大数据之路—数据架构体系及模型设计
- 一、阿里巴巴数据整合及管理体系
- 二、维度设计
- 1、基本概念
- 2、规范化和反规范化
- 3、维度整合
- 4、维度拆分
- 5、维度变化
- 6、特殊维度
- 三、事实表设计
- 1、事实表特性
- 2、事实表类型
- 3、事实表设计原则
- 4、事务事实表
- 5、周期快照事实表的注意事项
- 6、累计快照事实表的物理实现
- 7、三种事实表的比较
- 8、聚集型事实表
一、阿里巴巴数据整合及管理体系
实施工作流:
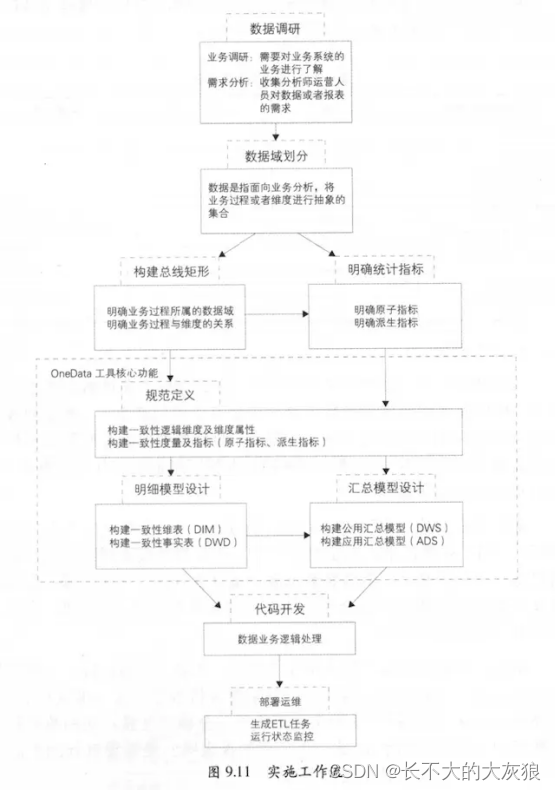
1、划分数据域:根据业务过程抽象出数据域。
2、构建总线矩阵:明确每个数据域下有哪些业务过程,业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
3、规范定义:定义度量/原子指标、修饰类型、修饰词、时间周期、派生指标。是一套数据规范命名体系,用在模型设计中。
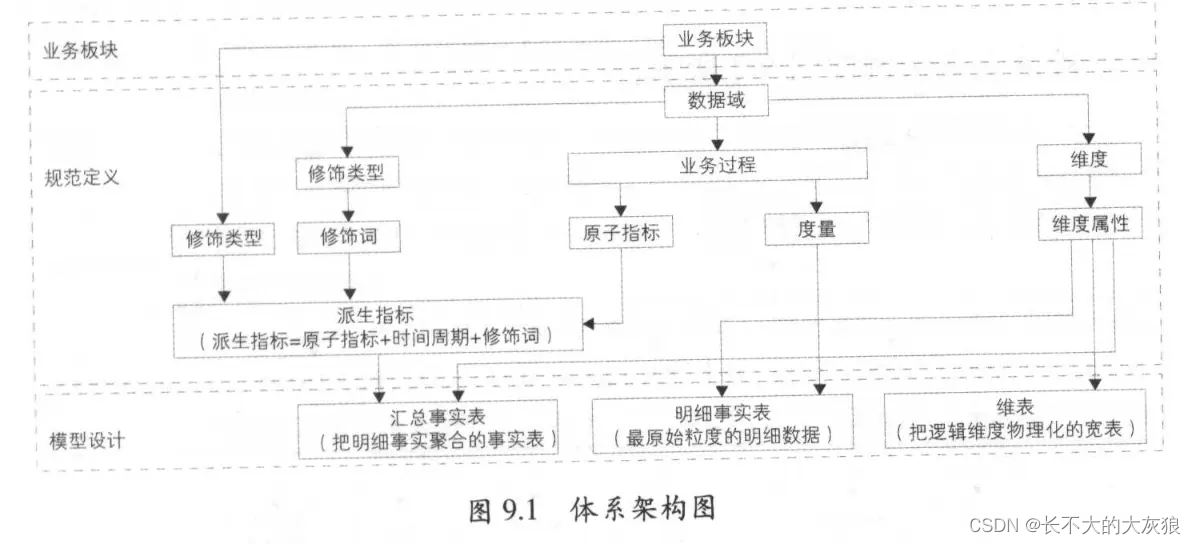
规范定义实例:
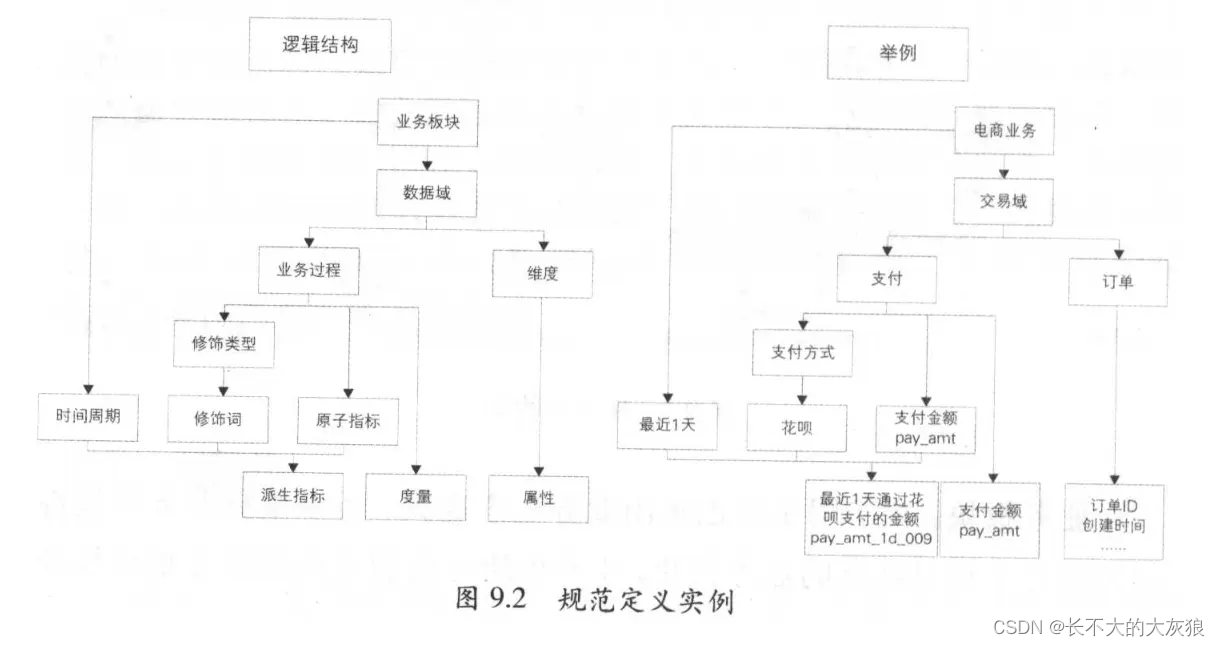
指标定义:
- 事务型指标:指对业务活动进行衡量的指标,例如新发商品数、新增会员数等。
- 存量型指标:指对实体对象某些状态的统计,例如商品总数、会员总数。
- 复合型指标:是在事务型指标和存量型指标的基础上复合而成的,例如浏览 UV-下单买家数转化率,有些需要创建新原子指标,有些则可以在事务型或存量型原子指标的基础上增加修饰词得到派生指标。
4、模型设计:维度及属性的规范定义,维表、明细事实表和汇总事实表的模型设计。
5、模型架构图
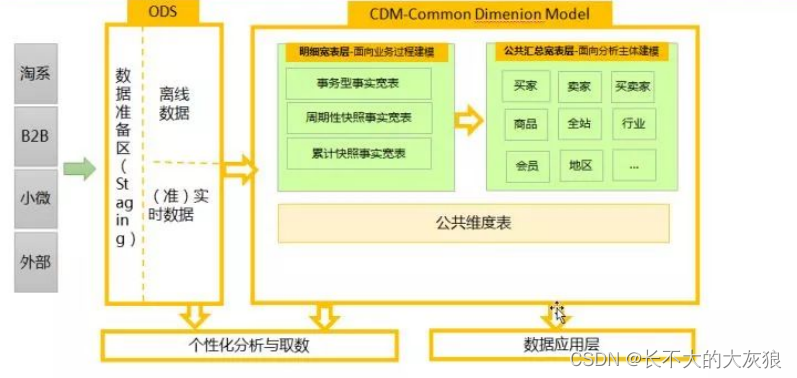
操作数据层(ODS):把操作系统数据几乎无处理地存放在数据仓库系统中。
公共模型层(CDM):存放明细事实数据、维表数据及公共指标汇总数据 ,其中明细事实数据、维表数据一般根据 ODS 层数据加工生成 ;公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
明细数据层(DWD)和汇总数据层(DWS):CDM 层又细分为 DWD 层和 DWS 层,分别是明细数据层和汇总数据层,采用维度模型方法作为理论基础 ,更多地采用一些维度退化手法, 将维度退化至事实表中,减少事实表和维表的关联 ,提高明细数据表的易用性;同时在汇总数据层, 加强指标的维度退化, 采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
