| 1. hive安装部署 2. hive基础 3. hive高级查询 4. Hive函数及性能优化 |
1.hive安装部署
| 解压tar -xvf ./apache-hive-3.1.2-bin.tar.gz -C /opt/soft/ 改名mv apache-hive-3.1.2-bin/ hive312 |
| 配置环境变量:vim /etc/profile #hive export HIVE_HOME=/opt/soft/hive312 export PATH=$HIVE_HOME/bin:$PATH 更新环境变量:source /etc/profile |
| 进入/opt/soft/hive312/conf
[root@kb129 lib]# pwd 拷贝MySQL8的连接驱动至/opt/soft/hive312/lib
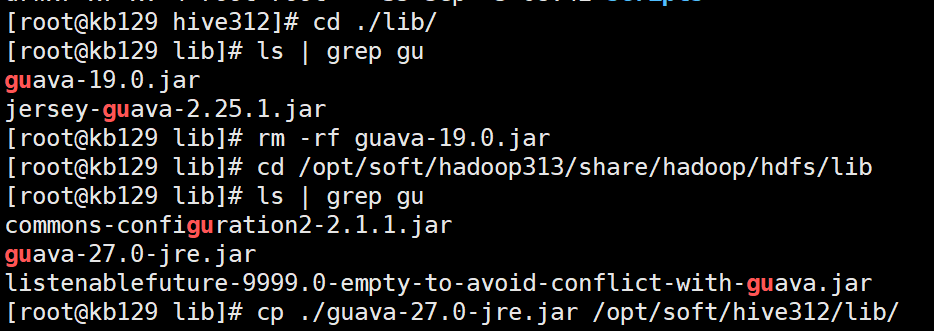
修改配置文件: (1)新建配置文件[root@kb129 conf]# vim ./hive-site.xml (2)删除hive中的guava-19.0.jar,将hadoop目录中的guava-27.0-jre.jar拷贝至hive312/lib目录下 cp /opt/soft/hadoop313/share/hadoop/common/lib/guava-27.0-jre.jar /opt/soft/hive312/lib/
(3)hive初始化 [root@kb129 hive312]# schematool -dbType mysql -initSchema
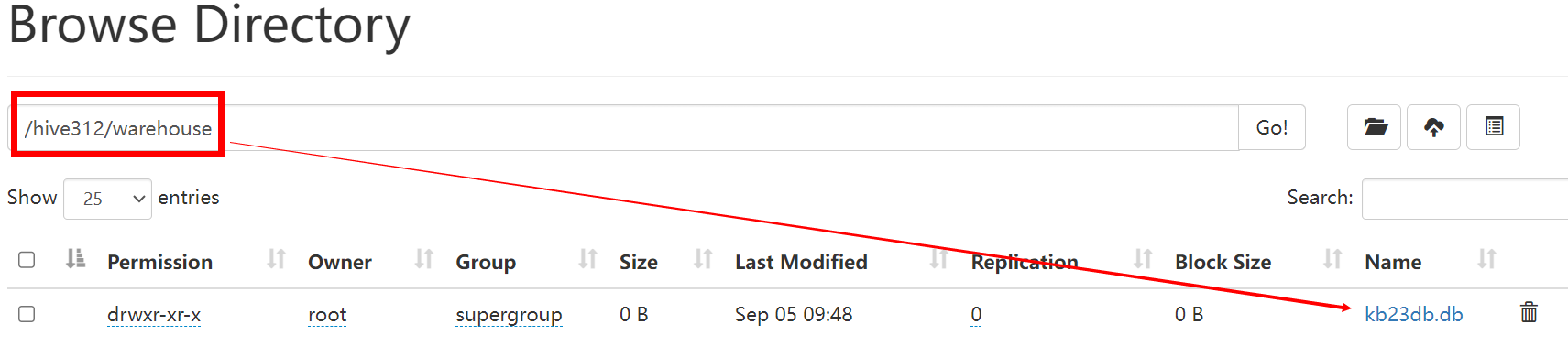
(4)进入hive,创建数据库测试 [root@kb129 hive312]# hive hive (default)> create database kb23DB > ; OK Time taken: 0.401 seconds hive (default)> show databases; OK database_name default kb23db Time taken: 0.082 seconds, Fetched: 2 row(s) 创建完成后HDFS系统中会生成
(注:hive如果关闭会进入异常模式,执行命令关闭:hdfs dfsadmin -safemode leave) |
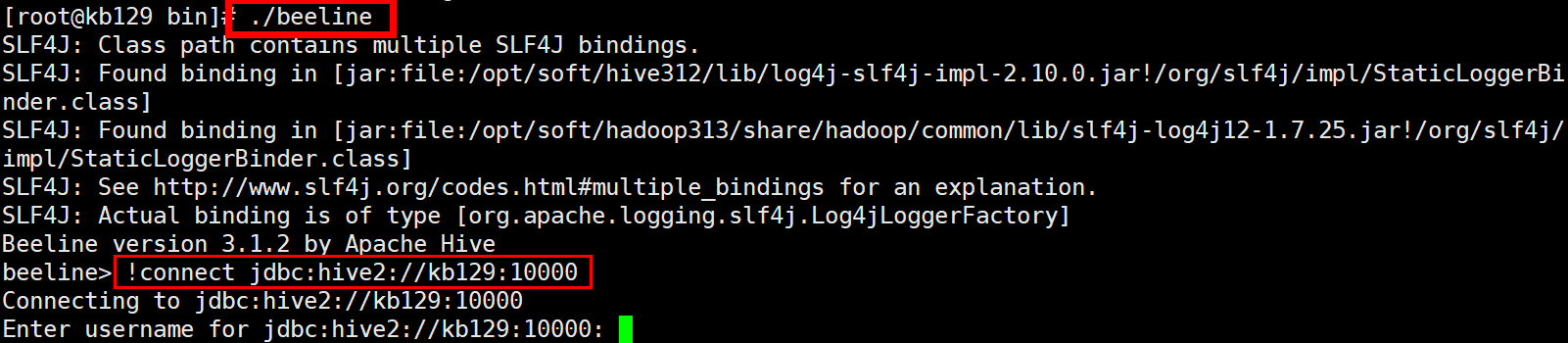
| 启动metastore元数据服务:[root@kb129 hive312]# nohup hive --service metastore & 启动hiveserver2远程服务:[root@kb129 hive312]# nohup hive --service hiveserver2 & 进入beeline客户端连接
|
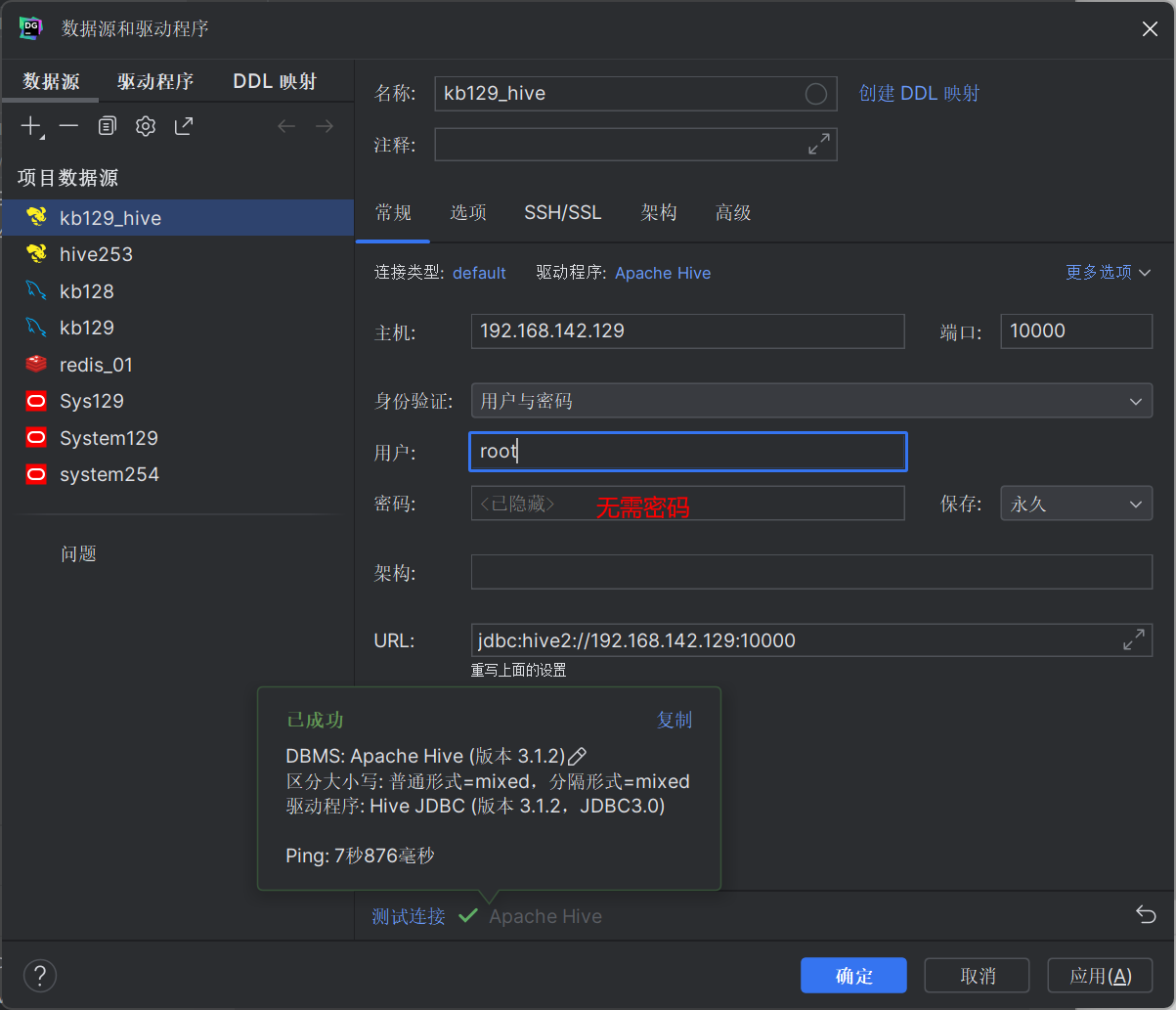
| 使用datagrip连接
|
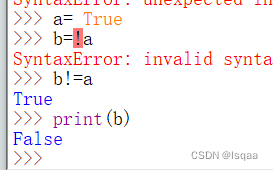
| 查找命令:查找当前目录下以gu开头的文件名 [root@kb129 lib]# find ./ -name gu* ./guava-19.0.jar |


2.hive基础
| 2.1 hive (1)基于Hadoop的数据仓库解决方案: 将结构化的数据文件映射为数据库表 提供类sql的查询语言HQL(Hive Query Language) Hive让更多的人使用Hadoop (2)Hive成为Apache顶级项目 Hive始于2007年的Facebook 官网:hive.apache.org | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.2 Hive的优势和特点 提供了一个简单的优化模型 HQL类SQL语法,简化MR开发 支持在不同的计算框架上运行 支持在HDFS和HBase上临时查询数据 支持用户自定义函数、格式 常用于ETL操作和BI 稳定可靠(真实生产环境)的批处理 有庞大活跃的社区 | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.3 Hive元数据管理 (1)记录数据仓库中模型的定义、各层级间的映射关系 (2)存储在关系数据库中 1)默认Derby, 