计算机视觉领域下自监督学习方法原理
- 导语
- 为什么在计算机视觉领域中进行自我监督学习?
- 自监督学习方法
- Generative methods
- BEiT 架构
- Predictive methods
- Contrastive methods
- Bootstraping methods
- Simply Extra Regularization methods

导语
自监督学习是一种机器学习方法,它利用未标记的数据来训练模型,而无需人工标注的标签。相反,自监督学习通过利用数据中的自动生成的标签或任务来训练模型。
现在,让我使用拟人化的方法来解释自监督学习的原理。假设你是一个学习者,而计算机视觉任务是你需要完成的作业。然而,与传统的监督学习不同,你的老师并没有直接告诉你作业的答案。相反,他提供了一些提示和线索来帮助你解决问题。这些提示可以是关于图像的一些变换,比如旋转、裁剪或翻转。你的任务是根据这些变换之间的关系来预测图像的正确答案,比如预测旋转前后的角度或翻转前后的方向。通过预测这些自动生成的标签,你逐渐理解了图像的结构和特征,从而学会了计算机视觉任务。
类似地,自监督学习中的计算机模型也通过观察数据中的自动生成的标签来学习图像的特征。这种方法利用了数据中的内在结构和关联性,无需手动标注大量的数据。通过大规模的未标记数据,模型可以自主地学习视觉特征,从而在各种计算机视觉任务中表现出色。
为什么在计算机视觉领域中进行自我监督学习?
尽管视觉模型有很多很好的模型,但它们的成功取决于对数据的巨大需求。因此,以有监督的方式培训这些模型需要广泛的标签工作,这并不总是可能的或可持续的。因此,实现视觉模型的自我监督方法可能是一种可能的方式,使这些模型不仅强大,而且更容易应用于更广泛的问题。
为了理解这种方法有多强大,让我们先来看看自然语言处理领域,在那里,自我监督的方法可以实现难以想象的结果。
GPT-3是迄今为止最大的语言模型之一,拥有1750亿个参数,被认为是迈向人工通用智能(AGI)的第一步,能够翻译文本、总结文本、回答问题,甚至根据文字描述编写代码!但要训练这样一个同样基于变形金刚的大型模型,你需要大量数据,尤其是GPT-3,它是用通过在互联网上爬行收集的570GB文本信息进行训练的。假设我们想以监督的方式训练这个模型,这意味着手动标记所有这些数据,这太疯狂了!
自监督学习方法
🎙🕺🤟🏀
Self-Supervised Learning (自监督学习) 在计算机视觉领域主要分为五种方法,包括生成方法、预测方法、对比方法、自助法和简单的额外正则化方法。这样的划分是为了应对不同的问题和任务,并且通过不同的方法来训练模型从未标记的数据中学习有用的表示。
