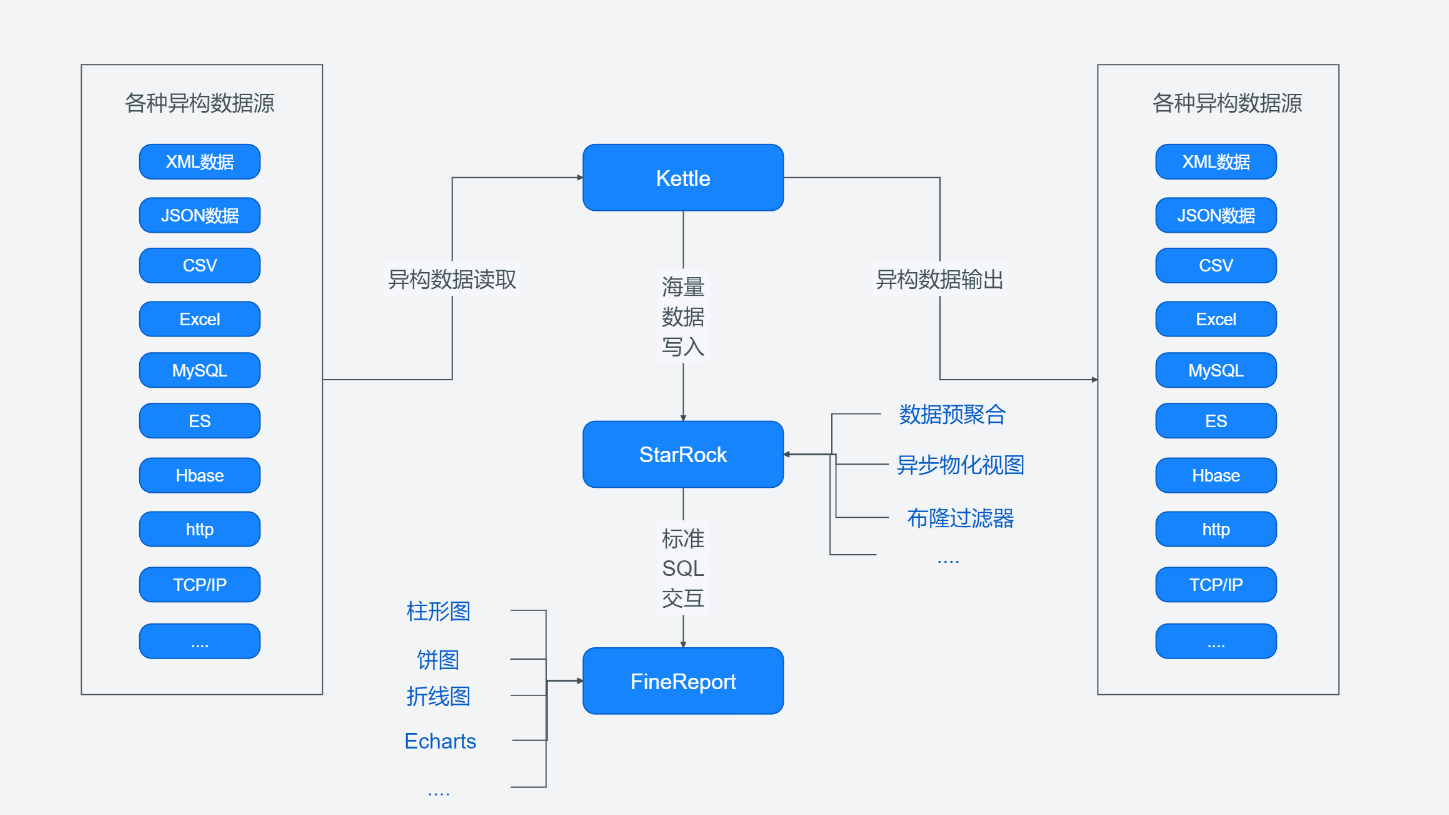
Kettle + StarRocks + FineReport 的大数据处理分析方案
其中 Kettle 负责数据的ETL处理,StarRocks 负责海量数据的存储及检索,FineReport 负责数据的可视化展示。整体过程如下所示:
如果多上面三个组件不了解可以先参考下下面的文章:
Kettle 介绍及基本使用
StarRocks 极速全场景 MPP 数据库介绍及使用
FineReport 快速设计联动报表
一、实验数据及数据规划
COVID-19,简称“新冠肺炎”,世界卫生组织命名为“2019冠状病毒病” [1-2] ,是指2019新型冠状病毒感染导致的肺炎。现有美国 2021-01-28 号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)
2021-01-28,Pike ,Alabama,01109,2704,35
2021-01-28,Randolph,Alabama,01111,1505,37
2021-01-28,Russell,Alabama,01113,3675,16
2021-01-28, Shelby ,Alabama,01117,19878,141
2021-01-28,St. Clair,Alabama,01115,8047,147
2021-01-28, Sumter ,Alabama,01119,925,28
