101.如何让写出去的数据能成功生效?
flush()刷新数据
close()方法是关闭流,关闭包含刷新,关闭后流不可以继续使用了。
102.学会字节流完成文件的复制(支持一切的文件)
public class CopyDemo05 {
public static void main(String[] args) {
try {
// 1、创建一个字节输入流管道与原视频接通
InputStream is = new FileInputStream("file-io-app/src/out04.txt");
// 2、创建一个字节输出流管道与目标文件接通
OutputStream os = new FileOutputStream("file-io-app/src/out05.txt");
// 3、定义一个字节数组转移数据
byte[] buffer = new byte[1024];
int len; // 记录每次读取的字节数。
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0 , len);
}
System.out.println("复制完成了!");
// 4、关闭流。
os.close();
is.close();
} catch (Exception e){
e.printStackTrace();
}
}
}
103.字节流适合做一切文件数据的拷贝吗?
任何文件的底层都是字节,拷贝是- -字不漏的转移字节,只要前后文件格式、编码-致没有任何问题。
104.字节流的适用范围
适合文件(数据)的拷贝,不适合读取中文字输出
105.资源的两种释放方式
try-catch-finally
finally: 在异常处理时提供finally块来执行所有清除操作,比如说I0流中的释放资源
特点:被finally控制的语句最终一定会执行, 除非JVM退出
●异常处理标准格式: try...catch..finally
try-catch-finally格式
try
File0utputStream fos = new FileOutputStream("a.txt");
fos.write(97);
fos.close();
} catch (IOException e) {
e. printStackTrace( );
} finally{
}
106.如何使用字节输入流读取中文内容输出不乱码呢?
定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。
可以定义与文件- -样大的字节数组读取,也可以使用官方API.
107.直接把文件数据全部读取到-一个字节数组可以避免乱码,是否存在问题?
如果文件过大,字节数组可能引起内存溢出。
108.静态代码块,构造代码块,构造方法执行顺序
public class ExA {
private static ExA a = new ExA();
static {
System.out.println("父类--静态代码块");
}
public ExA() {
System.out.println("父类--构造函数");
}
{
System.out.println("父类--非静态代码块");
}
public static void main(String[] args) {
new ExB();
}
}
class ExB extends ExA {
private static ExB b = new ExB();
static {
System.out.println("子类--静态代码块");
}
{
System.out.println("子类--非静态代码块");
}
public ExB() {
System.out.println("子类--构造函数");
}
109.==和equals区别
1.如果是基本类型比较,那么只能用==来比较,不能用equals 比较的数值2.对于基本类型的包装类型,比如Boolean、Character、Byte、Shot、Integer、Long、Float、Double等的引用变量,==是比较地址的,而equals是比较内容的。
110.while循环和do–while的区别
while循环: 先判断条件是否符合要求,在执行循环体。 do-while循环 先执行循环体,在判断执行条件是否符合要求
111.数组的特点
1.一旦初始化,容量不可变2.只能存储同一种数据类型的数据3.数组中的元素与元素之间的内存地址是连续的
112.类的三个基本特征是什么?
1.封装 属性私有化private 对外界提供对应的Setter和Getter方法,保证了数据的安全性 例如电视机,不能直接通过电视机内部来操作电视机,可以通过遥控器来控制电视 如果你用publice,当你插入一个年龄时候,你不小心输入负数,会直接插入,但是年龄不可能为负数,但是用封装的话会在 Getter和Setter方法里面进行一个判断2.继承 子类可以继承父类,子类可以使用父类的非私有化属性和方法 java是单继承语言3.多态 父类引用指向子类对象,接口引用指向实现类对象 作用: 1.扩展方法的参数范围 2.统一返回值类型,便于后期处理,编译看左,运行看右
113.什么是方法的重载、方法的重写
方法的重载发生在
1.同一个类中可以使用不同的参数实现不同的效果
2.要求方法名必须一致
3,要求形式参数必须不一致
方法的重写是发生在父子类之间的
1.重写要求方法声明必须一致(权限修饰符 返回值类型 方法名 (形式参数))
2.可以重写方法体内容
3.子类或者实现类中可以重写
4.强制要求使用@Override 开启代码格式严格检查
114.instanceof关键字的作用
instanceof 运算符的前一个操作符是一个引用变量,后一个操作数通常是一个类(可以是接口),用于判断前面的对象是否是后面的类,或者其子类、实现类的实例。如果是返回true,否则返回false。使用instanceof关键字做判断时, instanceof 操作符的左右操作数必须有继承或实现关系
115.String、StringBuffer和StringBuilder的区别是什么?
