (i == 0 && fdsArray[i] == listensock)
{// 判断listensocket有没有事件监听if (!FD_ISSET(listensock, &readfds)){cerr << "listensocket not set in readfds" << endl;continue;}// 具有了一个新链接cout << "get new connection" << endl;string clientip;uint16_t clientport = 0;int sock = Sock::Accept(listensock, &clientip, &clientport); // 不会阻塞if (sock < 0)return; // 出错了, 直接返回// 成功获取新连接cout << "new conn:" << clientip << ":" << clientport << " | sock: " << sock << endl;// 这里我们不能直接对这个socket进行独写, 因为新链接来了并不代表新数据一并过来了// 所以需要将新的文件描述符利用全局数组, 交付给select// select 帮我们监看socket上的读事件是否就绪int i = 0;for (i = 0; i < fdsArraySz; i++){if (fdsArray[i] == DFL_FD)break;}// 达到上限了if (i == fdsArraySz){cerr << "reach the maximum number of connections" << endl;close(sock);}else // 没有达到{fdsArray[i] = sock; // 新的链接, 插入到数组中, 下次遍历就会添加到select监看中ShowArray(fdsArray, fdsArraySz);}
}
3.2.6 处理已有链接
这里暂时只做了对读的操作, 当读事件就绪的时候, 我们通过read读取已有的数据。这里因为socket中肯定是有数据的, 所以也不会出现阻塞的情况。
// end if (i == 0 && fdsArray[i] == listensock)
else
{// 处理普通sock的IO事件if (FD_ISSET(fdsArray[i], &readfds)){// read、recv读取即可char buffer[1024];ssize_t s = recv(fdsArray[i], buffer, sizeof(buffer), 0); // 不会阻塞if (s > 0){buffer[s] = 0;cout << "client[" << fdsArray[i] << "]# " << buffer << endl;}else if (s == 0) // 对端关闭{cout << "client[" << fdsArray[i] << "] quit, server close " << fdsArray[i] << endl;close(fdsArray[i]);fdsArray[i] = DFL_FD; // 去除对该文件描述符的select事件监听ShowArray(fdsArray, fdsArraySz);}else // 异常了{cout << "client[" << fdsArray[i] << "] error, server close " << fdsArray[i] << endl;close(fdsArray[i]);fdsArray[i] = DFL_FD; // 去除对该文件描述符的select事件监听ShowArray(fdsArray, fdsArraySz);}}
}
这里我单次读取的时候, 最多只能读出1024字节的数据;如果想一次性读取完毕, 则需要使用循环+设置非阻塞来进行读取。后续在epoll的代码示例中会展示这种写法。
3.2.7 实测
到这里, 我们这套代码就基本完成了, 可以来测试一下能否实现单线程监听多个链接;
在本地使用telnet+多个终端进行测试, 可以看到我们成功实现了同时监听两个链接, 并接受这两个链接给自己发送的信息的功能。当telnet退出的时候, 也能成功回收文件描述符。
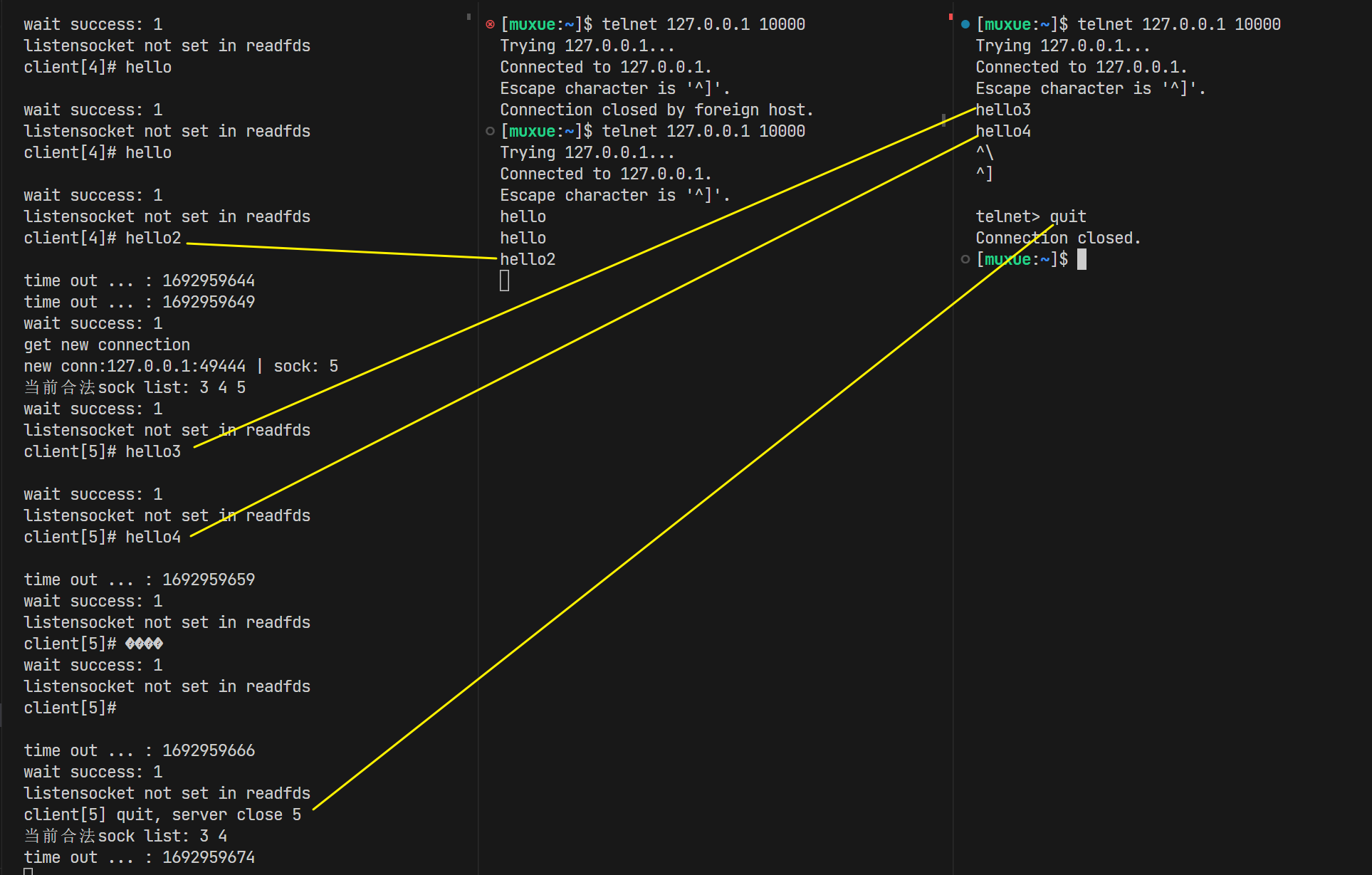
select的小实现暂时先看到这里, 如果想用select实现同时读+写, 其实是很复杂的。需要一套完整的逻辑。这就留着到最后epoll的时候再统一展现吧!
3.3 socket就绪条件
socket不同事件的就绪有各自的条件
3.3.1 读就绪
- socket内核中, 接收缓冲区中的字节数, 大于等于低水位标记
SO_RCVLOWAT, 此时可以无阻塞的读该文件描述符, 并且返回值大于0; - socket在TCP通信中, 对端关闭连接, 此时对该socket读, 则返回0;
- 监听的socket上有新的连接请求;
- socket上有未处理的错误;
3.3.2 写就绪
- socket内核中, 发送缓冲区中的可用字节数(发送缓冲区的空闲位置大小), 大于等于低水位标记
SO_SNDLOWAT, 此时可以无阻塞的写, 并且返回值大于0; - socket的写操作被关闭(close或者shutdown). 对一个写操作被关闭的socket进行写操作, 会触发
SIGPIPE信号; - socket使用非阻塞connect连接成功或失败之后;
- socket上有未读取的错误;
3.3.3 异常就绪
socket上收到带外数据(TCP报头中的URG和紧急指针)
3.4 select的特点
- 可监控的文件描述符有上限, 取决于
fd_set位图结构体的配置 - 在监控文件描述符的时候, 需要用户额外的数组来维护文件描述符
- 每次循环都得遍历整个数组, 效率较低(可以优化为保证有效文件描述符都在数组的前方)
一下是它在效率上的一些缺点
- 每次调用select都得手动设置一边fd集和(因为
fd_set也是输出型参数, 在内核中会被修改) - 每次调用select, 都需要把所有fd从用户态拷贝到内核态, 小陆地
- 每次调用, 内核都须遍历传递进来的位图, 效率低
- 监控的文件描述符有上限, 数量小
4.多路转接之poll
4.1 函数原型
接下来我们要了解的是另外一个多路转接方案, poll
#include <poll.h>int poll(struct pollfd *fds, nfds_t nfds, int timeout);
4.1.1 参数
这里的参数就和select完全不同了, 出现了另外一个结构体
struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */
};
这一个结构体分别包含了三个成员
- 文件描述符fd;
- 用户告诉内核需要监看的事件events;
- 内核返回的就绪事件revents;
但是从这个函数的参数上看来, 貌似它是一个只有一个元素的输入输出型参数, 难道说poll只能监看一个文件描述符吗?🧐
非也, 我们将函数原型改一下就能看明白了, 实际上, 第一个参数是一个结构体数组, 第二个参数是该结构体数组的长度!