- 生成方法 (Generative methods):
生成方法通过从未标记的数据中生成合成样本来进行自监督学习。例如,使用自动编码器 (autoencoders) 或生成对抗网络 (generative adversarial networks, GANs) 来重构或生成与原始图像相似的图像。模型通过学习将图像转换为低维表示,并再次还原回原始图像,从而学习图像的有用特征。 - 预测方法 (Predictive methods):
预测方法通过使用未标记数据中的自动生成的标签来训练模型。这些标签可以是对图像进行旋转、遮挡、颜色变换等操作后的预测结果。模型学习通过自主预测这些变换后的图像来理解图像的内容和结构。 - 对比方法 (Contrastive methods):
对比方法通过将同一图像的不同变换或不同图像之间的关系进行对比学习。模型被要求区分同一图像的不同变换或从数据集中选择的不同图像。这样,模型能够学习到图像之间的相似性和差异性,从而学习到更具有判别性的特征。 - 自助法 (Bootstraping methods):
它通过利用自动生成的标签和模型的预测结果来迭代地训练模型,从而提高模型的性能。。这种方法允许模型逐步提高性能,并在迭代中不断改进。 - 简单的额外正则化方法 (Simply Extra Regularization methods):
简单的额外正则化方法通过在模型训练过程中引入额外的正则化约束来促使模型学习有用的表示。例如,使用降噪自编码器 (denoising autoencoders) 在输入数据中添加噪声,强制模型学习抵抗噪声的能力,从而学习到更鲁棒的特征表示。这些不同的自监督学习方法的划分是为了解决不同的问题和任务,并从未标记的数据中提取有用的信息。
下面的表格,我按照监督学习输入(input)和目标(label)的格式形式来分别表示这五种方法的输入和目标构成。
| method | input | label |
|---|---|---|
| 生成方法 (Generative methods) | 遮挡后的图像 | 没有遮挡的图像 |
| 预测方法 (Predictive methods) | 旋转的图像 | 原始图像 |
| 对比方法 (Contrastive methods) | 图像 | 其他图像 |
| 自助法 (Bootstraping methods) | 目标网络输出的特征 | 在线网络输出的特征 |