应用数据层(ADS):存放数据产品个性化的统计指标数据,根据 CDM 层与 ODS 层加工生成 。
6、模型设计原则
(1)高内聚和低耦合
主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关、粒度相同的数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
(2)核心模型与扩展模型分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用的核心业务,扩展模型包括的字段支持个性化或少量应用的需要 ,不能让扩展模型的宇段过度侵入核心模型,以免破坏核心模型的架构简洁性与可维护性。
(3)公共处理逻辑下沉及单一
越是底层公用的处理逻辑越应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑多处同时存在。
(4)成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
(5)数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
(6)一致性
具有相同含义的字段在不同表中的命名必须相同,必须使用规范定义中的名称。
(7)命名清晰、可理解
表命名需清晰、一致,表名需易于消费者理解和使用。
二、维度设计
1、基本概念
在维度建模中,将度量成为“事实”,将环境称为“维度”。代理键和自然键–例如,对于前台应用系统来说,商品ID是代理键;而对于数据仓库系统来说,商品ID则属于自然键。
2、规范化和反规范化
当属性层次被实例化为一系列维度,而不是单一维度时被称为雪花模型。大多数OLTP系统模型采用雪花模型这种规范化操作。采用雪花模型,除了可以节约一部分存储外,对于OLAP系统来说没有其他效用,而现阶段存储的成本很低,所以在实际应用中几乎总是使用维表的空间来换取简明性和查询性能。
3、维度整合
数据集成到数仓中的体现:
- 命名规范的统一
- 字段类型的统一
- 公共代码及代码值的统一
- 业务含义相同的表的统一:通常有3种方式–主从表(将多个表都有的字段放在主表中,而从属信息分别放在各自的从表中)、直接合并、不合并,具体可以根据源表重合度及差异等状况确定。
