二手车交易信息爬取、数据分析以及交易价格预测
- 引言
- 一、数据爬取
- 1.1 解析数据
- 1.2 编写代码爬
- 1.2.1 获取详细信息
- 1.2.2 数据处理
- 二、数据分析
- 2.1 统计分析
- 2.2 可视化分析
- 三、价格预测
- 3.1 价格趋势分析(特征分析)
- 3.2 价格预测
引言
本文着眼于车辆信息,结合当下较为火热的二手车交易市场数据,对最近二手车的交易价格进行分析以及预测。
经过前期调研,最终决定通过爬取一些网站的二手车数据和一些公开的数据集,分析交易数据的特征,根据交易特征对二手车交易价格进行分析预测。
本文主要核心内容:数据爬取、数据分析、交易价格预测
一、数据爬取
1.1 解析数据
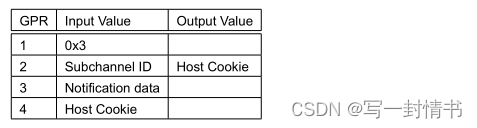
- 选择二手车交易网站-瓜子二手车。点开官网,点击我要买车。以QQ浏览器为例,点击
开发者工具(菜单-工具中),选择Network-DOC过滤。获取头部cookie等相关信息,如下图所示。
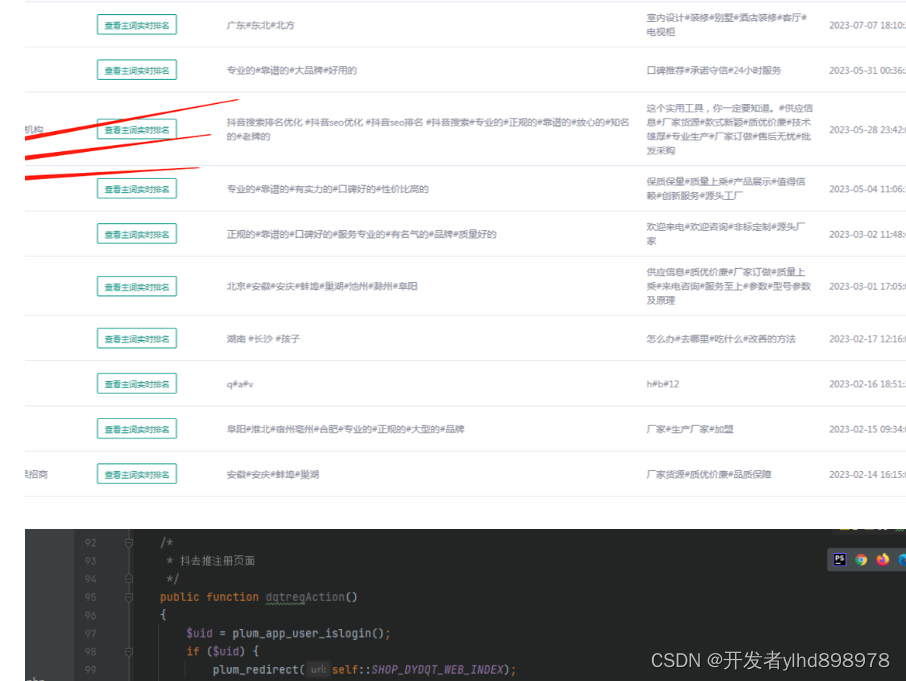
- 通过
搜索框(点击开发者工具页面右上角 ‘竖着的三个点’ - Search),输入页面商品名称和属性名称,获取想要数据的位置,方便后续爬取解析,如下图所示。

- 根据以上获取的信息构造程序的
headers以及编写具体数据的爬取代码
1.2 编写代码爬
1.2.1 获取详细信息
# 获取详细数据的 url
def get_detail_url(url, headers):rq = requests.get(url, headers=headers)soup = BeautifulSoup(rq.text, 'lxml')content = soup.find(class_='carlist clearfix js-top')links = content.find_all('a')detail_url_list = []for link in links:detail_url_list.append(f"https://www.guazi.com{link['href']}")return detail_url_list# 获取详情数据
def get_detail(url, headers):rq = requests.get(url, headers=headers)soup = BeautifulSoup(rq.text, 'lxml')# namecontent = soup.find(class_='product-textbox')title = content.find('h1').text# info (上牌时间为图片) 里程数 排量 变速箱info = content.find(class_='assort clearfix')span = info.find_all('span')if len(span) >= 4:info_dic = {'name': title.strip(), 'km': span[1].text, 'displacement': span[2].text, 'gearbox': span[3].text}else: # 某些网页 span数据较少info_dic = {'name': title.strip(), 'km': span[1].text, 'displacement': '无', 'gearbox': '无'}# price 价格单位是万price = soup.find(class_='price-num') # price-num pricebox js-dispriceprice = price.text# 销售方seller = soup.find(class_='ten')seller = seller.find(class_='typebox')seller = seller.text# 燃油类型fuel = soup.find_all(class_='td2') # 很多信息 第十五个是燃油类型 或者 没有信息horsepower = "无"if len(fuel)>=13:horsepower = fuel[12].textif len(fuel)>=15:fuel = fuel[14].textelse:fuel = "无"# fuelreturn info_dic, price, seller, fuel,horsepower1.2.2 数据处理