轻量级内嵌SQL数据库 Derby非常适合测试和演示 存储在.metastore_db目录中 2)实际生产一般存储在MySQL中 修改配置文件hive-site.xml (3)HCatalog 将Hive元数据共享给其他应用程序 | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.4 Hive操作-客户端交互模式 (1)检查Hive服务是否已经正常启动 (2)使用Hive交互方式(输入hive即可) (3)使用beeline 1)需启动hiveserver2服务 nohup hive --service metastore &(非必须) nohup hive --service hiveserver2 & 2)输入beeline进入beeline交互模式 !connect jdbc:hive2://kb129:10000 | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.5Hive Interface – 其他使用环境 (1)Hive Web Interface (2)Hue (Cloudera) (3)Ambari Hive View (Hortonworks) 1)JDBC/ODBC(ETL工具,商业智能工具,集成开发环境) 2)Informatica, Talend等 3)Tableau, QlikView, Zeppelin等 4)Oracle SQL Developer, DB Visualizer等 | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.6 Hive数据类型 - 基本数据类型 类似于SQL数据类型
- 集合数据类型 ARRAY:存储的数据为相同类型 MAP:具有相同类型的键值对 STRUCT:封装了一组字段
| ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.7 Hive数据结构
| ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.8 数据库(Database) (1)表的集合,HDFS中表现为一个文件夹 默认在hive.metastore.warehouse.dir属性目录下 (2)常用命令 查看细节:desc/describe database kb23db; 创建:create database aabb; 查看内容:show databases; 使用:use aabb; 查看当前使用的数据库:select current_database(); 新增数据:insert into demo values(3,'wangwu'); 覆写表格:insert overwrite table demo values(3,'wangwu'); 删除:drop database [if exist] aabb;(非空数据库无法直接使用) 强制删除:drop database kb23db cascade; 查看日期:select `current_date`(); 查看创建表/库的命令行细节:show create table/database demo;
更改表名:alter table demo2 rename to stu; 更改字段/列名:alter table stu change name uname string; 添加字段/列:alter table stu add columns(age int comment 'user_age');(comment注释) 添加多字段/列:alter table stu add columns(address string, email string); 替换字段/列(覆盖):alter table stu replace columns(id int, uname string, address string);
查看函数:show functions; | ||||||||||||||||||||||||||||||||||||||||||||||||
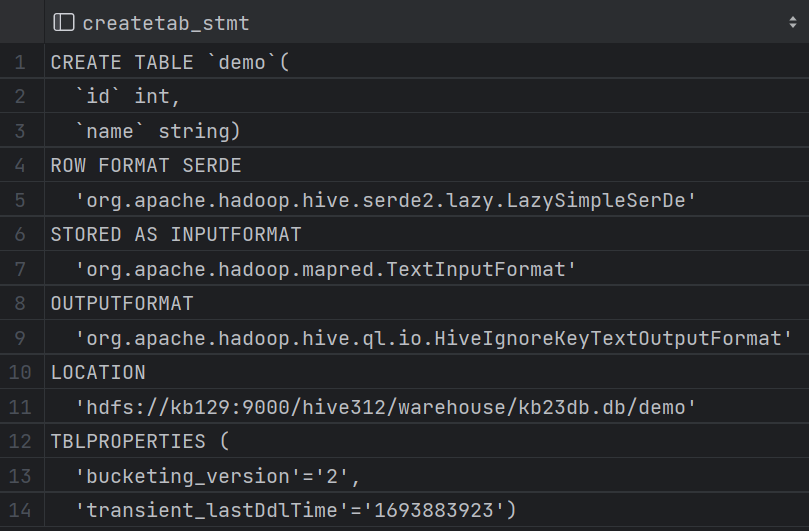
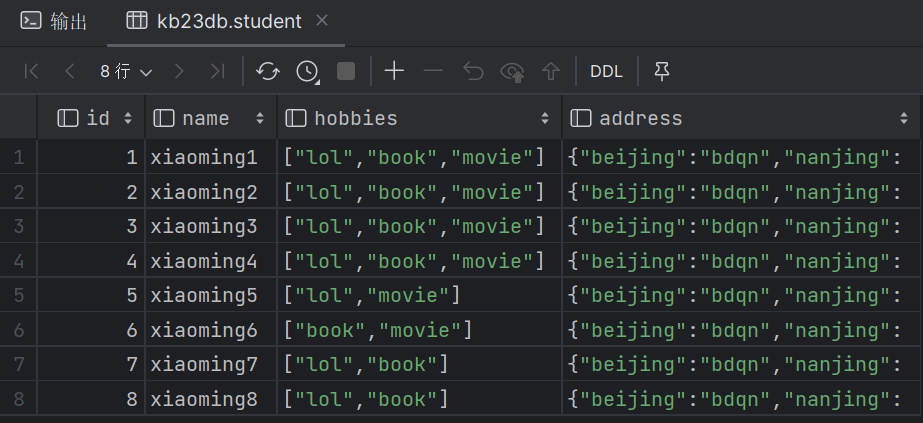