int poll(struct pollfd fds[], nfds_t nfds, int timeout);
第三个参数和select中的timeout的功能相同, 如果到达一定时间还没有获取到参数, 则直接返回;如果设置为-1则阻塞等待, 设置为0为完全非阻塞。
这里的timeout并非输入输出型号参数, 其只是一个输入参数, 单位为毫秒(记住, 不是秒, 是毫秒)
4.1.2 返回值
- 小于0, 出错
- 等于0, 等待超时
- 大于0, 文件描述符已经就绪的数量
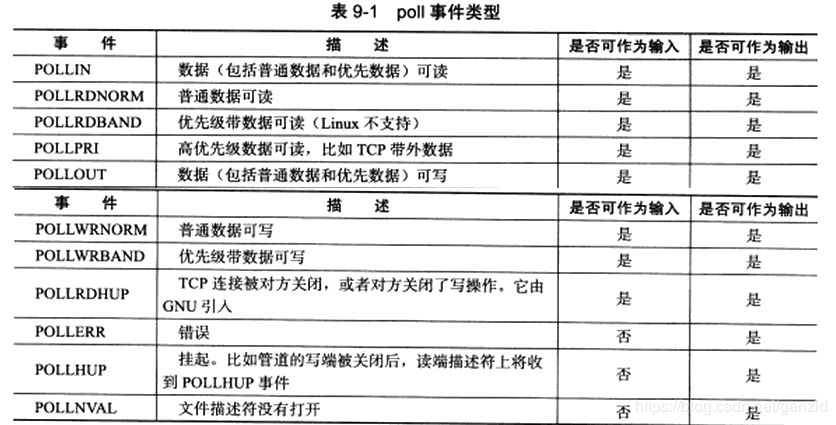
4.1.3 事件
这里需要了解一下poll包含的事件类型了, 我们需要根据不同情况来选择想要的事件, 并设置到结构体的event中;对于select/poll/epoll来说, 这些socket的就绪条件都是相同的。详见 3.3 socket就绪条件;
4.2 poll优缺点
4.2.1 优点
在poll中, 使用的是一个结构体数组来表示需要监听的文件描述符, 以及事件就绪的文件描述符
- 因为结构体中用户需要监听的event和内核返回的就绪event并不在一个变量上, 所以只需要设置一次即可(如果需求没有变动的话), 无需像select每次都得重新遍历来设置位图
- poll没有最大文件描述符限制
- poll无需用户额外维护一个单独的文件描述符数组, 直接沿用该结构体数组即可
4.2.2 缺点
- 和select一样, poll也需要轮询检测就绪的fd和相关事件
- 每次调用poll需要把pollfd结构体从用户态拷贝到内核态
- 虽然poll没有最大文件描述符限制, 但是监看的多了后性能会线性下降
4.3 看看示例代码
poll的代码部分的主机结构和select基本相同,这里我们主要来说一下不同的地方
#define NUM 1024
#define DFL_FD -1
struct pollfd fdsArray[NUM];
首先是全局的数组,这时候不需要自己维护一个int文件描述符数组了,直接使用这个结构体作为全局数组就OK了;在main函数里面还是老样子,我们得把整个数组的fd都设置成默认的fd作为标识
for (int i = 0; i < NUM; i++){fdsArray[i].fd = DFL_FD;fdsArray[i].events = 0;fdsArray[i].revents = 0;}fdsArray[0].fd = listensock;fdsArray[0].events = POLLIN;
在main函数的主循环中,也是用poll来依次监听事件,并判断poll函数的返回值
int timeout = 5;
while (true)
{int n = poll(fdsArray, NUM, timeout);switch (n){case 0:cout << "time out ... : " << (unsigned long)time(nullptr) << endl;break;case -1:cerr << errno << " : " << strerror(errno) << endl;break;default:HandlerEvent(listensock);break;}
}
在HandlerEvent函数中,我们通过判断结构体内部的revent来得知是否有事件就绪
if (fdsArray[i].revents & POLLIN){} // 读事件是否就绪
对于listensocket来说,就绪了就执行accept;并将新的文件描述符添加到数组中
int j = 0;for (j = 0; j < NUM; j++){if (fdsArray[j].fd == DFL_FD)break;}// 通过for循环找到当前位置是默认的结构体下标if (j == NUM) // 如果达到上限才break{cerr << "我的服务器已经到了最大的上限了,无法在承载更多同时保持的连接了" << endl;close(sock);}else{fdsArray[j].fd = sock; // 将sock添加到数组中fdsArray[j].events = POLLIN;fdsArray[j].revents = 0;ShowArray(fdsArray, NUM);}
对于其他链接来说,就绪了就开始read。如果read异常或者对端关闭,那就将对应位置的结构体全部初始化(清空),相当于将这个链接从监听中去掉!
fdsArray[i].fd = DFL_FD;
fdsArray[i].events = 0;
fdsArray[i].revents = 0;
其余的操作和select完全一致,在这里就不展示代码了!
5.epoll
man手册中提到, epoll是为了处理大量socket文件描述符句柄而进行了一定改进的poll;
5.1 接口
epoll就不是只有一个函数接口了, 而是有3个相关的函数,使用过程就是三部曲:
- epoll_create 创建epoll文件句柄
- epoll_ctl 将需要监控的文件描述符进行注册
- epoll_wait 等待文件描述符就绪
5.1.1 epoll_create
#include <sys/epoll.h>int epoll_create(int size);
int epoll_create1(int flags);
epoll在使用的时候, 我们需要用create函数创建一个epoll的句柄(本质上也是文件描述符), 来管理当前进程需要操作系统帮我们监看的文件描述符
- 自从
linux 2.6.8后, 这里的size参数是被胡咯的 - epoll的句柄在使用完毕后也需要用
close()函数关闭 - 错误的时候返回
-1并设置errno, 正确的时候返回文件描述符
5.1.2 epoll_ctl
该函数是对epoll中需要监看的文件描述符进行设置
#include <sys/epoll.h>int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- 第一个参数是
epoll_create的返回值 - 第二个参数是动作, 包含三个不同的选项
EPOLL_CTL_ADD:将新的文件描述符添加到epfd中EPOLL_CTL_MOD:修改已有文件描述符的监听事件EPOLL_CTL_DEL:删除已有文件描述符
- 第三个参数是目标文件描述符
- 第四个参数是一个
epoll_event结构体
这个结构体的定义如下
typedef union epoll_data {void *ptr;int fd;uint32_t u32;uint64_t u64;
} epoll_data_t;struct epoll_event {uint32_t events; /* Epoll events */epoll_data_t data; /* User data variable */
};
事件
事件events可以是下面的这些选项
| 事件 | 说明 |
|---|---|
| EPOLLIN | 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭); |
| EPOLLOUT | 表示对应的文件描述符可以写; |
| EPOLLPRI | 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来); |
| EPOLLERR | 表示对应的文件描述符发生错误; |
| EPOLLHUP | 表示对应的文件描述符被挂断; |
| EPOLLET | 将EPOLL设为边缘触发 (Edge Triggered)模式, 这是相对于水平触发(Level Triggered) 来说的; |
| EPOLLONESHOT | 只监听一次事件, 当监听完这次事件之后, 如果还需要继续监听这个socket的话, 需要手动再次把这个socket加入到EPOLL队列里; |
5.1.3 epoll_wait
#include <sys/epoll.h>int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
int epoll_pwait(int epfd, struct epoll_event *events, int maxevents, int timeout, const sigset_t *sigmask);
改函数的作用是收集在epoll监控的事件中,已经就绪的事件
- 第一个参数是epoll的文件描述符句柄
- 参数events是
epoll_events结构体数组,是一个输出型参数。epoll会将就绪的事件赋值到events数组里面; - maxevents 告诉内核这个events的大小,其不可以超过
epoll_create的size; - 参数timeout是超时时间,也是毫秒(0非阻塞,-1永久阻塞)
- 返回值:成功返回IO事件就绪的文件描述符数目,0代表超时,负数代表失败
5.2 工作原理
5.2.1 从源码看流程
我们知道,select通过位图来告诉操作系统需要管理的文件描述符,poll通过结构体数组来告诉操作系统需要管理的文件描述符。
但epoll里面,却变成了一个epfd文件句柄,我们只是给这个特定的句柄交付文件描述符。这说明底层肯定需要其他的数据结构,来管理某个进程的某个epfd交付给操作系统的文件描述符,以及需要监看的事件!
