前言:Hello大家好,我是小哥谈。人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术,也是计算机视觉重点发展的技术。机械学习算法诞生之后,计算机可以通过摄像头等输入设备自动分析图像中包含的内容信息,随着技术的不断发展,现在已经有了多种人脸识别的算法。🌈
![]() 前期回顾:
前期回顾:
史上最全OpenCV常用方法及使用说明汇总,建议收藏!
OpenCV基础知识(1)— OpenCV概述
OpenCV基础知识(2)— 图像处理的基本操作(读取图像、显示图像、保存图像和获取图像属性)
OpenCV基础知识(3)— 图像数字化基础(像素、色彩空间)
OpenCV基础知识(4)— 绘制图形(线段、矩形、圆形、多边形和文字)
OpenCV基础知识(5)— 几何变换(缩放、翻转、旋转和透视)
OpenCV基础知识(6)— 滤波器(均值滤波器、中值滤波器、高斯滤波器和双边滤波器)
OpenCV基础知识(7)— 腐蚀与膨胀
OpenCV基础知识(8)— 图形检测(图像轮廓、轮廓拟合、Canny边缘检测和霍夫变换)
OpenCV基础知识(9)— 视频处理(读取并显示摄像头视频、播放视频文件、保存视频文件等)
目录
🚀1.人脸跟踪
💥💥1.1 级联分类器
💥💥1.2 方法
💥💥1.3 分析人脸位置
🚀2.检测其他内容
💥💥2.1 眼睛跟踪
💥💥2.2 行人跟踪
💥💥2.3 车牌跟踪
🚀3.人脸识别
💥💥3.1 Eigenfaces人脸识别器
💥💥3.2 Fisherfaces人脸识别器
💥💥3.3 Local Binary Pattern Histogram人脸识别器

说明:关于本节完整代码及相关资源,请在我的“资源”中下载。 ♨️♨️♨️
🚀1.人脸跟踪
人脸跟踪是让计算机在一幅画面中找出人脸的位置。毕竟计算机还达不到人类的智能水平,所以计算机在检测人脸的过程中实际上是在做“分类”操作,例如,计算机发现图像中有一些像素组成了眼睛的特征,那这些像素就有可能是“眼睛”;如果“眼睛”旁边还有“鼻子”和“另一只眼睛”的特征,那这三个元素所在的区域就很有可能是人脸区域;但如果“眼睛”旁边缺少必要的“鼻子”和“另一只眼睛”,那就认为这些像素并没有组成人脸,它们不是人脸图像的一部分。🌵
检测人脸的算法比较复杂,但OpenCV已经将这些算法封装好了,本节将介绍如何利用OpenCV自带的功能进行人脸跟踪。🌵
💥💥1.1 级联分类器
将一系列简单的分类器按照一定顺序级联到一起就构成了级联分类器,使用级联分类器的程序可以通过一系列简单的判断来对样本进行识别。例如,依次满足“有六条腿”“有翅膀”“有头胸腹”这三个条件的样本就可以被初步判断为昆虫,但如果任何一个条件不满足,则不会认为是昆虫。
OpenCV提供了一些已经训练好的级联分类器,这些级联分类器以XML文件的方式保存在以下路径中:
...\Python\Lib\site-packages\cv2\data\路径说明:
...\Python\:python虚拟机的本地目录。
\Lib\site-packages\:pip安装扩展包的默认目录。
\cv2\data\:OpenCV库的data文件夹。
说明:♨️♨️♨️
不同版本的OpenCV自带的级联分类器XML文件可能会有差别,data文件夹中缺少的XML文件可以到OpenCV的源码托管平台下载。
地址为:https://github.com/opencv/opencv/tree/master/data/haarcascades
每一个XML文件都对应一种级联分类器,但有些级联分类器的功能是类似的(正面人脸识别分类器就有三个),下表就是部分XML文件对应的功能。
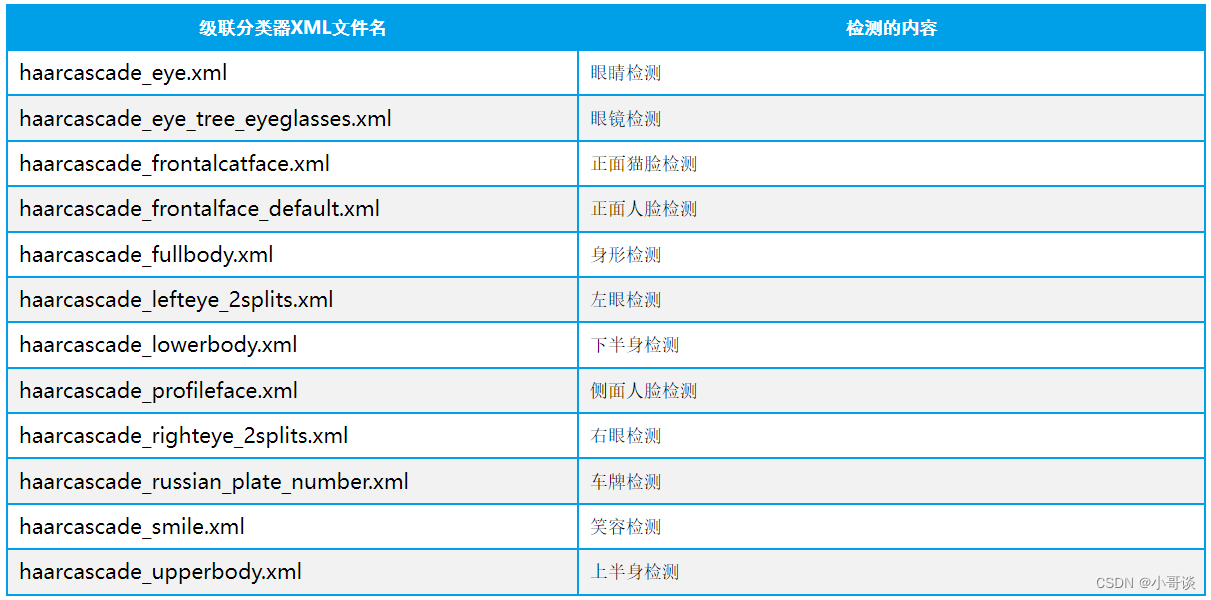
想要实现哪种图像检测,就要在程序启动时加载对应的级联分类器。🌱
💥💥1.2 方法