| 2.9 内部表 row format语法:DELIMITED关键字对 按照指定格式进行分割 ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char](空位补值,默认为\N) (1)创建内部表 create table student( id int, name string, hobbies array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' lines terminated by '\n'; (2)[root@kb129 kb23]# hdfs dfs -put ./student.txt /hive312/war ehouse/kb23db.db/student 上传数据至表所属路径,执行select可以查询表内容
(3)加载hdfs数据:load data inpath '/kb23/hadoopstu/student.txt' into table student; 加载完数据后,hdfs原位置中文件转移到表中 加载centos本地数据:load data local inpath 'opt/kb23/student.txt'into table student; (4)清空表数据 truncate table student; (5)练习 employee文件 Michael|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead Will|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead Shelley|New York|Female,27|Python:80|Test:Lead,COE:Architect Lucy|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead 转换成表: create external table employee_external ( name string, work_place string, gender_age struct<gender:string, age:int>, skills_score map<string,int>, depart_title map<string,array<string>> ) row format delimited fields terminated by '|' collection items terminated by ',' map keys terminated by ':' lines terminated by '\n' location '/kb23/hadoopstu/employeefile';
| ||||||||||||||||||||||||||||||||||||||||||||||||
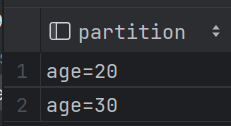
| 2.10 分区表 (1)关键字:partitioned by(age int) (2)导入数据时添加年龄放置20分区:load data local inpath '/opt/kb23/student.txt'into table student2 partition (age=20); (3)查看有多少分区字段:show partitions student2;
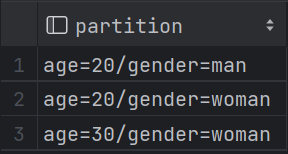
hdfs分区显示: (4)添加分区:alter table student3 add partition (age = 10, gender = 'man');
| ||||||||||||||||||||||||||||||||||||||||||||||||
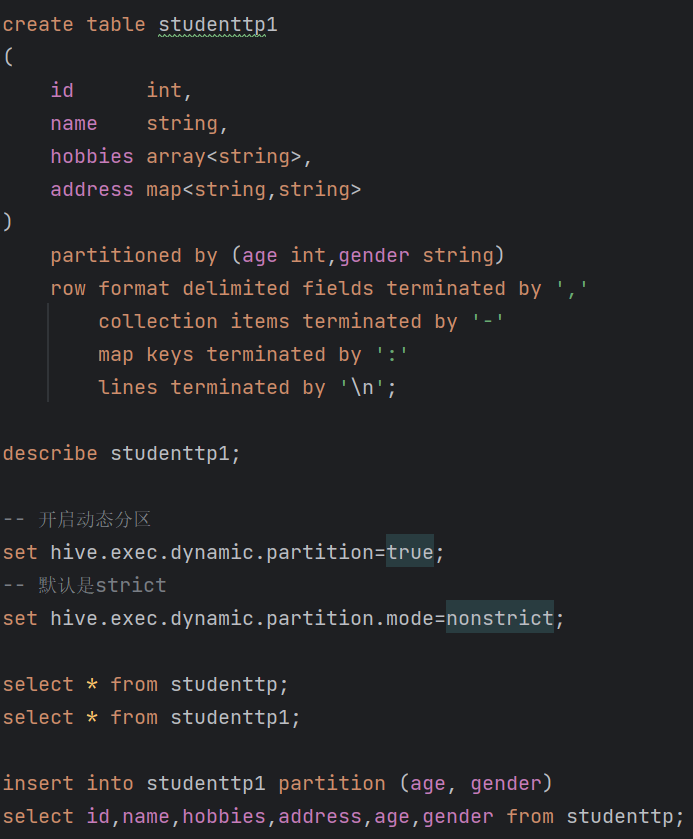
| 2.11 动态分区 -- 开启动态分区 set hive.exec.dynamic.partition=true; -- 默认是strict set hive.exec.dynamic.partition.mode=nonstrict; 插入数据后实现自动分区insert into studenttp1 partition (age, gender) select id,name,hobbies,address,age,gender from studenttp;
| ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.12 外部表(hdfs中查看不到表,删除外部表不会删除location的文件数据) create external table student_external ( id int, name string, hobbies array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' lines terminated by '\n' location '/kb23/hadoopstu/stufile'; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.13 临时表(当前会话内有效,数据库资源不显示) 临时表是应用程序自动管理在复杂查询期间生成的中间数据的方法 表只对当前session有效,session退出后自动删除 表空间位于/tmp/hive-<user_name>(安全考虑) 如果创建的临时表表名已存在,实际用的是临时表 create temporary table tmp_employee as select name,work_place from employee_external; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.14 查询 (1)查询字段属性为struct的内容 select * from employee_external where gender_age.gender = 'Female'; (2)多条件查询 select * from employee_external where name = 'Will' union select * from employee_external where gender_age.gender = 'Male' union select * from employee_external where gender_age.gender = 'Female'; 或 create temporary table ctas_employee as with r1 as (select * from employee_external where name = 'Will'), r2 as (select * from employee_external where gender_age.gender = 'Male'), r3 as (select * from employee_external where gender_age.gender = 'Female') select * from r1 union select * from r2 union select * from r3; (3)查询表的详情 desc formatted student3; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.15 Hive建表 - 分隔符 Hive中默认分隔符 字段:^A(\001) 集合:^B(\002) 映射:^C(\003) 在hive中建表时可以指定分割符 -- 指定列分隔符语法 ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' - Storage SerDe (1)SerDe:Serializer and Deserializer (2)Hive支持不同类型的Storage SerDe LazySimpleSerDe: TEXTFILE BinarySerializerDeserializer: SEQUENCEFILE ColumnarSerDe: ORC, RCFILE ParquetHiveSerDe: PARQUET AvroSerDe: AVRO OpenCSVSerDe: for CST/TSV JSONSerDe RegExSerDe HBaseSerDe Hive建表高阶语句 - CTAS and WITH (1)CTAS – as select方式建表 CREATE TABLE ctas_employee as SELECT * FROM employee; CTAS不能创建partition, external, bucket