垂直整合: 不同的来源表包含相同的数据集,比如淘宝会员在源系统中有多个表,包括会员基础信息表、会员扩展信息表等,可以尽量垂直整合到会员维度模型中。
水平整合: 不同的来源表包含不同的数据集,不同子集之间无交叉,也可以存在部分交叉,如果要整合则可以采用各子集的自然键作为联合主键的方式来实现。
4、维度拆分
水平拆分:
- 属性差异较大时,将所有属性建在一张维表中是不切实际的。可以抽象出稳定的公共维度,特殊维度单独落地。
- 两个相关性较低的业务,整合在一起弊大于利,对模型的稳定性和易用性影响较大,需要拆分单独落地。
垂直拆分:
出于扩展性、产出时间、易用性等方面的考虑,设计主从维度,主维表存放稳定、产出时间早、热度高的属性,从维表存放变化较快、产出时间晚、热度低的属性,比如商品主维表在每日的1:30左右产出,而商品扩展维度在每日的3:00左右产出。
5、维度变化
缓慢变化维,有三种处理方式:
- 重写维度值,不保留历史数据;
- 插入新的维度行,保留历史数据,这种方式不能将变化前后记录的事实归一化为变化前或变化后的维度;
- 添加维度列,记录新旧维度值,可以解决方案2的不足。
阿里巴巴内部处理缓慢变化维的方法是采用快照维表方式,即每天保留一份全量的快照数据,这种方案简单高效,但是存储空间浪费严重。
针对空间的浪费问题:
极限存储:采用历史拉链存储,对于不变的数据,不再重复存储。
6、特殊维度
递归维度:可以直接采用递归模型支撑递归维度,但很多工具不支持递归SQL,且递归SQL成本高,所以可以在维度模型中对层次结构进行扁平化处理。大部分时候,扁平化设计足够满足需求了。
多值维度: 常见的有三种处理方式
- 降低事实表的粒度,避免出现多值;
- 采用多字段来处理多值维度(如果值的数量固定);
- 采用桥接表来表达一对多关系(复杂成本高需慎重)。
多值属性: 常见的有三种处理方式
- 保持维度主键不变,将多值属性存放在维度的一个属性字段中,一般以K-V的形式存放;
- 保持维度主键不变,将多值属性存放在多个字段中;
- 维度主键发生变化,一个维度值存放多条记录,主键变更为原主键加属性ID。
杂项维度: 除去关键维度之外的维度,比如订单类型、支付状态、物流状态、订单属性、订单标签等。以上杂项维度一般单独建表存放。
三、事实表设计
1、事实表特性
作为度量业务过程的事实,有可加性、半可加性(只能按照特定维度汇总,不能对所有的维度进行汇总)、不可加性(比率类事实)。
