目录
1 更强更通用的建模能力
2 并行计算
3 大规模训练数据
4 多训练技巧的集成
Transformer是一种基于自注意力机制的网络,在最近一两年年可谓是大放异彩,我23年入坑CV的时候,我看到的CV工作似乎还没有一个不用到Transformer里的一些组件的,我不禁好奇,为什么Transformer如此有效呢?
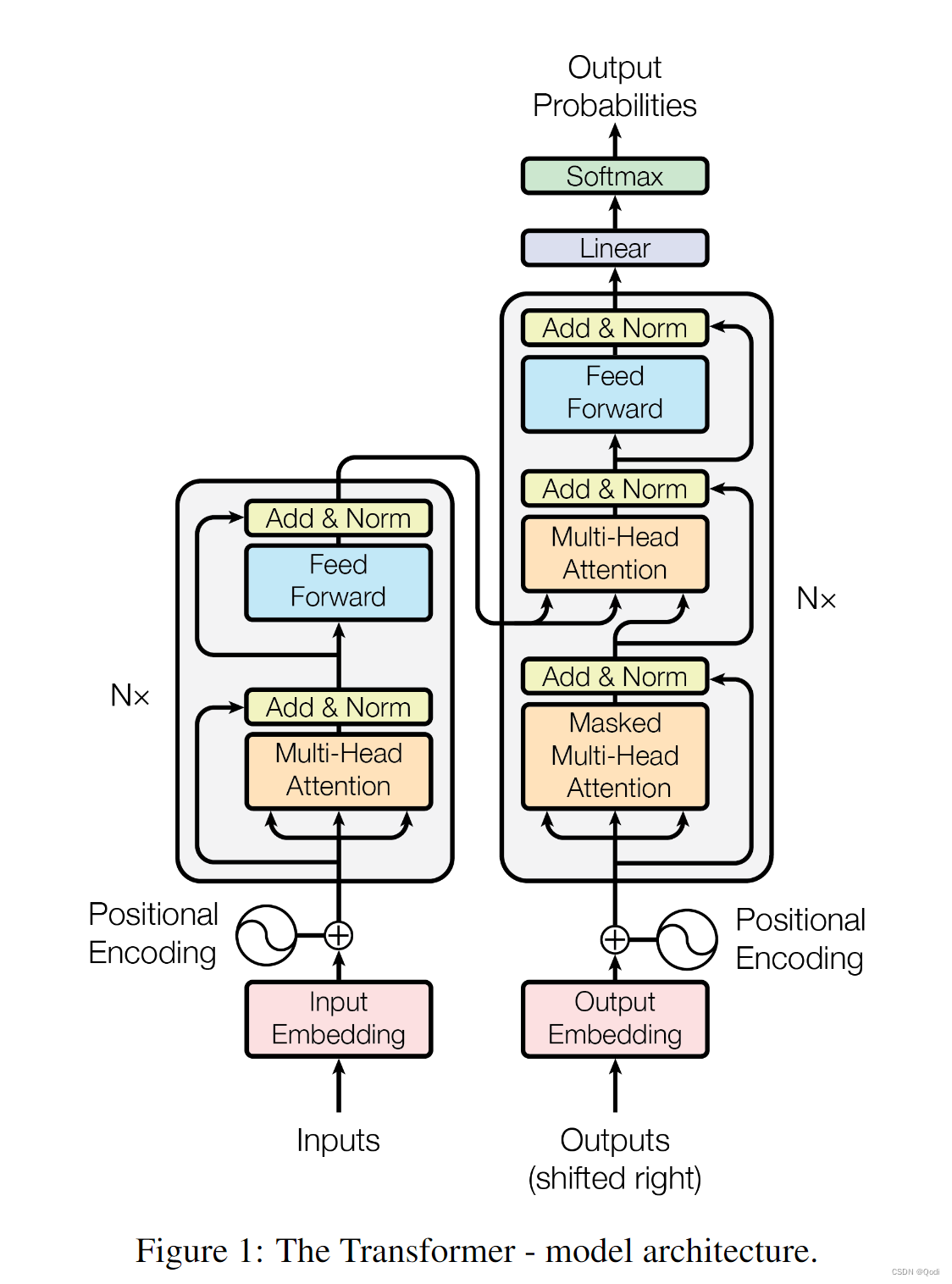
Transformer最早提出是在2017年,发源于那篇著名的《Attention is all you need》大佬的文章标题就是这么接地气哈哈哈哈,不过吧,确实目前看来Attention is all my need,Transformer的提出最初是用于自然语言处理的
不过就在2020年底,CV探索者们将Transformer迁移到了计算机视觉领域,起初只是在分类任务上展露头角(开拓性工作VIT,全程Vision Transformer),后来各种变体工作的探索,使得Transformer在CV的很多下游任务上,如检测,分割等任务上都表现很好
既然有了统一的主干网络,科学家们就逐渐感觉CV和NLP的大一统会一点点成为可能。
不过今天这篇文章重点还是会放在Transformer为什么如此有效
1 更强更通用的建模能力
卷积网络得吭哧吭哧卷半天,有时候卷到后面前面的信息就忘记了,但Transformer咔嚓一下子就可以捕获全局像素信息
Transformer网络中的自注意力机制可以帮助模型自动捕捉输入序列中不同位置的依赖关系(而图片也可以变为序列),这种机制使得不需要卷积或循环的情况下降整个序列作为输入
正是因为具备这样的通用建模能力,Transformer 中的注意力单元可以被应用到各种各样的视觉任务中。
2 并行计算
在Transformer架构中,实现并行计算的关键在于自注意力(Self-Attention)机制。自注意力机制允许模型同时处理输入序列的所有元素(自注意力机制可以最后化为矩阵运算,实现并行运算),而无需像循环神经网络(RNN)那样按顺序迭代。这种特性使得Transformer可以有效地利用现代硬件(如GPU和TPU)进行并行计算。
3 大规模训练数据
之前很多工作都是有监督的,也就是说为了获取数据集我们需要做很多标记工作
因而我们都想着把数据直接丢给网络,让网络自己学习会有多香呢哈哈哈,方便做数据集的拓展
而Transformer之后的Bert等一系列无监督工作,方便了使用大规模数据获得卓越性能
而现在的Transformer通常使用大量的训练数据进行预训练。这使得模型可以学习到丰富的语言知识和语境信息。随着训练数据的增加,模型的性能通常也会得到显著提高
4 多训练技巧的集成
在训练过程中,采用了迭代了许多训练优化技巧,如学习率调整、批归一化,层归一化,梯度裁剪等,提高模型的训练速度和稳定性。