table (2)CTE (CTAS with Common Table Expression) CREATE TABLE cte_employee AS WITH r1 AS (SELECT name FROM r2 WHERE name = 'Michael'), r2 AS (SELECT name FROM employee WHERE sex_age.sex= 'Male'), r3 AS (SELECT name FROM employee WHERE sex_age.sex= 'Female') SELECT * FROM r1 UNION ALL SELECT * FROM r3; (3)like只创建employee结构,并没有数据 CREATE TABLE employee_like LIKE employee; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.16 分桶(Bucket) 分桶对应于HDFS中的文件 更高的查询处理效率 使抽样(sampling)更高效 一般根据"桶列"的哈希函数将数据进行分桶 分桶只有动态分桶 SET hive.enforce.bucketing = true; 定义分桶 CLUSTERED BY (employee_id) INTO 2 BUCKETS 必须使用INSERT方式加载数据 -- 创建分桶表 create table employee_id_buckets ( name string, employee_id int, work_place array <string>, gender_age struct<gender:string, age:int>, skills_score map<string, int>, depart_title map<string, array<string>> ) clustered by (employee_id) into 2 BUCKETS row format delimited fields terminated by '|' collection items terminated by ',' map keys terminated by ':' lines terminated by '\n'; select * from employee_id_buckets; set map.reduce.tasks=2; set hive.enforce.bucketing=true; insert overwrite table employee_id_buckets select * from employee_id; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.17 分桶抽样(Sampling) 随机抽样基于整行数据 随机条数据:select * from employee_id_buckets tablesample ( bucket 3 out of 16 on rand())s; 指定从16个桶中选择第3个桶的数据,并且使用随机的方式进行采样。 随机4条数据:select * from employee_id_buckets tablesample ( 4 rows )s; 随机20%数据:select * from employee_id_buckets tablesample ( 20 percent )s; 随机抽样基于指定列(使用分桶列更高效) SELECT * FROM table_name TABLESAMPLE(BUCKET 3 OUT OF 32 ON id) s; | ||||||||||||||||||||||||||||||||||||||||||||||||
