什么是小文件?
小文件指的是文件size比HDFS的block size小很多的文件。Hadoop适合处理少量的大文件,而不是大量的小文件。
hadoop小文件常规的处理方式
1、小文件导致的问题
首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。
其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
2、Hadoop自带的解决方案
对于小文件问题,Hadoop本身也提供了几个解决方案,分别为: Hadoop Archive , Sequence
file 和 CombineFileInputFormat 。
- Hadoop Archive
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多
个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行
透明的访问。 - Sequence file
sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可
以将大批小文件合并成一个大文件。 - CombineFileInputFormat
它是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的
存储位置。
Hadoop Archive
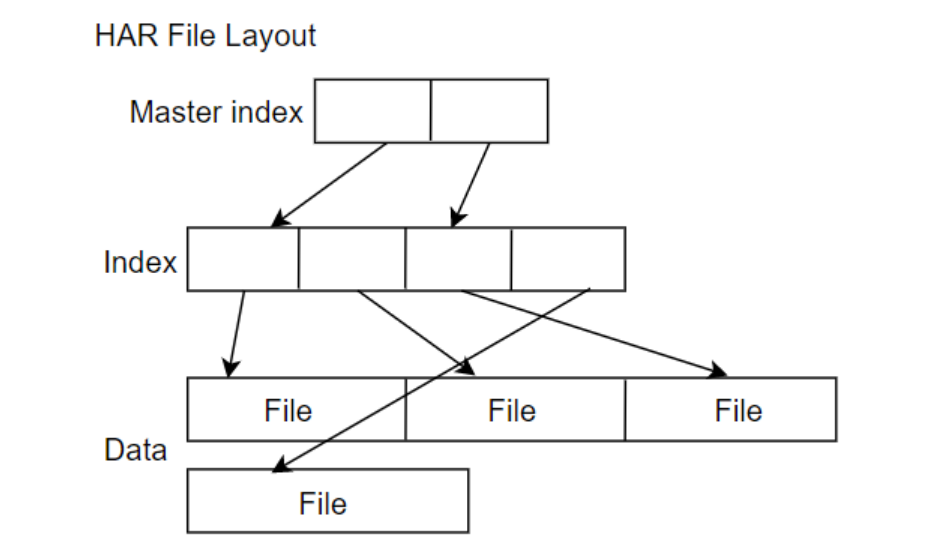
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。对某个目录/foo/bar下的所有小文件存档成/outputdir/ zoo.har:
hadoop archive -archiveName zoo.har -p /foo/bar /outputdir
当然,也可以指定HAR的大小(使用-Dhar.block.size)。
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样,HAR的访问路径可以是以下两种格式:
har://scheme-hostname:port/archivepath/fileinarchive
har:///archivepath/fileinarchive(本节点)
可以这样查看HAR文件存档中的文件:
hadoop dfs -ls har:///user/zoo/foo.har
输出:
har:///user/zoo/foo.har/hadoop/dir1
har:///user/zoo/foo.har/hadoop/dir2
使用HAR时需要两点
第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;
第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
此外,HAR还有一些缺陷:
第一,一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。
第二,要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换
(使用-Dhar.space.replacement.enable=true 和-Dhar.space.replacement参数)。
第三,存档文件不支持压缩。
一个归档后的文件,其存储结构如下图:
Sequence file
Sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
Hadoop-0.21.0中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。
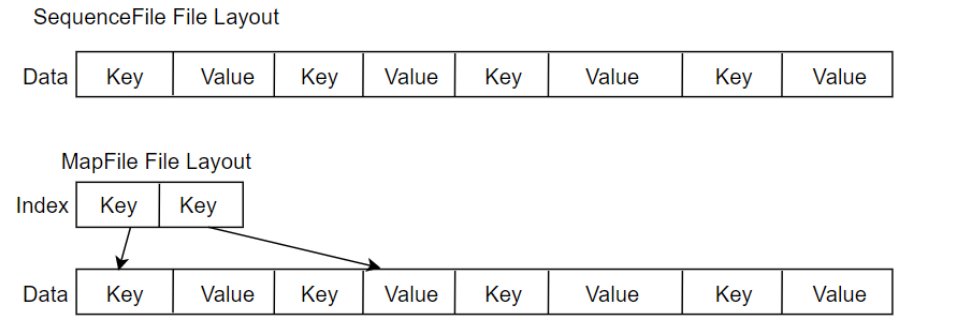
创建sequence file的过程可以使用mapreduce工作方式完成,对于index,需要改进查找算法
优缺点:对小文件的存取都比较自由,也不限制用户和文件的多少,但是该方法不能使用append方
法,所以适合一次性写入大量小文件的场景
CombineFileInputFormat
CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split,另外,它会考虑数据的存储位置。
Hive小文件问题怎么解决?