1.String是字符串常量,StringBuffer和StringBulider都是字符串变量。后两者字符内容可变,而前者内容不可变
2.StringBuffer是线程安全的,而StringBulider是非线程安全的
3.String不可变是类声明的final类
116.ArrayList和LinkedList区别
ArrayList 和 LinkedList都是List的实现类,List集合主要有两个特点:1、有序;2、可重复。ArrayList底层是可变的数组 查询快,增删慢LinkedList底层是双向链表 增删慢,查询快
117.HashSet集合的特点
1.HashSet无序,不能存储重复元素
2.HashSet不确保插入顺序
3.HashSet是非线程安全的。
118.线程安全的集合
Vector,hashtable,concurrenthashmap
119.HashSet添加对象时,如何判断对象是否相同?
存对象时,hashSet集合首先调用该对象的hashCode方法来获得该对象的hashCode值(一定的算法),与hash表中的值进行比较。如果不存在,则直接把该对象存入集合中,并把该hashCode值存入hash表中,此次add操作结束。如果存在,则进行下面的计算。
通过”==”操作符判断已经存入的对象与要存入的对象是否为同一对象。如果true则集合认为添加相同对象,add失败。如果false(不是同一对象),则进行下面的计算。(这一条很重要,保证了,不管如何操作,在HashSet中都不可能存入同一个对象两次)
调用要添加的对象的equals()方法,并把集合中的另一元素作为参数传入,如果返回值为true则集合认为添加相同对象,add失败。否则添加成功。
120.JDK1.8中,简述HashMap的底层数据结构?
HashMap底层是一个哈希表 ,HashMap是由数组+链表组成的,数组是HashMap的主体,而链表是为了解决哈希冲突而存在的,如果定位的数组不含链表,那么对于查找,添加等操作非常快,仅需要一次寻址就可以了,如果定位的数组包含链表,首先遍历链表,如果存在即覆盖,不存在就新增,对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找,判断内容是否相等。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
继续向下和其他的数据的key进行比较,如果都不相等,则划出一个结点存储数据,如果结点长度即链表长度大于阈值8并且数组长度大于64则将链表变为红黑树。
jdk1.8之后的HashMap是 数组+链表+红黑树
由于数组+链表会产生链表过长的现象,链表过长使得key值查找时候效率低,数组+链表+红黑树这个时候大大提高了效率
121.HashMap是否线程安全的?有哪些线程安全的map结构?