2021-01-28,Talladega,Alabama,01121,6711,114
2021-01-28,Tallapoosa,Alabama,01123,3258,112
2021-01-28, Tuscaloosa ,Alabama,01125,22083,283
2021-01-28,Walker,Alabama,01127,6105,185
2021-01-28, walker,Alabama,01129,1454,27
数据集下载:
https://download.csdn.net/download/qq_43692950/86805389
数据规划 及 表设计
最终呈现希望要根据 县 和 州 分别统计确诊病例和死亡病例的总数、最大值,并以图表的形式展示。
可以考虑使用 StarRocks 聚合模型和明细模型:
-- 县聚合表
DROP TABLE IF EXISTS agg_county;
CREATE TABLE IF NOT EXISTS agg_county (county VARCHAR(255) COMMENT "县",cases_sum BIGINT SUM DEFAULT "0" COMMENT "确诊总数",cases_max BIGINT MAX DEFAULT "0" COMMENT "确诊最大值",deaths_sum BIGINT SUM DEFAULT "0" COMMENT "死亡总数",deaths_max BIGINT MAX DEFAULT "0" COMMENT "死亡最大值"
)
DISTRIBUTED BY HASH(county) BUCKETS 8;-- 州聚合表
DROP TABLE IF EXISTS agg_state;
CREATE TABLE IF NOT EXISTS agg_state (state VARCHAR(255) COMMENT "州",cases_sum BIGINT SUM DEFAULT "0" COMMENT "确诊总数",cases_max BIGINT MAX DEFAULT "0" COMMENT "确诊最大值",deaths_sum BIGINT SUM DEFAULT "0" COMMENT "死亡总数",deaths_max BIGINT MAX DEFAULT "0" COMMENT "死亡最大值"
)
DISTRIBUTED BY HASH(state) BUCKETS 8;--明细表
DROP TABLE IF EXISTS covid;
CREATE TABLE IF NOT EXISTS covid (county VARCHAR(255) COMMENT "县",date DATE COMMENT "日期",state VARCHAR(255) COMMENT "州",fips VARCHAR(255) COMMENT "县编码code",cases INT(10) COMMENT "累计确诊病例",deaths INT(10) COMMENT "累计死亡病例"