在Linux 2.6.32.16源码fs/eventpoll.c中,可以找到如下这个结构体
// linux源码文件路径:fs/eventpoll.c/** This structure is stored inside the "private_data" member of the file* structure and rapresent the main data sructure for the eventpoll* interface.*/
struct eventpoll {/* Protect the this structure access */spinlock_t lock;/** This mutex is used to ensure that files are not removed* while epoll is using them. This is held during the event* collection loop, the file cleanup path, the epoll file exit* code and the ctl operations.*/struct mutex mtx;/* Wait queue used by sys_epoll_wait() */wait_queue_head_t wq;/* Wait queue used by file->poll() */wait_queue_head_t poll_wait;/* List of ready file descriptors */struct list_head rdllist;/* RB tree root used to store monitored fd structs */struct rb_root rbr;/** This is a single linked list that chains all the "struct epitem" that* happened while transfering ready events to userspace w/out* holding ->lock.*/struct epitem *ovflist;/* The user that created the eventpoll descriptor */struct user_struct *user;
};
在这里面,我们既可以看到熟悉的mutex锁,又可以看到一个wait_queue等待队列,一个双链表,和一个rb_root红黑树节点。
struct list_head {struct list_head *next, *prev;
}; // 内核中的双链表
抽象出来之后,其大概的结构图如下
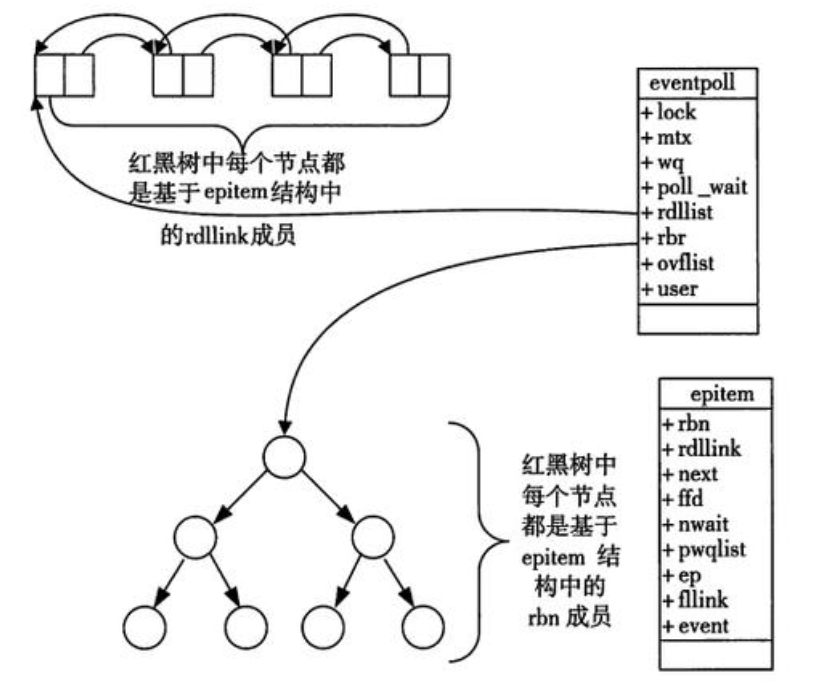
当某一个进程调用epoll_create创建epoll的文件描述符句柄的时候,操作系统就会帮我们在底层创建一个struct eventpoll结构体,内部包含了就绪队列和一个红黑树(主要关注这两个成员)
- 调用
epoll_ctl的时候,操作系统就会将我们配置的文件描述符和对于的事件添加到红黑树节点中; - 重复添加的事件也可以通过红黑树的键值唯一性检查出来(避免冗余)
- 所有添加到epoll中的事件都会与设备的网卡驱动程序建立回调消息,当某个文件描述符对应的链接有信息传来的时候,就会调用回调函数,告知epoll
- 网卡收到消息
- 驱动程序处理,并调用对应的回调机制
- epoll通过回调消息收到事件就绪,将其链入
rdllist双链表中 - 上层只需要调回
epoll_wait从该双链表中获取就绪事件
- 该回调办法在底层为
ep_poll_callback,它会将就绪的事件插入到rdllist双链表中 - epoll中每一个事件都会建立一个对应的
epitem结构体 - 当调用
epoll_wait有事件发生的时候,只需要检查eventpoll对象的rdllist双链表中是否有epitem元素即可,有则取出; - 如果
rdllist不为空,则将发生的事件复制到用户态,并将事件数量返回给用户;对比需要遍历的select/poll,这个获取就绪事件的时间复杂度是O(1)的(直接判断并取出就可以了)
这一大圈操作都是操作系统自行完成的,对于用户来说是无感知的!
关于epitem结构体,可以瞅一眼下面的注释,他也是在源码的fs/eventpoll.c文件中
struct epitem {/* RB tree node used to link this structure to the eventpoll RB tree */struct rb_node rbn; // 这个事件对应的红黑树节点/* List header used to link this structure to the eventpoll ready list */struct list_head rdllink; // 这个事件对应的双链表节点/** Works together "struct eventpoll"->ovflist in keeping the* single linked chain of items.*/struct epitem *next; /* The file descriptor information this item refers to */struct epoll_filefd ffd; // 事件句柄信息/* Number of active wait queue attached to poll operations */int nwait; /* List containing poll wait queues */struct list_head pwqlist;/* The "container" of this item */struct eventpoll *ep; // 指向其所属的epollevent对象/* List header used to link this item to the "struct file" items list */struct list_head fllink;/* The structure that describe the interested events and the source fd */struct epoll_event event; // 该fd关注的事件
};
5.2.2 PSH标记位
在学习TCP的时候,我们了解过PSH这个标记位,它的作用是告诉对端的应用层,尽快取走缓冲区中的数据。
对于epoll而言,这个PSH的作用就是让epoll在rdllist里面新建一个就绪节点,这样上层就能知道这个文件描述符的事件就绪了(至于读不读取依旧是上层的问题)
- 你可能会问,既然对方都发消息来催你取数据了,那不应该你的数据并没有被取走吗?这时候该文件描述符的就绪节点不应该已经存在了吗?为什么还需要额外创建一个就绪事件的节点来通知用户呢?
这就涉及到epoll的两种工作策略LT/ET了,后文会讲解;
需要注意的是,epoll并没有对URG进行特殊处理,而是视之为正常的可读事件连入就绪队列,但是事件类型有所不同,可以用
EPOLLPRI来关注紧急事件(存疑,但是没有找到相关资料,暂且这么认为)
5.2.3 epoll优点
一下是epoll相比poll和select的优点
- 接口使用方便,虽然拆分了3个函数,但是每个函数的功能非常明确;不需要每次使用都重新设置文件描述符,也实现了输入和输出参数的分离
- 数据拷贝轻量:在需要的时候调用epoll_ctl来处理文件描述符和事件,并不会每次调用都得大批量在用户和内核态之间拷贝数据(poll和select都需要)
- 事件回调机制:使用事件回调来替代遍历,回调函数将就绪的文件描述符结构加入到就绪队列中;
epoll_wait直接使用就绪队列,就能知道那些文件描述符就绪;即便文件描述符较多的时候,也能快速知道就绪的文件描述符(省去了遍历的时间消耗) - 无上限:文件描述符没有数量限制
- 线程安全:在
eventpoll结构体里面,我们可以看到有一个mutex锁,在linux底层已经帮我维护了epoll相关操作的线程安全性!
在有些博客里面说epoll使用了内存映射机制,这种说法是错误的!因为epoll_event结构体是在用户态创建的,我们势必还是需要进行一定的用户态到内核态的拷贝。
内存映射机制:linux内核直接将就绪队列通过mmap的方式映射到用户态,避免拷贝消耗(你可以理解为用户态和内核态之间的共享内存)
5.3 工作模式
在epoll的工作模式中,我们可以选择水平触发和边缘触发,这就好比物理实验中示波器的两种触发模式;
假设有这样一个tcp通信的栗子:
- 对方给我发送了2kb数据
- 我通过epoll_wait成功获取到这个文件描述符的读事件就绪
- 我取出文件描述符,通过
recv读取了1kb的数据 - 但缓冲区里面还有1kb……
5.3.1 水平触发 LT
所谓水平触发,就是只要fd的缓存区里面有数据,那么epoll就会一直认为这个fd的读事件是就绪的,并一直通知用户;
- 上面的栗子中,因为用户只拿走了1kb数据,缓冲区里面还有1kb,在第二次调用
epoll_wait的时候,epoll还是会报告该文件描述符的读事件就绪,让用户取走剩下的数据 - 只有所有的数据都被处理完毕,epoll才不会继续通知
- LT支持阻塞和非阻塞读写
因为LT模式只要缓冲区中还有剩余数据,epoll就会一直通知我们,这就允许上层不需要一次性取走所有数据,或者说不立刻处理当前缓冲区的数据。
因此,在LT模式中,只要是事件就绪,那么缓冲区里面一定会有数据。所以它是即支持阻塞,也支持非阻塞的文件读写的!
select/poll都是默认的LT模式,且不可以切换模式;epoll默认是LT,但可以切换到ET
5.3.2 边缘触发 ET
边缘触发的含义,是只有某个文件描述符的数据变动的时候,才会通知用户;反应到读事件上,只有缓冲区数据增多了,才会通知用户;
- 在上面的tcp通信栗子中,epoll会在数据到来的时候通知用户;但即便用户没有一次性读取完毕所有数据,epoll并不会继续通知了(除非有PSH信息到来)
- 在ET模式下,文件描述符的事件就绪后,只有一次处理机会。第二次你就无法得知这个文件描述符上是否还有没有读完的数据了
- 因为ET模式下
epoll_wait返回的次数更少,所以ET的性能远高于LT(nginx默认采用ET模式的epoll) - 因为我们只有一次机会,所以收到事件后必须立即处理
- 只支持非阻塞
5.3.3 LT和ET的区别
因为ET模式下,epoll只会提示你一次事件就绪,所以就倒逼程序猿在收到这个事件之后,一次性处理完数据;
当然,LT模式下你也可以这么做(如果每次都能一次性取走数据,那么LT和ET的性能差距就不大了)。但ET模式就相当于告诉所有使用者,必须这么做,减少了容错率;
但ET的代码复杂度会增加;
5.3.4 ET和非阻塞
为什么ET必须要将文件描述符设置成非阻塞呢?
假设下面这个场景,客户端C给服务端S发送10kb数据,在没有收到服务端对这个数据的响应之前,不会继续发送数据;
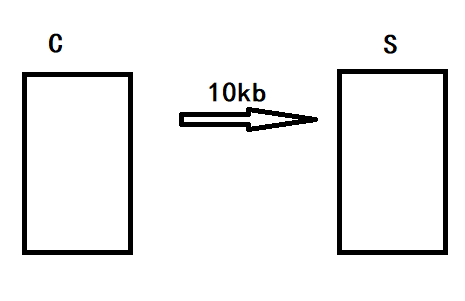
但服务器一次性只读取了1KB,剩下了9KB数据在缓冲区中;因为数据没有读完,所以不会给客户端发送响应。
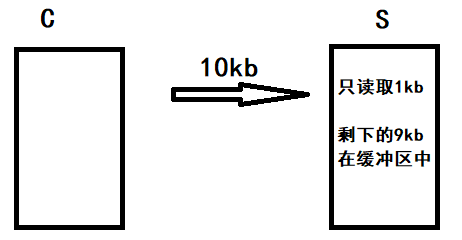
因为epoll设置了ET模式,所以并不会认为此时的文件描述符读就绪;epoll_wait不会针对这个文件描述符返回,剩下的9KB数据会一直留在缓冲区中;
- 注意,服务端的代码逻辑是收到就绪事件就读取一次;并不存在再次读取的可能
问题就来了!