不是,多线程调用的情况下扩容会出问题。vactor、hashtable、concurrentHashMap、copyOnWriteArrayList是线程安全的。
122.throw和throws关键字区别
throw是语句中抛出异常,一般都是在代码块中,当程序中某种逻辑错误时由开发人员主动抛出自己指定类型异常。创建的是一个异常对象,确定某种异常才能使用,定义在方法体内,必须搭配 try / catch 或者 throws 一起使用。在方法参数后(方法头的位置),throws 可以 跟着 多个异常名,多个抛出的异常用逗号隔开。表示在调用该方法的类中抛出异常(可以理解往上抛),不在该类中解决,预计这个方法可能出现的异
123.泛型的三种使用
泛型的三种使用方式:**泛型类**,**泛型方法**,**泛型接口**
1.泛型类
public class 类名 <泛型类型1,...> {
}
注意事项:泛型类型必须是引用类型(非基本数据类型)
2.泛型方法
public <泛型类型> 返回类型 方法名(泛型类型 变量名) {
}
方法声明中定义的形参只能在该方法里使用,而接口、类声明中定义的类型形参则可以在整个接口、类中使用。当调用fun()方法时,根据传入的实际对象,编译器就会判断出类型形参T所代表的实际类型。
class Demo{
public <T> T fun(T t){ // 可以接收任意类型的数据
return t ; // 直接把参数返回
}
};
public class GenericsDemo26{
public static void main(String args[]){
Demo d = new Demo() ; // 实例化Demo对象
String str = d.fun("汤姆") ; // 传递字符串
int i = d.fun(30) ; // 传递数字,自动装箱
System.out.println(str) ; // 输出内容
System.out.println(i) ; // 输出内容
}
};
3.泛型接口
public interface 接口名<泛型类型> {
}
/**
* 泛型接口的定义格式: 修饰符 interface 接口名<数据类型> {}
*/
public interface Inter<T> {
public abstract void show(T t) ;
}
/**
* 子类是泛型类
*/
public class InterImpl<E> implements Inter<E> {
@Override
public void show(E t) {
System.out.println(t);
}
}
Inter<String> inter = new InterImpl<String>() ;
inter.show("hello") ;
124.高级通配符
<? extends T> 上界通配符
上界通配符顾名思义,<? extends T>表示的是类型的上界【包含自身】,因此通配的参数化类型可能是T或T的子类
<? super T> 下界通配符
下界通配符<? super T>表示的是参数化类型是T的超类型(包含自身),层层至上,直至Object
125.Java中的基本数据类型有哪些?占用内存空间大小是多少?
| 类型 | 字节 | 位数 | 存储范围 |
| byte | 1 | 8 | -128~127 |
| short | 2 | 16 | -32768~32767 |
| int | 4 | 32 | -2^31~2^31-1 |
| float | 4 | 32 | -2^31~2^31-1 |
| dounle | 8 | 64 | -2^63~2^63-1 |
| long | 8 | 64 | -2^63~2^63-1 |
| char | 2 | 16 | -2^15~2^15-1 |
| boolean | 4 | 32 | -2^31~2^31-1 |
126.计算机中最小操作单位是什么?常见存储单位有哪些?
位:计算机最小的数据单位,每一位只能是0或1
计算机存储单位一般用B,KB,MB,GB,TB,EB,ZB,YB,BB来表示,它们之间的关系是:
位 bit (比特)(BinaryDigits):存放一位二进制数,即 0 或 1,b是最小的存储单位。
字节 byte:8个二进制位为一个字节(B),B是最常用的单位。1B=8b
1KB (Kilobyte千字节)=1024B,
1MB(Megabyte 兆字节简称“兆”)=1024KB,
1GB (Gigabyte 吉字节又称“千兆”)=1024MB,
1TB (Trillionbyte万亿字节太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节拍字节)=1024TB,
1EB(Exabyte百亿亿字节艾字节)=1024PB,
1ZB(Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Jottabyte 一亿亿亿字节 尧字节)= 1024ZB,
1BB (Brontobyte一千亿亿亿字节)= 1024 YB.
注:“兆”为百万级数量单位。
127.常见分支结构格式
单分支语句
格式:
if (布尔表达式) {
语句//布尔表达式为true时执行
}
双分支语句
格式:
if(布尔表达式) {
语句1//布尔表达式为true时执行
}else{
语句2/ /布尔表达式为false时执行
}
多分支语句
格式:
if (布尔表达式1) {
语句1//布尔表达式1为true时执行
}else if (布尔表达式2) {
语句2/ /布尔表达式2为true时执行
}else if (布尔表达式3) {
语句3//布尔表达式3为true时执行
}else{
语句4//以上布尔表达式都为false时执行
}
嵌套Q语句
格式:
if (布尔表达式1) {
语句1//布尔表达式1为true时执行
if (布尔表达式2) {
语句2//布尔表达式2为true时执行0-
}else{
语句3//布尔表达式2为false时执行}
}
switch语句
格式: .