)
DUPLICATE KEY(county)
DISTRIBUTED BY HASH(county) BUCKETS 8;
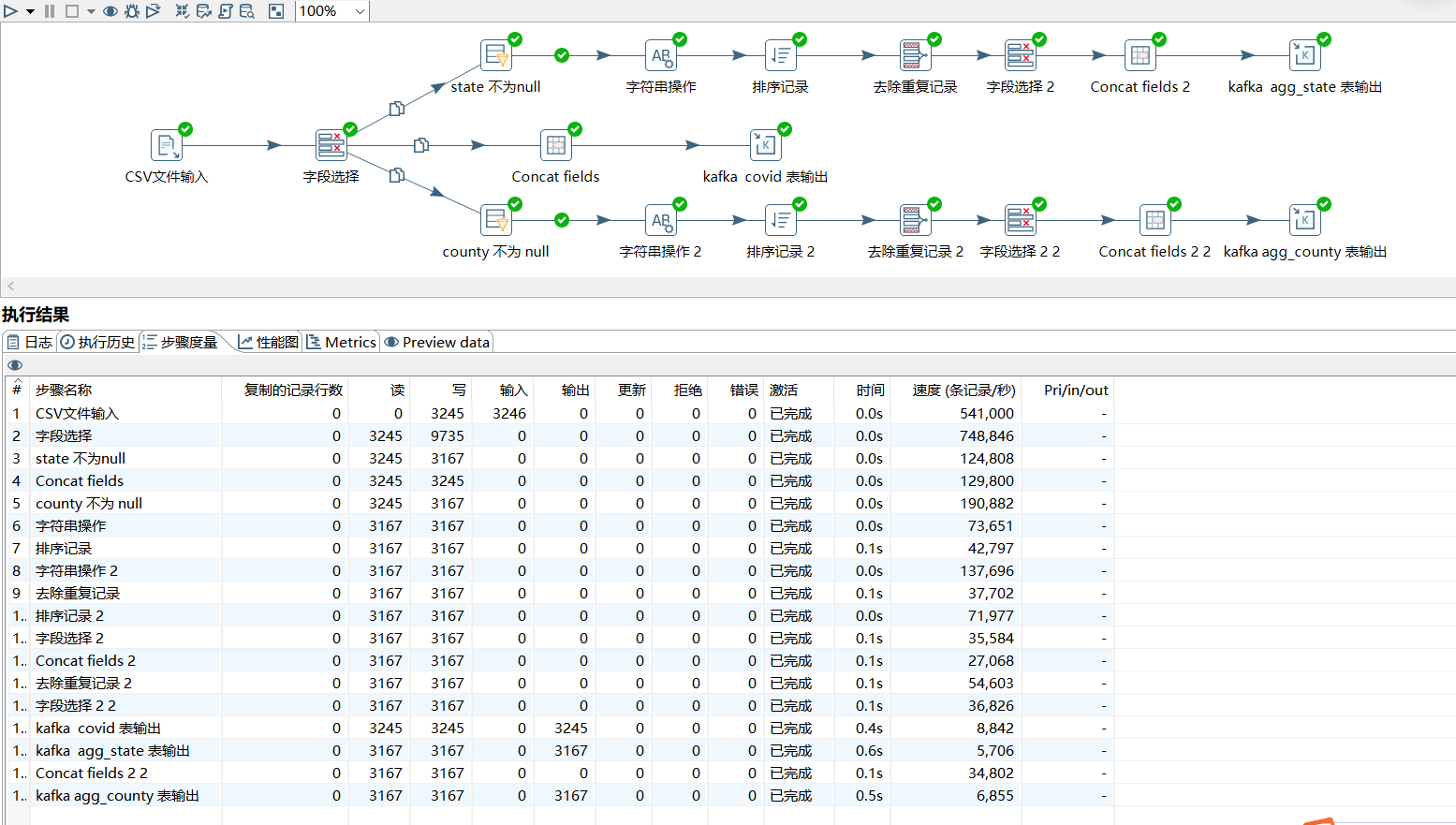
二、 ETL 处理
2.1 ETL 整体设计:
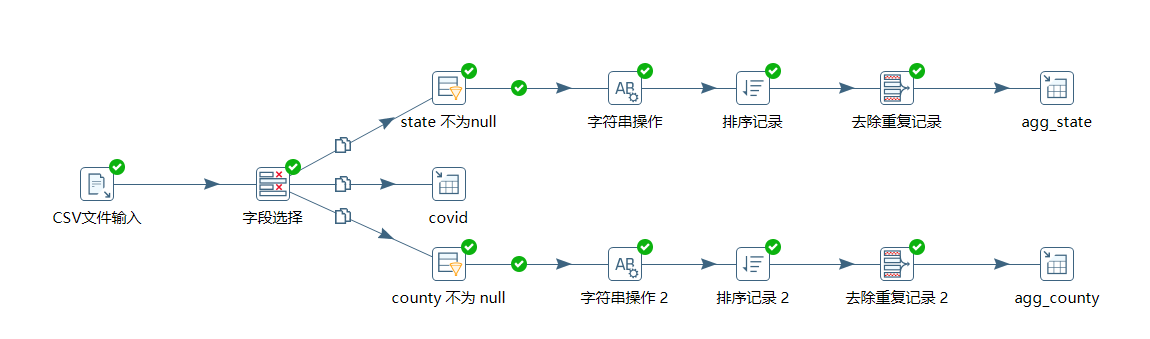
2.2 详细处理过程
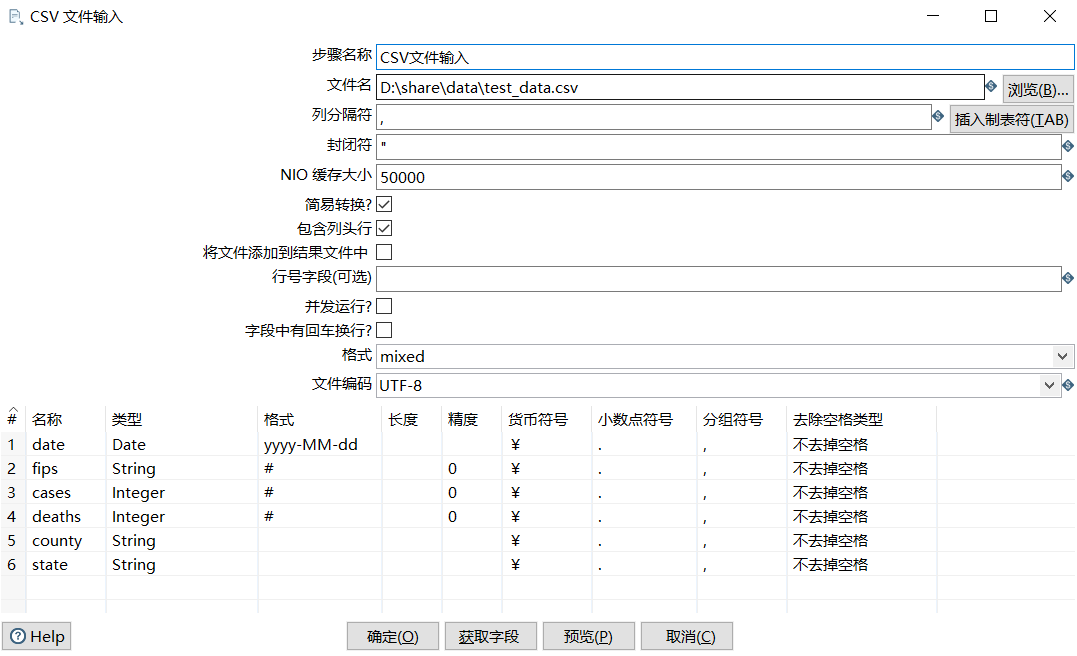
- CSV文件输入
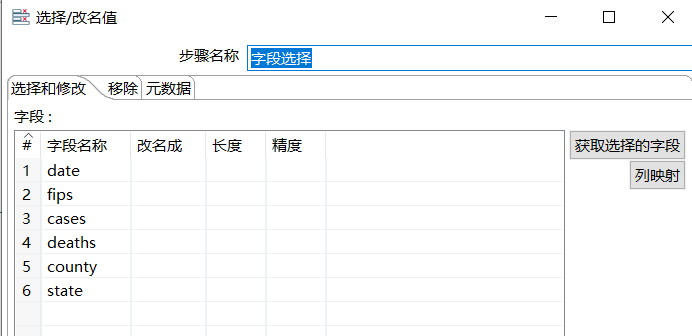
- 字段选择
- 字符串不为空,
state和county同理:
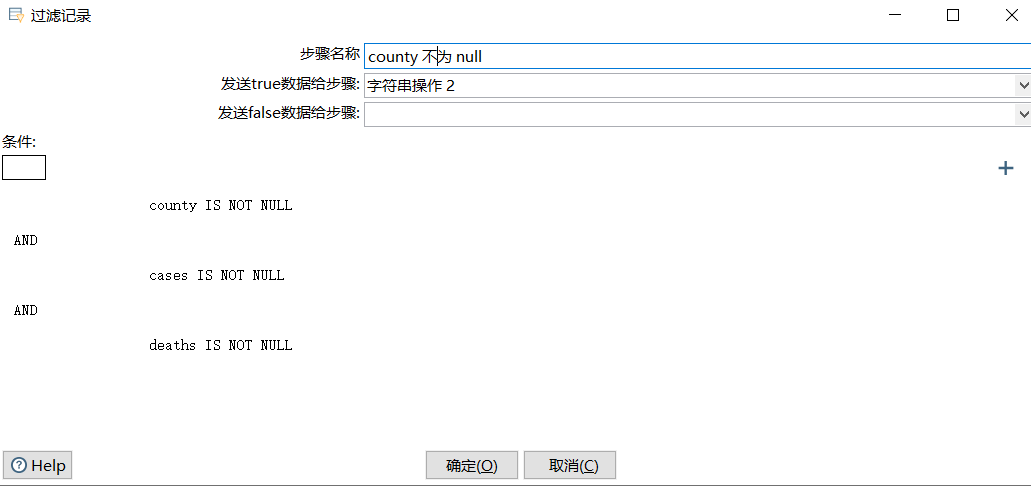
- 字符串操作

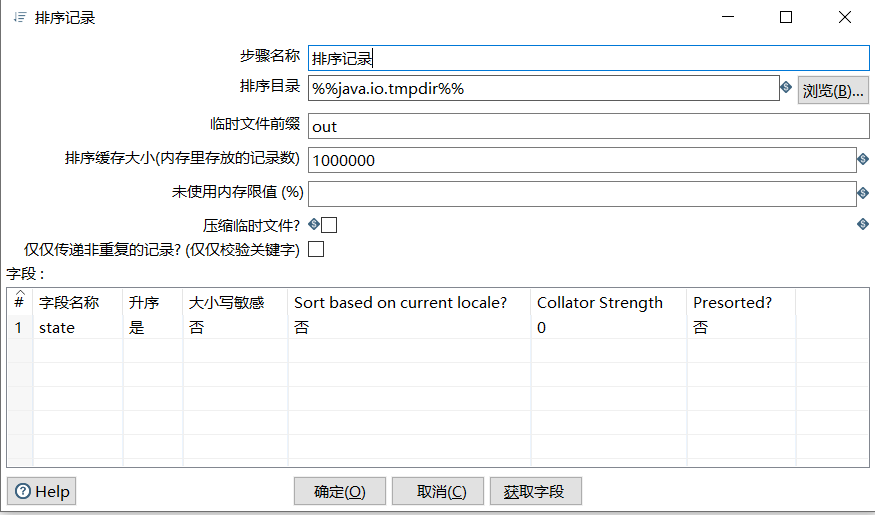
- 排序记录
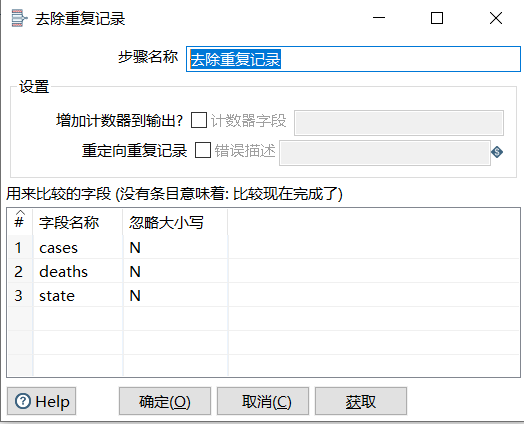
- 去除重复记录
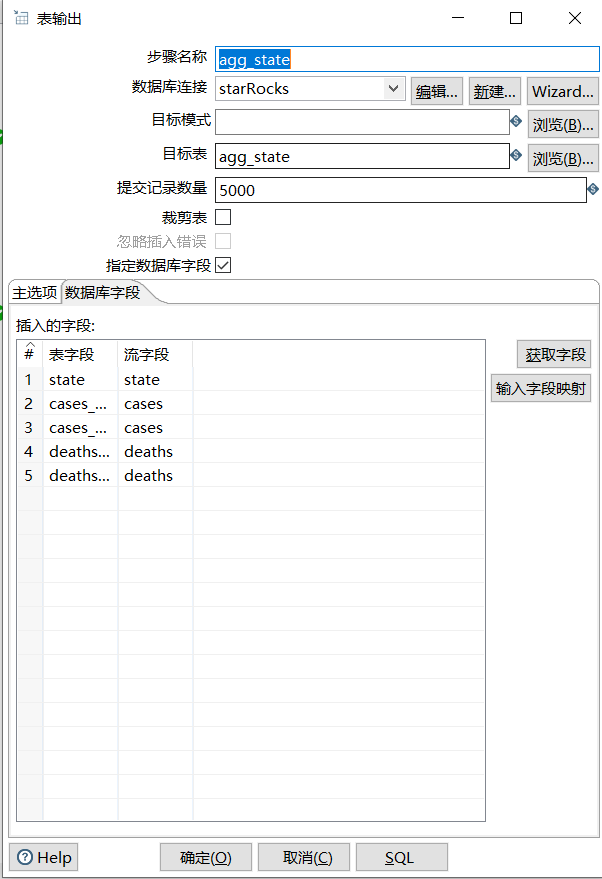
- 表输出:
2.3 ETL 处理耗时:
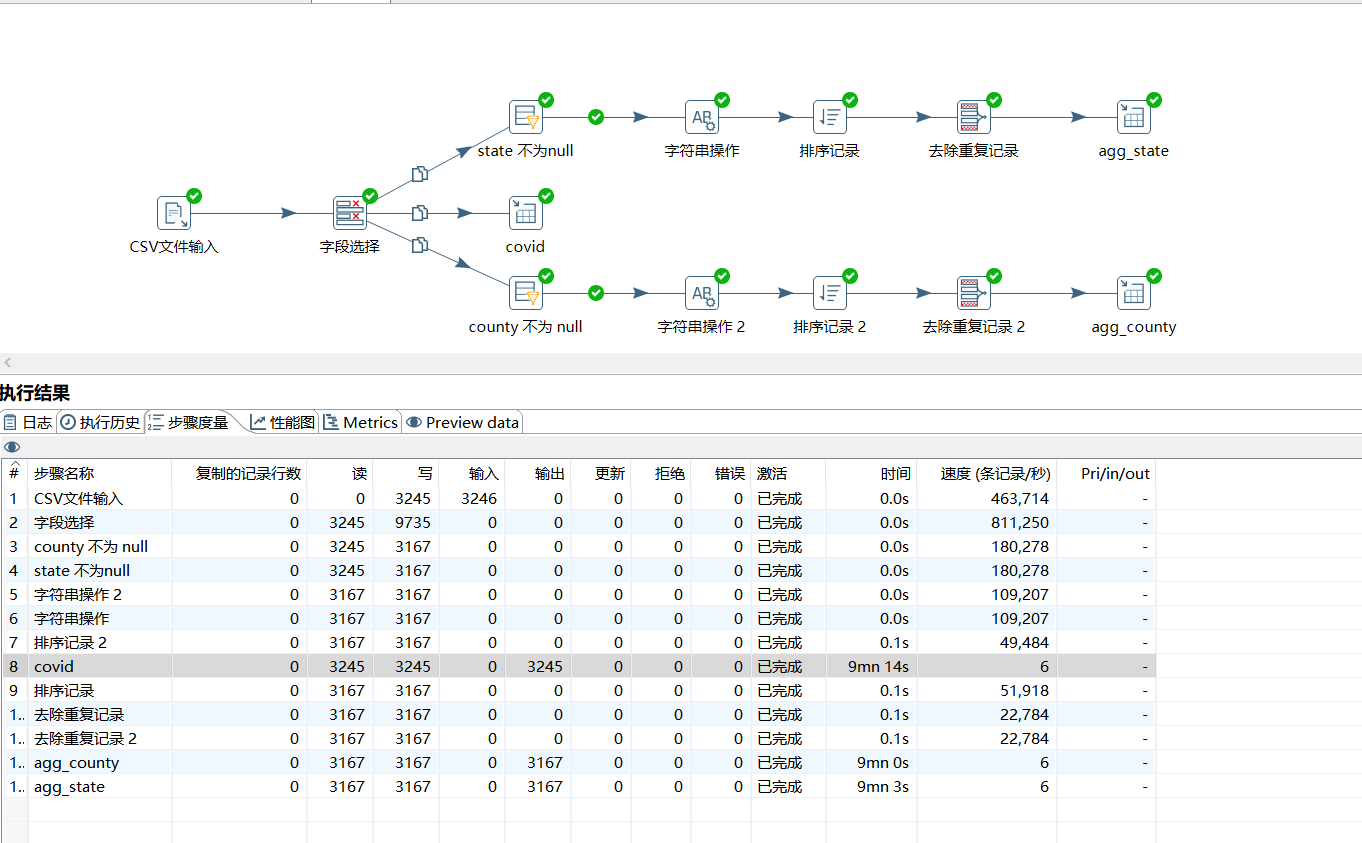
可以明显看出写入速度非常慢 !