| 简单的额外正则化方法 (Simply Extra Regularization methods) | 网络A输出的特征 | 网络B输出的特征 |
小编将结合当下热门论文中提出的算法,详细介绍五种方法的原理。
Generative methods
计算机视觉自监督学习Generative methods方法中最经典的模型有BeiT(Bert for Image Recognition),它是一种基于BERT(Bidirectional Encoder Representations from Transformers)模型的生成方法,用于图像识别任务。
BERT最初是为自然语言处理(NLP)任务设计的,但研究人员发现其在计算机视觉领域也具有潜力。BERT是一种预训练的深度双向Transformer模型,通过学习上下文关系,将单词或标记嵌入到高维空间中。它通过在大规模文本语料库上进行掩码语言建模和下一句预测任务的预训练,从而学习到丰富的语义表示。受BERT启发,提出了一种预训练任务,即遮蔽图像建模(Masked Image Modeling,MIM)进而实现BeiT模型。
BeiT旨在将自然语言处理中的预训练Transformer模型应用于计算机视觉领域,实现图像的特征学习和识别。它通过在大规模图像数据集上进行自监督预训练,学习到图像的高级特征表示。
例如下图所示,通过人为去掉(mask)图像一部分信息,让模型学习图像的上下文内容(周围的图像信息)去生成这部分缺失(mask)的图像信息。
BEiT 架构
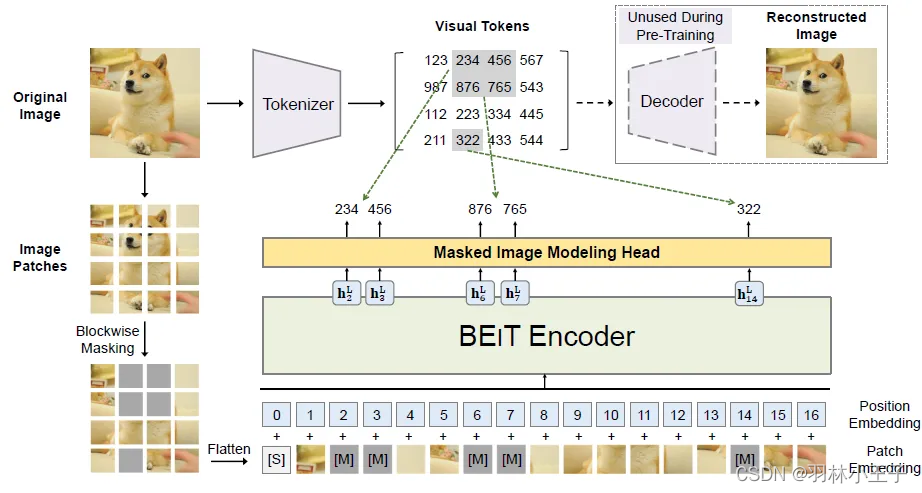
下面我将通过整体架构,详细介绍架构中的算法流程和原理
图片表示(Image Patches和Visual Tokens)
在BEIT视角下,图片有二种表示方式,Image Patcheshe和viual Tokens。
image → image patches | visual tokens
将图片转为这二种方式,也是为了在自监督学习原理下,通过自身数据集做出模型的input和label。,以便在预训练过程中,做为模型的输入和输出,我们选择什么样的图片做为输入,最后模型就学到了这类图片的学习经验
| input | label |
|---|---|
| 遮挡后的图像 | 没有遮挡的图像 |
Image Patches流程:
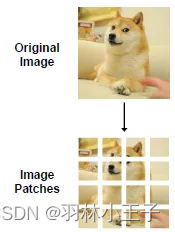