swi tch (expression) {
case valuel :
语句
break ;
case value2 :
语句
break ;
default :
语句
}
128. for循环结构格式和执行流程
1、语法格式
for (初始化变量; 条件表达式; 控制体语句) {undefined
语句体;
}
2、执行流程:
1)初始化变量
2)判断条件表达式,表达式成立,执行循环体;表达式不成立,退出for循环
3)执行控制语句(控制语句一般为自增1或者自减1)
4)跳转到步骤二继续执行
129.命名规范要求简述
1.项目名全部小写
2.包名全部小写
3.类名首字母大写,如果类名由多个单词组成,每个单词的首字母都要大写
如:public class MyFirstClass{}
4.变量名、方法名首字母小写,如果名称由多个单词组成,每个单词的首字母都要大写。
如:int index=0;
public void toString(){}
5、 常量名全部大写
如:public static final String GAME_COLOR=”RED”;
6、所有命名规则必须遵循以下规则:
1)、名称只能由字母、数字、下划线、$符号组成
2)、不能以数字开头
3)、名称不能使用JAVA中的关键字。
4)、坚决不允许出现中文及拼音命名。
130. 数组的定义格式和各元素的含义
格式:
数据类型[] 数组名 = new 数据类型[容量];
赋值号左侧:
数据类型:
明确当前数组存储的数据类型是什么,要求只能存储对应数据类型,严格遵守数据类型一致化要求。
类似于
停车场每一个位置都是停车使用,类型一致
洗浴中心,每一个衣柜都是存储衣服,类型一致
[]:
1. 明确告知编译器,当前创建的数据情况为数组。
2. 数组名是一个【引用数据类型】★
引用数据类型 类比文章中的 [1] 引用,用于引入参考文献。
具有跳转性,和指向性。
数组名:
1. 操作数组非常重要的名称
2. 数组名是一个【引用数据类型】★
类似于
停车场 A区 B区
洗浴中心 1层 2层 3层
赋值号右侧:
new:
1. 在内存的【堆区】申请目前数据类型所需空间
2. 擦除整个空间中所有的数据内容。
类似于:
内存堆区可以认为是一块空地,里面有杂物
new 会根据自己所需申请合适的面积
同时会将所有的杂物全部清理干净。
数据类型:
前后呼应,前后一致,明确当前数组可以存储的类型是哪一个,有且只能存储对应类型,严格遵从数据类型一致化
[容量]:
为整数 int 范围以内
明确当前数组可以存储指定数据类型最大容量,并且一旦确定,无法修改
131.选择排序算法
目标数组:
int[] arr = {1, 3, 5, 7, 9, 2, 4, 6, 8, 10};
/**
* 选择排序算法,核心: 找极值下标,交换数据位置
*
* @param arr 需要排序的 int 类型数组
*/
public static void selectSort(int[] arr) {
// 2. for - i 循环控制执行排序操作核心模块的次数
for (int i = 0; i < arr.length - 1; i++) {
// 3. for - j 找出数组中未排序数据的极值下标
int index = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[index] < arr[j]) {
index = j;
}
}
// 4. 交换数据位置,判断 index 值是否有变化
if (index != i) {
int temp = arr[index];
arr[index] = arr[i];
arr[i] = temp;
}
}
}
132.equals 和 hashCode方法重写要求
equals方法**:比较两个对象是否一致,在Object类内默认方式是比较两个对象的地址是否一致。
代码中存在一些情况,需要比较的是两个对象中保存的内容是一直,但是使用Object类内继承而来的equals方法,是不合理的!!!
【实现】
这里需要重写equals方法
* 重写equals方法
* 1. 判断两个对象是不是同一个对象。如果调用方法的类对象和传入参数类对象
* 地址一致,那就是同一个对象,返回true,搞定!!!