- 服务端必须要收到就绪事件才会把剩下的9kb数据给读取完毕
- 服务端想要收到就绪事件,就必须收到客户端C发来的新数据
- 但客户端C认为服务器没有给自己发送响应,不会继续发送数据
这就相当于一个死循环了!
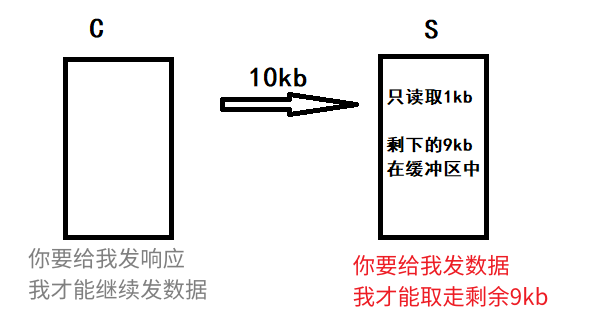
因此,服务端为了保证一次性能将数据全部取出,必须要采用循环读取+非阻塞的方式来将缓冲区读完!
如果采用阻塞式,那么在轮询读取的时候,就有可能因为缓冲区已经空了而阻塞!因为我们这个是一个单线程的模型,这样会直接导致整个服务器宕机了。
而LT则不会出现此问题,因为只要缓冲区中有数据就会通知你,所以我们可以一次读取定长,再将读到的数据拼接起来。
5.3.5 epoll的使用场景
epoll的高性能是有一定特殊场景的,如果场景不适合,epoll的性能可能表现不佳;
- 对于多链接且链接中有一部分活跃的时候,适合使用epoll
比如各种互联网APP的入口服务器,就很适合使用epoll来处理上万客户端的请求;
如果是系统内部处理服务器和服务器之间的通信,链接数较少的情况,这种时候使用epoll并不方便。得根据具体需要选择更加适合的IO模型。
5.4 惊群效应
参考 https://zhuanlan.zhihu.com/p/359774959
5.4.1 概念
在多线程环境下,可能会遇到epoll的惊群效应;
- 那么什么是惊群效应呢。其产生的原因是什么呢?
惊群效应的具体情况是,当有多个线程或进程在 epoll 上等待某个事件(如套接字可读事件),当该事件发生时,所有等待的线程或进程都会被唤醒。然而,只有一个线程或进程可以成功地处理这个事件,而其他的线程或进程会进行不必要的竞争,可能会导致额外的上下文切换、锁竞争等问题,从而降低系统性能。
- 以下是一个具体场景的说明
在多线程或者多进程环境下,有些人为了提高程序的稳定性,往往会让多个线程或者多个进程同时在epoll_wait监听的socket描述符。当一个新的链接请求进来时,操作系统不知道选派那个线程或者进程处理此事件,则干脆将其中几个线程或者进程给唤醒,而实际上只有其中一个进程或者线程能够成功处理accept事件,其他线程都将失败,且errno错误码为EAGAIN。这种现象称为惊群效应。
结果是肯定的,惊群效应肯定会带来资源的消耗和性能的影响,因为你无端地多唤醒了几个线程,这些线程/进程却没有活干。
5.4.2 多线程环境下解决办法
- 专门的线程负责等待:在多线程场景下,不建议让多个线程进行
epoll_wait,而用单个线程进行wait,并由该线程调用accept建立新链接,并将就绪的文件描述符交付给其他线程,来处理后续的读写操作。 - 使用线程池:不为每个链接都创立一个专门的线程,而是根据读写事件,将其交付给线程池中已有线程来处理;
- 使用ET模式:该模式下读写就绪的时候只会通知一次,再加上epoll本身是线程安全的,所以只会有一个线程可以拿到这个就绪事件,从而避免惊群现象;
- 互斥锁:同一时间只有一个线程进行等待和事件处理;
5.4.3 多进程下解决办法
目前很多开源软件,如lighttpd和nginx等都采用master/workers的模式提高软件的吞吐能力及并发能力,在nginx中甚至还采用了负载均衡的技术,在某个子进程的处理能力达到一定负载之后,由其他负载较轻的子进程负责·的调用,那么nginx和Lighttpd是如何避免epoll_wait的惊群效用的呢?
- lighttpd的解决思路是无视惊群效应
仍然采用master/workers模式,每个子进程仍然自己在监听的socket上调用epoll_wait,当有新的链接请求发生时,操作系统仍然只是唤醒其中部分的子进程来处理该事件,仍然只有一个子进程能够成功处理此事件,那么其他被惊醒的子进程捕获EAGAIN错误,并无视。
- nginx的解决思路是互斥锁
在同一时刻,永远都只有一个子进程在监听的socket上epoll_wait,其做法是,创建一个全局的pthread_mutex_t,在子进程进行epoll_wait前,则先获取锁。当epoll_wait返回之后,nginx会调用accept把连接取出来,然后释放文件锁,让别的进程去监听。
这是一种折衷的办法,并没有很完美,首先进程间争抢锁会有性能开耗(即使是非阻塞的锁),中间可能会有小段时间没有进程去获取锁,比如A进程拿到锁,其他进程将会过一小段时间尝试再去获取锁,而这小段时间里面如果请求量很大,A仅接受一小部分请求就让出锁,则中间过程会有一些连接事件被hang住;
5.4.4 内核解决了惊群效应了吗
惊群的根本原因在于epoll的默认行为是对于多进程监听同一文件不会设置互斥,进而将所有进程唤醒,后续的内核版本主要提供了两种解决方案
- 既然默认不会设置互斥,那就加一个互斥功能好了,
linux 4.5内核之后给epoll添加了一个EPOLLEXCLUSIVE的标志位,如果设置了这个标志位,那epoll将进程挂到等待队列时将会设置一下互斥标志位,这时实现跟内核原生accept一样的特性,只会唤醒队列中的一个进程 - 第二种方法:
linux 3.9内核之后给socket提供SO_REUSEPORT标志,这种方式解决得更彻底,他允许不同进程的socket绑定到同一个端口,取代以往需要子进程共享socket监听的方式,这时候,每个进程的监听socket将指向open_file_tables下的不同节点,也就是说不同进程是在自己的设备等待队列下被挂起的,不存在共享fd的问题,也就不存在被同时唤醒的可能。而内核则在驱动中将设置了SO_REUSEPORT并且绑定同一端口的这些socket分到同一个group中,当有tcp连接事件到达的时候,内核将会对源IP+源端口取hash然后指定这个group中其中一个进程来接受连接,相当于在内核级别中实现了一个负载均衡
基于以上两种方法,其实epoll生态在目前来说不存在所谓的惊群效应了。而新版本的nginx也采用了 SO_REUSEPORT来解决此问题。
除非你溢用epoll,比如多进程之间共享了同一个epfd(父进程创建epoll由多个子进程来调用),那就不能怪epoll了,因为这时候多个进程都被挂到这个epoll下,这种情况下,已经不是仅仅是惊群效应的问题了;比如说,A进程在epoll挂了socket1的连接事件,B进程调用了epoll_wait,由于属于同一个epfd,当socket1产生事件的时候,进程B也会被唤醒,而更严重的事情在于,在B进程的空间下并不存在socket1这个fd,从而把问题搞得很复杂。
总结:千万不要在多线程/多进程之间共享epfd!
6.Reactor模型
接下来就让我们来用epoll编写一个基于Reactor模式的服务器吧!
6.1 什么是Reactor?