- 将尺寸为 H × W × C H\times W \times C H×W×C 的二维图像被分割成一系列大小为 P × P P \times P P×P 的小块(小块数量为N),其中数量 N = H × W p × p N = \frac{H \times W}{p \times p} N=p×pH×W。
- 遮挡mask一部分块,然后将所有patch块展平为向量,并进行线性投影,这类似于 BERT 中的单词嵌入。(与vit模型处理数据的方法一致从Transformer到ViT:多模态编码器算法原理解析与实现)
特别注意,BEiT 将每个 224×224 的图像分割成一个 14×14 的图像patch网格,其中每个patch的大小为 16×16。
Visual Tokens流程:
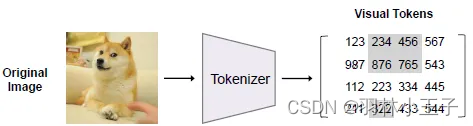
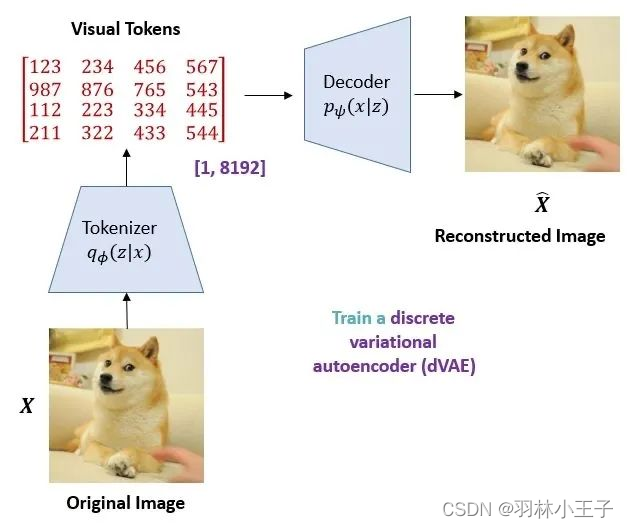
这个过程beit通过dVAE模型里一个image tokenizer模块将输入的图像转换为一系列的离散的tokens,以便模型能够对它们进行处理。
整个模型架构也是又解码器和编码器共同组成,解码器和编码器都dVAE构成,通过编码器将图像映射到隐变量空间上,再用解码器将隐变量重建为原图。
Predictive methods
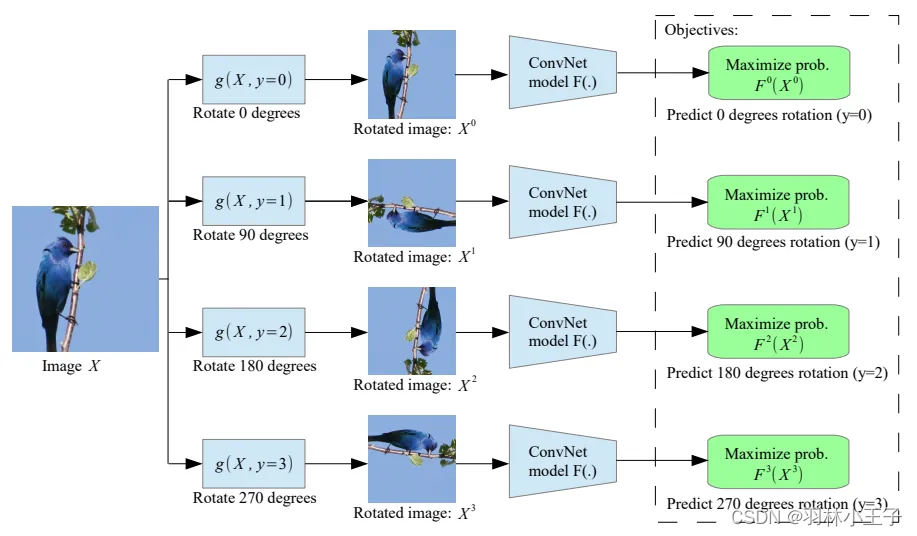
以ICLR 2018 的 Unsupervised Representation Learning by Predicting Image Rotations这篇论文为例。
该方法,说白就是将原始图像进行做旋转变换,旋转图像0、90、180、270度。
模型的input就是旋转后的图像,label就是原始图像,通过模型ConvNet学习到不同旋转图像的特征,来预测那个旋转的图像与原始图像最接近。
| input | label |
|---|---|
| 旋转的图像 | 原始图像 |
Contrastive methods
对比学习方法是自监督学习中常用的一种技术,用于通过比较样本之间的相似性来训练模型。在对比学习中,模型被要求区分正样本对和负样本对,以学习样本之间的语义关系。
| input | label |
|---|---|
| 图像 | 其他图像 |
模型架构主要是使用 Siamese Network。如下图所示
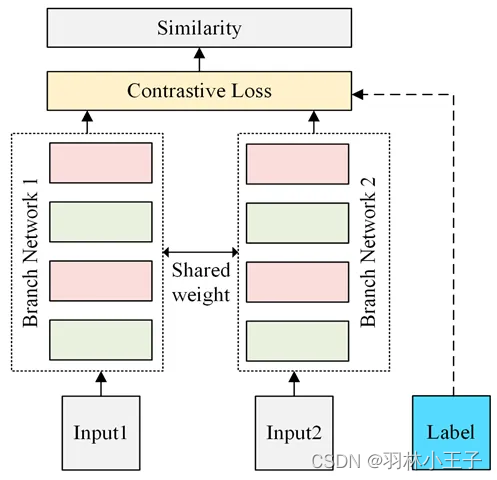
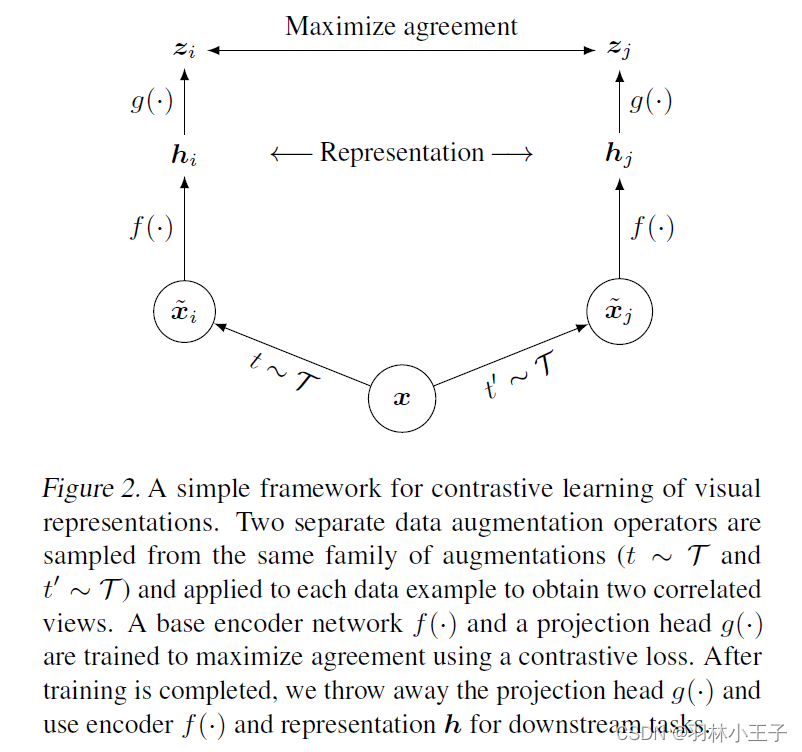
这里以SimCLRv1模型举例来详细介绍对比学习的方法原理:
论文链接:https://arxiv.org/abs/2002.05709
整个模型的网络结构,如下图所示。它包含四个组成部分:
- 一个随机数据增强模块,用于产生同一个示例的两个相关图片,这两个相关图片可以被认为是正例。数据增强方式就是前面提到的(随机裁剪而后调整到与原图一样大小,随机颜色扭曲、随机高斯模糊)。
- 一个神经网络编码层f(),用于提取表示向量,这部分对网络结构没有限制,论文里用的是 ResNet
- 映射层,用于将表示层输出映射到对比损失空间。
- 对比学习loss。
其中对比学习 loss 的计算公式为:
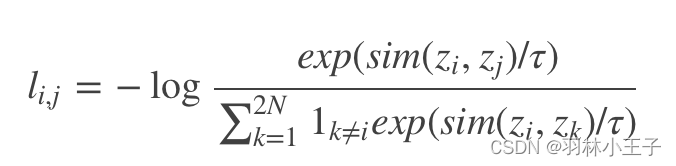
其中 sim 使用 L2 标准化的表征上计算 cosine 相似度。公式的含义是正例的相似度与其他所有负例的相似度在除以 τ
后算一下 softmax loss。也就是尽肯能的让正例在样本空间与原图片更相近,负例推得更远。
下面提供一张gif可以更直观看出对比学习的流程

Bootstraping methods
自助法(Bootstraping methods)是自监督学习中常用的一种方法,特别适用于计算机视觉领域。它通过利用自动生成的标签和模型的预测结果来迭代地训练模型,从而提高模型的性能。
下面通过BYOL (Bootstrap your own latent)模型来详细介绍这个方法的原理。
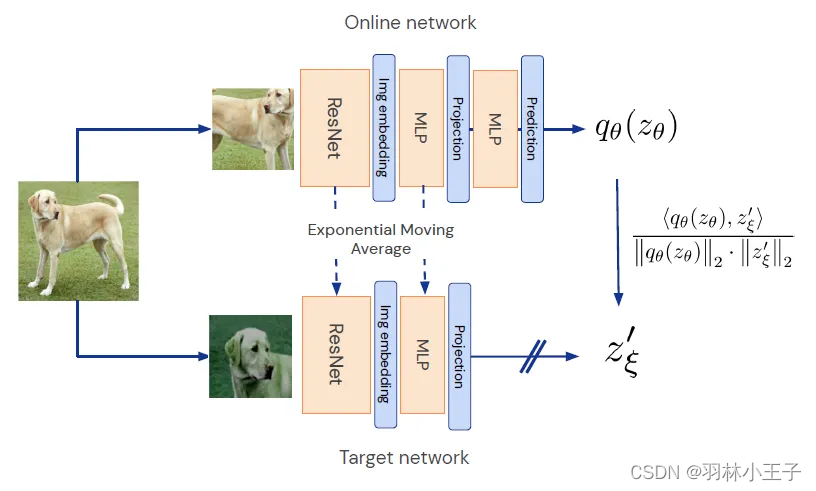
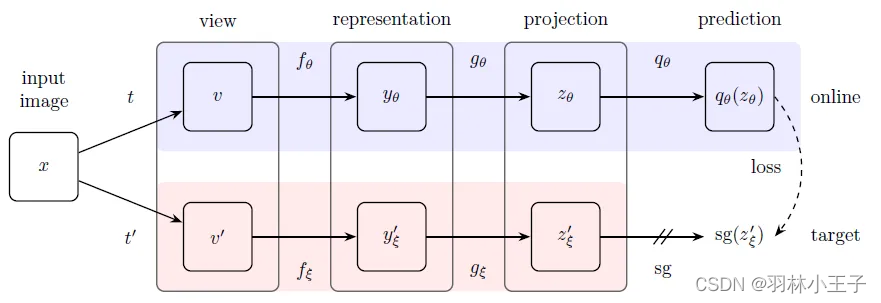
BYOL(Bootstrap Your Own Latent)是一种自监督学习方法,其基本原理是通过在线网络和目标网络之间的相互学习来训练模型。
在线网络(online network)和目标网络(target network)是两个神经网络,它们在BYOL中起着关键的作用。在线网络负责从图像的增强视角中提取特征,并预测同一图像在不同增强方法下的目标网络表示。目标网络则通过平均化在线网络的参数来进行更新,以保持稳定性和模型的持续进展。
增强视角指的是对原始图像应用一系列的数据增强方法,例如旋转、剪裁、缩放等。通过从不同的增强视角观察同一图像,模型可以学习到图像的不变性和丰富的表示
这种方法无需使用负样本和对比损失,具有在图像分类、语义分割和深度预测等任务中表现良好的特点,并且在学术界得到广泛关注和引用。
BYOL其算法流程和原理如下:
- 数据准备:准备大规模的未标记数据集,例如图像数据。
- 网络架构:定义在线网络(online network)和目标网络(target network),它们可以使用卷积神经网络(CNN)或其他深度学习模型。
- 数据增强:对每个未标记图像应用一系列的数据增强操作,例如随机裁剪、旋转、翻转等,以产生增强的图像。
- 在线网络预测:使用在线网络对增强后的图像进行前向传播,得到在线网络的输出特征向量。
- 目标网络更新:通过平均化在线网络的参数来更新目标网络的参数,这可以通过指数滑动平均等方法实现。
- 目标网络预测:使用更新后的目标网络对同一增强图像进行前向传播,得到目标网络的输出特征向量。
- 损失函数计算:计算在线网络的输出特征向量与目标网络的输出特征向量之间的损失函数。常用的损失函数是均方差损失函数(Mean Squared Error,MSE)或余弦相似度损失函数(Cosine Similarity Loss)。
- 反向传播和参数更新:根据损失函数的梯度,执行反向传播算法,并更新在线网络的参数。
- 重复迭代:重复执行步骤3至步骤8,使用不同的增强视角和未标记图像进行迭代训练。通常情况下,每个迭代步骤会采用不同的图像增强方式。
跟GAN模型方法有点异曲同工的意思。
| input | label |
|---|---|
| 目标网络输出的特征 | 在线网络输出的特征 |
BYOL架构图如下所示:
Simply Extra Regularization methods
这里以这篇论文Barlow Twins: Self-Supervised Learning via Redundancy Reduction为例来介绍这个方法
论文链接:https://arxiv.org/abs/2103.03230
Barlow Twins:通过冗余减少实现的自监督学习
Barlow Twins原理是通过衡量两个相同网络的输出之间的互相关矩阵,并使其尽可能接近单位矩阵,来实现特征的冗余减少。这种冗余减少的原则是受到神经科学家H. Barlow的启发。,
Barlow Twins模型中的冗余减少目标函数可以看作是一种额外的正则化方法,它在训练过程中通过衡量网络输出的互相关矩阵来减少特征的冗余。这有助于提高模型的泛化能力和学习效果。
模型架构图所下图所示:
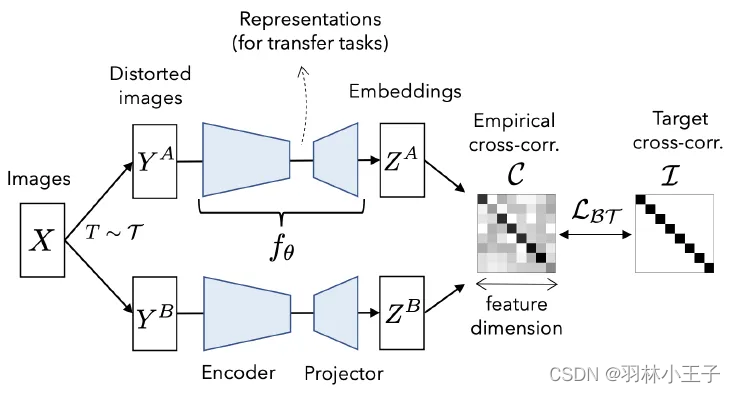
我们都知道如果二个向量很相似,那他们就互相关,那它们的相关矩阵在对角线上的值就比周围的值更大。也就更接近单位矩阵,放到图像的维度上,向量也就是图像在模型上的输出后的特征
| input | label |
|---|---|
| 网络A输出的特征 | 网络B输出的特征 |