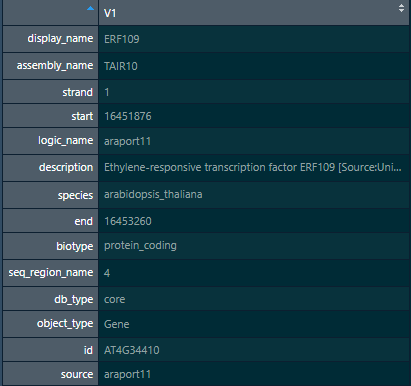
1、motif 是什么?
“高出现频率的分子片段”,它与fragment的区别可能就是一个是高频出现一个不是高频出现的吧
维基百科:经常出现的统计学上非常重要的子图或子结构
下面我们给出例子,分子图通过一些分解手段来构造一些子结构,我们列出了4个例子:
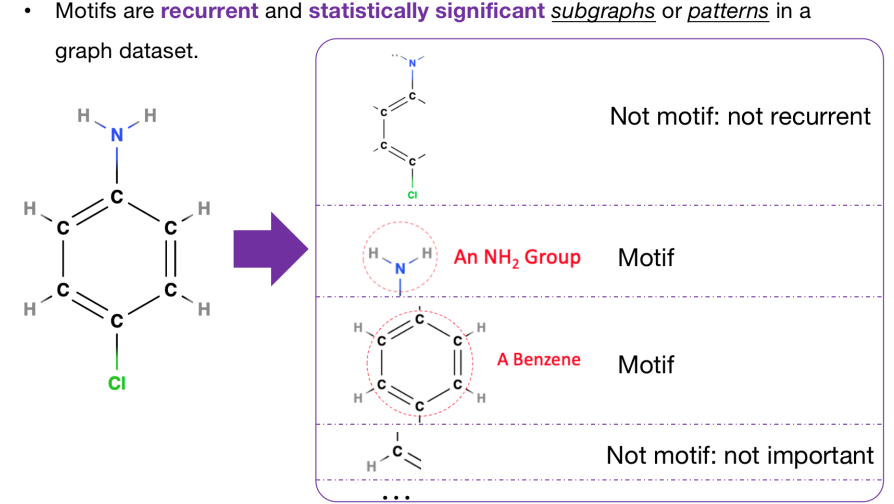
- 第一个子结构包含了绝大多数分子图中的点,也就是说本身这个子结构包含了很多非常有用的信息。但是由于这个结构非常特殊,我们很难在其他图中找到相同的子结构,所以我们就不把它当作motif。
- 第二个和第三个例子可以被当作motif,首先是因为他们都经常出现在各种分子图中。另一方面根据化学中的domain knowledge,我们可以知道这两个子结构具有特殊的性质。所以我们认为这两种子结构都可以被当作motif。
- 最后一个例子是一个碳氢结构,该结构也经常出现在图中。但是目前还很难知道它有什么特殊的性质,所以不把它作为motif。
2、Why motifs?
第一个原因就是motif已经在图领域被广泛学习,而且已被证明可以对一些图表示学习起到帮助。第二个原因是motif作为统计学上较重要的子图,学习motif本身也就如同在学习图中的一个重要子结构。自然我们也可以学习到一些有用的信息来帮助分子图的表示学习。
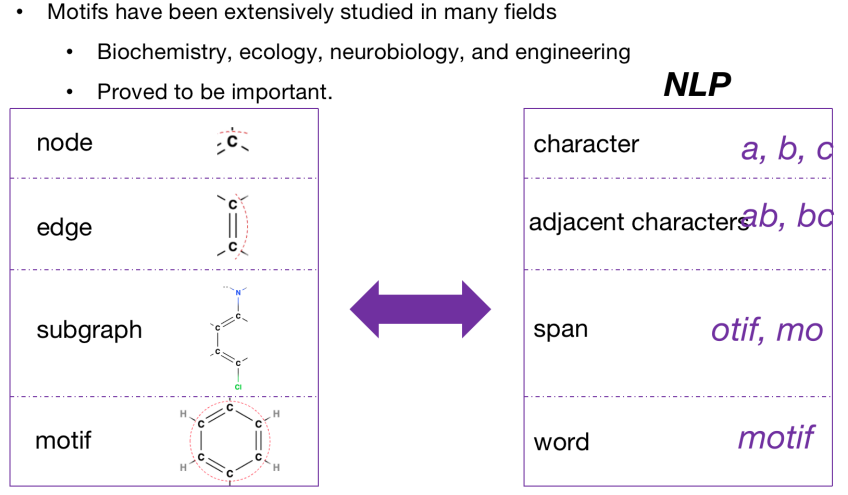
对比NLP和图领域,这两者有非常多的相似之处。我们在图中以node作为基本的单位,在NLP中把字母作为基本的单位;图中的edge这种两个node之间的关系可以看做NLP中两个相邻字母之间的关系;图中的子图在NLP中也可以用连续的字母作为相对应的关系。图中的motif在NLP中也可以被看作word,在NLP中word embedding的学习是非常重要的,无论是对于sentence还是document。类比过来,图中motif的学习对于graph的学习也是非常重要的。
3、Motif Vocabulary
构建motif的字典,我们首先给一个数据集选取一个提取motif的方法,然后遍历数据集中所有的分子图提取出一些子图。
我们也可以进行筛选,选出一些重要的子图。当然也可以不做筛选,全部放在字典之中。这样肯定也不会遗漏信息。
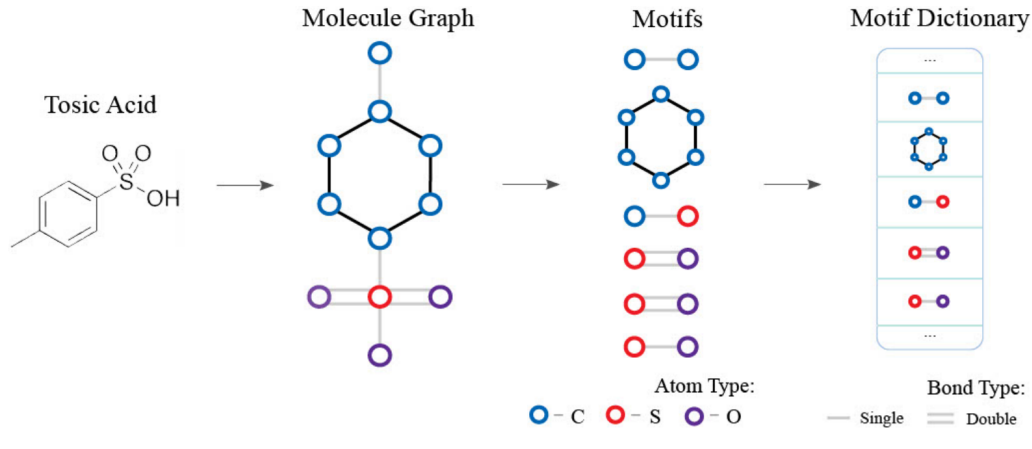
需要强调的是,提取motif方法的选择也很重要。我们可以用环来代表非常多的motif,本研究中的提取方法就是选取所有的环结构已经那些不在环结构上的边作为motif放入字典之中。其他一些分子中的成熟的decomposition方法例如RECAP和BRICS提取出来的motif相对较大,很难控制字典的大小,因为当motif过大的时候就不够基础,提取出的motif中数量就很难控制。只提取环和边的另一个好处是其时间复杂度不是很高,只有o(n2)。
干货!通过异构子图神经网络进行分子表示学习_AITIME论道的博客-CSDN博客