OpenCV实现人脸跟踪需要做两步操作:加载级联分类器和使用分类器识别图像。这两步操作都有对应的方法。🌱
首先是加载级联分类器,OpenCV通过CascadeClassifier()方法创建了分类器对象,其语法如下:
<CascadeClassifier object> = cv2.CascadeClassifier(filename)参数说明:
filename:级联分类器的XML文件名
返回值说明:
object:分类器对象
然后使用已经创建好的分类器对图像进行识别,这个过程需要调用分类器对象的detectMultiScale()方法,其语法如下:
objects = cascade.detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)对象说明:
cascade:已有的分类器对象。
参数说明:
image:待分析的图像。
scaleFactor:可选参数,扫描图像时的缩放比例。
minNeighbors:可选参数,每个候选区域至少保留多少个检测结果才可以判定为人脸。该值越大,分析的误差越小。
flags:可选参数,旧版本OpenCV的参数,建议使用默认值。
minSize:可选参数,最小的目标尺寸。
maxSize:可选参数,最大的目标尺寸。
返回值说明:
objects:捕捉到的目标区域数组,数组中每一个元素都是一个目标区域,每一个目标区域都包含四个值,分别是:左上角点横坐标、左上角点纵坐标、区域宽、区域高。
object的格式为:[[244 203 111 111] [432 81 133 133]]。
💥💥1.3 分析人脸位置
haarcascade_frontalface_default.xml是检测正面人脸的级联分类器文件,加载该文件就可以创建出追踪正面人脸的分类器,调用分类器对象的detectMultiScale()方法,得到的objects结果就是分析得出的人脸区域的坐标和宽高。下面通过一个实例来介绍如何实现此功能。🌱
案例1:
在图像的人脸位置绘制红框
将haarcascade_frontalface_default.xml文件放到项目根目录下的cascades文件夹中,加载此级联分类器之后,检测出所有可能是人脸的区域,通过for循环在这些区域上绘制红色边框。具体代码如下:
import cv2img = cv2.imread("model.png") # 读取人脸图像
# 加载识别人脸的级联分类器
faceCascade = cv2.CascadeClassifier("cascades\\haarcascade_frontalface_default.xml")
faces = faceCascade.detectMultiScale(img, 1.3) # 识别出所有人脸
for (x, y, w, h) in faces: # 遍历所有人脸的区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5) # 在图像中人脸的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体运行效果如图所示:

案例2:
戴墨镜特效
手机拍照软件自带各种各样的贴图特效,实际上这些贴图特效就是先定位了人脸位置,然后在人脸相应位置覆盖素材实现的。OpenCV也可以实现此类功能,例如为人脸添加戴墨镜的特效,需要实现以下三个步骤:
首先要编写一个覆盖图片的overlay_img()方法。因为素材中可能包含透明像素,这些透明像素不可以遮挡人脸,所以在覆盖背景图像时要做判断,忽略所有透明像素。判断一个像素是否为透明像素,只需将图像从3通道转为4通道,判断第4通道的alpha值,alpha值为1表示完全不透明,alpha值为表示完全透明。
然后要创建人脸识别级联分类器,分析出图像中人脸的区域。
最后要把墨镜图像按照人脸宽度进行缩放,并覆盖到人脸区域约三分之一的位置。
实现以上需求的具体代码如下:
import cv2# 覆盖图像
def overlay_img(img, img_over, img_over_x, img_over_y):"""覆盖图像:param img: 背景图像:param img_over: 覆盖的图像:param img_over_x: 覆盖图像在背景图像上的横坐标:param img_over_y: 覆盖图像在背景图像上的纵坐标:return: 两张图像合并之后的图像"""img_h, img_w, img_p = img.shape # 背景图像宽、高、通道数img_over_h, img_over_w, img_over_c = img_over.shape # 覆盖图像高、宽、通道数if img_over_c == 3: # 通道数小于等于3img_over = cv2.cvtColor(img_over, cv2.COLOR_BGR2BGRA) # 转换成4通道图像for w in range(0, img_over_w): # 遍历列for h in range(0, img_over_h): # 遍历行if img_over[h, w, 3] != 0: # 如果不是全透明的像素for c in range(0, 3): # 遍历三个通道x = img_over_x + w # 覆盖像素的横坐标y = img_over_y + h # 覆盖像素的纵坐标if x >= img_w or y >= img_h: # 如果坐标超出最大宽高break # 不做操作img[y, x, c] = img_over[h, w, c] # 覆盖像素return img # 完成覆盖的图像face_img = cv2.imread("peoples.png") # 读取人脸图像
glass_img = cv2.imread("glass.png", cv2.IMREAD_UNCHANGED) # 读取眼镜图像,保留图像类型
height, width, channel = glass_img.shape # 获取眼镜图像高、宽、通道数
# 加载级联分类器
face_cascade = cv2.CascadeClassifier("./cascades2/haarcascade_frontalface_default.xml")
garyframe = cv2.cvtColor(face_img, cv2.COLOR_BGR2GRAY) # 转为黑白图像
faces = face_cascade.detectMultiScale(garyframe, 1.3, 5) # 识别人脸
for (x, y, w, h) in faces: # 遍历所有人脸的区域gw = w # 眼镜缩放之后的宽度gh = int(height * w / width) # 眼镜缩放之后的高度度glass_img = cv2.resize(glass_img, (gw, gh)) # 按照人脸大小缩放眼镜overlay_img(face_img, glass_img, x, y + int(h * 1 / 3)) # 将眼镜绘制到人脸上
cv2.imshow("screen", face_img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体
运行效果如图所示:

🚀2.检测其他内容
OpenCV提供的级联分类器除了可以识别人脸以外,还有可以识别一些其他具有明显特征的物体,例如眼睛、行人等。本小节将介绍几个OpenCV自带的级联分类器的用法。🌿
💥💥2.1 眼睛跟踪
haarcascade_eye.xml是检测眼睛的级联分类器文件,加载该文件就可以追踪眼睛的分类器,下面通过一个实例来介绍如何实现此功能。🌱
案例3:
在图像的眼睛位置绘制红框
将haarcascade_eye.xml文件放到项目根目录下的cascades3文件夹中,加载此级联分类器之后,检测出所有可能是眼睛的区域,通过for循环在这些区域上绘制红色边框。具体代码如下:
import cv2img = cv2.imread("peoples.png") # 读取人脸图像
# 加载识别眼睛的级联分类器
eyeCascade = cv2.CascadeClassifier("cascades3\\haarcascade_eye.xml")
eyes = eyeCascade.detectMultiScale(img, 1.15) # 识别出所有眼睛
for (x, y, w, h) in eyes: # 遍历所有眼睛的区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 4) # 在图像中眼睛的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体运行效果如图所示:

💥💥2.2 行人跟踪
haarcascade_fullbody.xml是检测人体(正面直立全身或背影直立全身)的级联分类器文件,加载该文件就可以追踪人体的分类器,下面通过一个实例来介绍如何实现此功能。🍄
案例4:
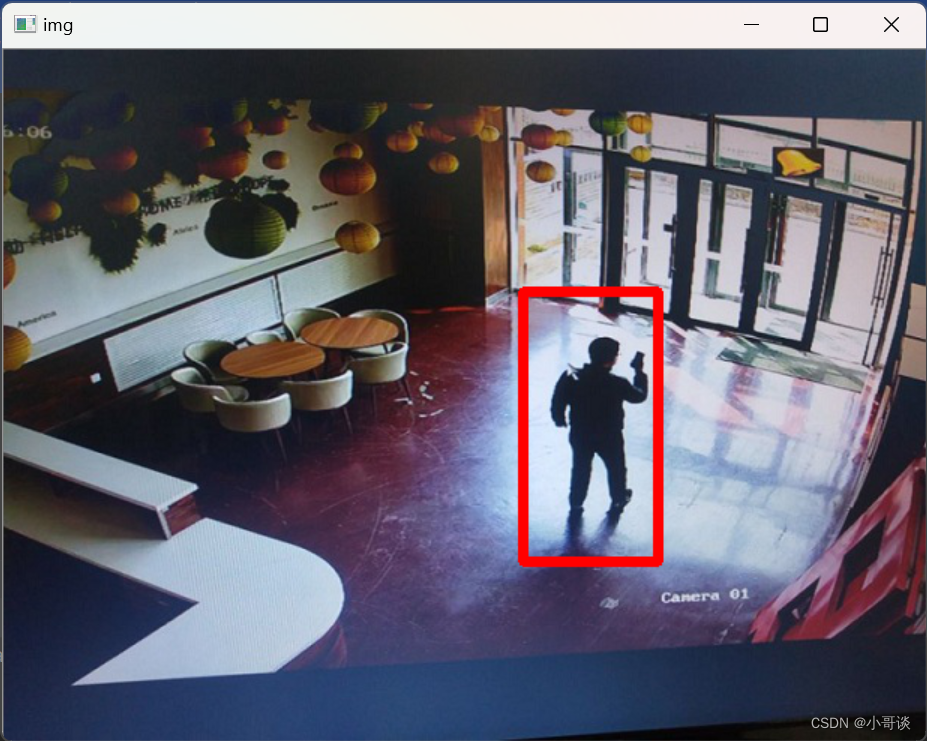
在图像里行人的位置
将haarcascade_fullbody.xml文件放到项目根目录下的cascades4文件夹中,加载此级联分类器之后,检测出所有可能是人形的区域,通过for循环在这些区域上绘制红色边框。具体代码如下:
import cv2
img = cv2.imread("monitoring.jpg") # 读取图像
# 加载识别类人体的级联分类器
bodyCascade = cv2.CascadeClassifier("cascades4\\haarcascade_fullbody.xml")
bodys = bodyCascade.detectMultiScale(img, 1.15, 4) # 识别出所有人体
for (x, y, w, h) in bodys: # 遍历所有人体区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5)# 在图像中人体的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体运行效果如图所示:
💥💥2.3 车牌跟踪
haarcascade_russian_plate_number.xml是检测汽车车牌的级联分类器文件,虽然文件名直译过来是“俄罗斯车牌”,但同样可以用于检测中国的车牌,只不过精准度稍微低了一点。加载该文件就可以追踪图片中的车牌,下面通过一个实例来介绍如何实现此功能。🌳
案例5:
标记图像中车牌的位置
将haarcascade_russian_plate_number.xml文件放到项目根目录下的cascades5文件夹中,加载此级联分类器之后,检测出所有可能是车牌的区域,通过for循环在这些区域上绘制红色边框。具体代码如下:
import cv2img = cv2.imread("car.jpg") # 读取车的图像
# 加载识别车牌的级联分类器
plateCascade = cv2.CascadeClassifier("cascades5\\haarcascade_russian_plate_number.xml")
plates = plateCascade.detectMultiScale(img, 1.15, 4) # 识别出所有车牌
for (x, y, w, h) in plates: # 遍历所有车牌区域cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5) # 在图像中车牌的位置绘制方框
cv2.imshow("img", img) # 显示最终处理的效果