2、事实表类型
- 事务事实表: 用来描述业务过程,跟踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为“原子事实表“。
- 周期快照事实表: 以具有规律性的、可预见的时间间隔记录事实 ,时间间隔如每天、每月、每年等。
- 累积快照事实表:用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点,当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。
3、事实表设计原则
- 尽可能包含所有与业务过程相关的事实
- 只选择与业务过程相关的事实
- 分解不可加性事实为可加事实
- 在选择维度和事实之前必须先声明粒度
- 在同一个事实表中不能有多个不同粒度的事实
- 事实的单位要保持一致
- 对事实的null值要处理:对于事实表中事实度量为 null 值的处理,因为在数据 库中 null 值 对常用数字型字段的 SQL过滤条件都不生效,比如大于、小于、等于、 大于或等于、小于或等于,建议用零值填充。
- 使用退化维度提高事实表的易用性
4、事务事实表
单事务事实表: 针对每个业务过程设计一个事实表。
多事务事实表: 多事务事实表在设计时有两种方法进行事实的处理
- 不同业务过程的事实使用不同的事实字段进行存放(会产生大量空数据),适合当不同业务过程的度量差异较大的情形;
- 不同业务过程的事实使用同一个事实字段进行存放,但增加一个业务过程标签。适合当不同业务过程的度量比较相似、差异不大的情形。
例子:淘宝交易事务事实表:
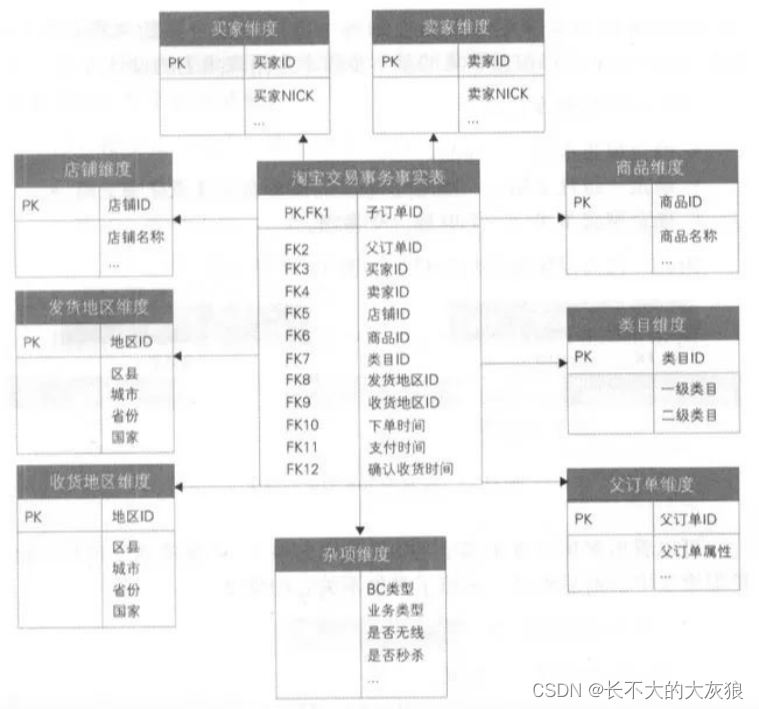
5、周期快照事实表的注意事项
- 事务事实表与周期快照事实表成对设计:
数据仓库维度建模时,对于事务事实表和快照事实表往往都是成对 设计的,互相补充,以满足更多的下游统计分析需求,特别是在事务事实表的基础上可以加工快照事实表,如前面所述的淘宝卖家历史至今快 照事实表,就是在事务事实表的基础上加工得到的,既丰富了星形模型, 又降低了下游分析的成本。 - 附加事实:快照事实表在确定状态度量时,一般都是保存采样周期结束时的状态度量,比如历史截至当日下单金额、历史截至当日XXXX。但是也有分析需求需要关注上一个采样周期结束时的状态度量,而又不愿意多次使用快照事实表,因此一般在设计周期快照事实表时会附加一些上一个采样周期的状态度量。