2.4 写入速度非常慢怎么办
StarRocks 不建议小批量的 INSERT 写入数据,对于持续写入可使用 Kafka 或 MySQL 中转,下面以 kafka 为示例:
官方示例:https://docs.starrocks.io/zh-cn/latest/loading/RoutineLoad
先清空数据
truncate table covid;
truncate table agg_state;
truncate table agg_county;
创建 kafka 持续导入任务:
-- covid 数据接入
CREATE ROUTINE LOAD covid_load ON covid
COLUMNS TERMINATED BY ",",
COLUMNS (date,fips,cases,deaths,county,state)
PROPERTIES
("desired_concurrent_number" = "5"
)
FROM KAFKA
("kafka_broker_list" = "192.168.40.1:9092,192.168.40.2:9092,192.168.40.3:9092","kafka_topic" = "starrocks_covid","kafka_partitions" = "0,1,2","property.kafka_default_offsets" = "OFFSET_END"
);-- agg_state 数据接入
CREATE ROUTINE LOAD agg_state_load ON agg_state
COLUMNS TERMINATED BY ",",
COLUMNS (state,deaths_sum,deaths_max,cases_sum,cases_max)
PROPERTIES
("desired_concurrent_number" = "5"
)
FROM KAFKA
("kafka_broker_list" = "192.168.40.1:9092,192.168.40.2:9092,192.168.40.3:9092","kafka_topic" = "starrocks_agg_state","kafka_partitions" = "0,1,2","property.kafka_default_offsets" = "OFFSET_END"
);-- agg_county数据接入
CREATE ROUTINE LOAD agg_county_load ON agg_county
COLUMNS TERMINATED BY ",",
COLUMNS (county,deaths_sum,deaths_max,cases_sum,cases_max)
PROPERTIES
("desired_concurrent_number" = "5"
)
FROM KAFKA
("kafka_broker_list" = "192.168.40.1:9092,192.168.40.2:9092,192.168.40.3:9092","kafka_topic" = "starrocks_agg_county","kafka_partitions" = "0,1,2","property.kafka_default_offsets" = "OFFSET_END"
);
ETL 修改:
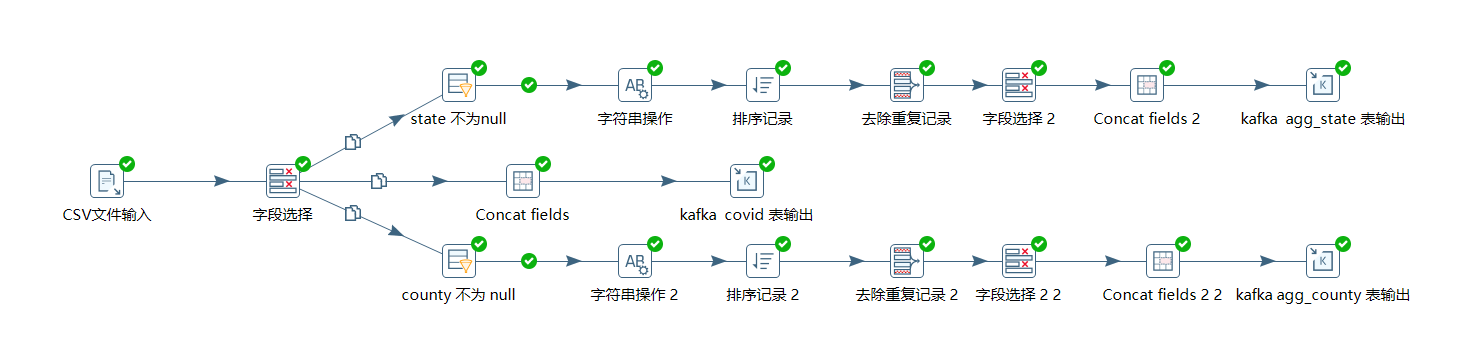
主要将表输出换成了 Concat fields 和 kafka producer:
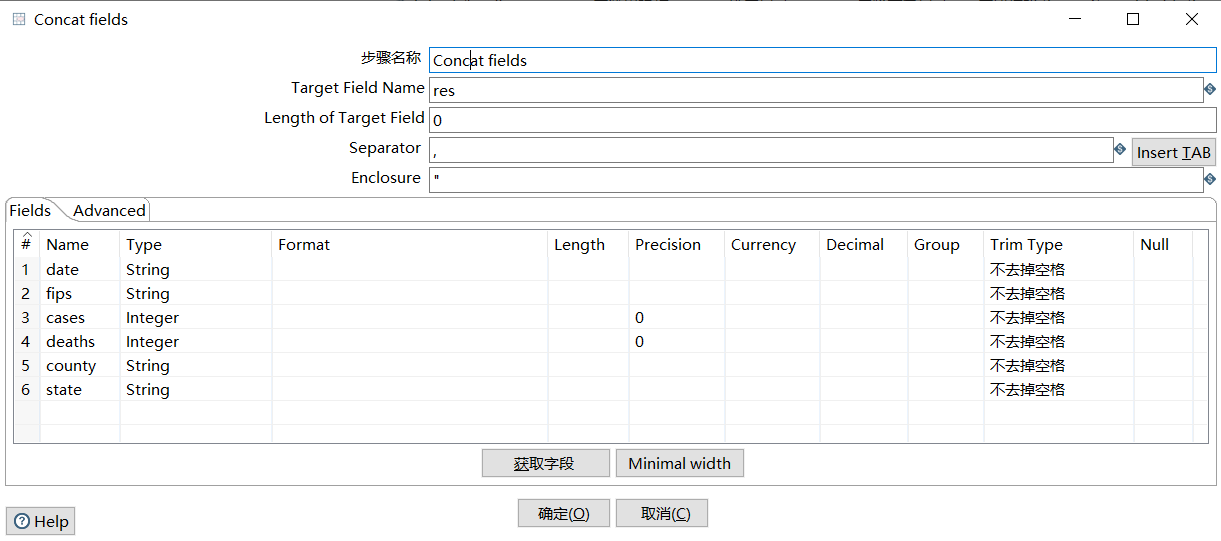
Concat fields:
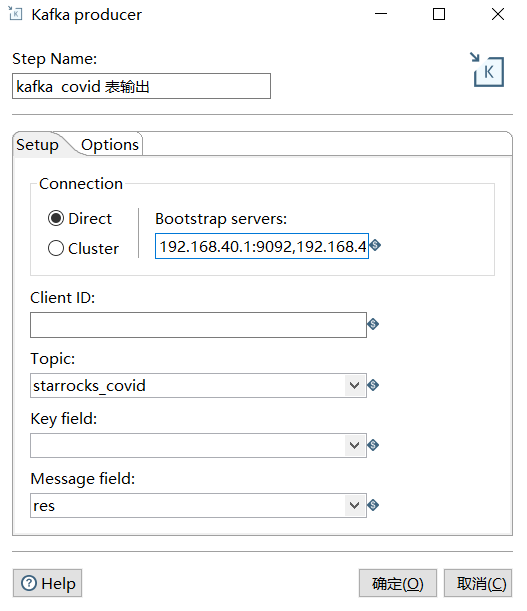
kafka producer:
再次运行查看 ETL 耗时:
速度快了近 1000 倍。
三、FineReport 可视化设计
- 新建决策报表:
- 拖入图表
-
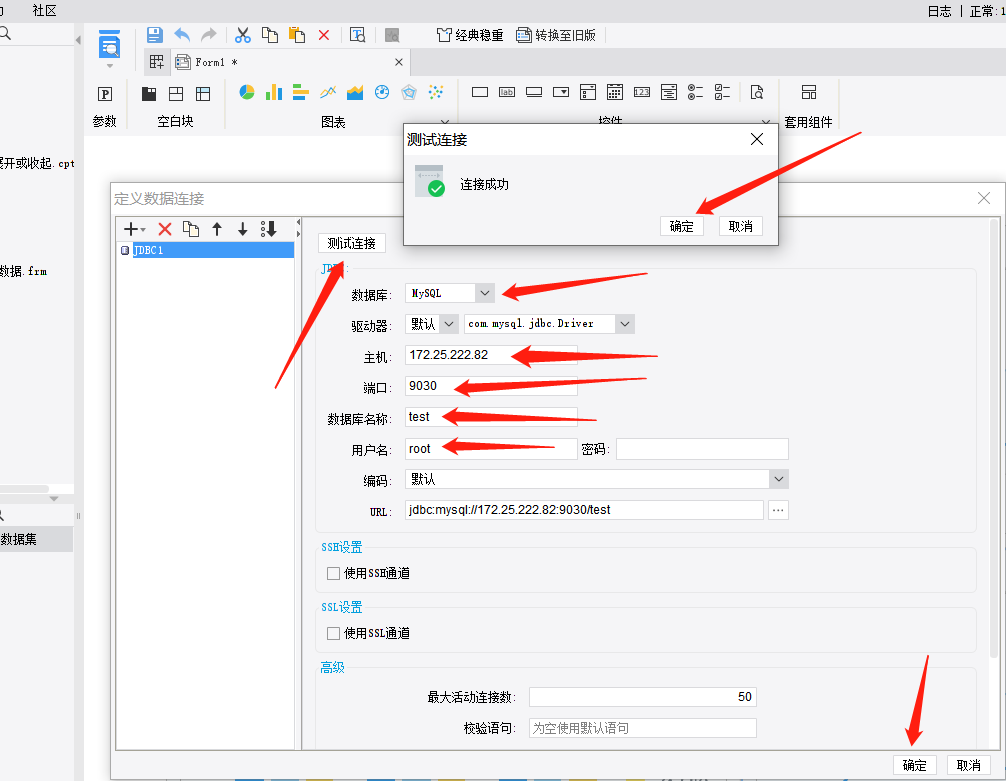
定义数据库连接
-
定义数据库查询
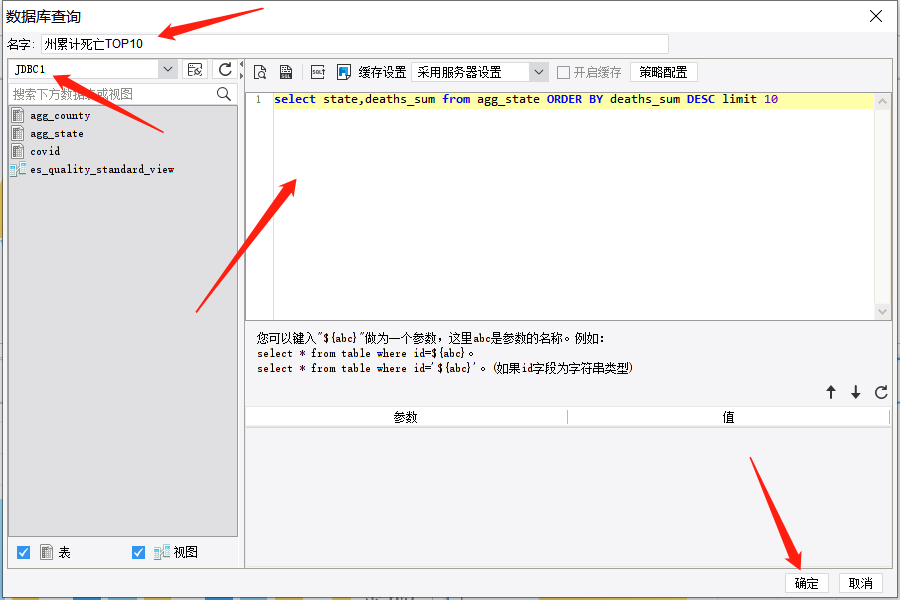
select state,deaths_sum from agg_state ORDER BY deaths_sum DESC limit 10同理添加:
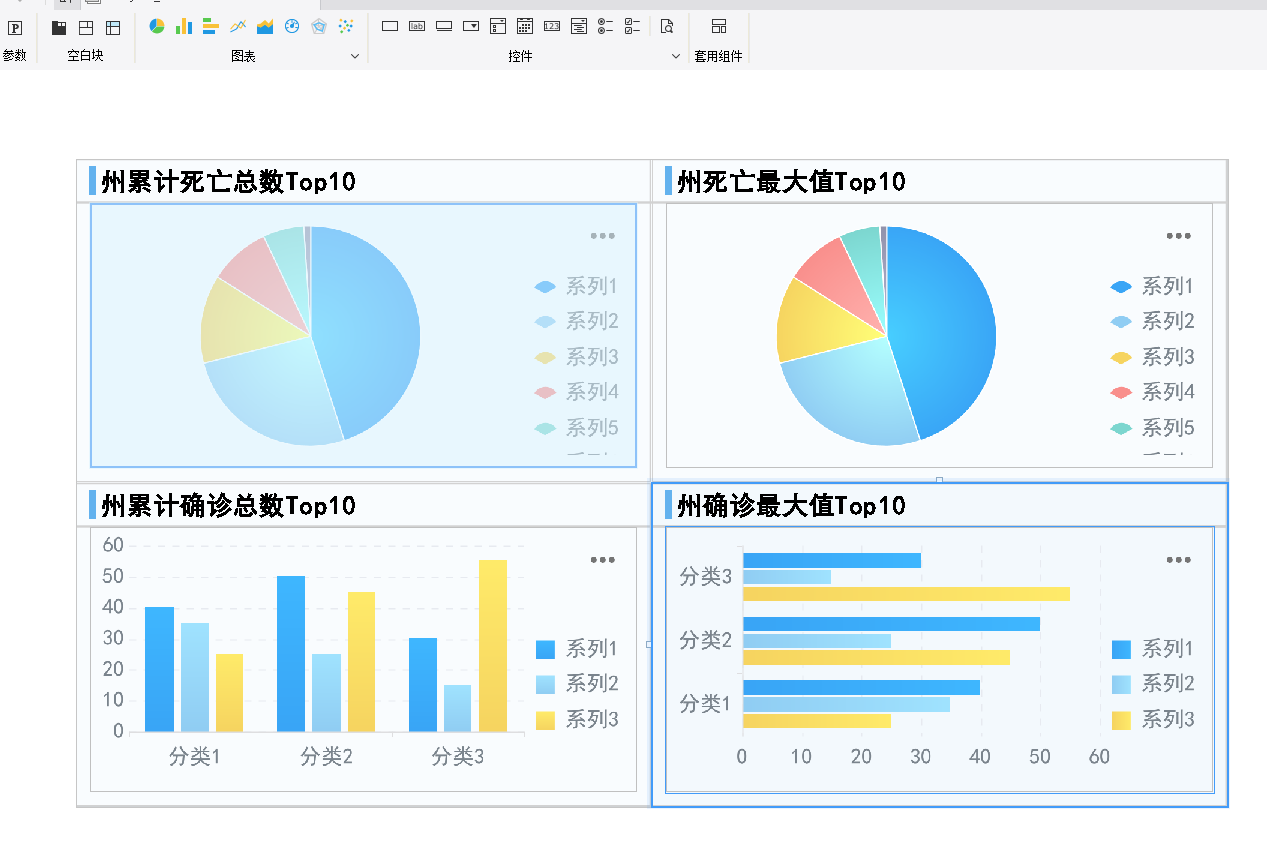
州累计确诊Top10:
select state,cases_sum from agg_state ORDER BY cases_sum DESC limit 10各个州确诊最大值Top10:
select state,cases_max from agg_state ORDER BY cases_max DESC limit 10各个州死亡最大值 Top10:
select state,deaths_max from agg_state ORDER BY deaths_max DESC limit 10 -