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体运行效果如下所示:

🚀3.人脸识别
OpenCV提供了三种人脸识别方法,分别是Eigenfaces、Fisherfaces和LBPH。这三种方法都是通过对比样本的特征最终实现人脸识别。因为这三种算法提取特征的方式不一样,侧重点不同,所以不能分出孰优孰劣,只能说每种方法都有各自的识别风格。🌱
OpenCV为每一种人脸识别方法都提供了创建识别器、训练识别器和识别这三个方法,这三个方法的语法非常相似。本小节将简单介绍如何使用这些方法。🌱
💥💥3.1 Eigenfaces人脸识别器
Eigenfaces也被叫作“特征脸”。 Eigenfaces通过PCA(主成分分析技术)方法将人脸数据转换到另外一个空间维度去做相似性计算。在计算过程中,算法可以忽略掉一些无关紧要的数据,仅识别一些具有代表性的“特征”数据,最后根据这些“特征”来识别人脸。🌱
开发者需要通过三个方法来完成人脸识别操作。
🍀(1)通过cv2.face.EigenFaceRecognizer_create()方法创建Eigenfaces人脸识别器,其语法如下:
recognizer = cv2.face.EigenFaceRecognizer_create(num_components, threshold)参数说明:
num_components:可选参数,PCA方法中保留的分量个数,建议使用默认值
thresh:可选参数,人脸识别时使用的阈值,建议使用默认值。
返回值说明:
recognizer:创建完的Eigenfaces人脸识别器对象。
🍀(2)创建完识别器对象之后,需要通过对象的train()方法来训练识别器。建议每个人都给出2张以上的照片作为训练样本。train()方法的语法如下:
recognizer.train(src, labels)对象说明:
recognizer:已有的Eigenfaces人脸识别器对象。
参数说明:
src:用来训练的人脸图像样本列表,格式为list。样本图像必须宽高一致。
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应。
🍀(3)训练完识别器之后就可以通过识别器的predict()方法来识别人脸了,该方法会对比样本的特征,给出最相近的结果和评分,其语法如下:
label, confidence = recognizer.predict(src)对象说明:
recognizer:已有的Eigenfaces人脸识别器对象。
参数说明:
src:需要识别的人脸图像,该图像宽高必须与样本一致。
返回值说明:
label:与样本匹配程度最高的标签值。
confidence:匹配程度最高的信用度评分。评分小于5000就可以认为匹配程度较高,0分表示两幅图像完全一样。
案例6:
使用Eigenfaces识别人脸
现以两个人的照片作为训练样本,第一个人的照片如图8至图10所示,第二个人的照片如图11至图13所示。

用于识别的照片如图14所示。

创建Eigenfaces人脸识别器对象,训练以上样本之后,判断图13所示是哪一个人,具体代码如下:
import cv2
import numpy as npphotos = list() # 样本图像列表
lables = list() # 标签列表
photos.append(cv2.imread("face\\summer1.png", 0)) # 记录第1张人脸图像
lables.append(0) # 第1张图像对应的标签
photos.append(cv2.imread("face\\summer2.png", 0)) # 记录第2张人脸图像
lables.append(0) # 第2张图像对应的标签
photos.append(cv2.imread("face\\summer3.png", 0)) # 记录第3张人脸图像