*
* 2. equals方法参数是Object类型,那也就是说任何类型的数据都可以作为参数。
* 两个数据类型不一致,是否需要进行比较操作。
* 判断数据类型是否一致
* 使用关键字 instanceOf,同数据类型继续运行,非同类型,结束判断返回false
* 格式:
* 类对象 instanceOf 类名
*/
@Override
public boolean equals(Object obj) {
// 1. 判断是不是同地址对象
if (this == obj) {
return true;
}
// 2. 类型是否一致
if (!(obj instanceof Student)) {
return false;
}
// 数据类型强制转换
Student stu = (Student) obj;
return this.id == stu.id
// this.name.equals(stu.name) 该equals方法是String类equals方法
&& this.name.equals(stu.name)
&& this.age == stu.age
&& this.gender == stu.gender;
}
hashCode**方法****
在Object类内,hashCode方法,返回的内容是当前对象的空间首地址十进制展示方式。
当前类重写equals方法之后,两个当前类对象比较结果为true,那么要求这两个对象的hashCode必须一致!!!
hashCode使用有一个唯一原则。
一般会参考参与equals比较的所有成员变量来组成对应的hashCode,这里会使用到一些Java中提供的计算哈希值的方法。
hashCode使用未进行重写的情况下,会使用地址作为hashCode对应的数据,重写之后,不再使用地址。重写之后hashCode 不对应当前对象所在地址。
@Override
public int hashCode() {
// 这里通过Objects 工具类内的hash方法,传入所有参与equals比较的成员变量
// 得到对应的hashCode值
return Objects.hash(id, name, age, gender);
}
133. 为什么要同时重写重写hashcode方法?
未重写之前hashcode方法返回的是对象的32位JVM内存地址,那么当我们把这不同地址但是实际相等的两个对象放进HashMap里面的时候它们不被看成是同一个对象,占据了两个位置。这个跟我们的预期不符,所以要重写hashcode方法
134.简述成员变量和局部变量的区别
成员变量和局部变量的区别
(1)在类中的位置不同
成员变量:类中方法外
局部变量:方法定义中或者方法声明上
(2)在内存中的位置不同
成员变量:在堆中
局部变量:在栈中
(3)生命周期不同
成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:随着方法的调用而存在,随着方法的调用完毕而消失
(4)初始化值不同
成员变量:有默认值
局部变量:没有默认值,必须定义,赋值,然后才能使用
135.定义接口的格式,成员变量的缺省属性是什么?成员方法的缺省属性是什么?如果希望接口中的成员方法有自己的方法体,如何实现
成员变量默认为public、static、final修饰
成员方法默认为public、abstract修饰*
JDK1.8后接口中的方法被允许为“默认方法”和静态方法,即jdk1.8下接口中方法可以被如下修饰符/关键字修饰:public, abstract, default, static 和 strictfp。
public interface MyInterface {
default String getName(){
return "呵呵呵";
}
//public, abstract, default, static and strictfp are permitted
strictfp static void show(){
System.out.println("接口中的静态方法");
}
}
136.一个类遵从接口的格式和要求有什么? 认真思考
class A implements 接口名 {
需要实现在接口中定义的缺省属性abstract成员方法
}
abstract class B implements 接口名 {
}
interface A extends B {
}
137.使用代码演示接口对应的匿名内部类使用方法
匿名内部类实现抽象类
public abstract class Animal {
public abstract void eat();
}
使用匿名内部类不必再写子类实现父类
格式:
new类名/接口名(){
重写抽象方法
}
public class Demo01 {
public static void main(String[] args) {
//整体就等效于: 是Animal父类的子类对象
new Animal(){
@Override
public void eat() {
System.out . println("狗吃肉");
}.eat();*/
}
}
String name =“哈士奇"; // 通过匿名内部类访问局部变量。在JDK8版本之前,必须加final关键字
//name =“金毛”; //不可以
Animal a = new Animal(){
@Override
public void eat() {
System . out . println("狗吃肉");
}
};
a.eat();
匿名内部类实现接口
public interface Inter {
public abstract void method( ) ;
}
public class Demo02 {
public static void main(String[] args) {
/*new Inter() {
@Override
public void method() {
System. . out .println("我是重写后的method方法");
}
}. method();*/
function(
new Inter() {
@Override
public void method() {
System. out . println(”我是重写后的method方法");
}
);
}
public static void function(Inter i) { // Inter i
i . method();
}
对于作为方法参数时传递,类和接口中只有一个抽象方法
138.自增自减
int num1 = 5;
int num2 =3;
int num3 = num1++ + ++num2;
int num4 = num1++ + --num2;
System.out.println(num1); //7
System.out.println(num2); //3
System.out.println(num3); //9
System.out.println(num4);//9
139. static修饰成员方法有什么特征,static修饰静态代码块有什么特征?
a. IDE工具推荐使用类名直接调用静态成员方法,不推荐使用类对象调用静态成员方法,提示与对象无关。【没有对象】
b. 静态成员方法不可以直接使用类内的非静态成员。【没有对象】
c. 静态成员方法可以直接使用类内的静态成员。【难兄难弟,互不嫌弃】
d. 静态成员方法常用于工具类封装,采用类名直接调用方法,提高开发效率。
1.格式static{静态代码块中执行的代码}2.什么时候执行随着类的加载而加载,并且只执行一次3.作用用于给类初始化4.特点优先于主函数执行,在静态方法之前执行
public class Test {
static{
System.out.println("a");
}
public static void main(String[] args) {
Demo d1 = new Demo();
Demo d2 = new Demo();
d1.method();
d2.method();
new Demo();
System.out.println("over");
}
}
class Demo{
static{
System.out.println("b");
}
public static void method(){
System.out.println("c");
}
}
abcc
140.static修饰静态成员变量特征
a. static 修饰的静态成员变量推荐使用类名调用,不推荐使用类对象调用,IDE提示 静态成员变量与对象无关。【没有对象】
b. static 修饰的静态成员变量,在 .class 字节码文件加载过程中,直接定义在内存的【数据区】,早于类对象出现,同时在程序退出过程中,JVM的GC机制首先会销毁类对象占用内存空间,再来处理静态成员变量占用的数据区内存空间。晚于类对象销毁。静态成员变量整个生命周期是远远高于类对象,【没有对象】
c. static 修饰的静态成员变量属于类内的【共享资源】,一处修改,处处受影响
d. 类对象具有使用权
141.反射中获取Constructor对象和执行使用的方法,已经授予权限的方法
public Constructor[ ] getConstructors();
获取当前Class类对象对应Java文件中,所有[public
修饰构造方法的类对象数组]
public Constructor[ ] getDeclaredConstructors();
[暴力反射]
获取当前Class类对象对应Java文件中,所有[构造方法
的类对象数组],包括私有化构造方法。
141.1反射:框架设计的灵
* 框架:半成品软件。可以在框架的基础上进行软件开发,简化编码
* 反射:将类的各个组成部分封装为其他对象,这就是反射机制* 好处:1. 可以在程序运行过程中,操作这些对象。2. 可以解耦,提高程序的可扩展性。* 获取Class对象的方式:1. Class.forName("全类名"):将字节码文件加载进内存,返回Class对象* 多用于配置文件,将类名定义在配置文件中。读取文件,加载类2. 类名.class:通过类名的属性class获取* 多用于参数的传递3. 对象.getClass():getClass()方法在Object类中定义着。* 多用于对象的获取字节码的方式* 结论:同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个。 * Class对象功能:* 获取功能:1. 获取成员变量们* Field[] getFields() :获取所有public修饰的成员变量* Field getField(String name) 获取指定名称的 public修饰的成员变量* Field[] getDeclaredFields() 获取所有的成员变量,不考虑修饰符* Field getDeclaredField(String name) 2. 获取构造方法们* Constructor<?>[] getConstructors() * Constructor<T> getConstructor(类<?>... parameterTypes) * Constructor<T> getDeclaredConstructor(类<?>... parameterTypes) * Constructor<?>[] getDeclaredConstructors() 3. 获取成员方法们:* Method[] getMethods() * Method getMethod(String name, 类<?