任务描述
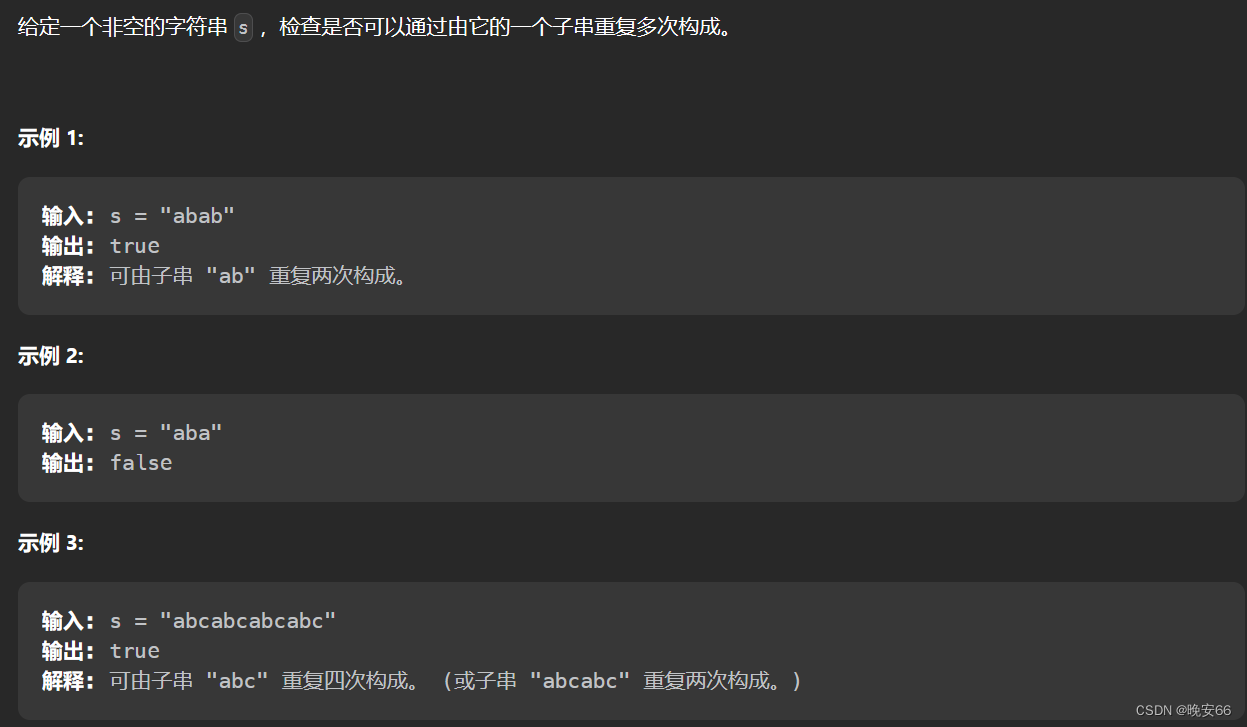
本关任务:使用Scala编写一个找出README.md文件中包含'a'的行数和包含'b'的行数的程序,并使用Maven对程序进行编译打包提交到Saprk上。
相关知识
在终端中执行如下命令创建一个文件夹 sparkapp3作为应用程序根目录:
cd ~ # 进入用户主文件夹mkdir ./sparkapp3 # 创建应用程序根目录mkdir -p ./sparkapp3/src/main/scala # 创建所需的文件夹结构
在./sparkapp3/src/main/scala下建立一个名为SimpleApp.scala的文件(vim ./sparkapp3/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */import org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConfobject SimpleApp {def main(args: Array[String]) {val logFile = "file:///usr/local/spark/README.md" // Should be some file on your systemval conf = new SparkConf().setAppName("Simple Application")val sc = new SparkContext(conf)val logData = sc.textFile(logFile, 2).cache()val numAs = logData.filter(line => line.contains("a")).count()val numBs = logData.filter(line => line.contains("b")).count()println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))}}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。 该程序依赖Spark Java API,因此我们需要通过Maven进行编译打包。在./sparkapp3目录中新建文件pom.xml,命令如下:
cd ~/sparkapp3vim pom.xml
然后,在pom.xml文件中添加如下内容,用来声明该独立应用程序的信息以及与Spark的依赖关系:
<project><groupId>cn.edu.xmu</groupId><artifactId>simple-project</artifactId><modelVersion>4.0.0</modelVersion><name>Simple Project</name><packaging>jar</packaging><version>1.0</version><repositories><repository><id>jboss</id><name>JBoss Repository</name><url>http://repository.jboss.com/maven2/</url></repository></repositories><dependencies><dependency> <!-- Spark dependency --><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.2</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><executions><execution><goals><goal>compile</goal></goals></execution></executions><configuration><scalaVersion>2.12.10</scalaVersion><args><arg>-target:jvm-1.8</arg></args></configuration></plugin></plugins></build></project>
为了保证Maven能够正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp3find .
