1. WaterMark源码分析
- watermark源头
- watermark下游
-
代码
public class FlinkWaterMark {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.getConfig().setAutoWatermarkInterval(1000);// 获取Socket数据源DataStreamSource<String> socketSource = env.socketTextStream("localhost", 8888);// 将数据转换成UserEvent2SingleOutputStreamOperator<UserEvent2> mapStream = socketSource.map(s -> {String[] split = s.split(",");UserEvent2 userEvent2 = UserEvent2.builder().uId(split[0]).name(split[1]).event(split[2]).time(split[3]).build();return userEvent2;}).returns(UserEvent2.class).disableChaining(); // 这里做算子链的解绑// 构造Watermark策略,使用允许时间乱序策略,并设置允许时间乱序时间最大值为2000msWatermarkStrategy<UserEvent2> watermark = WatermarkStrategy.<UserEvent2>forBoundedOutOfOrderness(Duration.ofMillis(2000)) // 设置乱序时间.withTimestampAssigner(new SerializableTimestampAssigner<UserEvent2>() {@Overridepublic long extractTimestamp(UserEvent2 userEvent2, long l) {/** 抽取事件时间逻辑, 根据数据中的实际情况来看 **/String time = userEvent2.getTime();// 将事件中携带的时间转换成毫秒值DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS");LocalDateTime parse = LocalDateTime.parse(time, dateTimeFormatter);Instant instant = parse.atZone(ZoneId.systemDefault()).toInstant();long timestamp = instant.toEpochMilli();return timestamp;}});// 将构造完成的watermark分配给数据流SingleOutputStreamOperator<UserEvent2> mapStream2 = mapStream.assignTimestampsAndWatermarks(watermark);// 通过process算子打印watermark信息mapStream2.process(new ProcessFunction<UserEvent2, UserEvent2>() {@Overridepublic void processElement(UserEvent2 value, ProcessFunction<UserEvent2, UserEvent2>.Context ctx, Collector<UserEvent2> out) throws Exception {// 获取水位线long l = ctx.timerService().currentWatermark();System.out.println("当前watermark: " + l);// 直接输出数据out.collect(value);}}).startNewChain().print(); // 这里要注意,一定要新开一个算子链,如果watermark和process算子绑定到一个算子链中就不会形成上下游的关系,后续的一些实验也就无法验证env.execute();} }下面将会围绕上面这段业务代码对
watermark源码进行解析,在进行解析前说一个小技巧:当对某个框架进行源码解析时,最好是通过Debug的方式进行,就以Flink为例,如果直接通过点击查看源码是很难进行追溯的,代码执行过程中所用到的很多类通过点击的方式是查看不到的.
1.1 watermark源头源码分析
-
通过
forBoundedOutOfOrderness(Duration.ofMillis(2000))方法点进源码,再通过源码进入到BoundedOutOfOrdernessWatermarks类中,对onEvent方法和onPeriodicEmit方法中的方法体中的内容打上断点@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput output) {maxTimestamp = Math.max(maxTimestamp, eventTimestamp); // 断点位置}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1)); // 断点位置}-
onEvent
onEvent方法其实就是筛选最大时间的通过maxTimestamp和eventTimestamp进行比较来判断是否根据事件时间更新maxTimestamp. -
onPeriodicEmit
onPeriodicEmit方法根据名称就可以看出是周期性发射,而发射的内容就是watermark,通过方法体可以看到每次发射的watermark都是maxTimestamp - outOfOrdernessMillis - 1,maxTimestamp就是上面onEvent方法获取的最大时间戳,outOfOrdernessMillis就是在调用forBoundedOutOfOrderness(Duration.ofMillis(2000))这个方法时所给的2000的时间容错,1则是恒定减1.