- Reactor模型是基于事件驱动的,通过一个或者多个输入同时传递给服务端进行处理
- 服务端请求程序处理传入的多个请求,并分发到相应的处理线程
- 基于IO多路转接(多路复用)模型:多个链接通用一个阻塞对象,引用程序只需要在一个阻塞对象等待,无需阻塞等待所有链接;当有新链接或者事件就绪的时候,由操作系统通知应用程序,开始进行业务处理
- 基于线程池复用线程资源:不必给每个链接单独创建线程,而是将链接完成后的业务处理交付给已有线程池中的线程进行处理,一个线程在生命周期中可以处理多个链接的业务。
reactor模式有下面3种方式,参考博客 @顽石九变
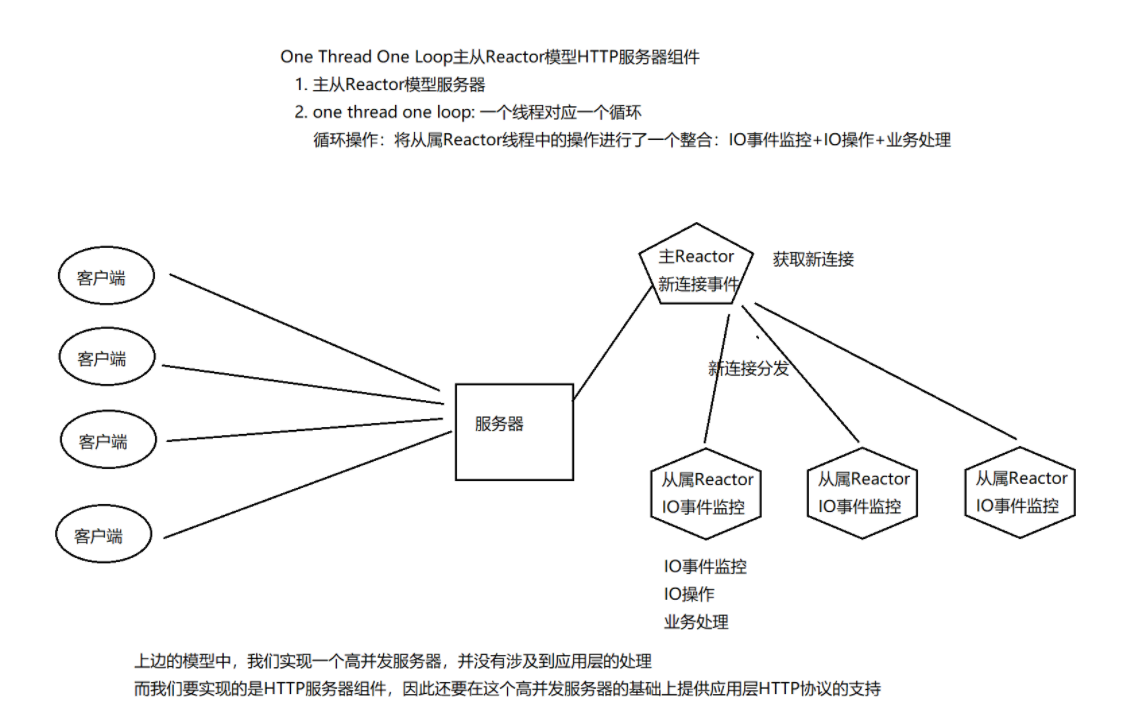
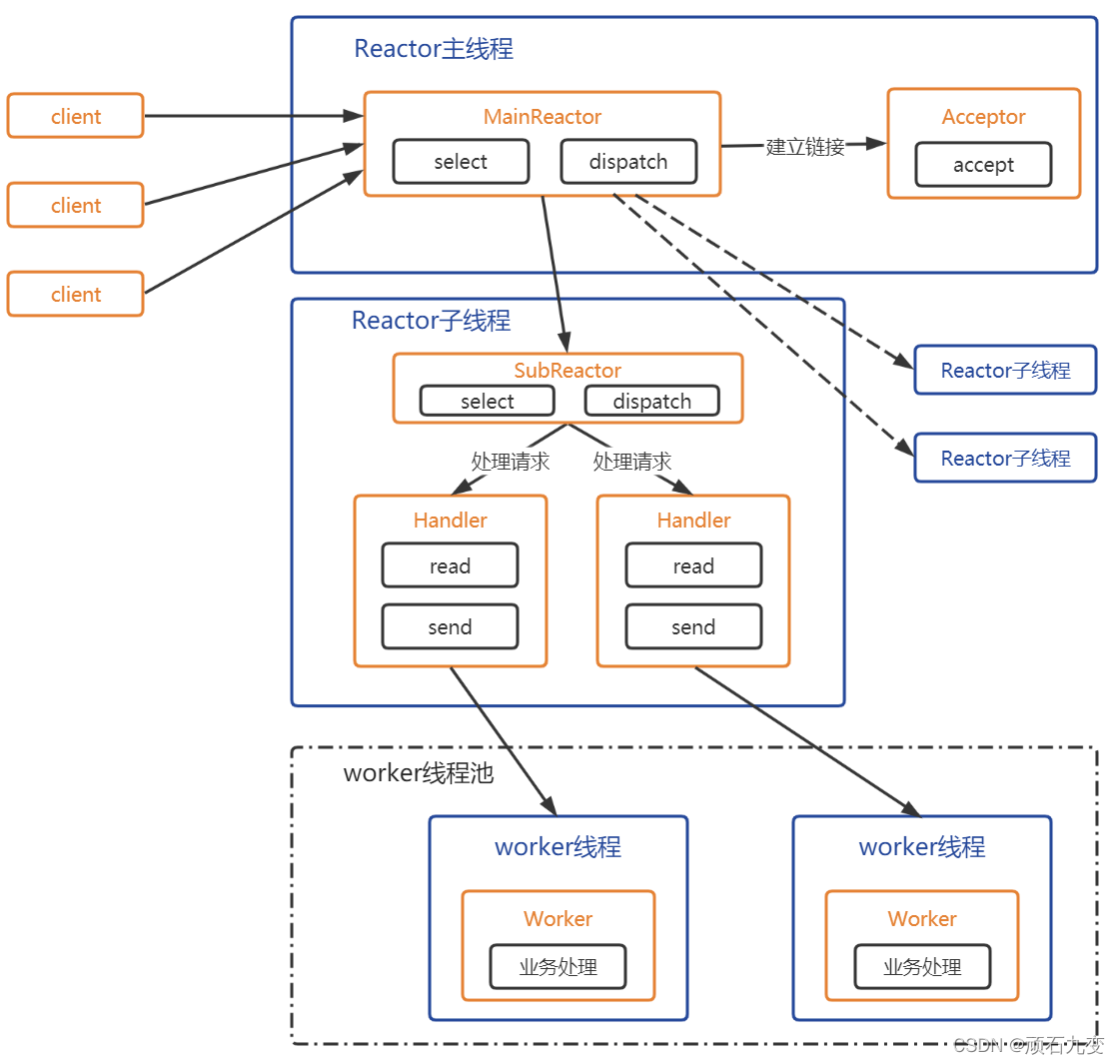
6.1.1 主从Reactor多线程模型
第一种是多线程模式的,有不同的从属reactor来进行事件监控和处理
- Reactor主线程负责监听事件并进行链接的accept
- accpet获取到链接后,分配给某一个从Reactor进行读写事件的监听
- 从Reactor进行事件监听,当有新事件发生的时候,创建Handler进行事件处理
- Headler通过read读取数据,并处理数据(这里还可以将读取数据后的响应操作分发给线程池进行处理,线程池处理完毕后返回给Handler),通过send返回给客户端
- Reactor主线程可以对应多个子线程
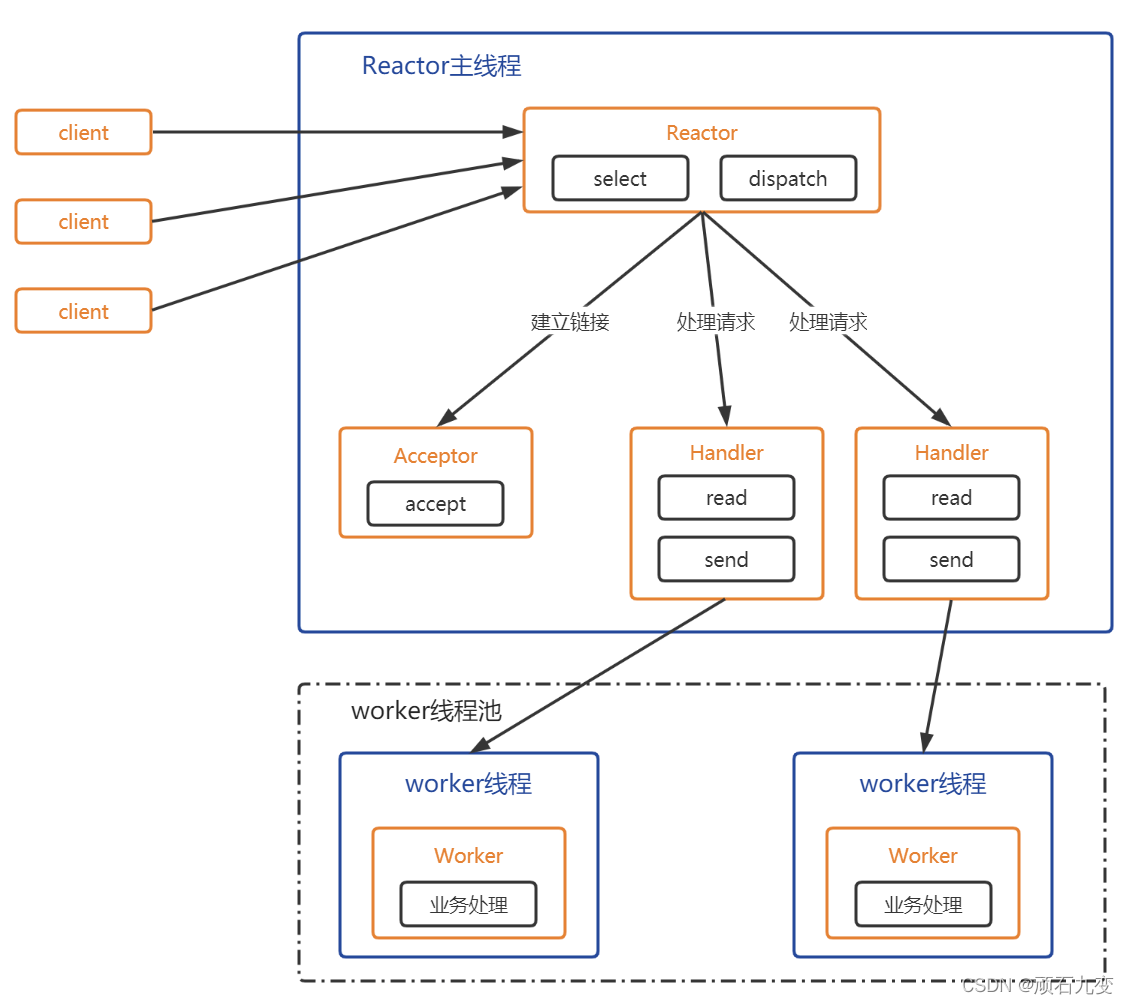
6.1.2 单Reactor多线程
- Reactor通过多路转接监听客户端事件,收到事件后,进行分发
- 如果是建立链接的请求,则执行accept,建立链接后,创建一个Handler完成链接建立后的各个操作
- 如果不是链接请求(读写就绪)则由Reactor分发调用链接对应的读写Handler来进行处理
- Handler只负责响应具体的事件,而不进行具体的业务处理
- 通过Handler中的read读取到数据后,分发给线程池子中的线程处理,处理完毕后返回Handler,再通过写方法发送给客户端
6.1.3 单Reactor单线程
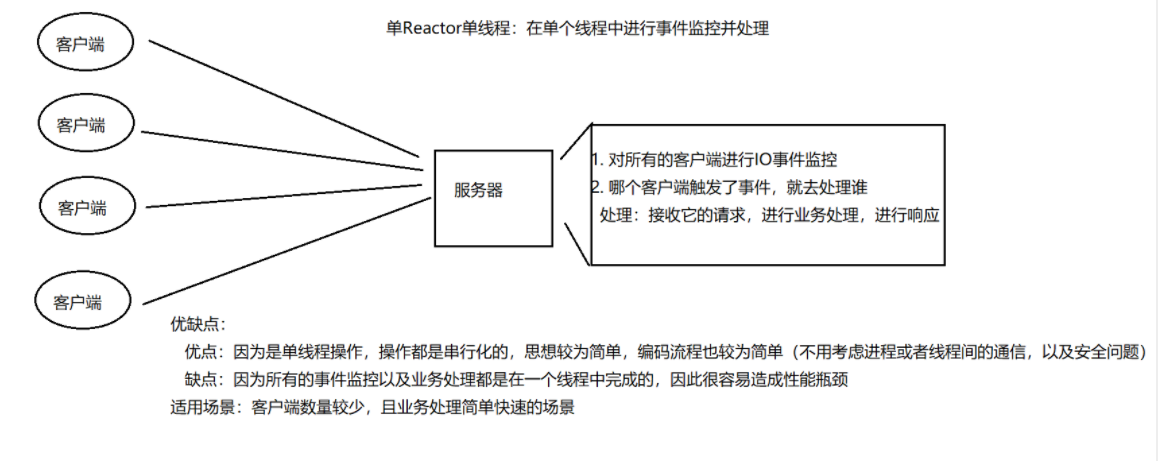
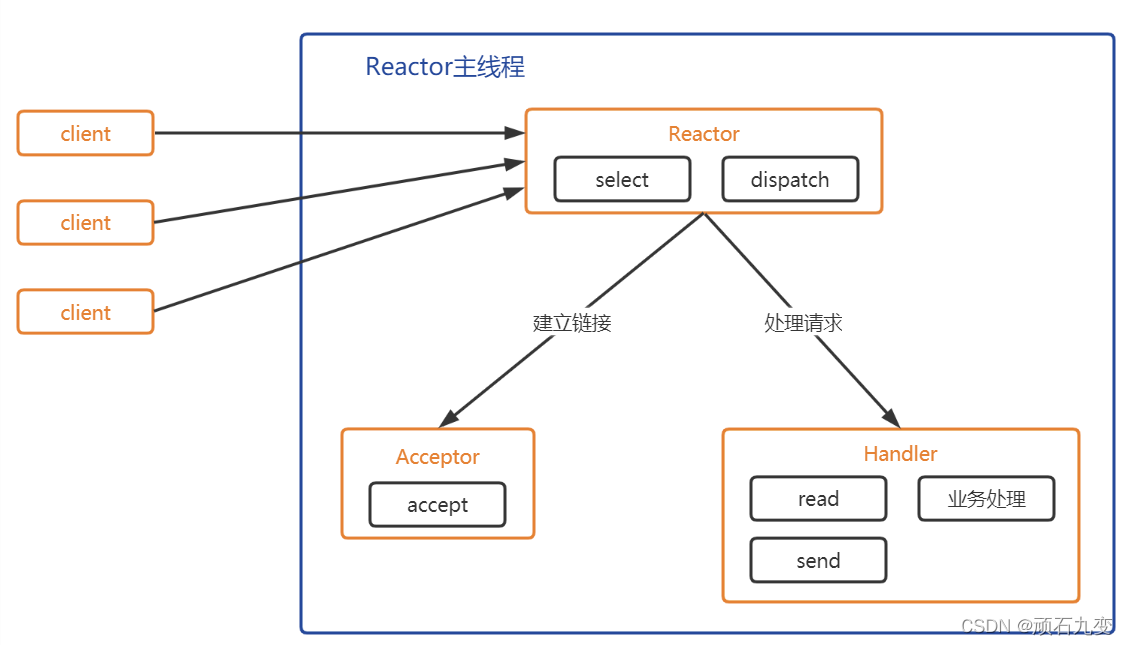
第三种是单线程模式下的(半异步半同步模型),当收到某个客户端的就绪事件,就去处理这个客户端的请求。此时Handler会完成read到业务处理到send的全流程;
本次主要写的是该模式下的操作,因为它基本是串行运行的,思路比较容易理解。但需要注意的是,这种模式支持的客户端量不应过多,否则会极大影响性能。
6.1.4 总结
三种模式用生活案例来理解
-
单Reactor单线程,前台接待员和服务员是同一个人,全程为顾客服务
-
单Reactor多线程,1个前台接待员,多个服务员,接待员只负责接待
-
主从Reactor多线程,多个前台接待员,多个服务员
Reactor模型具有如下优点
-
响应快,不必为单个同步事件所阻塞,虽然Reactor本身依然是同步的
-
可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销
-
扩展性好,可以方便的通过增加Reactor实例个数来充分利用CPU资源
-
复用性好,Reactor模型本身与具体事件处理逻辑无关,具有很高的复用性
6.2 代码分析
话不多说,直接上代码吧!本次将所有处理模块都给拆分开来,一一进行说明
6.2.1 Epoller.hpp
首先是将对epoll的三个系统调用函数进行一定的封装,统一进行错误的判断处理。方便了其他模块的调用用;
这部分的代码非常简单,就只在注释里写一下解析吧!
#pragma once
#include <iostream>
#include <cerrno>
#include <cstdlib>
#include <unistd.h>
#include <sys/epoll.h>
#include "Log.hpp"class Epoller
{