文件结构应该是类似如下的内容:
../pom.xml./src./src/main./src/main/scala./src/main/scala/SimpleApp.scala
接下来,我们可以通过如下代码将整个应用程序打包成JAR包(注意:计算机需要保持连接网络的状态,而且首次运行打包命令时,Maven会自动下载依赖包,需要消耗几分钟的时间):
cd ~/sparkapp3 #一定把这个目录设置为当前目录/usr/local/maven/bin/mvn package
如果屏幕返回如下信息,则说明生成JAR包成功:
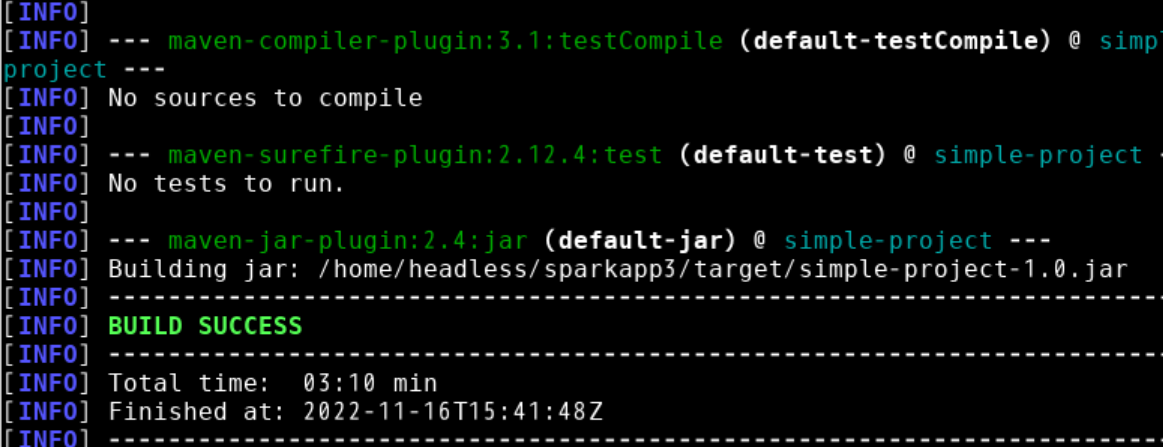
生成的应用程序JAR包的位置为~/sparkapp3/target/simple-project-1.0.jar。如果运行Maven编译打包过程很慢,是因为需要到国外网站下载很多的依赖包,国外网站速度很慢,因此,要花费很长时间。为了加快速度,可以更改为国内的仓库地址。 最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/simple-project-1.0.jar#上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp3/target/simple-project-1.0.jar > step5.txt #结果输出到step5.txt中cat step5.txt
得到的结果如下:
Lines with a: 71, Lines with b: 38
到此,就顺利完成 Spark 应用程序的Maven编译打包运行了。
编程要求
根据提示,完成Maven对Sacal进行打包。
开始你的任务吧,祝你成功!

![[桌面运维]PC常用的视频接口,显示器VGA、DVI、HDMI、DP、USB-C接口的认识和应用](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)