州累计死亡总数Top10 绑定数据
-
州累计确诊总数 Top10 绑定数据
-
同步设置另两个图表
-
生成预览链接:
-
展示效果:
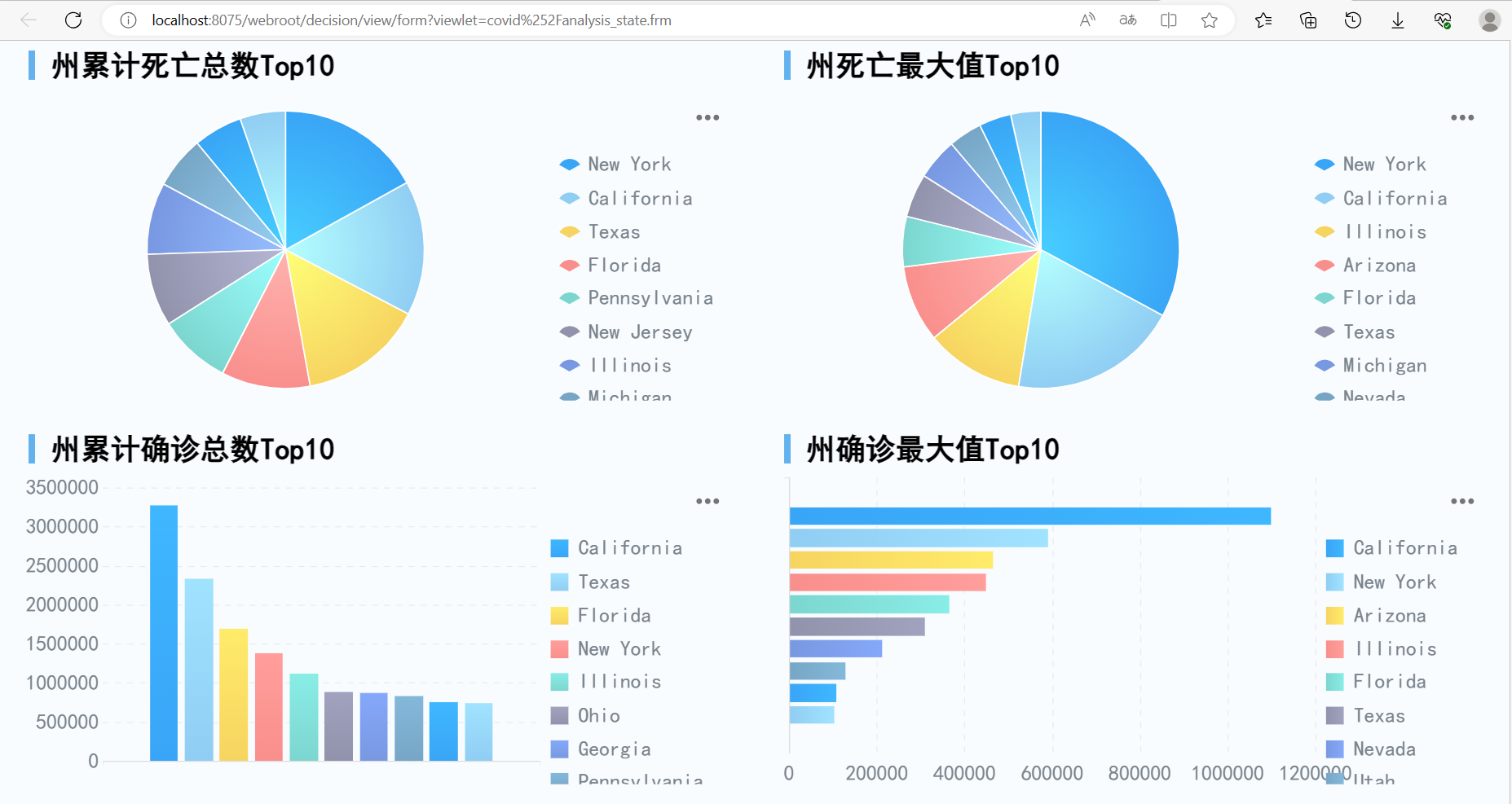
四、 需求修改应对方式
假设现在需要统计每个州的平均死亡数,怎么高效率低成本修改?
答案:可以基于明细表,使用异步物化视图,实现预聚合的效果。
官方说明:https://docs.starrocks.io/zh-cn/latest/using_starrocks/Materialized_view
CREATE MATERIALIZED VIEW agg_state_view
DISTRIBUTED BY HASH(state) BUCKETS 8 AS
SELECT state,sum(deaths) AS deaths_max, COUNT(county) AS num FROM covid GROUP BY state
注意:在 StarRocks 中聚合模型和物化视图都不支持 avg 。
FineReport 中查询时:
select state, deaths_max/num from agg_state_view
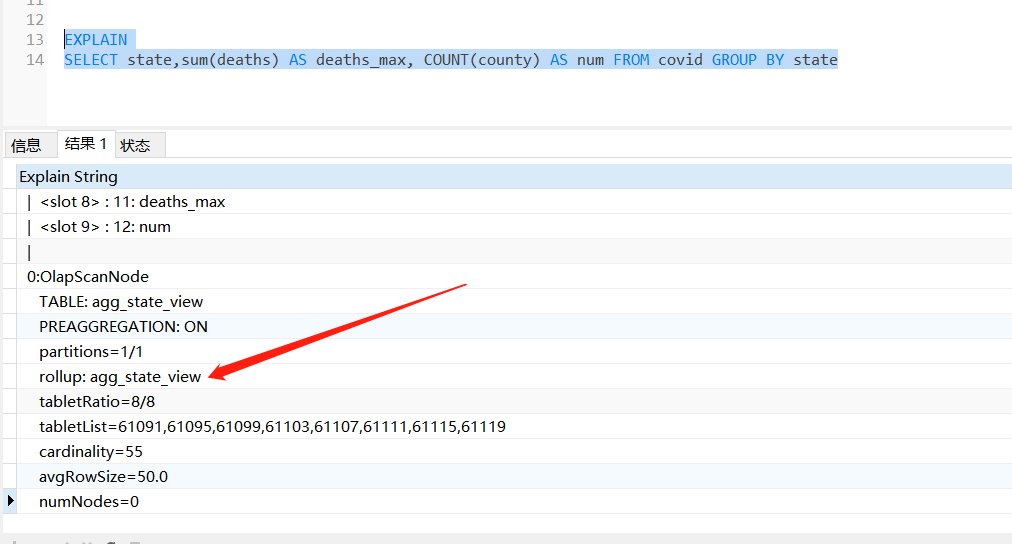
思考:当有了物化视图,再对明细表做相同聚合操作,还会扫描全表吗?
答案:不会了
例如:
EXPLAIN
SELECT state,sum(deaths) AS deaths_max, COUNT(county) AS num FROM covid GROUP BY state
下面可以看到自动转到视图上了: