由于要优化网络,老师给提供的几个思路:

个人学习后的几个认知:
1.联级特征融合模块
主要用于残差网络最后的残差块融合上
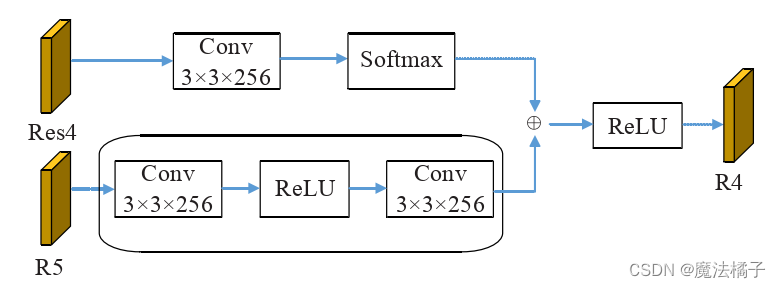
其中 R5 是经过 Res5 通过 3×3 的卷积获得的特征图,该特征图保持空间分辨率不变,并将通道的数量变成256
Res3、Res4、Res5为残差神经网络的几个残差块
2.GCN全局卷积网络(Global Convolutional Network)
当前网络的设置倾向于使用小尺寸滤波器,在相同的计算代价下效果与大核的效果相同,但是后者在同时处理分类和定位任务时非常关键。
分类和定位任务“天生”矛盾,对于分类任务来说,其要求网络具有不变性,即在各种变化和旋转之后,类别仍然一致;对于定位任务则相反,要求其对变换敏感。
为了克服上面提到的问题,提出了遵循下面两个准则的Global Convolutional Network(GCN):
- 对于分类任务:使用较大尺寸的核函数使得特征图和逐像素点分类器之间能够建立密集连接
- 对于定位任务:使用全卷积,剔除全连接和全局池化
具体地: - 为了使全局卷积便于执行,文中采用对称可分离的大滤波器来减少参数并降低计算代价;
- 设计了边界精细模块集成到网络中,精细化物体边界,并能够端到端的训练;
基于此,论文的主要贡献在于: - 提出全局卷积网络。减缓定位任务和分类任务的矛盾
- 提出边界精细模块使得物体边界处的定位更加精细
3.1 GCN:Global Convolutional Network
对于分类任务,模型需要抽取图像深层的特征(小尺寸的特征图),空间维度上比较粗糙,但能够使分类器和特征图通过全连接层建立密集连接;而对于定位任务,模型需要尽可能大的特征图来编码空间信息。当前的语义分割模型都着重于后者,使得分类器可能难以捕获某些关键的特征从而影响分类,出现下面的问题:图像尺寸变大后感受区域不能覆盖整个物体:
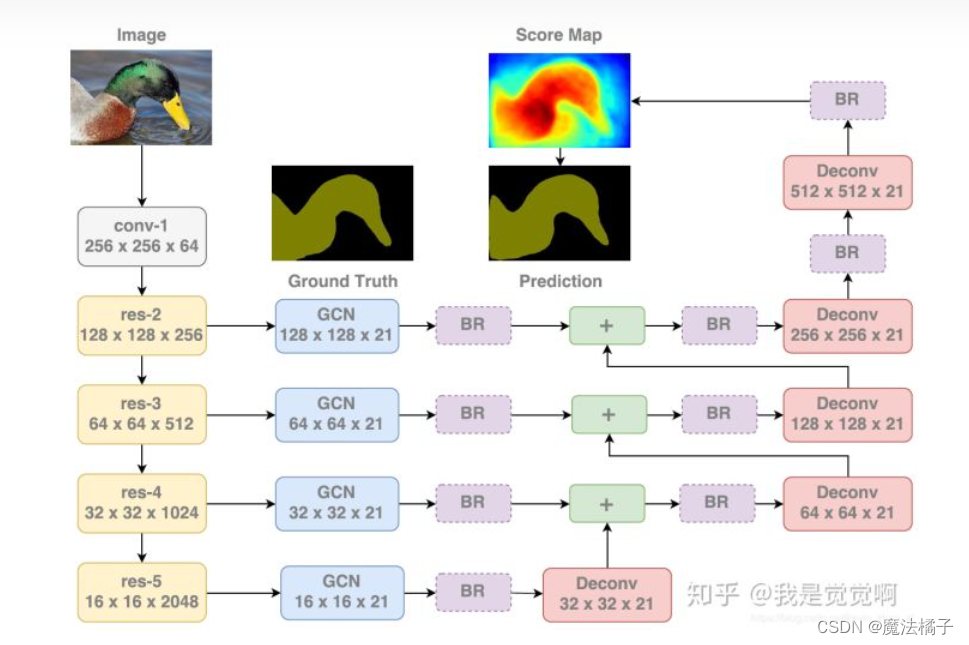
3.2 Boundary RefineMent Block
该模块设计为残差模块,具体如下图所示:
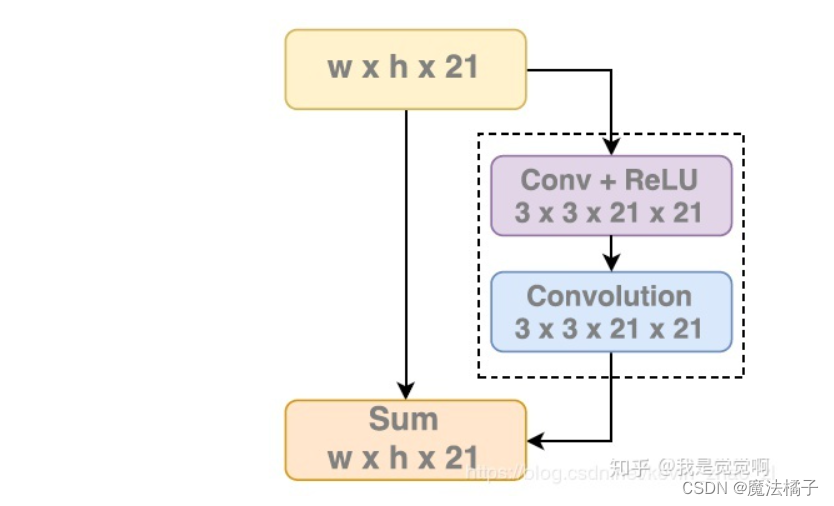
全局卷积网络,搜到的东西不多,就一篇,和BR出自同一篇文章
https://zhuanlan.zhihu.com/p/51670413
https://zhuanlan.zhihu.com/p/41077177
