一、概述
数据集:25601行×13列

二、可视化
1、星巴克全球分布图
(1)普通地图
由于包或数据格式错误,地图无法显示区域颜色。
import pandas as pd
from pyecharts.charts import *
import pyecharts.options as opts
df = pd.read_csv('./directory.csv')a = list(df.Country.value_counts().to_dict().items())
print(a)
map = Map()
map.add('', list(df.Country.value_counts().to_dict().items()),maptype='world',is_roam=False,
is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(title_opts=opts.TitleOpts(title='星巴克全球分布图',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(max_=14000))
map.render('bbb.html')
map.set_global_opts(title_opts=opts.TitleOpts(title='星巴克全球分布图',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(range_text=['门店数量'],
is_piecewise=True, #分段显示
pieces=[{'min':1000},{'min':500,'max':1000},
{'min':100,'max':500},{'max': 100}]))
map.render('ccc.html')
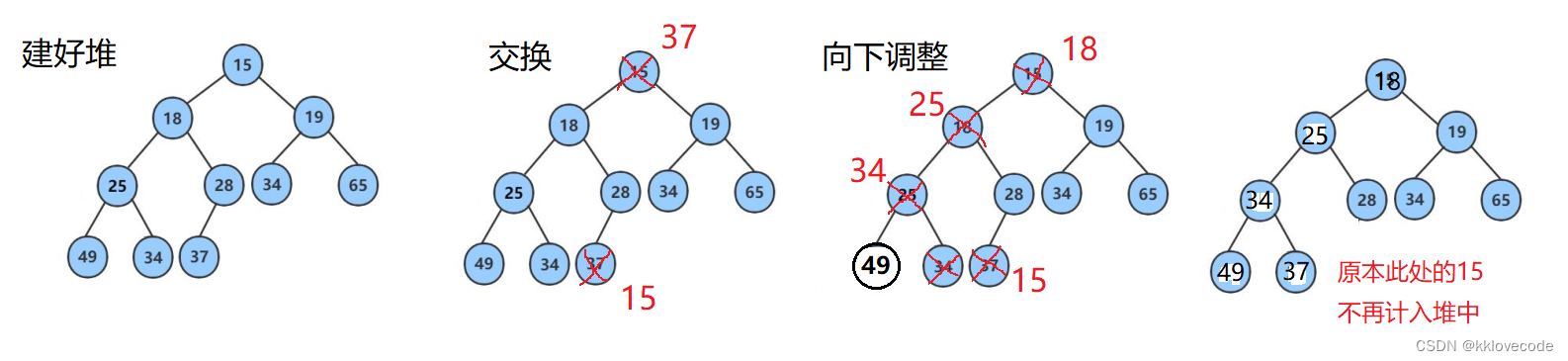
(2)各国/地区星巴克门店数量(可点击下钻到城市)
# 空值填充
df_t = df.fillna(value=dict(county_name='NA', city_name='NA'))
df_t = df_t.groupby(['Country', 'City'])['Brand'].count().reset_index()data = []
country = []
# 数据处理成Pyecharts需要的格式
for idx, row in df_t.iterrows():
if row['Country'] in country:
data[-1]['children'].append(dict(name=row['City'], value=row['Brand']))
else:
data.append(dict(name=row['Country'], children=[dict(name=row['City'], value=row['Brand'])]))
country.append(row['Country'])tree = TreeMap()
tree.add('星巴克门店',data,leaf_depth=1, # 叶子节点深度 国家和城市两层,深度为1
label_opts=opts.LabelOpts(position="inside",formatter='{b}:{c}门店'), # 标签设置
levels=[ # 针对每一层的样式设置
opts.TreeMapLevelsOpts(
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color="#555",border_width=4,gap_width=4)),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6], # 颜色饱和度范围
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7,gap_width=2,border_width=2))])tree.set_global_opts(title_opts=opts.TitleOpts(title="各国/地区星巴克门店数量(可点击下钻到城市)"),
legend_opts=opts.LegendOpts(is_show=False))
tree.render('hhh.html')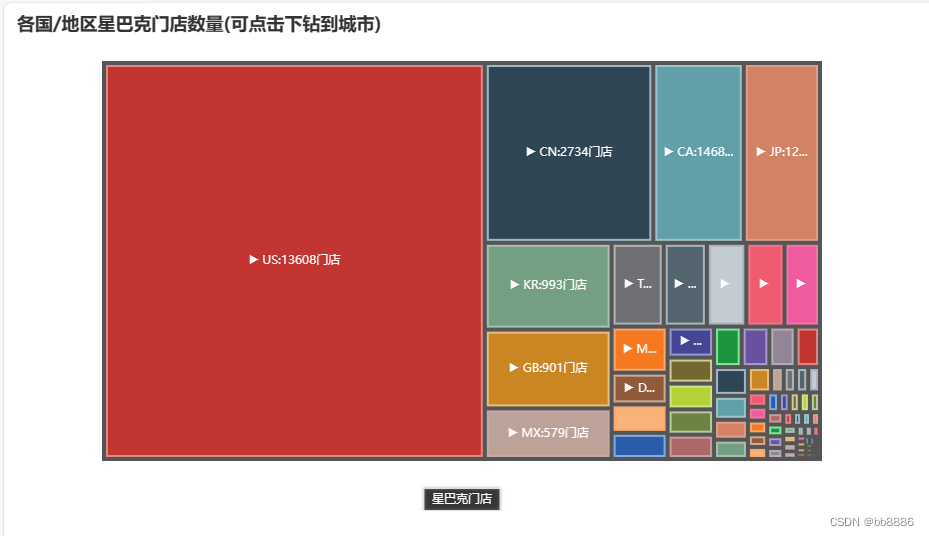
2、门店数量在前15的城市
b = list(df.City.value_counts().to_dict().items())[0:15]