-
数据集补充
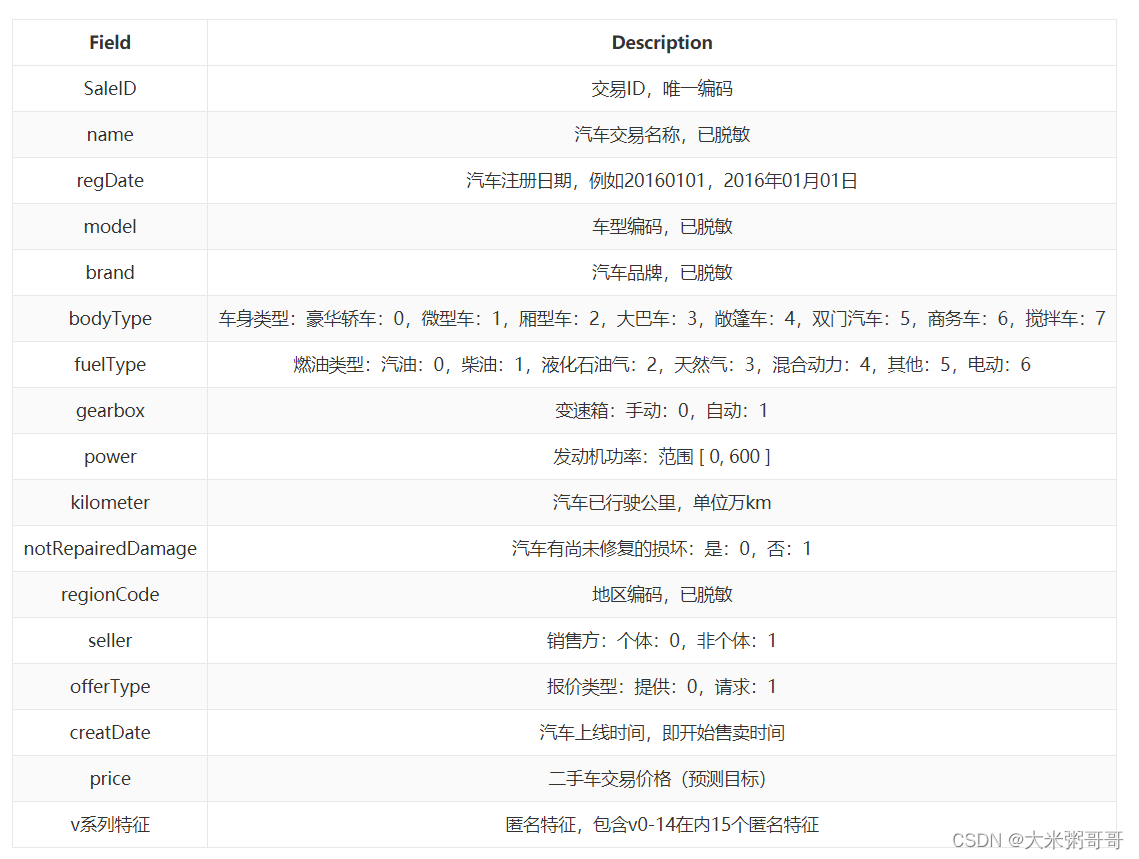
网站上的数据爬取难度较高,且数据量较少,一直爬取容易被封IP,所以这里使用公开赛的一个数据集对数据进行补充------阿里天池的二手车交易价格预测数据集,其数据具体内容如下图所示。
-
统一数据格式
网站上爬取的数据与公开赛数据集的数据是不一致的,相对来说公开赛数据集的标签比较多,信息比较详细,且数据类型单一,方便后续处理。所以这里需要对两个数据集进行统一,爬取的数据向公开赛数据靠拢,并将其转换为同一单位(比如fuelType网站上的数据是汉字,而公开赛数据集里的数据为数字,为了较少存储内存以及方便数据的后续处理,在这里将其统一为数字),同时删除无法在网站上爬取的公开赛数据中的标签。 -
代码
name = []
fuelType = []
gearbox = []
power = []
kilometer = []
seller = []
price = []
# 爬取 保存数据
for page in range(1,3):print("************第{}页正在保存**********".format(page)) # 每一页 数量不定base_url = 'https://www.guazi.com/sjz/buy/o{}/#bread'.format(page) #detail_url = get_detail_url(base_url, headers) # 所有车辆详细信息链接print(len(detail_url))for d_url in detail_url:print(d_url)info_dic, pric, sell, fuel, horsepower = get_detail(d_url, headers)name.append(info_dic['name']) # 名字if fuel.find("汽油"):fuel = 0elif fuel.find("柴油"):fuel = 1elif fuel.find("液化石油气"):fuel = 2elif fuel.find("天然气"):fuel = 3elif fuel.find("混合动力"):fuel = 4else:fuel = 6fuelType.append(fuel) # 燃油类型tmp = info_dic['gearbox']if tmp.find("手动"):tmp = 0else: # 电动汽车 大多是自动挡tmp = 1gearbox.append(tmp) # 变速箱 自动 or 手动tmp = re.findall("\d+", horsepower)if len(tmp) == 0:tmp = 0else:tmp = int(tmp[0]) * 0.735power.append(tmp) # 功率km = re.findall(r"\d+\.?\d*", info_dic['km'])if len(km) == 0:km = 0else:km = float(km[0])kilometer.append(km) # 里程数if sell.find("私户"):sell = 0else:sell = 1seller.append(sell) # 销售方、tmp = re.findall(r"\d+\.?\d*", pric)if len(tmp) == 0:tmp = 0else:tmp = float(tmp[0]) * 10000price.append(tmp) # 价格df = pd.DataFrame({'name' : name,'fuelType': fuelType,'gearbox' : gearbox ,'power' : power,'kilometer': kilometer,'seller' : seller,'price' : price})
df.to_csv('guazi.csv') # 最终保存为csv文件二、数据分析
2.1 统计分析
- 以
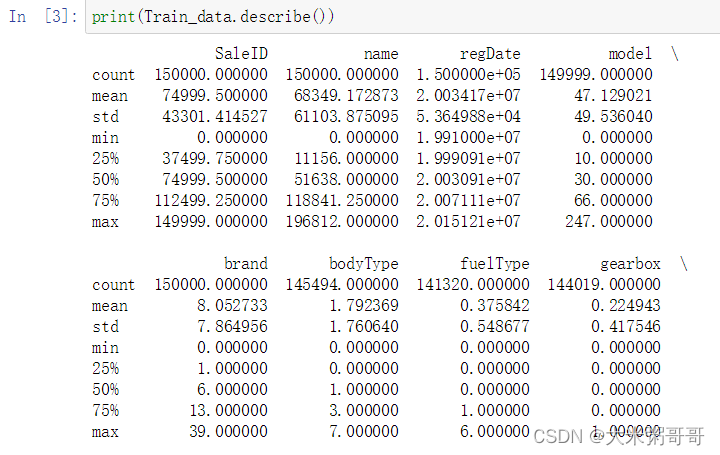
公开数据集为例,这里只显示了其部分标签列(共30列),一共有15万条交易数据。可以看到每一个数据的SaleID都是不同的,从0递增到149999,name标签最大为19万,但是其一共只有15万条数据,想必name的分布也是相对均匀的。model是车型编码,最大为247,数据中车辆种类一共不超过248种。之后标签的max都很小,其分布相对密集。
查看数据类型、缺失和异常值
代码
#!/usr/bin/env python
# coding: utf-8
## 导入所需包
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
import pickle
warnings.filterwarnings('ignore')
## 在Jupyter noteboo显示图像
get_ipython().run_line_magic('matplotlib', 'inline')
from sklearn import linear_model ## 模型预测的
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA ## 数据降维处理的
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error#Train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ') # shape: (150000, 40)
Train_data = pd.read_csv('guazi.csv', sep=',') # shape: (150000, 40)# In[10]:
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
print(Train_data.describe())# In[11]:
Train_data.head()# In[12]:
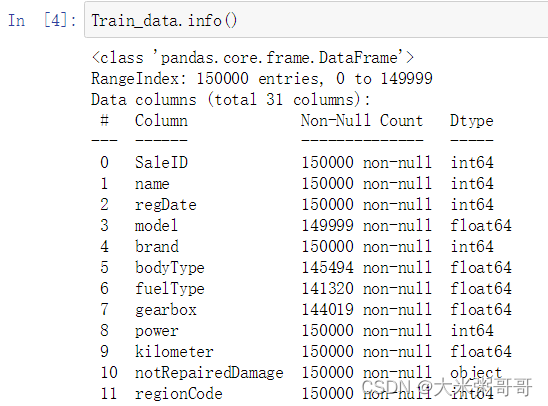
Train_data.info()# In[13]:
Train_data.isnull().sum()2.2 可视化分析
#!/usr/bin/env python
# coding: utf-8
## 导入所需包
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
import pickle
warnings.filterwarnings('ignore')
## 在Jupyter noteboo显示图像
get_ipython().run_line_magic('matplotlib', 'inline')
from sklearn import linear_model ## 模型预测的
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA ## 数据降维处理的
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error#Train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ') # shape: (150000, 40)
Train_data = pd.read_csv('guazi.csv', sep=',')
# In[3]:
plt.hist(Train_data['price'])
plt.show()
# In[4]:
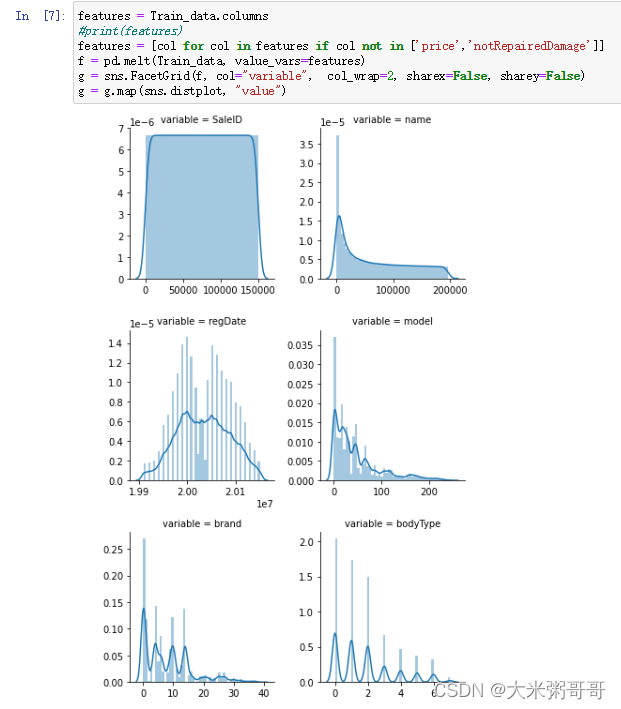
features = Train_data.columns
#print(features)
features = [col for col in features if col not in ['price','notRepairedDamage']]
f = pd.melt(Train_data, value_vars=features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
# In[ ]:三、价格预测
爬取的车辆数据集特征数量较少,能否准确预测交易价格?
3.1 价格趋势分析(特征分析)
- 按照爬取数据集的特征选取公开赛数据集的部分特征,然后将其分为训练集和验证集,训练集用于训练,验证集用于验证训练的模型的好坏(
模型采用xgboost),然后对爬取数据进行测试,查看预测价格与实际价格的分布是否大致相同。
以下是结果图,黄色表示为实际价格,蓝色为预测价格*6,由于公开赛数据集的二手车交易价格普遍较低,所以预测出来的价格也相对实际价格较低,这里乘以6是为了方便观察其价格分布。
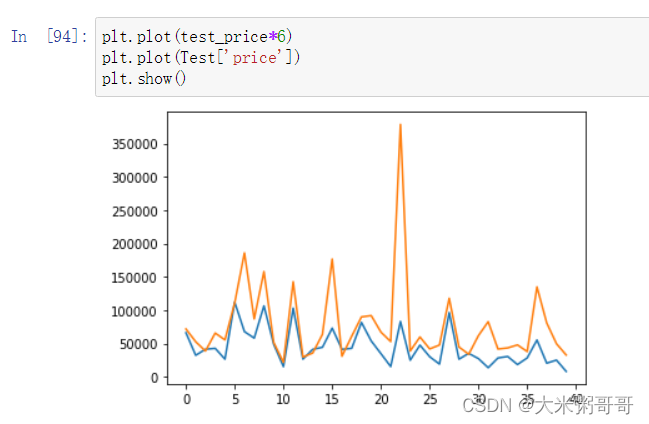
- 可以看到实际价格和预测价格的趋势大致相同,再计算以下他们的相关性,如下图。
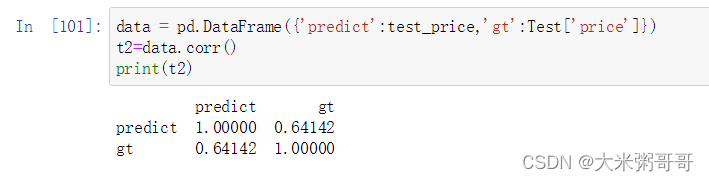
代码
## 导入所需包
import pandas as pd
import matplotlib.pyplot as plt
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
Train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ') # shape: (150000, 40)
## 查看列
#print(Train_data.columns)
cols = Train_data.columns
## 选择特征列
feature_cols =['fuelType','gearbox','power','kilometer','seller']
## 构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
def build_model_lgb(x_train,y_train):model = lgb.LGBMRegressor(objective='regression',max_depth = 10,num_leaves = 1000,learning_rate=0.1, n_estimators=100,metric='rmse', #bagging_fraction = 0.8, feature_fraction = 0.8)model.fit(x_train, y_train)return model
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.2)
# 训练模型
print('Predict lgb...')
model_lgb = build_model_lgb(x_train,y_train)
print('ok!')
# 测试模型
val_lgb = model_lgb.predict(x_val)
val_lgb[val_lgb<0] = 0
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
MAE = mean_absolute_error(y_val,val_lgb*0.5)
print('MAE:',MAE)Test = pd.read_csv('guazi.csv', sep=',') # shape
test_price = model_lgb.predict(Test[feature_cols])
#mean_absolute_error(Test['price'],test_price)
plt.plot(test_price*6)
plt.plot(Test['price'])
plt.show()
data = pd.DataFrame({'predict':test_price,'gt':Test['price']})
t2=data.corr()
print(t2)3.2 价格预测
-
通过对价格趋势的分析,有理由相信爬取的
有限的这几个特征:['fuelType','gearbox','power','kilometer','seller'],在一定程度上影响着车辆的价值。同时由于公开赛数据集的价格与爬取数据集的价格相差很大,所以没有办法使用公开赛数据集对爬取数据集做定量分析。只能爬取跟多的二手车数据集对二手车交易价格做定量的预测。 -
相对于价格趋势分析,这里同样使用的是
lgb模型,但是为了价格预测的准确性,将学习率降低为0.01,迭代次数增加为十万次。其测试误差如下(MAE-平均绝对误差7755):

-
查看实际价格与预测价格的折线图:

-
代码
#!/usr/bin/env python
# coding: utf-8
## 导入所需包
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import time
import pickle
warnings.filterwarnings('ignore')
## 在Jupyter noteboo显示图像
get_ipython().run_line_magic('matplotlib', 'inline')
from sklearn import preprocessing
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_errorTrain_data = pd.read_csv('guazi_more.csv', sep=',') # shape: (150000, 40)
#TestA_data = pd.read_csv('used_car_testB_20200421.csv', sep=' ') # shape: (50000, 39)
Train_data.describe()# In[35]:
## 查看列
#print(Train_data.columns)
cols = Train_data.columns
## 选择特征列
feature_cols =['fuelType','gearbox','power','kilometer','seller']
## 构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.2)# In[62]:
def build_model_lgb(x_train,y_train):model = lgb.LGBMRegressor(objective='regression',max_depth = 10,num_leaves = 1000,learning_rate=0.01, n_estimators=100000, # 60000 7千 # metric='rmse', #bagging_fraction = 0.8, feature_fraction = 0.8)model.fit(x_train, y_train)return model# In[63]:
# 训练模型
print('Predict lgb...')
model_lgb = build_model_lgb(x_train,y_train)
print('ok!')# In[64]:
# 测试模型
val_lgb = model_lgb.predict(x_val)
#val_lgb[val_lgb<0] = 0
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb) # In[68]:
x = np.arange(0,len(y_val),1)
plt.plot(x,val_lgb) # scatter
plt.plot(x,y_val)
plt.figure(figsize=(30,10),dpi=36)
plt.show()# In[69]:
data = pd.DataFrame({'predict':val_lgb,'gt':y_val})
t2=data.corr()
print(t2)