>... parameterTypes) * Method[] getDeclaredMethods() * Method getDeclaredMethod(String name, 类<?>... parameterTypes) 4. 获取全类名 * String getName() * Field:成员变量* 操作:1. 设置值* void set(Object obj, Object value) 2. 获取值* get(Object obj) 3. 忽略访问权限修饰符的安全检查* setAccessible(true):暴力反射* Constructor:构造方法* 创建对象:* T newInstance(Object... initargs) * 如果使用空参数构造方法创建对象,操作可以简化:Class对象的newInstance方法* Method:方法对象* 执行方法:* Object invoke(Object obj, Object... args) * 获取方法名称:* String getName:获取方法名
修饰成员变量
1.定义时必须初始化
2.一旦被赋值,后期无法修改,可以认为是一个带有名称
的常量。
MAX_ ARRAY_ SIZE MAX_ VALUE MIN_ _VALUE
DEFAULT_ CAPACITY
修饰成员方法
不可以被子类重写(override),为最终方法! ! !
修饰局部变量
一旦被赋值无法修改
修饰类
断子绝孙。
fina1修饰的类没有子类! ! !不能被继承,Java中的
String类就是一个final修饰类
143. 线程池的使用概述
144. 线程池作用:
减少创建和销毁线程的次数,每个工作线程可以多次使用
可根据系统情况调整执行的线程数量,防止消耗过多内存
145.单例模式(5种)
单例模式顾名思义就是只有一个实例,并且她自己负责创建自己的对象,这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。下面我们来看下有哪几种实现方式吧。
核心代码:构造方法私有化,private。
1、懒汉式
public class LHan {
private static LHan instance; //懒汉式
private LHan (){} //私有构造方法
public static LHan getInstance(){
if(instance == null){
instance = new LHan();
return instance;
}
}
懒汉式,顾名思义就是实例在用到的时候才去创建,“比较懒”,用的时候才去检查有没有实例,如果有则返回,没有则新建。有线程安全和线程不安全两种写法,区别就是synchronized关键字
懒汉式单例的实现没有考虑线程安全问题,它是线程不安全的,并发环境下很可能出现多个Singleton实例,要实现线程安全,有以下三种方式,都是对getInstance这个方法改造,保证了懒汉式单例的线程安全
2、饿汉式

饿汉式,从名字上也很好理解,就是“比较勤”,实例在初始化的时候就已经建好了,不管你有没有用到,都先建好了再说。好处是没有线程安全的问题,坏处是浪费内存空间。
3、双检锁

双检锁,又叫双重校验锁,综合了懒汉式和饿汉式两者的优缺点整合而成。看上面代码实现中,特点是在synchronized关键字内外都加了一层 if 条件判断,这样既保证了线程安全,又比直接上锁提高了执行效率,还节省了内存空间。
4、静态内部类
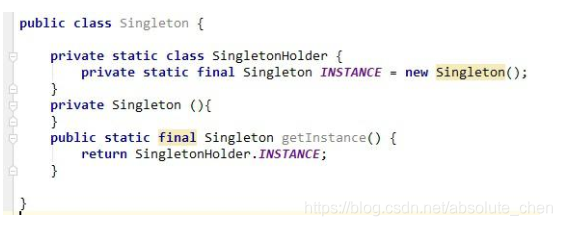
静态内部类的方式效果类似双检锁,但实现更简单。但这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
5、枚举
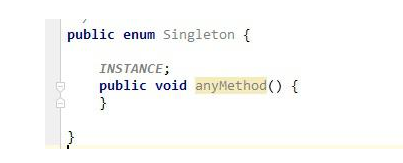
枚举的方式是比较少见的一种实现方式,但是看上面的代码实现,却更简洁清晰。并且她还自动支持序列化机制,绝对防止多次实例化。
好了,上面就是单例模式的五种主要写法。我们来总结下,一般情况下,懒汉式(包含线程安全和线程不安全梁总方式)都比较少用;饿汉式和双检锁都可以使用,可根据具体情况自主选择;在要明确实现 lazy loading 效果时,可以考虑静态内部类的实现方式;若涉及到反序列化创建对象时,大家也可以尝试使用枚举方式。
146.Lambda表达式使用举例说明
1、首先介绍下什么是Lambda?
我们知道,对于一个Java变量,我们可以赋给其一个“值”。如果你想把“一块代码”赋给一个Java变量,应该怎么做呢?比如,我想把右边那块代码,赋给一个叫做aBlockOfCode的Java变量:

在Java 8之前,这个是做不到的。但是Java 8问世之后,利用Lambda特性,就可以做到了。 为了使这个赋值操作更加elegant, 我们可以移除一些没用的声明。 如下图:

这样,我们就成功的非常优雅的把“一块代码”赋给了一个变量。而“这块代码”,或者说“这个被赋给一个变量的函数”,就是一个Lambda表达式。
147.Lambda表达式的几个最重要的特征:
- 可选的类型声明:你不用去声明参数的类型。编译器可以从参数的值来推断它是什么类型。
- 可选的参数周围的括号:你可以不用在括号内声明单个参数。但是对于很多参数的情况,括号是必需的。
- 可选的大括号:如果表达式体里面只有一个语句,那么你不必用大括号括起来。
- 可选的返回关键字:如果表达式体只有单个表达式用于值的返回,那么编译器会自动完成这一步。若要指示表达式来返回某个值,则需要使用大括号。
148.Lambda表达式有什么作用?
最直观的作用就是使得代码变得异常简洁。
我们可以对比一下Lambda表达式和传统的Java对同一个接口的实现:
149.ArrayList特征分析
增加慢:
1. 增加操作有可能会导致数组中的元素,从添加位置开始,整体向后移动,移动操作时间效率低!!!
2. 添加操作有可能触发扩容问题,扩容操作需要占用更多的内存空间,同时涉及到数据的复制操作。
删除慢:
1. 删除元素,从删除位置开始,之后的元素需要整体向前移动。
2. 删除元素,有可能导致数值中的有效元素个数和当前数组容量比例过小,导致数组空间浪费!
ArrayList底层数据存储方式为 数组方式,可以参考【数组地址内存图】分析,ArrayList 通过下标查询元素效率极高!!!
适应场景
增删少,查询多
人力系统,图书系统,订单系统
150.数组扩容
/**
* 扩容的核心方法
* @param minCapacity 期望最小扩容后的大小
*/
private void grow(int minCapacity) {
int oldCapacity = elementData.length; //旧数组容量
//新容量为旧容量的1.5倍.为什么是1.5倍?
//如果一次扩容太大,则会造成内存浪费;如果一次扩容太小,则势必很快又需要扩容,而扩容是一项很损耗性能的操作
//所以JDK开发人员进行了时间和空间的折衷,以旧容量的1.5倍为新容量(注意容量大小是int类型,即 3扩容后不是4.5,而是4!)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
//若期望的最小扩容后的大小比这次扩容操作后的大小要来的大,则说明这次扩容操作不足以满足期望大小,直接将list的新容量设置为期望容量
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
//如果新容量即将达到Integer最大值*(2^31-1),则调用超大扩容方法,避免扩容后数组大小超过Integer最大值
newCapacity = hugeCapacity(minCapacity);
// 这里的操作其实分为2步:
// 1.先将原数组扩容,返回一个新的、扩容后的空数组
// 2.调用Arrays的copyOf方法,将原数组对应索引处的值拷贝到新数组对应索引处
elementData = Arrays.copyOf(elementData, newCapacity);
}