public:static const int gsize = 128;
public:static int CreateEpoller(){int epfd = epoll_create(gsize); // 创建对应size的epfdif (epfd < 0) // 错误判断{logMessage(FATAL, "epoll_create : %d : %s", errno, strerror(errno));exit(3);}return epfd; // 正确返回epfd}static bool AddEvent(int epfd, int sock, uint32_t event){struct epoll_event ev;ev.events = event; // 设置eventev.data.fd = sock;// 给对应的socket添加到epoll中int n = epoll_ctl(epfd, EPOLL_CTL_ADD, sock, &ev);return n == 0; // 返回值是是否调用成功}static bool ModEvent(int epfd, int sock, uint32_t event){struct epoll_event ev;ev.events = event;ev.data.fd = sock;// 修改已有scoket的event// 该socket必须先用ADD添加,否则无法修改,会返回ENOENT错误int n = epoll_ctl(epfd, EPOLL_CTL_MOD, sock, &ev);return n == 0;}static bool DelEvent(int epfd, int sock){// 删除指定socketint n = epoll_ctl(epfd, EPOLL_CTL_DEL, sock, nullptr);return n == 0;}static int LoopOnce(int epfd, struct epoll_event revs[], int num){// 单次wait的调用,从数组里面取回就绪的文件描述符int n = epoll_wait(epfd, revs, num, -1);if(n == -1){logMessage(FATAL, "epoll_wait : %d : %s", errno, strerror(errno));}return n;}
};
6.2.2 Sock.hpp
同select,见上文 3.2.1 socket 部分;
6.2.3 Log.hpp
一个巨简单的日志类
#pragma once#include <cstdio>
#include <ctime>
#include <cstdarg>
#include <cassert>
#include <cassert>
#include <cstring>
#include <cerrno>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define DEBUG 0
#define NOTICE 1
#define WARNING 2
#define FATAL 3const char *log_level[] = {"DEBUG", "NOTICE", "WARINING", "FATAL"};#define LOGFILE "serverTcp.log"class Log
{
public:Log():logFd(-1){}void enable(){umask(0);logFd = open(LOGFILE, O_WRONLY | O_CREAT | O_APPEND, 0666);assert(logFd != -1);dup2(logFd, 1);dup2(logFd, 2);}~Log(){if(logFd != -1) {fsync(logFd);close(logFd);}}
private:int logFd;
};// logMessage(DEBUG, "%d", 10);
void logMessage(int level, const char *format, ...)