| 2.18 Hive视图(View) (1)视图概述 通过隐藏子查询、连接和函数来简化查询的逻辑结构 只保存定义,不存储数据 如果删除或更改基础表,则查询视图将失败 视图是只读的,不能插入或装载数据 (2)应用场景 将特定的列提供给用户,保护数据隐私 用于查询语句复杂的场景 (3)视图操作命令 CREATE、SHOW、DROP、ALTER -- 创建视图,支持 CTE, ORDER BY, LIMIT, JOIN,等 CREATE VIEW view_name AS SELECT statement; -- 查找视图 (SHOW VIEWS 在 hive v2.2.0之后) SHOW TABLES; -- 查看视图定义 SHOW CREATE TABLE view_name; -- 删除视图 DROP view_name; --更改视图属性 ALTER VIEW view_name SET TBLPROPERTIES ('comment' = 'This is a view'); -- 更改视图定义, ALTER VIEW view_name AS SELECT statement; create view employee_id_view as select name, work_place from employee_id_buckets; select * from employee_id_view; | ||||||||||||||||||||||||||||||||||||||||||||||||
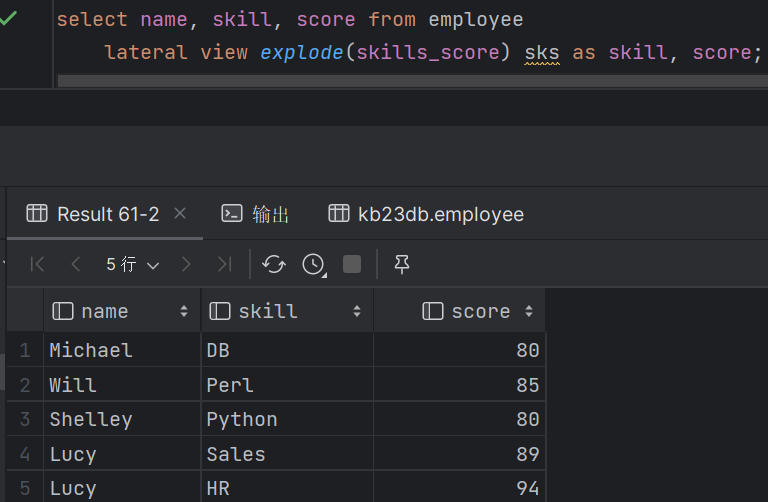
| 2.19 Hive侧视图(Lateral View) (1)与表生成函数结合使用,将函数的输入和输出连接 (2)OUTER关键字:即使output为空也会生成结果 select name,work_place,loc from employee lateral view outer explode(split(null,',')) a as loc;
(3)支持多层级 select name,wps,skill,score from employee lateral view explode(work_place) work_place_single as wps lateral view explode(skills_score) sks as skill,score; (4)通常用于规范化行或解析JSON |



3.hive高级查询
| 3.1 WordCount (1)创建表,加载数据 create table docs(line string); load data local inpath '/opt/kb23/docs.txt' into table docs; (2)查询 with t1 as ( select explode(split(line, ' ')) as word from docs ) select word, count(1) from t1 group by word order by word; |
| 3.3 case when用法 select name, gender, case when gender = 'boy' then 1 else 0 end as male, case when gender = 'girl' then 1 else 0 end as female from studenttp; |
| 3.4 collect_set()去重集合,collect_list()列表 with t1 as(select name, gender, case when gender = 'boy' then 1 else 0 end as male, case when gender = 'girl' then 1 else 0 end as female, case when gender = 'girl' or gender = 'boy' then 1 else 0 end as tag from studenttp) select collect_set(gender) colset,collect_list(gender) collist from t1 group by tag; |
| 3.5 concat()和concat_ws()用法 with t1 as(select name, gender, case when gender = 'boy' then 1 else 0 end as male, case when gender = 'girl' then 1 else 0 end as female, case when gender = 'girl' or gender = 'boy' then 1 else 0 end as tag from studenttp), t2 as(select collect_set(gender) colset,collect_list(gender) collist from t1 group by tag) select concat_ws(',',colset),concat_ws(',',collist) from t2; |