-
-
通过
Debug执行代码,在Debugger中是可以看到代码执行过程所调用的源码依赖顺序,如下图

通过上面的图片可以很清晰的看到代码执行过程类的调用顺序,这里不要关注每一个类的源码内容,可以直接点击onProcessingTime这个方法,在图片中就是第二行中的方法,点击这个方法后就可以定位到TimestampsAndWatermarksOperator这个类. -
TimestampsAndWatermarksOperator关注点在
TimestampsAndWatermarksOperator这个类中只需要关注三个方法即可open、processElement、onProcessingTimepublic class TimestampsAndWatermarksOperator<T> extends AbstractStreamOperator<T>implements OneInputStreamOperator<T, T>, ProcessingTimeCallback {// ...// 生命周期方法,初始化各种信息@Overridepublic void open() throws Exception {super.open();timestampAssigner = watermarkStrategy.createTimestampAssigner(this::getMetricGroup);watermarkGenerator =emitProgressiveWatermarks? watermarkStrategy.createWatermarkGenerator(this::getMetricGroup): new NoWatermarksGenerator<>();wmOutput = new WatermarkEmitter(output);// 根据配置获取watermark发送间隔,默认200mswatermarkInterval = getExecutionConfig().getAutoWatermarkInterval(); if (watermarkInterval > 0 && emitProgressiveWatermarks) {final long now = getProcessingTimeService().getCurrentProcessingTime();// 开启定时(200ms),执行onProcessingTime(long timestamp)方法getProcessingTimeService().registerTimer(now + watermarkInterval, this);}}// 由数据驱动的方法,只有数据进来时才执行这个方法@Overridepublic void processElement(final StreamRecord<T> element) throws Exception {final T event = element.getValue();final long previousTimestamp =element.hasTimestamp() ? element.getTimestamp() : Long.MIN_VALUE;final long newTimestamp = timestampAssigner.extractTimestamp(event, previousTimestamp);element.setTimestamp(newTimestamp);// 发送数据output.collect(element);// 根据BoundedOutOfOrdernessWatermarks类中的onEvent方法修改maxTimestampwatermarkGenerator.onEvent(event, newTimestamp, wmOutput);}// watermark定时触发器方法@Overridepublic void onProcessingTime(long timestamp) throws Exception {// 执行BoundedOutOfOrdernessWatermarks类中的onPeriodicEmit方法,发射watermarkwatermarkGenerator.onPeriodicEmit(wmOutput);final long now = getProcessingTimeService().getCurrentProcessingTime();// 重新定时,并在定时时间到达时再次触发onProcessingTime方法getProcessingTimeService().registerTimer(now + watermarkInterval, this);}// ... }-
open
open方法就是一个线程的生命周期方法,在这个方法里面会加载各种初始化信息,其中就包含了多久发送一次watermark的信息,就是watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();这行代码,watermark的默认发送周期是200ms,这个是可以在代码中进行配置的如env.getConfig().setAutoWatermarkInterval(1000);这样就将默认的200ms修改成了1000ms,在获取到watermark发送周期后,就会启动定时器getProcessingTimeService().registerTimer(now + watermarkInterval, this)这里就第一次执行了定时器,其实就是执行的onProcessingTime方法. -
processElement
processElement方法只有在有数据流入的时候才会执行,这个方法中只需要关注两行代码即可output.collect(element);和watermarkGenerator.onEvent(event, newTimestamp, wmOutput);在源码中可以看到,首先执行的就是output.collect(element);也就是发送数据,然后才执行的watermarkGenerator.onEvent(event, newTimestamp, wmOutput);也就是根据事件时间确定watermark,其实由这两行代码就可以看出Flink的机制其实就是数据优先,由数据驱动时间 -
onProcessingTime
onProcessingTime方法就是watermark的定时触发器,代码中的内容也极其简单,首先就是调用BoundedOutOfOrdernessWatermarks类中的onPeriodicEmit方法,将watermark发射,然后再次通过getProcessingTimeService().registerTimer(now + watermarkInterval, this);执行定时器,可以看做类似于循环或者是递归,不断的启动定时器不断地发射watermark,这个跟是否有数据进来没有关系,这样watermark就会根据设定好的周期不断地进行发送,看到这里就说一点在watermark的源头数据本身和watermark就是异步执行的互不影响.