lables.append(0) # 第3张图像对应的标签photos.append(cv2.imread("face\\Elvis1.png", 0)) # 记录第4张人脸图像
lables.append(1) # 第4张图像对应的标签
photos.append(cv2.imread("face\\Elvis2.png", 0)) # 记录第5张人脸图像
lables.append(1) # 第5张图像对应的标签
photos.append(cv2.imread("face\\Elvis3.png", 0)) # 记录第6张人脸图像
lables.append(1) # 第6张图像对应的标签names = {"0": "Summer", "1": "Elvis"} # 标签对应的名称字典recognizer = cv2.face.EigenFaceRecognizer_create() # 创建特征脸识别器
recognizer.train(photos, np.array(lables)) # 识别器开始训练i = cv2.imread("face\\summer4.png", 0) # 待识别的人脸图像
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字
cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体
运行效果如图所示:

程序对比样本特征分析得出,被识别的人物特征最接近的是“Summer”。🍂
💥💥3.2 Fisherfaces人脸识别器
Fisherfaces是由Ronald Fisher最早提出的,这也是Fisherfaces名字的由来。Fisherfaces通过LDA(线性判别分析技术)方法也会将人脸数据转换到另外一个空间维度去做投影计算,最后根据不同人脸数据的投影距离来判断其相似度。🍃
开发者需要通过三个方法来完成人脸识别操作。
🍀 (1)通过cv2.face.FisherFaceRecognizer_create()方法创建Fisherfaces人脸识别器,其语法如下:
recognizer = cv2.face.FisherFaceRecognizer_create(num_components, threshold)参数说明:
num_components:可选参数,通过Fisherface方法进行判断分析时保留的分量个数,建议使用默认值。
thresh:可选参数,人脸识别时使用的阈值,建议使用默认值。
返回值说明:
recognizer:创建完的Fisherfaces人脸识别器对象。
🍀 (2)创建完识别器对象之后,需要通过对象的train()方法来训练识别器。建议每个人都给出2张以上的照片作为训练样本。train()方法的语法如下:
recognizer.train(src, labels)对象说明:
recognizer:已有的Fisherfaces人脸识别器对象。
参数说明:
src:用来训练的人脸图像样本列表,格式为list。样本图像必须宽高一致。
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应。
🍀 (3)训练完识别器之后就可以通过识别器的predict()方法来识别人脸了,该方法会对比样本的特征,给出最相近的结果和评分,其语法如下:
label, confidence = recognizer.predict(src)对象说明:
recognizer:已有的Fisherfaces人脸识别器对象。
参数说明:
src:需要识别的人脸图像,该图像宽高必须与样本一致。
返回值说明:
label:与样本匹配程度最高的标签值。
confidence:匹配程度最高的信用度评分。评分小于5000就可以认为匹配程度较高,0分表示两幅图像完全一样。
下面通过一个实例来演示Fisherfaces人脸识别器的用法。
案例7:
使用Fisherfaces识别人脸
现以两个人的照片作为训练样本,第一个人的照片如图15至图17所示,第二个人的照片如图18至图20所示。

用于识别的照片如图21所示。

创建Fisherfaces人脸识别器对象,训练以上样本之后,判断图20是哪一个人,具体代码如下:
import cv2
import numpy as npphotos = list() # 样本图像列表
lables = list() # 标签列表
photos.append(cv2.imread("face1\\Mike1.png", 0)) # 记录第1张人脸图像
lables.append(0) # 第1张图像对应的标签
photos.append(cv2.imread("face1\\Mike2.png", 0)) # 记录第2张人脸图像
lables.append(0) # 第2张图像对应的标签
photos.append(cv2.imread("face1\\Mike3.png", 0)) # 记录第3张人脸图像
lables.append(0) # 第3张图像对应的标签photos.append(cv2.imread("face1\\kaikai1.png", 0)) # 记录第4张人脸图像
lables.append(1) # 第4张图像对应的标签
photos.append(cv2.imread("face1\\kaikai2.png", 0)) # 记录第5张人脸图像
lables.append(1) # 第5张图像对应的标签
photos.append(cv2.imread("face1\\kaikai3.png", 0)) # 记录第6张人脸图像
lables.append(1) # 第6张图像对应的标签names = {"0": "Mike", "1": "kaikai"} # 标签对应的名称字典recognizer = cv2.face.FisherFaceRecognizer_create() # 创建线性判别分析识别器
recognizer.train(photos, np.array(lables)) # 识别器开始训练i = cv2.imread("face1\\Mike4.png", 0) # 待识别的人脸图像
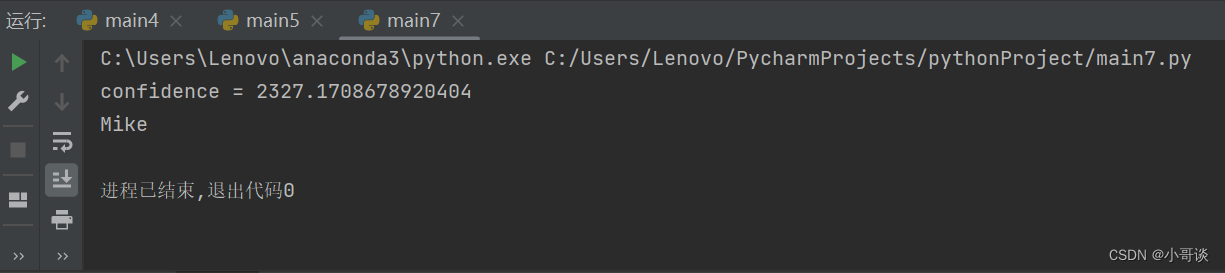
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体
运行效果如图所示:
💥💥3.3 Local Binary Pattern Histogram人脸识别器
Local Binary Pattern Histogram简称LBPH,翻译过来就是局部二值模式直方图,这是一种基于局部二值模式算法,善于捕获局部纹理特征。🌵
开发者需要通过三个方法来完成人脸识别操作。
🌵(1)通过cv2.face. LBPHFaceRecognizer_create()方法创建LBPH人脸识别器,其语法如下:
recognizer = cv2.face.LBPHFaceRecognizer_create(radius, neighbors, grid_x, grid_y, threshold)参数说明:
radius:可选参数,圆形局部二进制模式的半径,建议使用默认值。
neighbors:可选参数,圆形局部二进制模式的采样点数目,建议使用默认值。
返回值说明:
grid_x:可选参数,水平方向上的单元格数,建议使用默认值。
grid_y:可选参数,垂直方向上的单元格数,建议使用默认值。
threshold:可选参数,人脸识别时使用的阈值,建议使用默认值。
🌵(2)创建完识别器对象之后,需要通过对象的train()方法来训练识别器。建议每个人都给出2张以上的照片作为训练样本。train()方法的语法如下:
recognizer.train(src, labels)对象说明:
recognizer:已有的LBPH人脸识别器对象。
参数说明:
src:用来训练的人脸图像样本列表,格式为list。样本图像必须宽高一致。
labels:样本对应的标签,格式为数组,元素类型为整数。数组长度必须与样本列表长度相同。样本与标签按照插入顺序一一对应。
🌵(3)训练完识别器之后就可以通过识别器的predict()方法来识别人脸了,该方法会对比样本的特征,给出最相近的结果和评分,其语法如下:
label, confidence = recognizer.predict(src)对象说明:
recognizer:已有的LBPH人脸识别器对象。
参数说明:
src:需要识别的人脸图像,该图像宽高必须与样本一致。
返回值说明:
label:与样本匹配程度最高的标签值。
confidence:匹配程度最高的信用度评分。评分小于50就可以认为匹配程度较高,0分表示两幅图像完全一样。
下面通过一个实例来演示LBPH人脸识别器的用法。
案例8:
使用LBPH识别人脸
现以两个人的照片作为训练样本,第一个人的照片如图22至图24所示,第二个人的照片如图25至图27所示。

用于识别的照片如图28所示。

创建LBPH人脸识别器对象,训练以上样本之后,判断图27是哪一个人,具体代码如下:
import cv2
import numpy as npphotos = list() # 样本图像列表
lables = list() # 标签列表
photos.append(cv2.imread("face3\\lxe1.png", 0)) # 记录第1张人脸图像
lables.append(0) # 第1张图像对应的标签
photos.append(cv2.imread("face3\\lxe2.png", 0)) # 记录第2张人脸图像
lables.append(0) # 第2张图像对应的标签
photos.append(cv2.imread("face3\\lxe3.png", 0)) # 记录第3张人脸图像
lables.append(0) # 第3张图像对应的标签photos.append(cv2.imread("face3\\ruirui1.png", 0)) # 记录第4张人脸图像
lables.append(1) # 第4张图像对应的标签
photos.append(cv2.imread("face3\\ruirui2.png", 0)) # 记录第5张人脸图像
lables.append(1) # 第5张图像对应的标签
photos.append(cv2.imread("face3\\ruirui3.png", 0)) # 记录第6张人脸图像
lables.append(1) # 第6张图像对应的标签names = {"0": "LXE", "1": "RuiRui"} # 标签对应的名称字典recognizer = cv2.face.LBPHFaceRecognizer_create() # 创建LBPH识别器
recognizer.train(photos, np.array(lables)) # 识别器开始训练i = cv2.imread("face3\\ruirui4.png", 0) # 待识别的人脸图像
label, confidence = recognizer.predict(i) # 识别器开始分析人脸图像
print("confidence = " + str(confidence)) # 打印评分
print(names[str(label)]) # 数组字典里标签对应的名字cv2.waitKey() # 按下任何键盘按键后
cv2.destroyAllWindows() # 释放所有窗体
运行效果如图所示:
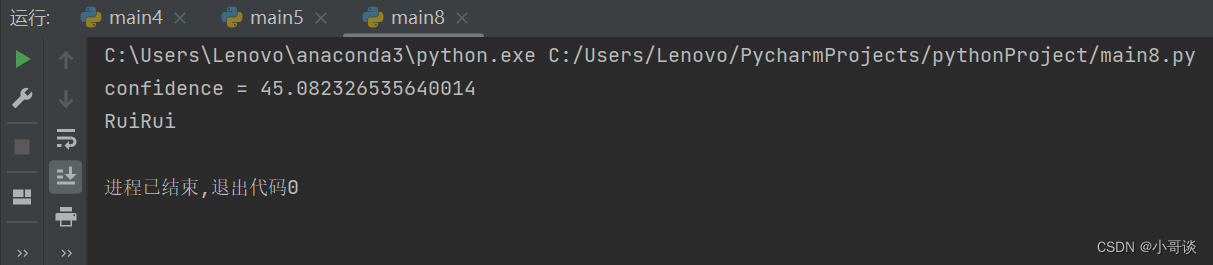
程序对比样本特征分析得出,被识别的人物特征最接近的是“RuiRui”。✅