{assert(level >= DEBUG);assert(level <= FATAL);char *name = getenv("USER");char logInfo[1024];va_list ap;va_start(ap, format);vsnprintf(logInfo, sizeof(logInfo) - 1, format, ap);va_end(ap); // ap = NULLFILE *out = (level == FATAL) ? stderr : stdout;fprintf(out, "%s | %u | %s | %s\n",log_level[level],(unsigned int)time(nullptr),name == nullptr ? "unknow" : name,logInfo);fflush(out); // 将C语言缓冲区中的数据刷新到OSfsync(fileno(out)); // 将OS中的数据尽快写入硬盘
}
6.2.4 TcpServer
这是我们reactor模型的重点
1.Connection类
这里先定义了一个Connection链接类,比较重要的是类里面有3个回调方法的指针。在Reactor中,我们用回调方法来替代了主执行流直接调用函数的方式。线程只需要接收到这个Connection对象,就可以用回调方法来实现对链接的数据处理
using func_t = std::function<int(Connection *)>;
using callback_t = std::function<int(Connection *, std::string &)>;class Connection
{
public:// 文件描述符int sock_;TcpServer *R_;// 主服务器的类指针// 自己的接受和发送缓冲区std::string inbuffer_;std::string outbuffer_;// 读、写、异常的回调函数func_t recver_; func_t sender_;func_t excepter_;public:Connection(int sock, TcpServer *r) : sock_(sock), R_(r){}void SetRecver(func_t recver) { recver_ = recver; }void SetSender(func_t sender) { sender_ = sender; }void SetExcepter(func_t excepter) { excepter_ = excepter; }~Connection() {}
};
2.TcpServer成员变量
再来看看tcpserver的成员变量有什么
private:// 接收队列的长度static const int revs_num = 64;// 1. 网络socketint listensock_;// 2. epoll的fdint epfd_;// 3. 将epoll和上层代码进行结合,已有链接std::unordered_map<int, Connection *> connections_;// 4. 就绪事件列表struct epoll_event *revs_;// 5. 设置完整报文的处理回调方法callback_t cb_;
3.构造
随后便是在构造函数中初始化这些成员变量,先是从Sock.hpp中获取到监听文件描述符,然后再通过Epoller类获取到epfd句柄,最后是将listensocket放入epoll的监听中;
这里的std::bind的作用,是将当前TcpServer的this指针绑定到TcpServer::Accepter函数的第一个参数上,否则在类外没有办法通过Connection类的回调指针来调用这个类的成员函数
TcpServer(callback_t cb, int port = 8080) : cb_(cb){// 当前监听的文件描述符及其事件revs_ = new struct epoll_event[revs_num]; // 网络功能listensock_ = Sock::SocketInit();Util::SetNonBlock(listensock_);Sock::Bind(listensock_, port);Sock::Listen(listensock_);// 多路转接epfd_ = Epoller::CreateEpoller();// 添加listensock匹配的connectionAddConnection(listensock_, EPOLLIN | EPOLLET,std::bind(&TcpServer::Accepter, this, std::placeholders::_1), nullptr, nullptr);}
4.添加链接
在AddConnection函数中,我们会将socket给添加到epfd中;如果这个epfd是使用了EPOLLET的ET模式,则还需要设置非阻塞;
void AddConnection(int sockfd, uint32_t event, func_t recver, func_t sender, func_t excepter)
{if (event & EPOLLET)Util::SetNonBlock(sockfd);// 添加sockfd到epollEpoller::AddEvent(epfd_, sockfd, event);// 将sockfd匹配的Connection也添加到当前的unordered_map中Connection *conn = new Connection(sockfd, this);conn->SetRecver(recver);conn->SetSender(sender);conn->SetExcepter(excepter);connections_.insert(std::make_pair(sockfd, conn));logMessage(DEBUG, "添加新链接到connections成功: %d", sockfd);
}
设置非阻塞的代码很简单,在前文已经演示过了
class Util
{
public:static void SetNonBlock(int fd){int fl = fcntl(fd, F_GETFL);fcntl(fd, F_SETFL, fl | O_NONBLOCK);}
};
5.析构
在析构函数中,我们需要将listensocket和epfd两个文件描述符关闭,并析构掉链接数组
~TcpServer(){if (listensock_ != -1)close(listensock_);if (epfd_ != -1)close(epfd_);delete[] revs_;// 还需要析构掉连接池中尚存在的connection对象for(auto&c:connections_){delete c.second;}}
6.获取新连接Accept
在获取新连接这里,我们采用了一个死循环来获取。这是因为对于listensocket文件描述符而言,只要来了一个新链接,在ET模式下就会提示我们。但有可能会出现我们还没有来得及取走这个链接,就又来了一个新链接的情况(可以简化理解为一次性来了两个链接)
这时候因为ET的特性,我们就需要一次性取走所有链接;为了避免在Accept的时候,因为链接已经都被取走了而阻塞住,我们需要将listensocket设置为非阻塞;
关于新链接为什么只关注读事件,在注释中有说明;
对于listensocket来说,这个Accepter函数就是它的读事件回调,所以这个函数的参数也是一个Connection *conn对象,其是为了与其他事件处理函数统一(因为这个事件处理函数不在Connection类中,所以我们必须要获取一个对象才能访问到它的成员变量)
int Accepter(Connection *conn)
{while (true){std::string clientip;uint16_t clientport = 0;int sockfd = Sock::Accept(conn->sock_, &clientip, &clientport);if (sockfd < 0){// 接收函数被事件打断了if (errno == EINTR)continue;// 本次数据没有准备好,可以理解为接收缓冲区空了else if (errno == EAGAIN || errno == EWOULDBLOCK)break;else{logMessage(WARNING, "accept error");return -1;}}logMessage(DEBUG, "get a new link: %d", sockfd);// 注意:默认我们只设置了让epoll帮我们关心读事件,没有关心写事件// 为什么没有关注写事件:因为最开始的时候,写空间一定是就绪的!// 运行中可能才会存在写条件不满足 -- 写空间被写满了AddConnection(sockfd, EPOLLIN | EPOLLET,std::bind(&TcpServer::TcpRecver, this, std::placeholders::_1),std::bind(&TcpServer::TcpSender, this, std::placeholders::_1),std::bind(&TcpServer::TcpExcepter, this, std::placeholders::_1));}return 0;
}
EAGAIN or EWOULDBLOCKThe socket is marked nonblocking and the receive operation would block, or a receive timeout had been set and the timeout expired before data was received. POSIX.1 allows either error to be returned for this case, and does not require these constants to have the same value, so a portable application should check for both possibilities.
7.链接的事件处理函数
其他链接的三个处理函数分别是TcpRever/TcpSender/TcpExcepter;
首先,在处理某一个链接的时候,我们必须要保证这个链接在已有的map里面,否则代表这个链接已经被关闭或者异常退出了;同理,在异常和关闭链接的处理流程中,我们也需要将链接从map中删除
bool IsExists(int sock){auto iter = connections_.find(sock);if (iter == connections_.end())return false;elsereturn true;}
读
对于读事件而言我们也是进行循环读取,该文件描述符也需要被设置为非阻塞。读取的内容拼接到该Connection对象的输入缓冲区string中;
在读取完毕后,我们需要在协议里面定义一个根据应用层协议字段来分离报文的函数(避免tcp的粘包问题),最终会得到一个string的数组,每个数组成员都是一个完整的报文;
最后,我们直接一个for循环,通过该tcpserver对象在初始化时候设置的cb_函数回调指针,来处理每一个报文(为每一个报文提供服务)
int TcpRecver(Connection *conn){while (true){char buffer[1024];ssize_t s = recv(conn->sock_, buffer, sizeof(buffer) - 1, 0);if (s > 0){buffer[s] = 0;conn->inbuffer_ += buffer;}else if (s == 0){logMessage(DEBUG, "client quit");conn->excepter_(conn);break;}else{if (errno == EINTR) // 接收事件被打断continue;// 接收缓冲区空了else if (errno == EAGAIN || errno == EWOULDBLOCK)break; // 跳出循环else{// 出错了logMessage(DEBUG, "recv error: %d:%s", errno, strerror(errno));conn->excepter_(conn);break;}}}// 将本轮全部读取完毕std::vector<std::string> result;PackageSplit(conn->inbuffer_, &result);for (auto &message : result){cb_(conn, message);}return 0;}
这个框架的好处就在于,你可以单独实现不同协议的报文分离函数和数据服务函数,而不需要重写TcpServer的实现,相当于解耦;
写
int TcpSender(Connection *conn)
{while(true){ssize_t n = send(conn->sock_, conn->outbuffer_.c_str(), conn->outbuffer_.size(), 0);if(n > 0){// 去除已经成功发送的数据conn->outbuffer_.erase(0, n);}else{// 写入操作被打断if(errno == EINTR) continue;// 写入缓冲区满了,没办法继续写else if(errno == EAGAIN || errno == EWOULDBLOCK) break; else // 异常{conn->excepter_(conn);logMessage(DEBUG, "send error: %d:%s", errno, strerror(errno));break;}}}return 0;
}
注意,这里的写入如果遇到(errno == EAGAIN || errno == EWOULDBLOCK) 这两种情况,并不能确保输出缓冲区中的数据已经被全部写入了;有可能是写入缓冲区满了导致无法继续写入;
这种i情况下,我们需要判断outbuffer是否为空,如果不为空,则还是需要设置EPOLLOUT标记位,告知epoll继续帮我们关注写事件(这样epoll就会发信息告知Reactor,Reactor会重新调用写入函数,继续写入缓冲区的剩下数据)这个操作会在主执行流中进行统一判断
// 主执行流
conn->sender_(conn); // 主执行流调用发送函数
// 判断本次是否发完毕了,没有发完毕还需要继续关心读写
if(conn->outbuffer_.empty()) conn->R_->EnableReadWrite(conn->sock_, true, false);
else conn->R_->EnableReadWrite(conn->sock_, true, true);
// 打开或者关闭对于特定socket是否要关心读或者写//- EnableReadWrite(sock, true, false); //只关心读//- EnableReadWrite(sock, true, true); //同时关心读写void EnableReadWrite(int sock, bool readable, bool writeable){uint32_t event = 0;event |= (readable ? EPOLLIN : 0);event |= (writeable ? EPOLLOUT : 0);Epoller::ModEvent(epfd_, sock, event);}
异常
为了统一进行异常处理,在上文中当我们遇到读写出错的时候,都会调用这个函数;
在这个函数体内,会将链接从epoll中删除、关闭链接、释放connection对象、将文件描述符从map里面剔除;
需要注意的是,一定要先将socket从epoll里面剔除掉,再关闭socket!
