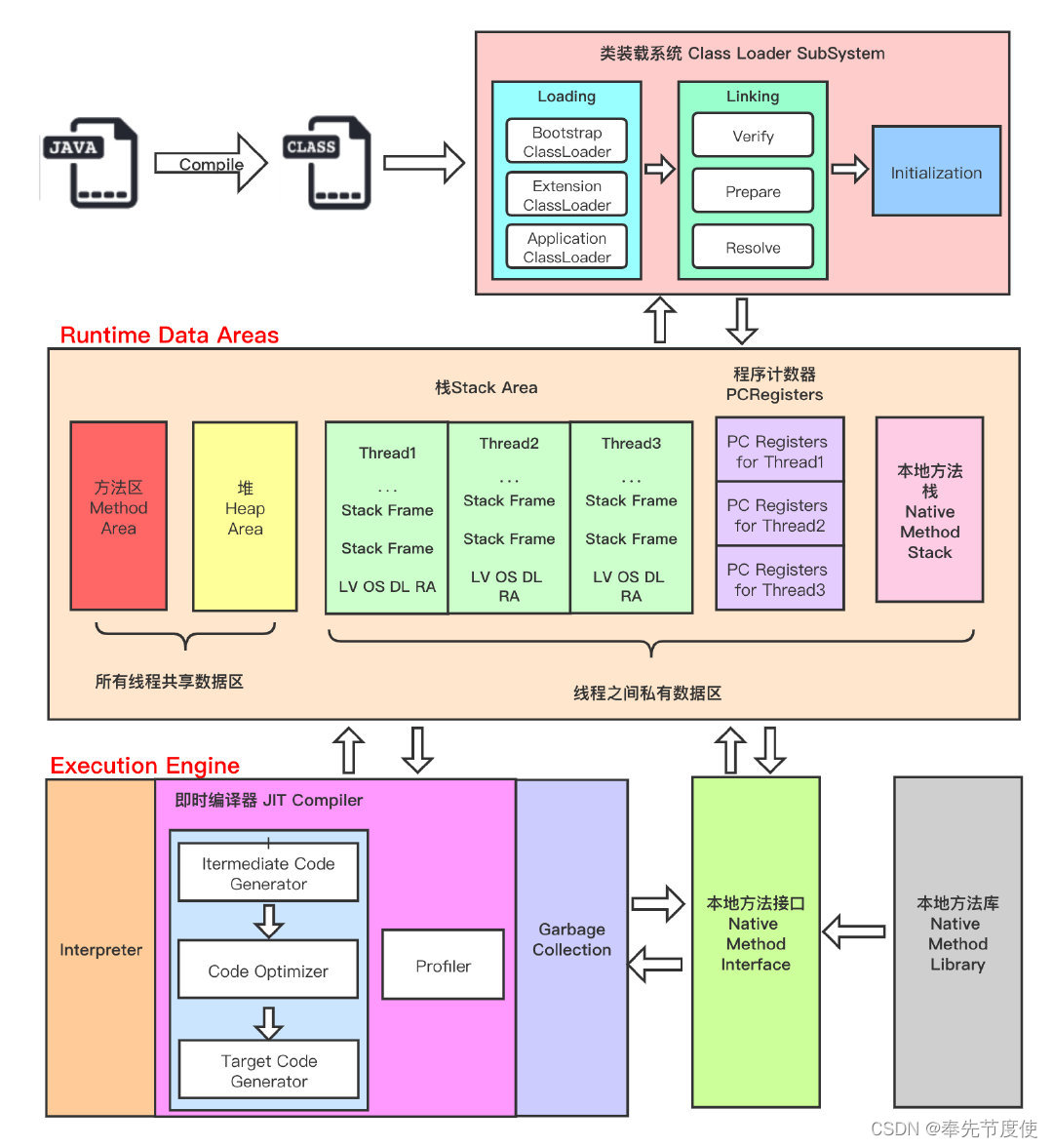
前言
本文以Mysql为例。Spark作为一种强大且广泛应用于大数据处理的分布式计算框架,有着出色的性能和可伸缩性。在使用Spark处理大规模数据时,往往需要与关系型数据库MySQL进行交互。然而,由于MySQL和Spark本身的特性之间存在一些差异,直接使用Spark读写MySQL的默认配置可能会导致性能瓶颈。因此,本篇博客将介绍一些优化技巧来加速Spark读写MySQL的过程。
Sparksql Options
可以使用数据源API将远程数据库中的表加载为DataFrame或Spark SQL临时视图。用户可以在数据源选项中指定JDBC连接属性。用户和密码通常作为登录到数据源的连接属性提供。除了连接属性外,Spark还支持以下不区分大小写的选项:
| 属性 | 含义 |
|---|---|
| user | 数据库用户名 |
| password | 数据库密码 |
| url | 要连接到的JDBC URL。可以在URL中指定特定于源的连接属性。例如jdbc:postgresql://localhost/test?user=fred&password=secret |
| dbtable |