data = dict(b)
print(list(data.keys()))
bar = Bar()
bar.add_xaxis(list(data.keys()))
bar.add_yaxis('', list(data.values()), label_opts=opts.LabelOpts(position='right'))
bar.set_global_opts(title_opts=opts.TitleOpts(title='门店数量在前15的城市'),
xaxis_opts=opts.AxisOpts(position='top'),
yaxis_opts=opts.AxisOpts(is_inverse=True),
visualmap_opts=opts.VisualMapOpts(is_show=False, dimension=0, max_=300,
range_color=['#FFE7D3','#7A0616']))
bar.reversal_axis()
bar.render('ddd.html')
3、门店所有权占比
c = list(df['Ownership Type'].value_counts().to_dict().items())
d = df.groupby('Ownership Type').Brand.agg('count').sort_values(ascending=False)
print(c)
p = Pie()
p.add('', c, rosetype='area',label_opts=opts.LabelOpts(formatter='{b}:{d}%'), radius=['10%', '45%'])
p.set_global_opts(title_opts=opts.TitleOpts(title='门店所有权占比'))
p.render('eee.html')

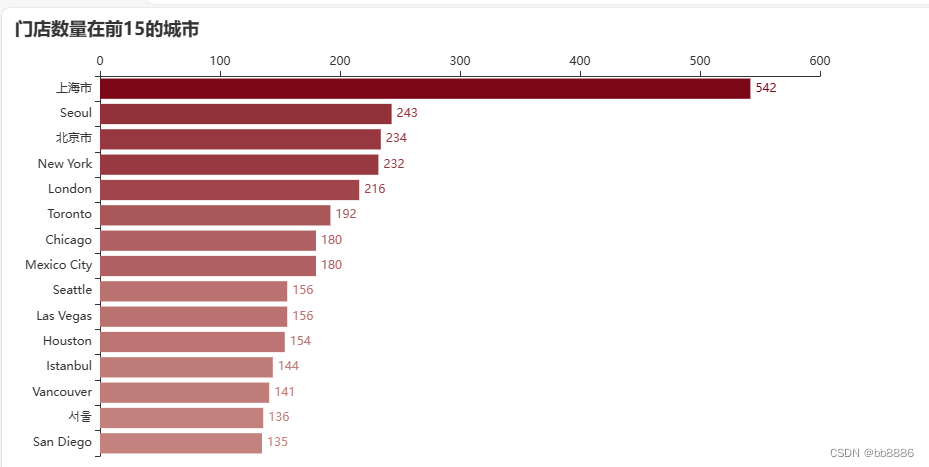
4、星巴克在中国的分布
(1)根据经纬度绘制热力地图
df_china = df[df['Country'] == 'CN']
a = df_china.groupby(['Longitude', 'Latitude']).Brand.value_counts()
print(list(a.to_dict().items()))
jwd, data = [], []
for i ,j in list(a.to_dict().items()):
jwd.append((str(i[0])+'-'+str(i[1]), i[0], i[1]))
data.append((str(i[0])+'-'+str(i[1]), j))geo = Geo()
for i in jwd:
geo.add_coordinate(i[0], i[1], i[2])
geo.add_schema(maptype='china', is_roam=False)
geo.add('', data, type_='heatmap', is_large=True,
blur_size=10,
point_size=2,)
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=False, max_=1))
geo.render('fff.html')
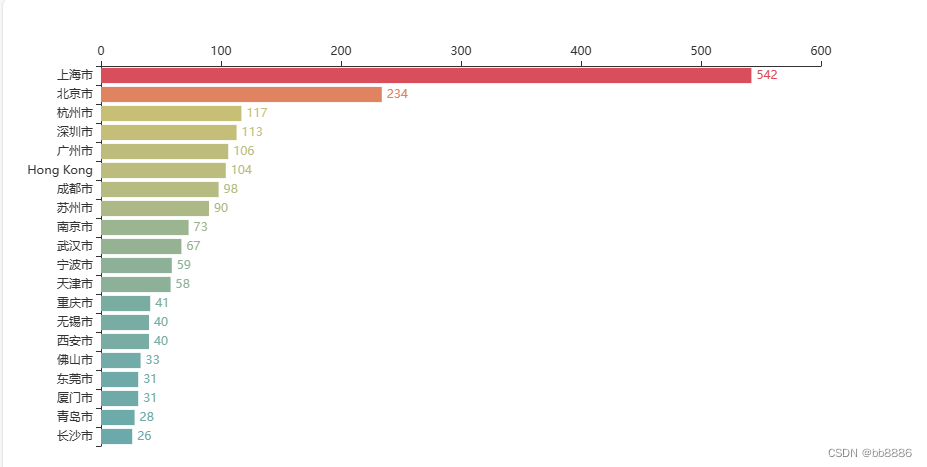
(2)国内星巴克门店最多的20个城市
e = list(df[df['Country'] == 'CN']['City'].value_counts().to_dict().items())[0:20]
print(e)
bar2 = Bar()
bar2.add_xaxis(list(dict(e).keys()))
bar2.add_yaxis('', list(dict(e).values()), label_opts=opts.LabelOpts(position='right'))
bar2.set_global_opts(yaxis_opts=opts.AxisOpts(is_inverse=True),
xaxis_opts=opts.AxisOpts(position='top'),
visualmap_opts=opts.VisualMapOpts(is_show=False, dimension=0, max_=300))
bar2.reversal_axis()
bar2.render('ggg.html')