int TcpExcepter(Connection *conn){// 0. 判断有效性if(!IsExists(conn->sock_)) return -1;// 所有的服务器异常,都会被归类到这里// 1. 删除epoll的监看Epoller::DelEvent(epfd_, conn->sock_);logMessage(DEBUG, "remove epoll event!");// 2. closeclose(conn->sock_);logMessage(DEBUG, "close fd: %d", conn->sock_);// 3. delete conn;delete connections_[conn->sock_];logMessage(DEBUG, "delete connection object done");// 4. erase conn;connections_.erase(conn->sock_);logMessage(DEBUG, "erase connection from connections");return 0;}
8.运行
对于TcpServer而言,一次的运行就是调用一次epoll_wait,再根据事件就绪的文件描述符,调用不同的事件处理函数
void Dispatcher(){int n = Epoller::LoopOnce(epfd_, revs_, revs_num);for (int i = 0; i < n; i++){int sock = revs_[i].data.fd;uint32_t revent = revs_[i].events;// 判断是否出现错误,如果出现了错误,那就把EPOLLIN和OUT都加上// 这样这个链接会进入下面的处理函数,并在处理函数中出现异常// 处理函数中出现异常回统一调用TcpExcpter函数if(revent & EPOLLHUP) revent |= (EPOLLIN|EPOLLOUT);if(revent & EPOLLERR) revent |= (EPOLLIN|EPOLLOUT);if (revent & EPOLLIN){if (IsExists(sock) && connections_[sock]->recver_)connections_[sock]->recver_(connections_[sock]);}// 当链接的写事件被激活的时候,在这里就会触发写事件的处理// 所以并不需要在recv里面主动调用写事件处理函数// 只需要告诉epoll让它帮我们监控写事件,那么就会在这里触发写操作if (revent & EPOLLOUT){if (IsExists(sock) && connections_[sock]->sender_)connections_[sock]->sender_(connections_[sock]);}}}
整个服务器运行起来,就一直调用分发函数就OK啦~
void Run(){while (true){Dispatcher();}}
6.2.5 主执行流
对于主执行流而言,要做的就是获取到命令行参数的端口,然后创建tcpserver对象并绑定事件处理函数
#include "TcpServer.hpp"
#include "Service.hpp"
#include <memory>using namespace std;static void usage(std::string process)
{cerr << "\nUsage: " << process << " port\n"<< endl;
}int main(int argc, char *argv[])
{if (argc != 2){usage(argv[0]);exit(0);}TcpServer svr(HandlerRequest, atoi(argv[1]));svr.Run();return 0;
}
事件处理函数可以做任意封装,来实现你自己想要的功能
int HandlerRequest(Connection *conn, std::string &message)
{// beginhandler里面是具体的调用逻辑,calculator是本次事务处理函数return BeginHandler(conn, message, calculator);
}
这里就是我们单个完整报文的处理函数,在tcprecver方法里面被调用了;
根据上文描述的调用方法,我们可以确定,这里传入来的message肯定是一个完整的应用层报文,我们只需要创建一个属于我们自己的协议和协议中的数据处理函数就OK了!
int BeginHandler(Connection *conn, std::string &message, service_t service)
{// message一定是一个完整的报文,因为我们已经对它进行了解码Request req;// 反序列化,进行处理的问题if (!Parser(message, &req)){// 写回错误消息return -1;// 可以直接关闭连接// conn->excepter_(conn);}// 业务逻辑Response resp = service(req);std::cout << req.x << " " << req.op << " " << req.y << std::endl;std::cout << resp.code << " " << resp.result << std::endl;// 序列化std::string sendstr;Serialize(resp, &sendstr);// 处理完毕的结果,发送回给clientconn->outbuffer_ += sendstr;conn->sender_(conn);if(conn->outbuffer_.empty()) conn->R_->EnableReadWrite(conn->sock_, true, false);else conn->R_->EnableReadWrite(conn->sock_, true, true);std::cout << "--- end ---" << std::endl;return 0;
}
6.2.6 协议和数据处理
下面提供一个最基础的计算器协议,这个协议的好处是我们可以用telnet就模拟出请求,无需写一个tcp客户端。
x 操作符 y#
这个协议中,每个有效数据中都会带上一个空格,并以#作为单个报文的结尾;
响应和请求的结构体格式也非常简单,响应里面是状态码和计算结果;我们在协议中添加序列化和反序列化函数就可以将响应和请求结构体转成字符串
struct Request
{int x;int y;char op;
};struct Response
{int code;int result;
};
完整代码
#pragma once#include <iostream>
#include <vector>
#include <cstring>
#include <string>
#include <cstdio>#define SEP '#'
#define SEP_LEN sizeof(SEP)#define CRLF "\r\n"
#define CRLF_LEN strlen(CRLF)
#define SPACE " "
#define SPACE_LEN strlen(SPACE)// 分离独立报文
void PackageSplit(std::string &inbuffer, std::vector<std::string> *result)
{while (true){std::size_t pos = inbuffer.find(SEP);if (pos == std::string::npos)break;result->push_back(inbuffer.substr(0, pos));inbuffer.erase(0, pos + SEP_LEN);}
}struct Request
{int x;int y;char op;
};struct Response
{int code;int result;
};bool Parser(std::string &in, Request *req)
{// 1 + 1, 2 * 4, 5 * 9, 6 *1std::size_t spaceOne = in.find(SPACE);if (std::string::npos == spaceOne)return false;std::size_t spaceTwo = in.rfind(SPACE);if (std::string::npos == spaceTwo)return false;std::string dataOne = in.substr(0, spaceOne);std::string dataTwo = in.substr(spaceTwo + SPACE_LEN);std::string oper = in.substr(spaceOne + SPACE_LEN, spaceTwo - (spaceOne + SPACE_LEN));if (oper.size() != 1)return false;// 转成内部成员req->x = atoi(dataOne.c_str());req->y = atoi(dataTwo.c_str());req->op = oper[0];return true;
}void Serialize(const Response &resp, std::string *out)
{std::string ec = std::to_string(resp.code);std::string res = std::to_string(resp.result);*out = ec;*out += SPACE;*out += res;*out += CRLF;
}
在service.hpp里面则是数据处理的计算函数,通过我们传入的请求,计算出结构并构造响应返回给用户
#pragma once#include "Protocol.hpp"
#include <functional>using service_t = std::function<Response (const Request &req)>;static Response calculator(const Request &req)
{Response resp = {0, 0};switch (req.op){case '+':resp.result = req.x + req.y;break;case '-':resp.result = req.x - req.y;break;case '*':resp.result = req.x * req.y;break;case '/':{ // x_ / y_if (req.y == 0)resp.code = -1; // -1. 除0elseresp.result = req.x / req.y;}break;case '%':{ // x_ / y_if (req.y == 0)resp.code = -2; // -2. 模0elseresp.result = req.x % req.y;}break;default:resp.code = -3; // -3: 非法操作符break;}return resp;
}
6.2.7 测试
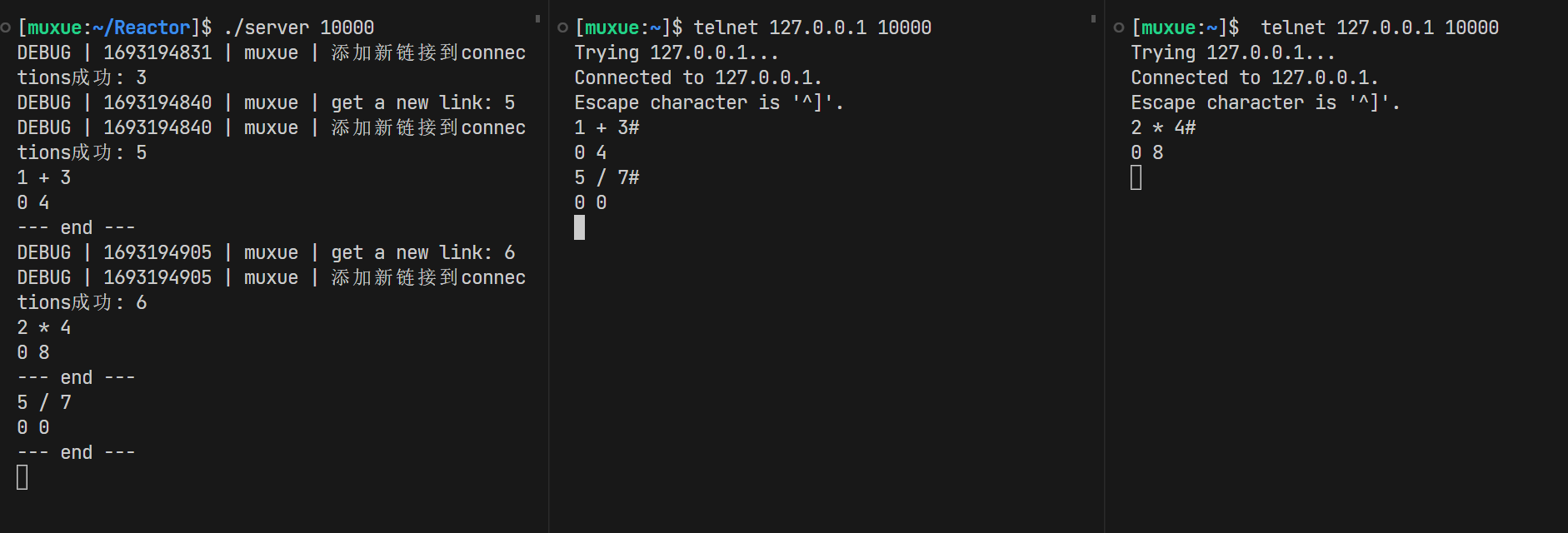
可以看到,我们的服务启动了之后,成功接收了一个链接,并计算出了我们发送的结果

多个链接也不在话下!
The end
多路转接这部分是linux服务器最重要的一部分知识,因为大部分服务器都抛弃了最传统的一个线程维护一个链接这样的方式,而采用了多路转接来实现对大量进程的维护;
本文是学习阶段的产物,有错误在所难免,请大佬们指教!