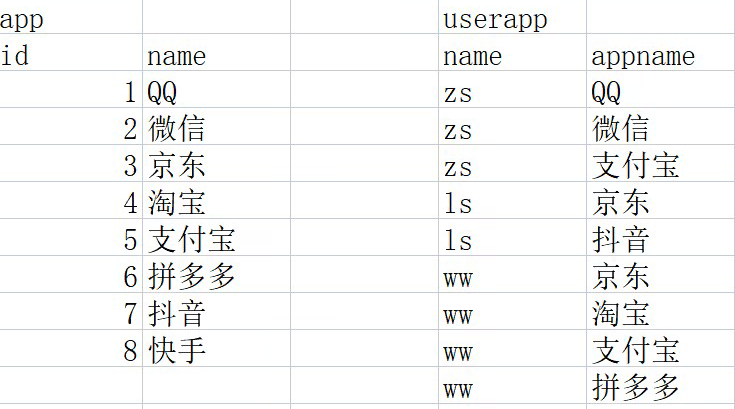
| 3.6 综合练习:找出每位用户没有安装的app
(1)找出有哪些用户(分组去重) select name from userapp group by name; (2)笛卡尔积 select a.id, a.name, u.name uname from app a cross join (select name from userapp group by name) u; (3)合并查询 with usertb as (select name from userapp group by name), userapp1 as (select a.id ,a.name , u.name uname from app as a cross join usertb as u), userapp2 as (select u1.name appname ,u1.uname from userapp1 u1 left join userapp u on u1.name=u.appname and u1.uname=u.name where u.name is null) select uname, concat_ws("," ,collect_set(appname)) from userapp2 group by uname; |
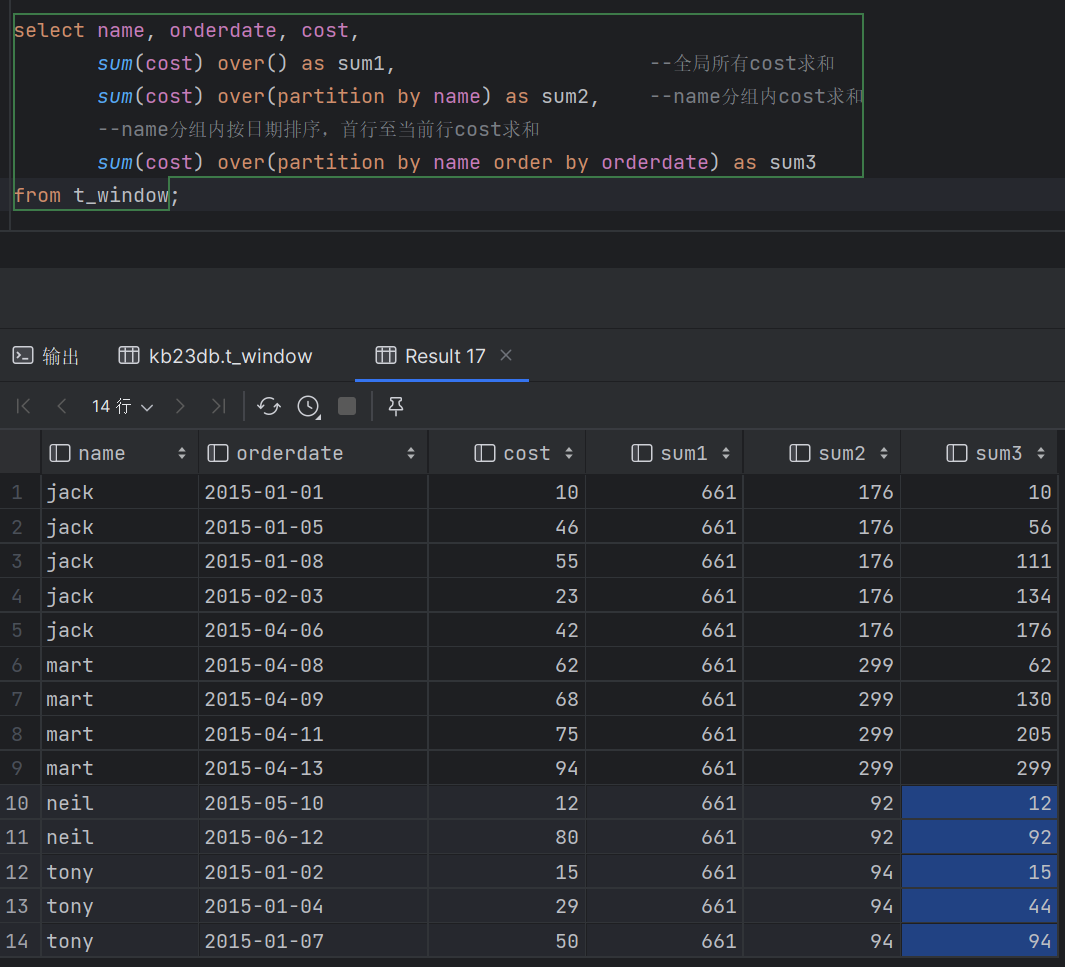
| 3.7 窗口函数 - 概述 (1)窗口函数是一组特殊函数 扫描多个输入行来计算每个输出值,为每行数据生成一行结果 可以通过窗口函数来实现复杂的计算和聚合 (2)语法 Function (arg1,..., arg n) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_clause>]) PARTITION BY类似于GROUP BY,未指定则按整个结果集 只有指定ORDER BY子句之后才能进行窗口定义 可同时使用多个窗口函数 过滤窗口函数计算结果必须在外面一层 (3)按功能可划分为:排序,聚合,分析
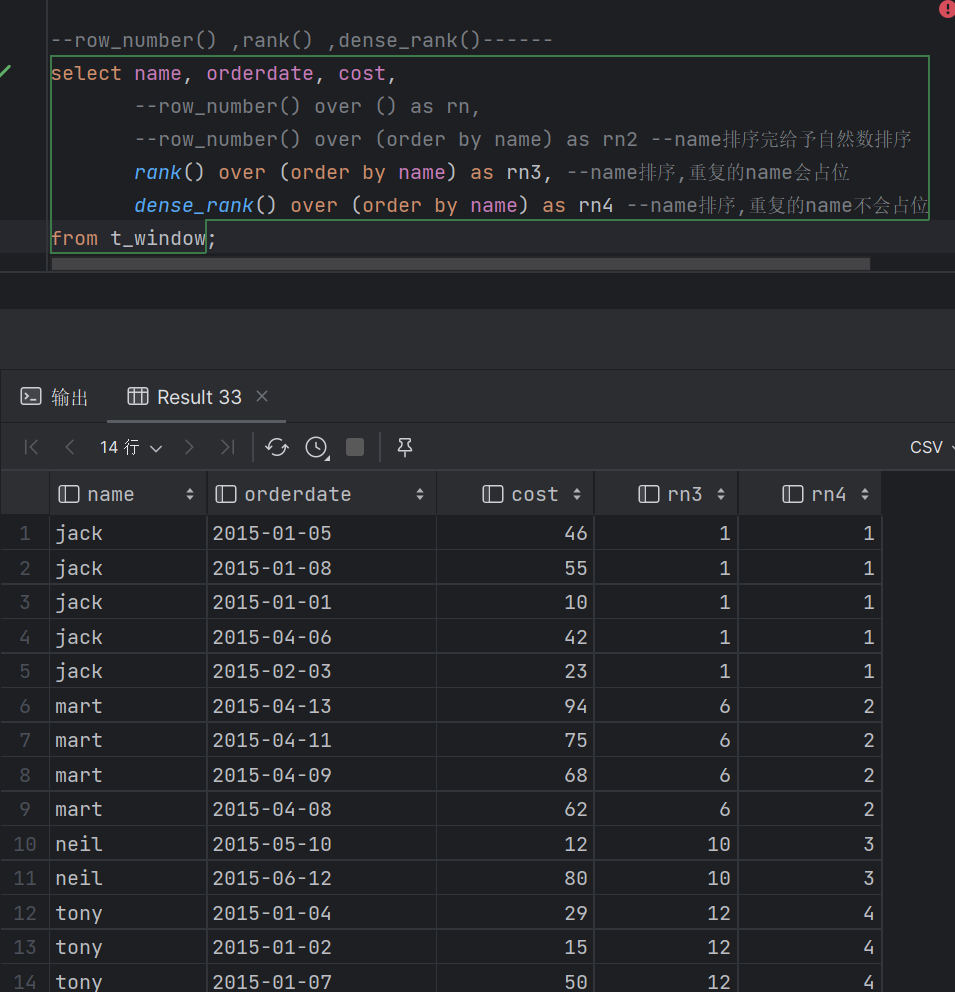
- 排序 ROW_NUMBER() 对所有数值输出不同的序号,序号唯一连续 RANK() 对相同数值,输出相同的序号,下一个序号跳过(1,1,3) DENSE_RANK() 对相同数值,输出相同的序号,下一个序号连续(1,1,2)
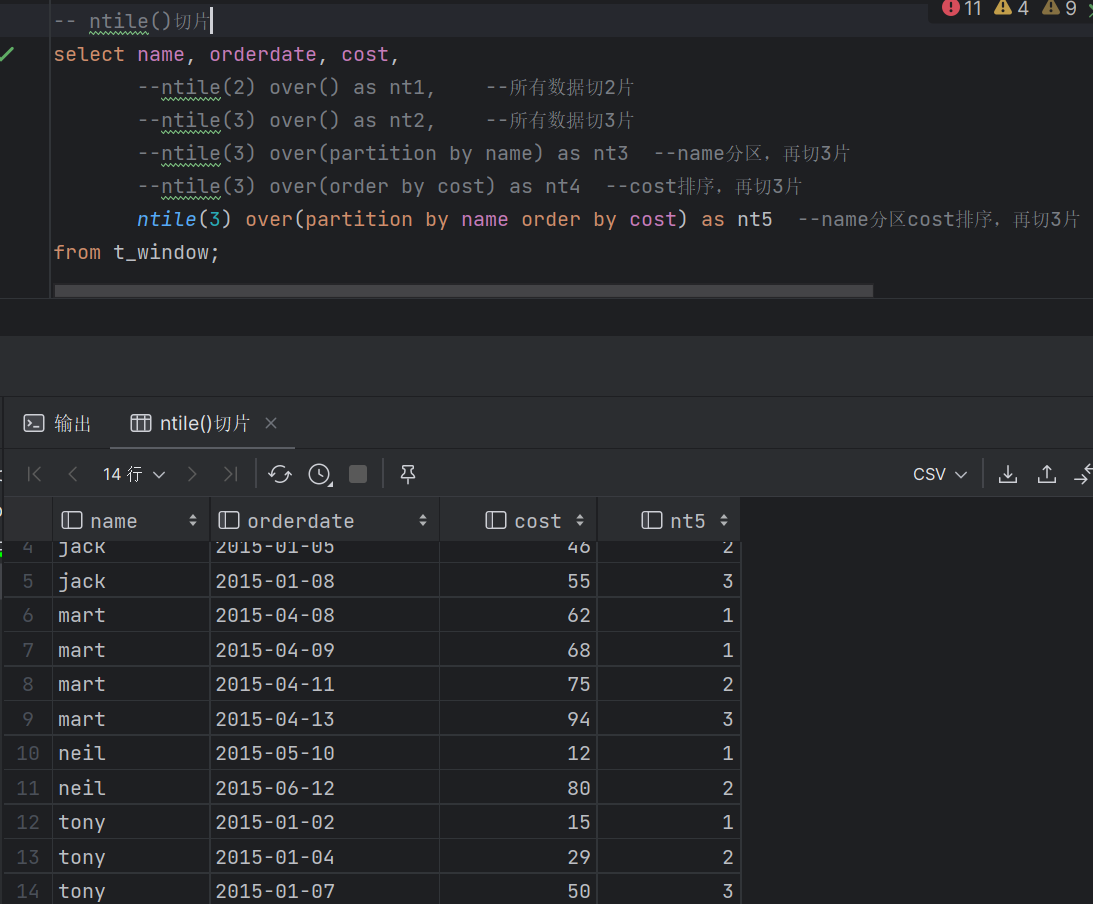
NLITE(n)切n片 将有序的数据集合平均分配到n个桶中, 将桶号分配给每一行,根据桶号,选取前或后 n分之几的数据
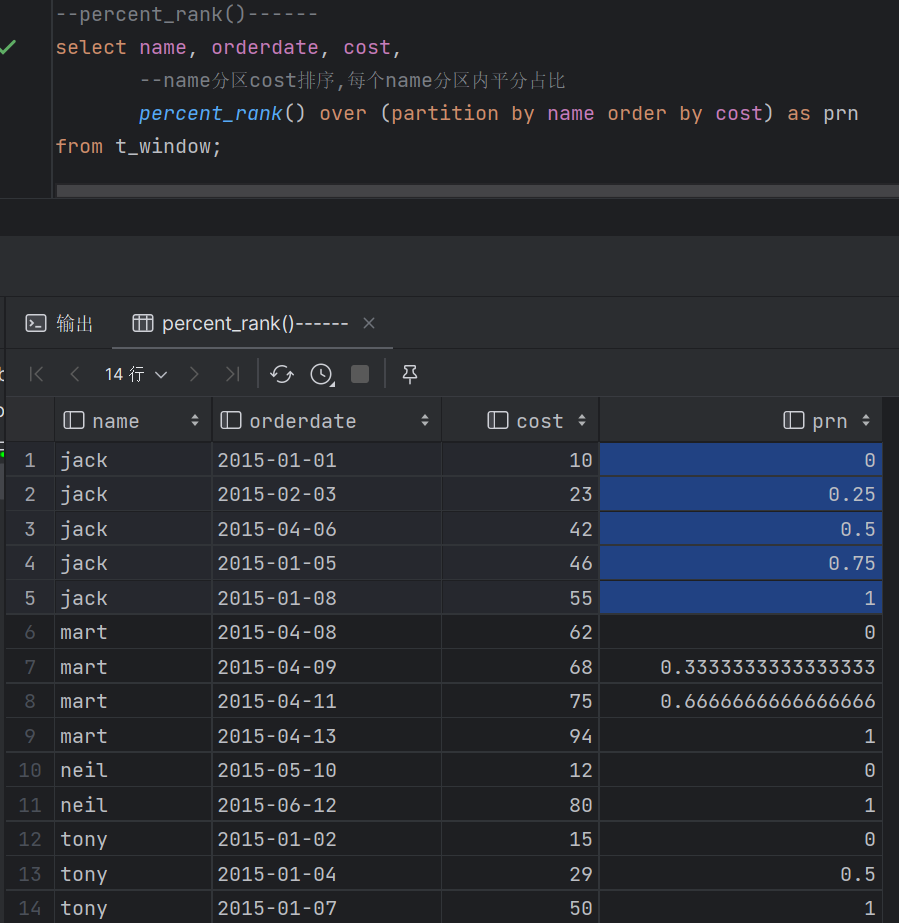
PERCENT_RANK()分区内数据压到0-1区间 (目前排名- 1)/(总行数- 1),值相对于一组值的百分比排名
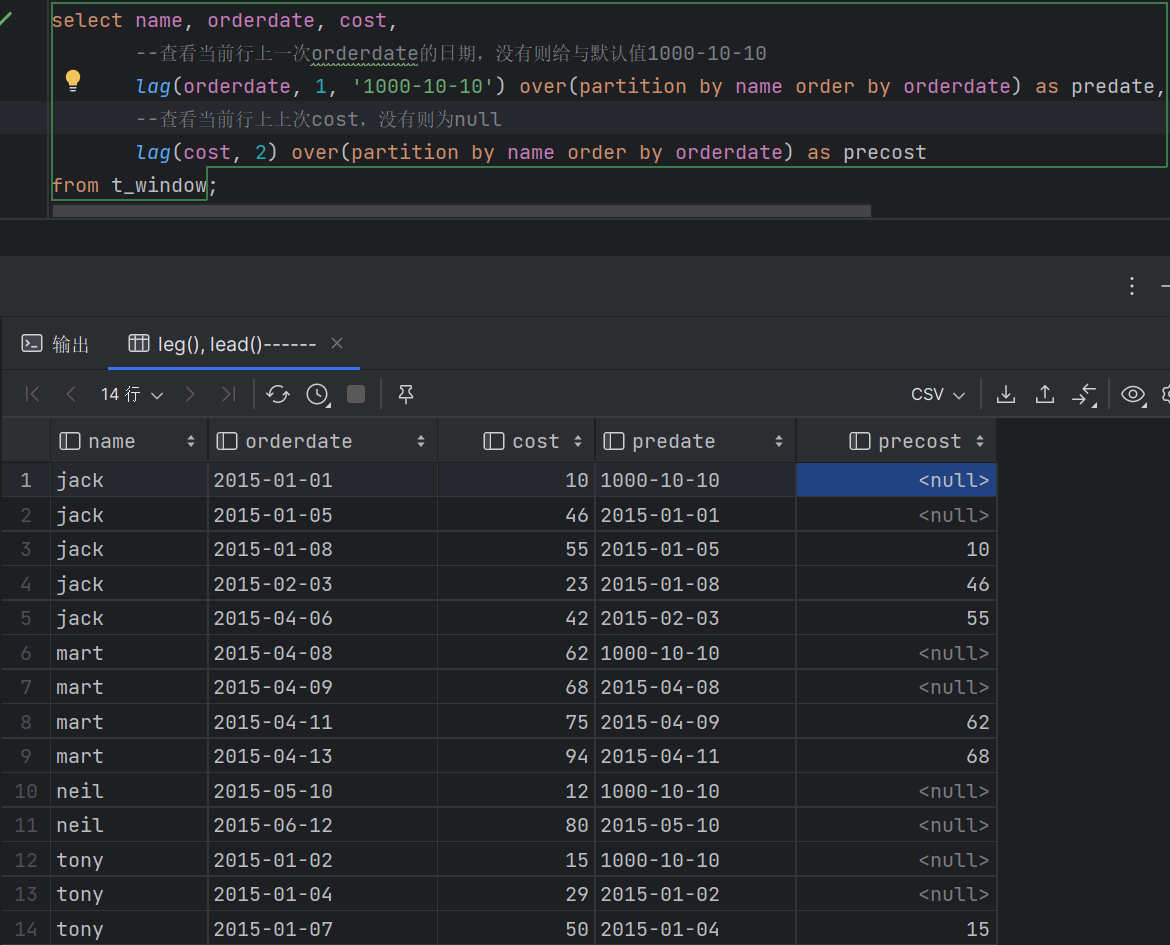
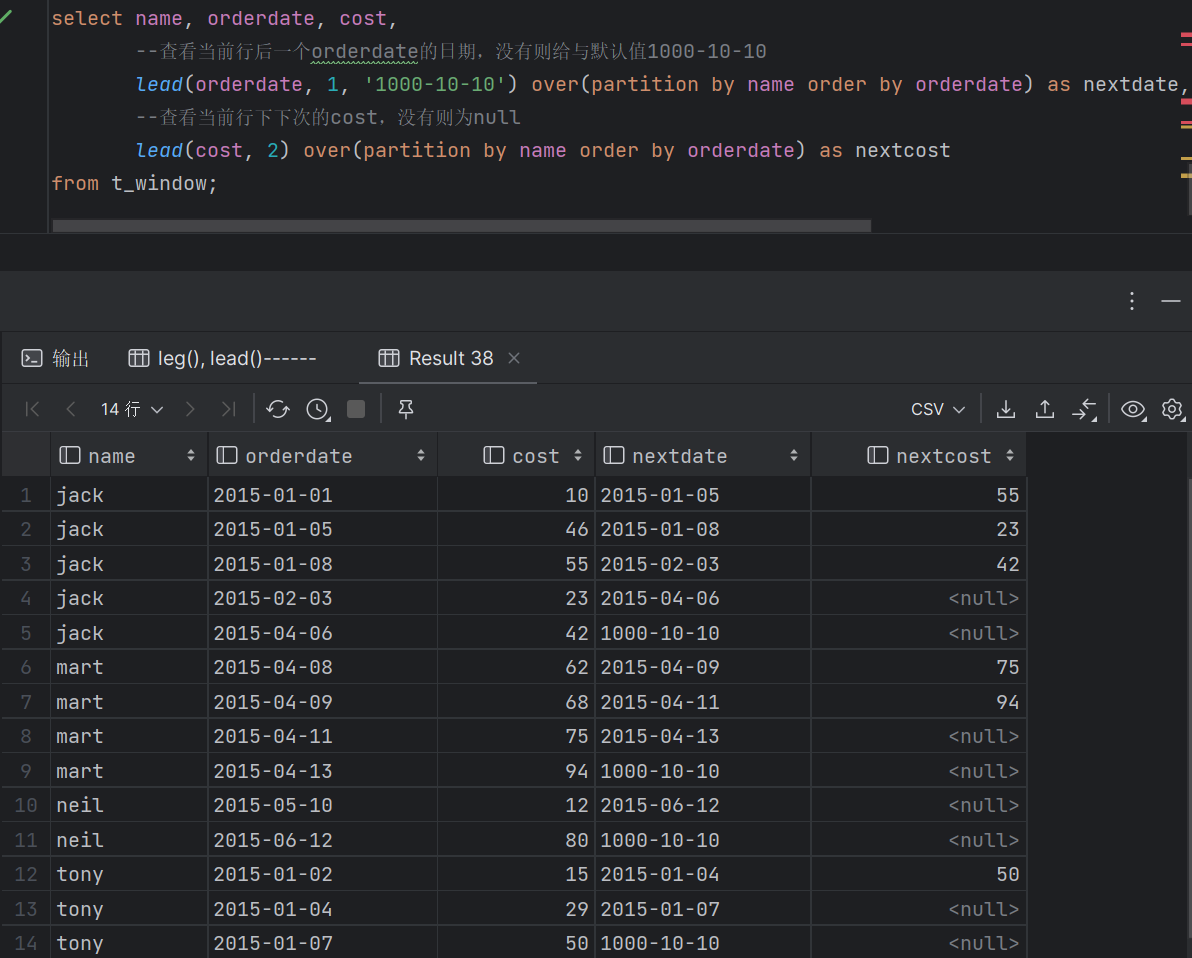
- 聚合 COUNT() 计数,可以和DISTINCT一起用 SUM():求和 AVG():平均值 MAX()/MIN(): 最大/小值 从Hive 2.1.0开始在OVER子句中支持聚合函数 - 分析 CUME_DIST 小于等于当前值的行数/分组内总行数 LEAD/LAG(col,n) 某一列进行往前/后第n行值(n可选,默认为1)
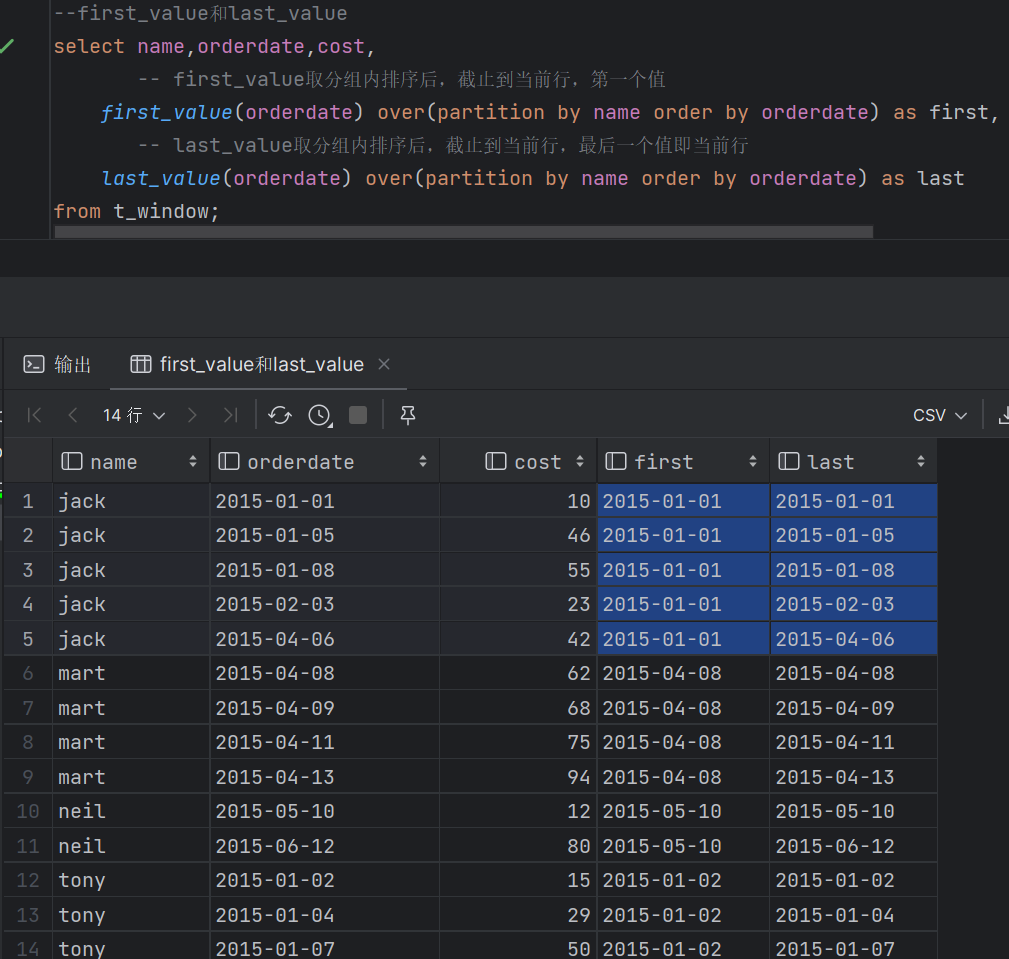
FIRST_VALUE 对该列到目前为止的首个值 LAST_VALUE 到目前行为止的最后一个值
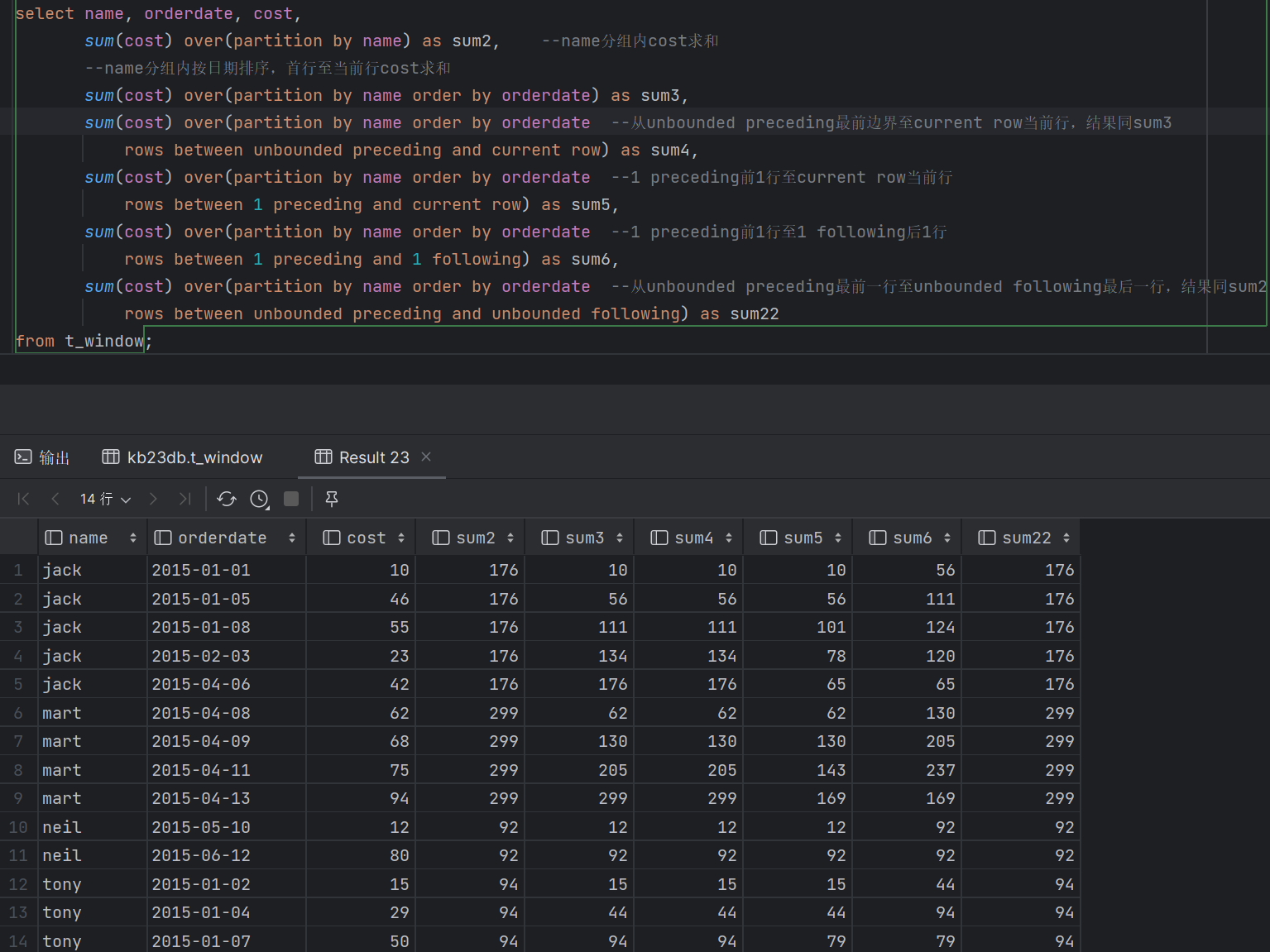