首先,我们要弄明白两个问题:
1)哪里会产生小文件
源数据本身有很多小文件
动态分区会产生大量小文件
reduce个数越多, 小文件越多
按分区插入数据的时候会产生大量的小文件, 文件个数 = maptask个数 * 分区数
2)小文件太多造成的影响
从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启
动,执行会浪费大量的资源,严重影响性能。
HDFS存储太多小文件, 会导致namenode元数据特别大, 占用太多内存, 制约了集群的扩展。
小文件解决方案:
方法一:通过调整参数进行合并
1)在Map输入的时候, 把小文件合并
-- 每个Map最大输入大小,决定合并后的文件数
set mapred.max.split.size=256000000;
-- 一个节点上split的至少的大小,决定了多个datanode上的文件是否需要合并
set mapred.min.split.size.per.node=100000000;
-- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set mapred.min.split.size.per.rack=100000000;
-- 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2)在Reduce输出的时候, 把小文件合并
-- 在map-onlyjob后合并文件,默认true
set hive.merge.mapfiles=true;
-- 在map-reducejob后合并文件,默认false
set hive.merge.mapredfiles=true;
-- 合并后每个文件的大小,默认256000000
set hive.merge.size.per.task=256000000;
-- 平均文件大小,是决定是否执行合并操作的阈值,默认16000000 sethive.merge.smallfiles.avgsize=100000000;
方法二:针对按分区插入数据的时候产生大量的小文件的问题,可以使用DISTRIBUTE BY rand() 将数据
随机分配给Reduce,这样可以使得每个Reduce处理的数据大体一致。
-- 设置每个reducer处理的大小为5个G
set hive.exec.reducers.bytes.per.reducer=5120000000;
-- 使用distributebyrand()将数据随机分配给reduce,避免出现有的文件特别大,有的文件特别小
insert overwrite table test partition(dt)
select * from iteblog_tmp
DISTRIBUTEBYrand();
方法三:使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件
方法四:使用hadoop的archive归档
-- 用来控制归档是否可用
set hive.archive.enabled=true;
-- 通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;-- 控制需要归档文件的大小
set har.partfile.size=1099511627776;
-- 使用以下命令进行归档
ALTER TABLE srcpart ARCHIVE PARTITION(ds='2008-04-08',hr='12');
- 对已归档的分区恢复为原文件
ALTER TABLE srcpart UNARCHIVE PARTITION(ds='2008-04-08',hr='12');
-- 注意,归档的分区不能够INSERTOVERWRITE,必须先unarchiveSpark输出文件的个数,如何合并小文件?
当使用spark sql执行etl时候出现了,最终结果大小只有几百k,但是小文件一个分区可能就有上千的情况。
小文件过多的一些危害如下:
- hdfs有最大文件数限制
- 浪费磁盘资源(可能存在空文件)
- hive中进行统计,计算的时候,会产生很多个map,影响计算的速度。
解决方案如下:
方法一:通过spark的coalesce()方法和repartition()方法
val rdd2 = rdd1.coalesce(8, true) //(true表示是否shuffle)
val rdd3 = rdd1.repartition(8)
coalesce:coalesce()方法的作用是返回指定一个新的指定分区的Rdd,如果是生成一个窄依赖的结果,那么可以不发生shuffle,分区的数量发生激烈的变化,计算节点不足,不设置true可能会出错。
repartition:coalesce()方法shuffle为true的情况。
方法二:降低spark并行度,即调节spark.sql.shuffle.partitions
比如之前设置的为100,按理说应该生成的文件数为100;
但是由于业务比较特殊,采用的大量的union all,且union all在spark中属于窄依赖,不会进行shuffle,所以导致最终会生成(union all数量+1)*100的文件数。
如有10个union all,会生成1100个小文件。这样导致降低并行度为10之后,执行时长大大增加,且文件数依旧有110个,效果不理想。
方法三:新增一个并行度=1任务,专门合并小文件
先将原来的任务数据写到一个临时分区(如tmp);再起一个并行度为1的任务,类似:
insert overwrite 目标表 select * from 临时分区
结果小文件数还是没有减少,经过多次测后发现原因:‘select * from 临时分区’ 这个任务在spark中属于窄依赖;
并且spark DAG中分为宽依赖和窄依赖,只有宽依赖会进行shuffle;
故并行度shuffle,spark.sql.shuffle.partitions=1也就没有起到作用;
由于数据量本身不是特别大,所以直接采用了group by(在spark中属于宽依赖)的方式,类似:
insert overwrite 目标表 select * from 临时分区 group by *
先运行原任务,写到tmp分区,‘dfs -count’查看文件数,1100个,运行加上group by的临时任务(spark.sql.shuflle.partitions=1),查看结果目录,文件数=1,成功。
总结:
1)方便的话,可以采用coalesce()方法和repartition()方法
2)如果任务逻辑简单,数据量少,可以直接降低并行度
3)任务逻辑复杂,数据量很大,原任务大并行度计算写到临时分区,再加两个任务:
一个用来将临时分区的文件用小并行度(加宽依赖)合并成少量文件到实际分区
另一个删除临时分区
4)hive任务减少小文件相对比较简单,可以直接设置参数,如:
Map-only的任务结束时合并小文件:
set hive.merge.mapfiles = true
在Map-Reduce的任务结束时合并小文件:
set hive.merge.mapredfiles= true
当输出文件的平均大小小于1GB时,启动一个独立的map-reduce任务进行文件merge:
set hive.merge.smallfiles.avgsize=1024000000