3.GCN(图卷积)
https://distill.pub/2021/gnn-intro/
4.多尺度输入
2014年在《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,这篇paper主要的创新点在于提出了空间金字塔池化。
提出的原因:
在SPP提出之前,深度学习网络主要是以R-CNN为主,它有两大缺点:
1、通常需要输入固定大小的图片来进行训练和测试。
对于大小不一的图片,需要经过裁剪,或者缩放等一系列操作,将其变为统一的尺寸。但是这样往往会降低识别检测的精度。
2、计算量较大,严重影响速度
R-CNN预设1000~2000个候选区域 (采用Selective Search 方法),并分别在每个候选区域进行特征提取。这个想想就害怕,因为图片上有些区域会被重复采样多次。
具体原理:
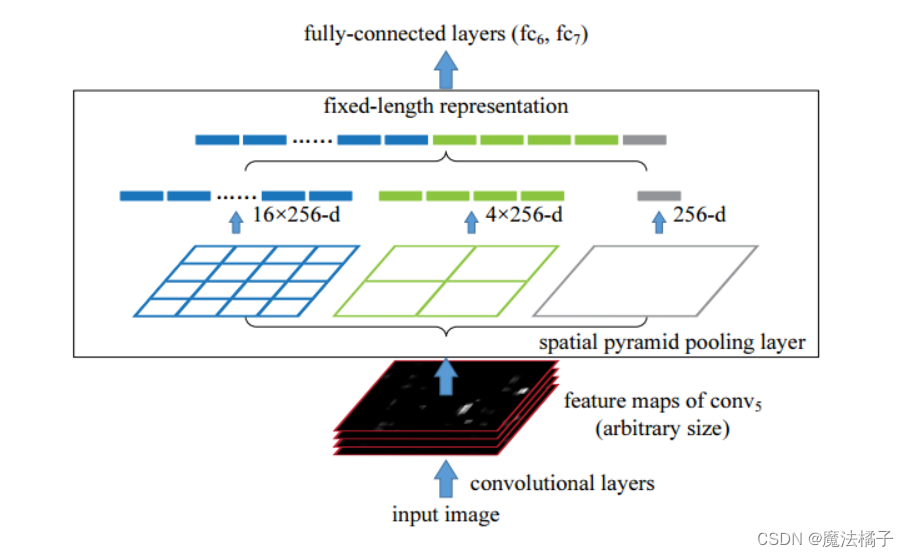
现在从左到右来看:
蓝色的图1——我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
绿色的图2,划分了4个块,每个块的大小就是(w/2,h/2);
黑色的图3,把整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值(局部max-pooling)。通过SPP,我们就把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:windows size了。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
解决的问题:
1、多尺度输入
当我们有很多层网络的时候,当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的奥义(多尺度特征提取出固定大小的特征向量)。
2、计算量的减少
存在spp网络的神经网络(如衍生出了之后的fast R-CNN)虽然也需要预设1000~2000个候选区域,但只需要对每张图片进行一次采样特征提取,再由特征图来确定每个候选区域的特征图,因此大大减小了计算量。



![[国产MCU]-W801开发实例-MQTT客户端通信](https://img-blog.csdnimg.cn/f6159728c6d74fc8bb888e440eddc698.png#pic_center)