- 窗口定义-1 (1)窗口定义由[<window_clause>]子句描述 用于进一步细分结果并应用分析函数 (2)支持两类窗口定义 行类型窗口 范围类型窗口 (3)RANK、NTILE、DENSE_RANK、CUME_DIST、PERCENT_RANK、LEAD、LAG和ROW_NUMBER函数不支持与窗口子句一起使用 - 窗口定义-2 (1)行窗口:根据当前行之前或之后的行号确定的窗口 ROWS BETWEEN <start_expr> AND <end_expr> (2)<start_expr>可以为下列值 UNBOUNDED PRECEDING : 窗口起始位置(分组第一行) CURRENT ROW:当前行 N PRECEDING/FOLLOWING:当前行之前/之后n行 (3)<end_expr>可以为下列值 UNBOUNDED FOLLOWING : 窗口结束位置(分组最后一行) CURRENT ROW:当前行 N PRECEDING/FOLLOWING:当前行之前/之后n行
- 窗口定义-3 范围窗口是取分组内的值在指定范围区间内的行 该范围值/区间必须是数字或日期类型 目前只支持一个ORDER BY列 |
| 设置本地模式:set mapred.framework.name=local; |
4. Hive函数及性能优化
| 4.1 Hive函数分类 (1)从输入输出角度分类 标准函数:一行数据中的一列或多列为输入,结果为单一值 聚合函数:多行的零列到多列为输入,结果为单一值 表生成函数:零个或多个输入,结果为多列或多行 (2)从实现方式分类 内置函数 自定义函数 UDF:自定义标准函数 UDAF:自定义聚合函数 UDTF:自定义表生成函数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.2 内置函数 (1)Hive提供大量内置函数供开发者使用 标准函数:字符函数、类型转换函数、数学函数、日期函数、集合函数、条件函数 聚合函数 表生成函数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.3 字符函数
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.4 类型转换函数和数学函数
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.5 日期函数
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.6 集合函数
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.7 条件函数
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.8 聚合函数和表生成函数 (1)聚合函数 count、sum、max、min、avg、var_samp等 (2)表生成函数:输出可以作为表使用
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4.9 Hive UDF开发流程 继承UDF类或GenericUDF类 重写evaluate()方法并实现函数逻辑 编译打包为jar文件 复制到正确的HDFS路径 使用jar创建临时/永久函数 调用函数 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||
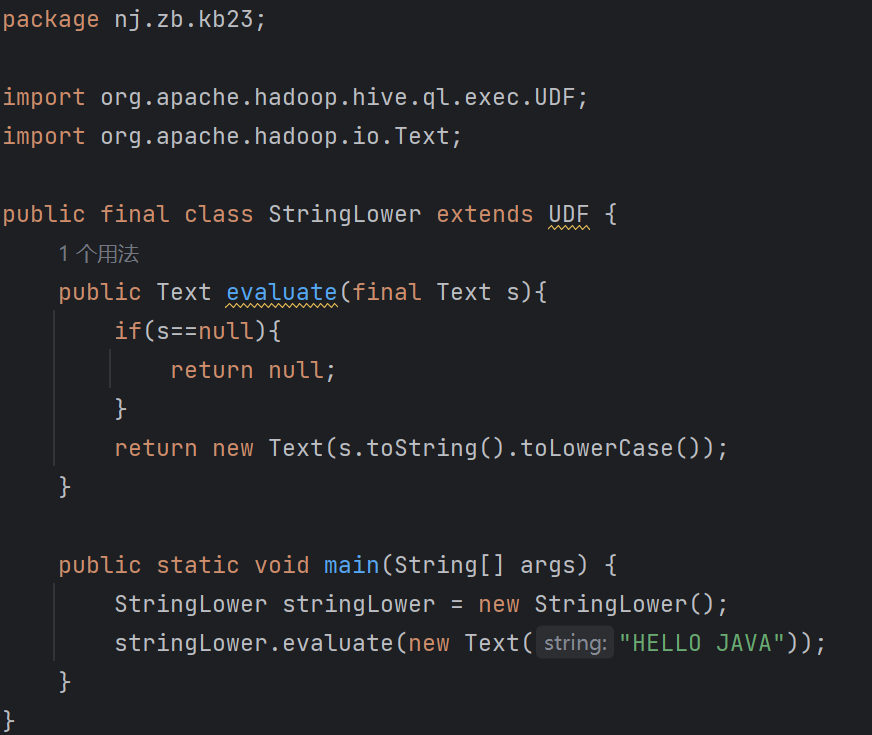
| 4.10 Hive UDF实现 Java IDE, JDK, Maven 继承UDF并重写evaluate()方法 演示:实现以下自定义函数 string_lower(letter) = LETTER 编译、测试和打包jar文件,上传jar并调用函数
上传[root@kb129 kb23]# hdfs dfs -put ./hive_udf-1.0-SNAPSHOT.jar /kb23
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Hive优化参考hive优化大全-一篇就够了_hive 优化_GOD_WAR的博客-CSDN博客 Hive常见set的配置设置https://blog.csdn.net/sweet19920711/article/details/117930785 Hive窗口函数参考Hive:窗口函数_hive窗口函数_花和尚也有春天的博客-CSDN博客 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||