周期到日期度量
- 在介绍淘宝卖家历史至今快照事实表时,指定了统计周期是卖家历史至今的一些状态度量,比如历史截至当日的下单金额、成交金额等。然而在实际应用中,也有需要关注自然年至今、季度至今、财年至今的一些状态度量,因此在确定周期快照事实表的度量时,也要考虑类似的度量值,以满足更多的统计分析需求。
阿里巴巴数据仓库在设计周期快照事实表时,就针对多种周期到日期的度量设计了不同的快照事实表,比如淘宝卖家财年至今的下单金额、淘宝商品自然年至今的收藏次数等。
6、累计快照事实表的物理实现
全量表的形式:此全量表一般为日期分区表,每天的 分区存储昨天的全量数据和当天的增量数据合并的结果,保证每条记录 的状态最新。此种方式适用于全量数据较少的情况。
全量表的变化形式:比如针对交易订单,我们以 200 天作为订单从产生到消亡的最大间隔。设计最近 200 天的交易订单累积快照事实表,每天的分 区存储最近 200 天的交易订单而 200 天之前的订单则按照 gmt_create 创建分区存储在归档表中。
业务实体的结束时间分区:每天的分区存放当天结 束的数据,设计一个时间非常大的分区,比如 3000-12-31 ,存放截至当前未结束的数据。由于每天将当天结束的数据归档至当天分区中,时间 非常大的分区数据量不会很大, ETL 性能较好;并且无存储的浪费,对于业务实体的某具体实例,在该表的全量数据中唯一。但接口等原因,存在结束标志的确认问题,有以下两个方案:
- 使用相关业务系统的业务实体的结束标志作为此业务 系统的结束标志。
- 和前端业务系统确定口径或使用前端归档策略。
7、三种事实表的比较
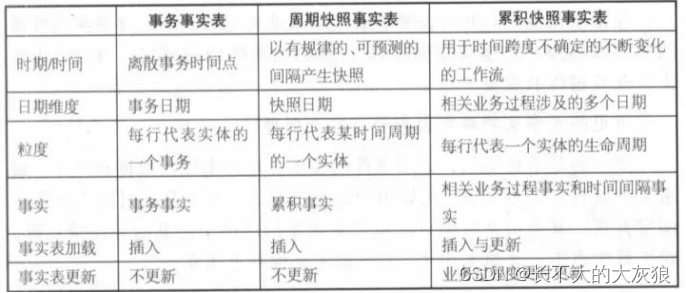
8、聚集型事实表
数据仓库的性能是数据仓库建设是否成功的重要标准之一。聚集主要是通过汇总明细粒度数据来获得改进查询性能的效果。通过访问聚集数据,可以减少数据库在响应查询时必须执行的工作量,能够快速响应用户的查询,同时有利于减少不同用户访问明细数据带来的结果不一致问题。尽管聚集能带来良好的收益,但需要事先对其进行加载和维护,这将会对给ETL带来更多的挑战。
阿里巴巴将使用频繁的公用数据,通过聚集进行沉淀,比如卖家最近1天的交易汇总表、卖家最近N天的交易汇总表、卖家自然年交易汇总表等。这类聚集汇总数据,被叫作“公共汇总层”。
参考文章:
[1] 阿里巴巴大数据实践(数据模型篇)