-
-
将源码内容拷贝到项目中,通过添加打印控制台的代码查看执行过程
只看源码其实很难弄清楚过程到底是怎么执行的,到底是谁先谁后,这里就可以通过将源码拷贝到项目中并且根据自己的需求添加对应的代码的这种小技巧来搞清楚代码的具体执行逻辑,方法很简单首先在
IDEA中查看对应的源码类,然后拷贝该类的全路径,在项目下新建一个一模一样的类即可,这样代码再执行的过程中就会优先调用项目中相同的类,这里以BoundedOutOfOrdernessWatermarks和TimestampsAndWatermarksOperator为例.-
BoundedOutOfOrdernessWatermarks
右键BoundedOutOfOrdernessWatermarks --> Copy Reference --> 在项目的Java目录下右键 --> 新建Java Class --> 将全路径粘贴 --> 点击OK --> 再将源码中的代码全部粘贴到新建的类中即可 --> 根据自己需要添加代码代码
package org.apache.flink.api.common.eventtime;import org.apache.flink.annotation.Public;import java.time.Duration;import static org.apache.flink.util.Preconditions.checkArgument; import static org.apache.flink.util.Preconditions.checkNotNull; public class BoundedOutOfOrdernessWatermarks<T> implements WatermarkGenerator<T> {// ...@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput output) {maxTimestamp = Math.max(maxTimestamp, eventTimestamp);// 在这里添加打印信息System.out.println(maxTimestamp);}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {// 在这里添加打印信息System.out.printf("周期性输出watermark: %d \n", maxTimestamp - outOfOrdernessMillis - 1);output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));} }代码中部分内容省略.
-
TimestampsAndWatermarksOperator
步骤同上,这里省略代码
package org.apache.flink.streaming.runtime.operators; // ... public class TimestampsAndWatermarksOperator<T> extends AbstractStreamOperator<T>implements OneInputStreamOperator<T, T>, ProcessingTimeCallback {// ...@Overridepublic void open() throws Exception {super.open();timestampAssigner = watermarkStrategy.createTimestampAssigner(this::getMetricGroup);watermarkGenerator =emitProgressiveWatermarks? watermarkStrategy.createWatermarkGenerator(this::getMetricGroup): new NoWatermarksGenerator<>();wmOutput = new WatermarkEmitter(output);watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();if (watermarkInterval > 0 && emitProgressiveWatermarks) {final long now = getProcessingTimeService().getCurrentProcessingTime();// 添加打印信息System.out.println("第一次执行定时器");getProcessingTimeService().registerTimer(now + watermarkInterval, this);}}@Overridepublic void processElement(final StreamRecord<T> element) throws Exception {final T event = element.getValue();final long previousTimestamp =element.hasTimestamp() ? element.getTimestamp() : Long.MIN_VALUE;final long newTimestamp = timestampAssigner.extractTimestamp(event, previousTimestamp);element.setTimestamp(newTimestamp);// 添加打印信息System.out.printf("准备发送数据: %s \n", element);output.collect(element);// 添加打印信息System.out.print("根据onEvent方法修改了maxTimestamp: ");watermarkGenerator.onEvent(event, newTimestamp, wmOutput);}@Overridepublic void onProcessingTime(long timestamp) throws Exception {// 添加打印信息System.out.println("watermark定时器触发,开始调用onPeriodicEmit方法");watermarkGenerator.onPeriodicEmit(wmOutput);final long now = getProcessingTimeService().getCurrentProcessingTime();getProcessingTimeService().registerTimer(now + watermarkInterval, this);}// ... }
-
-
执行代码查看结果
-
无数据进入
[2023-10-09 09:19:57,219]-[INFO] -org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction -2015 -org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction.run(SocketTextStreamFunction.java:103).run(103) | Connecting to server socket localhost:8888 第一次启动定时器 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808 watermark定时器触发,开始调用onPeriodicEmit方法通过结果可以看出
open方法只有开始的时执行了一次,后面就是一直在执行onProcessingTime方法,不断的启动定时器,然后发送watermark,而且也可以看出就算没有数据到达watermark也是根据定时周期不断地发送,数据能影响的只是watermark的值,但是不会影响watermark的发送. -
第一条数据到达
watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808 准备发送数据: Record @ 1696648332245 : UserEvent2(uId=101, name=Tom, event=查看商品, time=2023-10-07 11:12:12.245) 根据onEvent方法修改了maxTimestamp: 1696648332245 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648330244 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648330244 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648330244当第一条数据到达后可以看到,优先执行的数据处理的方法,当数据处理的方法执行完成后,才会变更对应的
maxTimestamp,然后再通过定时触发器发射watermark.
-
1.2 watermark下游源码分析
-
在
process算子中打上断点mapStream2.process(new ProcessFunction<UserEvent2, UserEvent2>() {@Overridepublic void processElement(UserEvent2 value, ProcessFunction<UserEvent2, UserEvent2>.Context ctx, Collector<UserEvent2> out) throws Exception {out.collect(value); // 断点位置}}).print(); -
通过
Debug运行,以同样的方式找到代码执行过程用到的调用栈,如下图
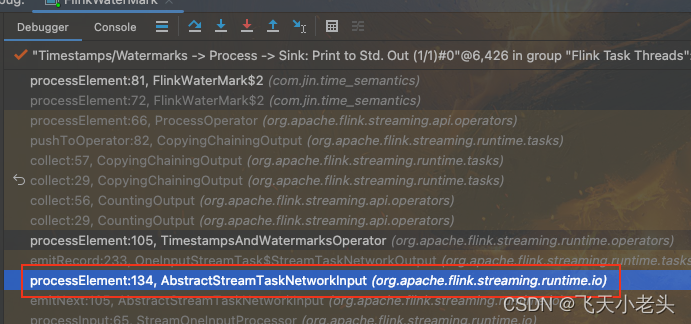
找到AbstractStreamTaskNetworkInput类的processElement方法 -
processElement方法体分析源码内容如下:
public abstract class AbstractStreamTaskNetworkInput<T, R extends RecordDeserializer<DeserializationDelegate<StreamElement>>>implements StreamTaskInput<T> {// ..private void processElement(StreamElement recordOrMark, DataOutput<T> output) throws Exception {if (recordOrMark.isRecord()) { // 判断是否是用户数据output.emitRecord(recordOrMark.asRecord());} else if (recordOrMark.isWatermark()) { // 判断是否是水位线数据statusWatermarkValve.inputWatermark(recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);} else if (recordOrMark.isLatencyMarker()) { // 判断是否是标记性水位线数据(用以兼容以前的版本[Flink-1.12以前的版本])output.emitLatencyMarker(recordOrMark.asLatencyMarker());} else if (recordOrMark.isWatermarkStatus()) { // 判断是否是水位线状态数据statusWatermarkValve.inputWatermarkStatus(recordOrMark.asWatermarkStatus(),flattenedChannelIndices.get(lastChannel),output);} else {throw new 8 ("Unknown type of StreamElement");}}// ... }源码省略了部分代码,这里只看需要的主体代码, 在
processElement方法体中可以看出watermark下游的算子当数据到达后首先会判断是什么类型的数据,然后做不同的处理,这里就和watermark的处理方式不同了,这里是指在一个方法体中做了一个if else判断,然后将数据发往不同的分支. -
通过同样的方式,将源码拷贝到项目中,并以打印到控制台的方式修改代码
代码:
public abstract class AbstractStreamTaskNetworkInput<T, R extends RecordDeserializer<DeserializationDelegate<StreamElement>>>implements StreamTaskInput<T> {// ..private void processElement(StreamElement recordOrMark, DataOutput<T> output) throws Exception {if (recordOrMark.isRecord()) {// 打印控制台System.out.println("下游process算子开始发送数据: " + recordOrMark);output.emitRecord(recordOrMark.asRecord());} else if (recordOrMark.isWatermark()) {// 打印控制台System.out.println("下游process算子开始发送watermark: " + recordOrMark);statusWatermarkValve.inputWatermark(recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);} else if (recordOrMark.isLatencyMarker()) {output.emitLatencyMarker(recordOrMark.asLatencyMarker());} else if (recordOrMark.isWatermarkStatus()) {statusWatermarkValve.inputWatermarkStatus(recordOrMark.asWatermarkStatus(),flattenedChannelIndices.get(lastChannel),output);} else {throw new UnsupportedOperationException("Unknown type of StreamElement");}}// ... }结果:
# watermark源头开始打印信息 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: -9223372036854775808# 这里不需要管重复的信息,重复只是因为方法被多次调用,从这里需要关注watermark和数据的先后关系 下游process算子开始发送数据: Record @ (undef) : 102,Jack,添加购物车,2023-10-07 11:12:14.209 下游process算子开始发送数据: Record @ (undef) : UserEvent2(uId=102, name=Jack, event=添加购物车, time=2023-10-07 11:12:14.209) 准备发送数据: Record @ 1696648334209 : UserEvent2(uId=102, name=Jack, event=添加购物车, time=2023-10-07 11:12:14.209) # 这里将源头的watermark修改成了事件中的时间,要注意这里只是修改了maxTimestamp但是还没有更新watermark 根据onEvent方法修改了maxTimestamp: 1696648334209 # 开始发送数据 下游process算子开始发送数据: Record @ 1696648334209 : UserEvent2(uId=102, name=Jack, event=添加购物车, time=2023-10-07 11:12:14.209) # 这里是在procees算子中打印的水位线信息,可以看到是第一条数据到达之前的watermark 当前watermark: -9223372036854775808 # print sink打印的数据 UserEvent2(uId=102, name=Jack, event=添加购物车, time=2023-10-07 11:12:14.209)# 到这里就要注意,这个时候才更新watermark信息,这也就说明,一个问题随着数据达到process算子的watermark其实就是更新之前的watermark,只有当新的数据到达后,才会再次将watermark更新为前一条数据的中的事件时间 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648332208# 下游刚刚获取到新的watermark 下游process算子开始发送watermark: Watermark @ 1696648332208# 在没有新数据到达时,process算子不会被触发,一直打印watermark源头的信息,虽然源头一直发送watermark,但是只有来数据时,process才会触发,而新数据到达时,proces触发拿到的其实就是上一条的watermark watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648332208 watermark定时器触发,开始调用onPeriodicEmit方法 周期性输出watermark: 1696648332208具体信息在注释中写明,这里不做过多阐释.
1.3 watermark整体流程图
流程图的说明也是结合本章中的代码进行说明,如下图:
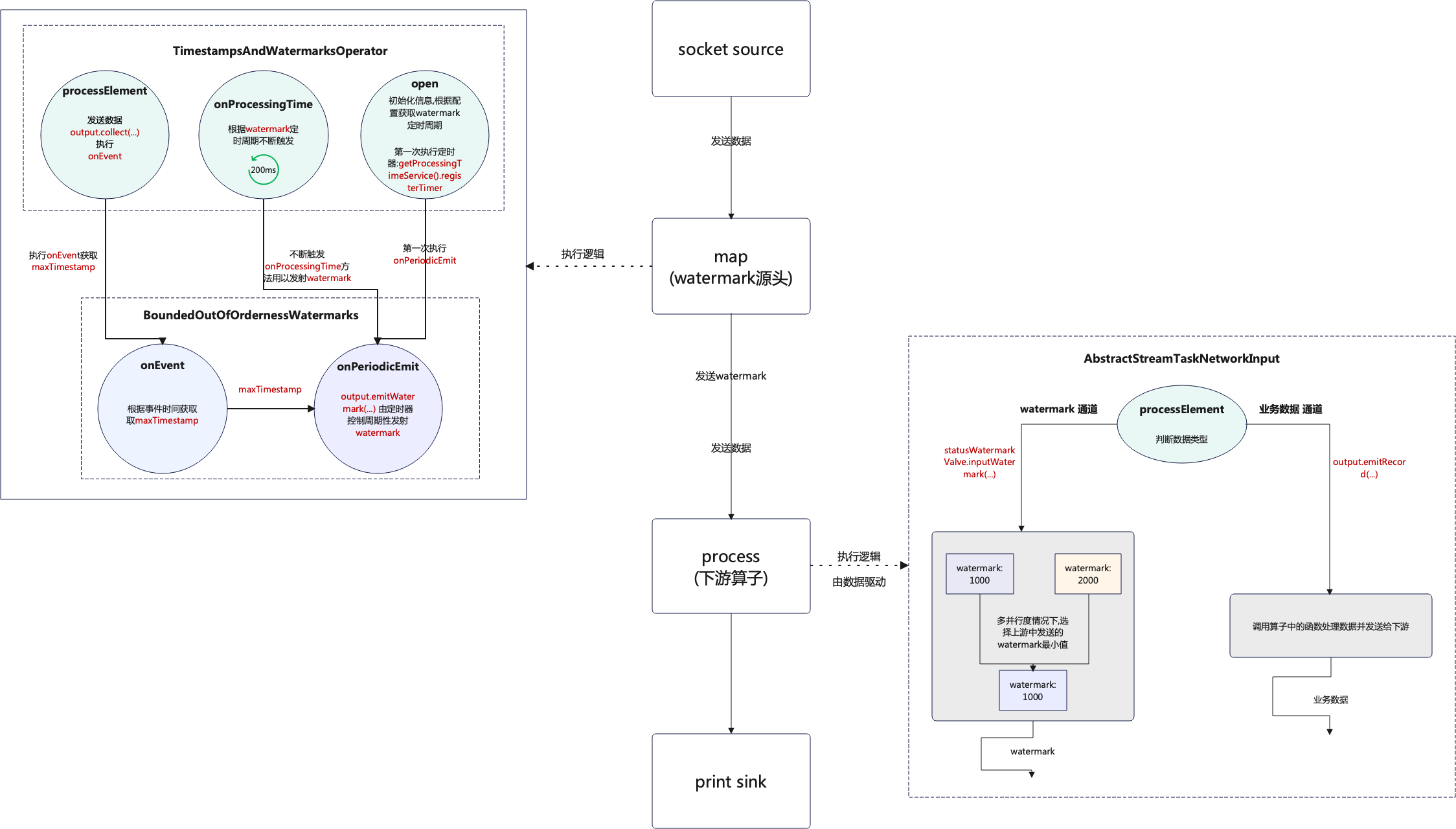
- 当程序刚启动时每个并行度都会执行
open方法且只执行一次,这个时候的watermark是Long.MIN_VALUE + outOfOrdernessMillis + 1;即Long类型的最小值 + 设置的容错时间(forBoundedOutOfOrderness(Duration.ofMillis(2000))) + 1,然后第一次启动定时器,定时器启动的周期则是通过读取配置获得,默认200ms. open执行后启动定时器,也就是onProcessingTime方法,在业务数据到达之前,定时器会根据watermark定时周期不断地自我触发,一直向下游发送watermark.- 当第一条数据到达后首先会执行
processElement方法,先将业务数据发送后再执行onEvent方法. onEvent方法获取maxTimestamp,就是从业务数据中获取事件时间和当前的watermark进行比较,保留最大值.- 获取到
maxTimestamp后,当定时触发器执行时onPeriodicEmit方法就会执行,这个时候就会用到maxTimestamp,再根据maxTimestamp - outOfOrdernessMillis - 1这个逻辑生成新的watermark. watermark生成后就会发往下游算子,这个还是根据watermark触发周期不断地发送,这个和数据是异步发送的,互不影响,只不过在发送watermark前,业务数据已经发往的下游.- 下游的
process算子只有接收到数据后才会执行,在没有数据到达之前是不会触发的,接收到数据后首先会判断数据类型 - 如果数据类型为
业务数据则走output.emitRecord(recordOrMark.asRecord());方法,如果是watermark则走statusWatermarkValve.inputWatermark(...)方法,但是数据必定是先到达到达的,如果output.emitRecord(recordOrMark.asRecord())这一步阻塞了,就不会进行到接收watermark的判断,比如在process算子中通过Thread.sleep(...)就可以到达这个效果. - 下游的
process算子获取到的watermark并不是最新的,比如第一条数据到达后当前获取的watermark还是Long.MIN_VALUE + ...,只有下一条数据到达后才能获取到第一条数据中携带的事件时间. process处理完数据和watermark后会继续发往下游算子,以此类推.