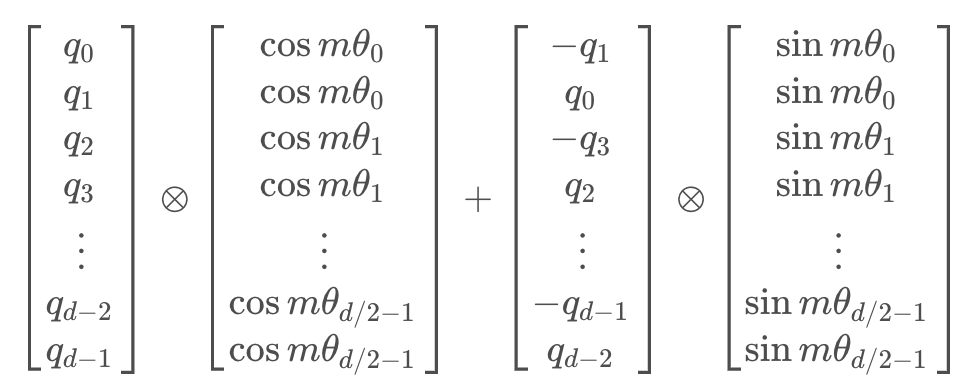摘要
在住院床位管理中,医院通常会将住院病人分配到相对应的专科病房,但随着病人的入院和出院,可能会出现病人所需的专科病房满员,而其他病房却有空余床位的情况。于是就有了 "溢出 "策略,即当病人等候时间较长的情况下,考虑将病人分配到非首选病房。在实际应用中,因为有很多不确定因素,实时决策何时使用 "溢出 "策略是非常有挑战性的一个问题。 本文将住院的病人流建模为一个并行多类别多池的排队网络(Multi-class, multi-pool queueing system),并将溢出决策问题表述为一个离散时间无限时域的平均成本马尔可夫决策过程(Markov decision process, MDP)。为了解决 MDP 的维度诅咒,本文采用了近似动态规划(Approximate Dynamic Programming, ADP)方法,其关键在于选择合适的基函数来近似相对值函数。
1. 介绍
在住院床位管理中,医院管理人员需要做的决策主要有两个方面: (a) 是否将候诊病人分配到非首选病房,以及 (b) 如果多个非首选病房都有空余床位,优先使用哪个病房。
在决策过程中,主要需要考虑的是这两方面成本: (a) 病人持有成本,该成本和等待中的病人数量有关,以及 (b) 溢出成本,该成本与把病人分配到非首选病房有关。
本文就介绍了这么一种辅助医院管理人员做出溢出决策的决策支持工具,旨在平衡多池并行服务器队列系统(multi-pool parallel- server queueing systems)中减少等待时间和避免不良溢出情况之间的权衡。
2. 模型介绍
2.1 住院病人流的多类别多池排队网络 (Multi-class, multi-pool queueing system)
假设该排队系统有 J J J类病人和 J J J个并行的服务池,每个服务池服务一类首选病人。假设 j j j池服务 j j j 类病人,并且有 N j N_j Nj个相同的服务器, N = ∑ j = 1 J N j N = \sum_{j=1}^{J}N_j N=∑j=1JNj表示该系统里所有的服务器。
- 当 j j j 类病人到达时,如果首选池有空闲服务器,该病人将立即进入服务,这种进入为一次分配;否则,病人将在无限大的 j j j 池等待区中等待。病人可能会一直等待直到首选池有空余床位,或者在此之前,在某个时间被收进非首选池中,后者被称为溢出分配。
- 当有病人离开服务池 j j j 时,如果 j j j 池等待区不为空,则服务池 j j j 会按照先到先得(FCFS)规则从等待区中收入一名病人;如果 j j j 池等待区为空,则服务池 j j j 里的空余床位就会保持空置直到下一个病人到来。
本文假设 J J J类病人中的每一类都是按照时间非齐次泊松过程到达,其中到达率函数 λ j ( t ) \lambda_j(t) λj(t)是周期为 T T T 的周期性函数,即
λ j ( s ) = λ j ( s + T ) , f o r s > = 0 , j = 1 , 2 , 3 , . . . , J \lambda_{j}(s) = \lambda_{j}(s+T), for \ s >= 0, j = 1,2,3,...,J λj(s)=λj(s+T),for s>=0,j=1,2,3,...,J
为便于说明,本文以天为时间单位,假设 T = 1 T = 1 T=1,并设
Λ j = ∫ 0 T λ j ( s ) d s \Lambda_j = \int_{0}^{T}\lambda_j(s)ds Λj=∫0Tλj(s)ds
为每一天的 j j j类病人到达率。
假设病人的服务时间遵循双时标形式,
s e r v i c e t i m e = L O S + h d i s − h a d m service \ time = LOS + h_{dis} - h_{adm} service time=LOS+hdis−hadm
其中 L O S LOS LOS是病人过夜的次数, h d i s h_{dis} hdis 和 h a d m h_{adm} hadm 是病人被接收入院和出院的时间。通过双时标的方式,本文可以抓取到每天和每小时的不确定性,其中 L O S LOS LOS可以抓取到每天的不确定性, h d i s h_{dis} hdis 可以抓取到每小时的不确定性, h a d m h_{adm} hadm 由系统决定,因为不遵循iid假设。
2.2 溢出决策和 MDP 表述
本文将溢出决策问题表述为一个离散时间无限时域的平均成本马尔可夫决策过程。决策者在决策时间点 t 0 t_0 t0、 t 1 t_1 t1、…观察系统状态 S ( . ) S(.) S(.),并根据在这些时间点观察到的状态采取行动。实际上,这些时间点的间隔不一定相等,但本文假定它们每天在相同的时刻重复出现。每天共有 m m m 个时间点,例如,每天凌晨 3 点、6 点、…、下午 5 点和晚上 9 点做出决策。
本文采用以下惯例: 假定 S ( . ) S(.) S(.)是右连续的,有左极限,在每个时点 t k t_k tk 采取行动, S ( t k − ) S(t_{k-}) S(tk−)是 S ( . ) S(.) S(.)在 tk 时的左极限,称为行动前状态, S ( t k ) S(t_k) S(tk)称为行动后状态。
状态空间
该系统状态可以表述为一个 ( 2 J + 1 ) (2J + 1) (2J+1)维度的向量:
S ( . ) = ( X 1 ( . ) , . . . , X J ( . ) , Y 1 ( . ) , . . . , Y J ( . ) , h ( . ) ) S(.) = (X_1(.), ..., X_J(.), Y_1(.), ..., Y_J(.), h(.)) S(.)=(X1(.),...,XJ(.),Y1(.),...,YJ(.),h(.))
X j ( t k ) X_j(t_k) Xj(tk)是在 t k t_k tk时间点,等待中的j类病人和在j服务池中被服务的病人的总数。
Y j ( t k ) Y_j(t_k) Yj(tk)是在 t k t_k tk时间点,服务池 j 的待出院人数,即从时间点 t k t_k tk 到第二天开始之间准备出院的患者人数。
h ( t k ) = k m o d m h(t_k) = k \ mod \ m h(tk)=k mod m 表示一天内的时间索引。换句话说, h ( t k ) ∈ { 0 , 1 , . . , m } h(t_k) \in \{0, 1, .., m\} h(tk)∈{0,1,..,m} 表示 tk 在一天内所属的 m m m 个决策时间点中的时间点 tk 的数字顺序。
行动和成本
本文将时间 t k t_k tk 的行动集表示为
f ( t k ) = { f i j ( t k ) , i ≠ j , i = 1 , . . . . , J , j = 1 , . . . , J } f(t_k) = \{ f_{ij}(t_k), i \not = j, i = 1,...., J, j = 1,..., J\} f(tk)={fij(tk),i=j,i=1,....,J,j=1,...,J}
其中 f i j f_{ij} fij表示i类病人被分配给非首要服务池j的数量。
本文将与行动 f ( t k ) f(t_k) f(tk) 和行动前状态 S ( t k − ) S(t_k-) S(tk−) 相关的单次成本定义为
g ( S ( t k − ) , f ( t k ) ) = ∑ i = 1 J ∑ j ≠ i , j = 1 J B i j . f i j ( t k ) + ∑ j = 1 J C j ∗ Q j ( t k ) g(S(t_k-),f(t_k)) = \sum_{i=1}^{J}\sum_{j \not = i, j =1}^{J}B_{ij}.f_{ij}(t_k) + \sum_{j=1}^{J}C_j * Q_j(t_k) g(S(tk−),f(tk))=i=1∑Jj=i,j=1∑JBij.fij(tk)+j=1∑JCj∗Qj(tk)
其中,第一部分为溢出成本, B i j B_{ij} Bij为每个病人的溢出成本;第二部分为滞留成本, C j C_j Cj为统一滞留成本, Q j ( . ) = ( X j ( . ) − N j ) + Qj(.)=(Xj(.)-Nj)^{+} Qj(.)=(Xj(.)−Nj)+ 为等待病人的数量,也就是队列长度。为了分析方便,本文使用在 t k t_k tk时间采取行动后的队列长度 Q j ( t k ) Q_j(t_k) Qj(tk)来表示两个决策时间段之间的平均队列长度。
本文的目标是找到一个最优的溢出政策,使长期平均成本最小化,其定义为:
l i m n → ∞ 1 n E ( ∑ k = 1 n g ( S ( t k − ) , f ( t k ) ) ) lim_{n \to \infty} {1 \over n} E(\sum_{k=1}^{n} g(S(t_k-), f(t_k))) limn→∞n1E(k=1∑ng(S(tk−),f(tk)))
状态转换
本文用 s = ( x 1 , . . . . , x J , y 1 , . . . , y J , h ) s = (x_1, ...., x_J, y_1, ..., y_J, h) s=(x1,....,xJ,y1,...,yJ,h)表示某一时刻的行动前状态,用 s ′ = ( x 1 ′ , . . . . , x J ′ , y 1 ′ , . . . , y J ′ , h ′ ) s' = (x_1', ...., x_J', y_1', ..., y_J', h') s′=(x1′,....,xJ′,y1′,...,yJ′,h′)表示一步转换后的行动前状态。
本文将说明非午夜的每个时间节点 h = 1 , . . . , m − 1 h = 1,...,m-1 h=1,...,m−1 时从 s s s 到 s ′ s' s′开始的过渡动态。
s ′ s' s′ 状态被更新为
x j ′ = x j + a j − d j − ∑ l ≠ j , l = 1 J f j l + ∑ i ≠ j , i = 1 J f i j , i = 1 , . . . , J x_j' = x_j + a_j - d_j - \sum_{l \not = j, l = 1}^{J}f_{jl} + \sum_{i \not = j, i =1}^{J}f_{ij}, i = 1, ..., J xj′=xj+aj−dj−l=j,l=1∑Jfjl+i=j,i=1∑Jfij,i=1,...,J
y j ′ = y j − d j , i = 1 , . . . , J y_j' = y_j - d_j, i = 1,..., J yj′=yj−dj,i=1,...,J
h ′ = ( h + 1 ) m o d m h' = (h+1) \ mod \ m h′=(h+1) mod m
其中, a j a_j aj 和 d j d_j dj分别表示在 h h h和下一时刻 h ′ h' h′之间第 j 类病人的到达量和第 j 组病人的离开量。 ∑ l ≠ j , l = 1 J f j l \sum_{l \not = j, l=1}^{J}f_{jl} ∑l=j,l=1Jfjl 表示j类病人被分配给非首选服务池的数量。 ∑ i ≠ j , i = 1 J f i j \sum_{i \not = j, i=1}^{J}f_{ij} ∑i=j,i=1Jfij 表示非j类病人被分配给服务池j的数量。
3. 时间分解泊松方程
在本节中,作者探讨了病人到达和离开的时间周期特性,并推导出一个时间分解泊松方程。
对于长期平均成本问题,本文需要求解贝尔曼方程:
γ ∗ + ν ∗ ( s ) = m i n f { g ( s , f ) + ∑ s ′ p ( s , ∣ s , f ) ν ∗ ( s , ) } , s ∈ S \gamma^* + \nu^*(s) = min_{f}\{ g(s,f) + \sum_{s'}p(s^,|s,f)\nu^*(s^,)\}, s \in \mathscr{S} γ∗+ν∗(s)=minf{g(s,f)+∑s′p(s,∣s,f)ν∗(s,)},s∈S
其中, s s s 表示行动之前的状态, γ ∗ \gamma^* γ∗表示每个决策周期的最小长期平均成本, ν ∗ ( . ) \nu^*(.) ν∗(.)是相对值函数, g ( s , f ) g(s,f) g(s,f)是一个决策周期的成本, p ( s , ∣ s , f ) p(s^,|s,f) p(s,∣s,f)是转换概率。
假设存在 ( γ ∗ , ν ∗ ) (\gamma^* , \nu ^ *) (γ∗,ν∗) ( γ ∗ , ν ∗ ) (\gamma^* , \nu^*) (γ∗,ν∗) f ∗ f^* f∗,
f ∗ ( s ) = a r g m i n f { g ( s , f ) + ∑ s ′ p ( s , ∣ s , f ) ν ∗ ( s , ) } , s ∈ S f^*(s) = arg min_{f}\{ g(s,f) + \sum_{s'}p(s^,|s,f)\nu^*(s^,)\}, s \in \mathscr{S} f∗(s)=argminf{g(s,f)+s′∑p(s,∣s,f)ν∗(s,)},s∈S
来实现最优的长期平均成本 γ ∗ \gamma ^ * γ∗,也就是说, f ∗ f^* f∗是最优的一个策略。
对于给定的静态策略 f f f,让 ν = { ν ( s ) : s ∈ S } \nu = \{ \nu(s):s\in \mathscr{S}\} ν={ν(s):s∈S}成为相应的相对价值函数。那么, ( f , ν ) (f,\nu) (f,ν)满足以下泊松方程:
ν = ( g f − γ e ) + P f v \nu=\left({\mathbf{g}}_f- \gamma \mathbf{e}\right)+{\mathbf{P}}_f v ν=(gf−γe)+Pfv
其中, γ \gamma γ是与政策 f f f相关的长期平均成本, e e e是单位向量, g f = { g ( s , f ) : s ∈ S } g_f=\{g(s,f):s\in \mathscr{S} \} gf={g(s,f):s∈S} 和 P f = { p ( s , ∣ s , f ) : s , s , ∈ S } P_f = \{ p(s^{,}|s,f):s,s^{,} \in \mathscr{S} \} Pf={p(s,∣s,f):s,s,∈S}分别是政策 f f f下的单周期成本向量和过渡概率矩阵。
本文将以上泊松方程进行时间分解,得到,对每一个时间节点 h = 0 , 1 , . . . , m − 1 h = 0,1,...,m-1 h=0,1,...,m−1,可以有
v h = ( g ~ f h − m γ e ) + P ~ f h v h . v^h=\left(\tilde{\mathbf{g}}_f^h-m \gamma \mathbf{e}\right)+\tilde{\mathbf{P}}_f^h v^h . vh=(g~fh−mγe)+P~fhvh.
其中, P ~ f h \tilde{\mathbf{P}}_f^h P~fh和 g ~ f h \tilde{\mathbf{g}}_f^h g~fh分别表示了单周期过渡矩阵和单周期累积成本。
P ~ f h = P f h , h + 1 P f h + 1 , h + 2 . . . P f h − 1 , h \tilde{\mathbf{P}}_f^h = {\mathbf{P}}_f^{h,h+1}{\mathbf{P}}_f^{h+1,h+2}...{\mathbf{P}}_f^{h-1,h} P~fh=Pfh,h+1Pfh+1,h+2...Pfh−1,h
g ~ f h = g f h + P f h , h + 1 g f h + 1 + . . . + ( P f h , h + 1 . . . P f h − 2 , h − 1 g f h − 1 ) \tilde{\mathbf{g}}_f^h = {\mathbf{g}}_f^h + {\mathbf{P}}_f^{h,h+1}{\mathbf{g}}_f^{h+1} + ... + ({\mathbf{P}}_f^{h,h+1}...{\mathbf{P}}_f^{h-2,h-1}{\mathbf{g}}_f^{h-1}) g~fh=gfh+Pfh,h+1gfh+1+...+(Pfh,h+1...Pfh−2,h−1gfh−1)
因为上述式子大部分都是0,除了 j = ( i + 1 ) m o d m j=(i+1) \ mod \ m j=(i+1) mod m, 从而可以得到
v h = ( g f h − γ e ) + P f h , h + 1 v h + 1 , h = 0 , 1 , . . . , m − 1 v^h=\left({\mathbf{g}}_f^h- \gamma \mathbf{e}\right)+{\mathbf{P}}_f^{h,h+1} v^{h+1} , h = 0, 1, ..., m-1 vh=(gfh−γe)+Pfh,h+1vh+1,h=0,1,...,m−1
4. 基于模拟的ADP:近似策略迭代
4.1. 相对值函数近似(relative value function approximation)
为了解决动态规划的维数诅咒,作者使用有限个基函数的线性组合来近似相对值函数。对于每个时间节点 h = 0 , 1 , . . . , m − 1 h=0,1,...,m-1 h=0,1,...,m−1,其相对值函数可被近似为
v h ( s ) ≈ ϕ h ( s ) β h = ∑ i = 1 K h β i h ϕ i h ( x , y ) , ∀ s ∈ S h v^h(s) \approx \phi^h(s) \beta^h=\sum_{i=1}^{K^h} \beta_i^h \phi_i^h(x, y), \quad \forall s \in \mathscr{S}^h vh(s)≈ϕh(s)βh=i=1∑Khβihϕih(x,y),∀s∈Sh
其中, ϕ h ( s ) = ( ϕ 1 h ( x , y ) , . . . , ϕ K h h ( x , y ) ) \phi^h(s)=(\phi^h_1(x,y),...,\phi^h_{K^h}(x,y)) ϕh(s)=(ϕ1h(x,y),...,ϕKhh(x,y))为 K h K^h Kh个基函数形成的向量,与之对应的系数向量为 β h = ( β 1 h , … , β K h h ) ′ \beta^h=(\beta_1^h,…,\beta_{K^h}^h)^{'} βh=(β1h,…,βKhh)′。注意,基函数的个数,具体函数形式,与系数都是与时间 h h h相关的。另外,基函数是关于 x x x和 y y y的二次函数的组合。
4.2. 近似策略迭代(更新系数向量)
显然,相对值函数的近似完全由基函数及其对应的系数决定。作者在本小节介绍如何在每个决策时间节点 h h h来更新这些系数。算法如下:
Inputs: 置 n = 1 n=1 n=1,并从任意的系数向量 ( β 0 , … , β m − 1 ) (\beta^0,…,\beta^{m-1}) (β0,…,βm−1)出发;
Step 1(策略提升): 使用提升策略 f ( n ) f^{(n)} f(n)模拟 J J J-池系统,其中,每一个决策阶段的action由下式生成
f ( n ) ( s ) = arg min f { g ( s , f ) + ∑ s ′ ∈ S h + 1 p ( s ′ ∣ s , f ) ϕ h + 1 ( s ′ ) β h + 1 } , s ∈ S h \begin{aligned}f^{(n)}(s)= & \underset{f}{\arg \min }\{g(s, f) \\& \left.+\sum_{s^{\prime} \in \mathscr{S}^{h+1}} p\left(s^{\prime} \mid s, f\right) \phi^{h+1}\left(s^{\prime}\right) \beta^{h+1}\right\}, \quad s \in \mathscr{S}^h\end{aligned} f(n)(s)=fargmin{g(s,f)+s′∈Sh+1∑p(s′∣s,f)ϕh+1(s′)βh+1},s∈Sh
Step 2(策略评估): 通过时序差分学习(temporal difference learning)并近似求解式
v h = ( g ~ f h − m γ e ) + P ~ f h v h . v^h=\left(\tilde{\mathbf{g}}_f^h-m \gamma \mathbf{e}\right)+\tilde{\mathbf{P}}_f^h v^h . vh=(g~fh−mγe)+P~fhvh.
中的 h h h个子式以获得更新系数向量 ( β ^ 0 , … , β ^ m − 1 ) (\hat{\beta}^0,…,\hat{\beta}^{m-1}) (β^0,…,β^m−1),关于上式,详见泊松方程的时间分解(Time Decomposition of the Poisson Equation)一节。
Step 3: 置 n = n + 1 n=n+1 n=n+1且 ( β 0 , … , β m − 1 ) = ( β ^ 0 , … , β ^ m − 1 ) (\beta^0,…,\beta^{m-1})=(\hat{\beta}^0,…,\hat{\beta}^{m-1}) (β0,…,βm−1)=(β^0,…,β^m−1);如果迭代次数 n n n达到预先设定的阈值 n ∗ n^* n∗,算法停止。
5. 基函数(basis functions)
为选取不同时期用于近似的基函数,首先研究一个当 m = 1 m=1 m=1时的MDP,作者将其称之为midnight MDP。之后,借助逆向归纳的方法,可以得到所有决策时期的基函数。注意,当m=1时,这意味着每一天只有一个决策阶段。作者使用 v m i d ( x ) v_{mid}(x) vmid(x)表示相关的最优近似值函数,并提出了如下近似
v mid ( x ) ≈ v 1 F ( x ) + V s ( ∑ j x j ) v_{\text {mid }}(x) \approx v_1^F(x)+V_s\left(\sum_j x_j\right) vmid (x)≈v1F(x)+Vs(j∑xj)
其中, v 1 F ( x ) v_1^F(x) v1F(x)由一个流体控制模型捕获(读者可以该论文以获得这个模型的详细信息),用于近似溢出成本; V s ( ⋅ ) V_s(\cdot) Vs(⋅)表示来自一个集成单池系统(integrated single-pool system)的相对值函数,用于近似持有成本。用户数 x = ( x 1 , … , x J ) x=(x_1,…,x_J) x=(x1,…,xJ)。
5.1. 午夜时期的基函数
对于一个多阶段MDP( m > 1 m>1 m>1),当 h = 0 h=0 h=0时,过去一天待出院的患者计为0,因为所有的患者在那时都出院了。而第二天待出院的患者在午夜时刻基于患者数 x = ( x 1 , … , x J ) x=(x_1,…,x_J) x=(x1,…,xJ)生成。另外,注意midnight时期的相对值函数及其最优值 v 0 , ∗ v^{0,*} v0,∗只与 x x x有关,且只有在 m = 1 m=1 m=1时,才有 v m i d = v 0 , ∗ v_{mid}=v^{0,*} vmid=v0,∗。
如果使用式 v mid ( x ) ≈ v 1 F ( x ) + V s ( ∑ j x j ) v_{\text {mid }}(x) \approx v_1^F(x)+V_s\left(\sum_j x_j\right) vmid (x)≈v1F(x)+Vs(∑jxj)经逆向归纳获取其它时期的值函数,对于所有可能的 x x x,不仅需要预存储 v 1 F ( x ) v_1^F(x) v1F(x),还需要预存储所有时期和所有状态的近似值函数。为处理 v 1 F ( x ) v_1^F(x) v1F(x)的分段线性结构,作者在午夜时期选择如下基函数:
V s ( ∑ x ) , x j 2 , x j , j = 1 , . . . , J , V_s(\sum x), x_j^2,x_j, \quad j=1,...,J, Vs(∑x),xj2,xj,j=1,...,J,
为了更加方便地寻找其它时期的基函数,相应地, v 0 , ∗ v^{0,*} v0,∗的更简洁的近似可以写成
v 0 , ∗ ( x ) ≈ β s 0 V s ( ∑ j x j ) + ∑ j = 1 J ( β 2 j 0 x j 2 + β 1 j 0 x j ) + β 00 0 v^{0, *}(x) \approx \beta_s^0 V_s\left(\sum_j x_j\right)+\sum_{j=1}^J\left(\beta_{2 j}^0 x_j^2+\beta_{1 j}^0 x_j\right)+\beta_{00}^0 v0,∗(x)≈βs0Vs(j∑xj)+j=1∑J(β2j0xj2+β1j0xj)+β000
5.2. 不同时期的基函数
对于时间点 m − 1 m-1 m−1,最优相对值函数为
γ + v m − 1 ( s ) = min f { g ( s , f ) + ∑ s ′ p ( s ′ ∣ s , f ) v 0 ( s ′ ) } , s ∈ S m − 1 \gamma+v^{m-1}(s)=\min _f\left\{g(s, f)+\sum_{s^{\prime}} p\left(s^{\prime} \mid s, f\right) v^0\left(s^{\prime}\right)\right\}, \quad s \in \mathscr{S}^{m-1} γ+vm−1(s)=fmin{g(s,f)+s′∑p(s′∣s,f)v0(s′)},s∈Sm−1
其中, v 0 v^0 v0是午夜时期的最优值函数,紧跟前一天的时间点 m − 1 m-1 m−1。把 v 0 , ∗ ( x ) v^{0,*}(x) v0,∗(x)的近似函数代入上式,就可以得到 v m − 1 ( s ) v^{m-1}(s) vm−1(s)的近似形式。不断重复这个操作,就可以得到所有时期的基函数形式,具体如下
ν h + 1 ( x 1 , x 2 , … , x J , y 1 , y 2 , … , y J ) ≈ β s V s h + 1 ( x , y ) + β 00 + ∑ j = 1 J ( β 2 j x j 2 + β 1 j x j ) + ∑ j = 1 J ( θ 2 j y j 2 + θ 1 j y j ) + ∑ j = 1 J ω 2 j x j y j , h + 1 = m − 1 , … , 2. \begin{aligned} & \nu^{h+1}\left(x_1, x_2, \ldots, x_J, y_1, y_2, \ldots, y_J\right) \\ \approx & \beta_s V_s^{h+1}(x, y)+\beta_{00} \\ & +\sum_{j=1}^J\left(\beta_{2 j} x_j^2+\beta_{1 j} x_j\right)+\sum_{j=1}^J\left(\theta_{2 j} y_j^2+\theta_{1 j} y_j\right)+\sum_{j=1}^J \omega_{2 j} x_j y_j, \quad h+1=m-1, \ldots, 2 . \end{aligned} ≈νh+1(x1,x2,…,xJ,y1,y2,…,yJ)βsVsh+1(x,y)+β00+j=1∑J(β2jxj2+β1jxj)+j=1∑J(θ2jyj2+θ1jyj)+j=1∑Jω2jxjyj,h+1=m−1,…,2.
6. 数值实验
6.1. 模拟模型
模拟模型考察了五个( J = 5 J=5 J=5)并行的服务池(专科):general medicine(GeMed,普通内科),Surgery (Surg,外科),Orthopedic(Ortho,骨科), Cardiology (Card,心脏病科)和Other Medicine(OtMed,包括肠胃病学和神经学)。根据入院来源,可分为三类:来自急诊(ED)部门;选择性住院(EL);从其它医院转入的内部患者(TR)。对于每个专科,作者分别生成来自每个入院源的到达队列,并使用三个单独的缓冲区来容纳来自三个来源的等待患者,也就是说,模型有15个到达流和15个缓冲区。作者对主床位分配执行优先级规则:当主床位可用时,EL患者具有最高优先级,其次是ED,然后是TR患者。
6.2. 参数估计
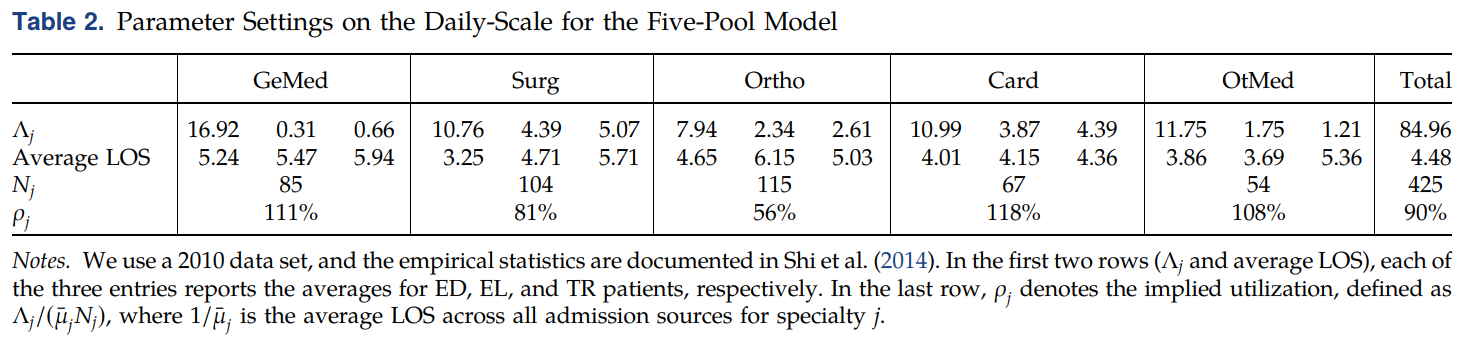
作者使用新加坡合作医院2010年的数据对模型中的参数进行了校准,结果如下表所示:
6.3. ADP结果分析与比较
(运行时间说明:每一次策略迭代需要花费20-27分钟,策略评估中的每一次replication需要花费5-10分钟;程序语言为C++;在Macbook Air(8 GB 1600 MHz DDR3,酷睿i5处理器)上执行)
将本文提出的近似动态规划策略(approximate dynamic programming,ADP)与以下三种策略进行比较:(i) 完全共享(full-sharing)策略:允许在每个决策时间段出现溢出;(ii) 午夜(midnight)政策:只允许在每天的午夜时间段出现溢出;(iii) 经验(empirical)政策:只允许在晚上 7 点到第二天早上 7 点之间出现溢出。
当单位持有成本 C j ≡ C = 6 C_j\equiv C=6 Cj≡C=6。对于溢出成本,以 B = ( 30 , 35 ) B=(30,35) B=(30,35)为例,表示对于所有科室类别,其首选病房的溢出均成本为30,次级病房的溢出成本均为35。作者对 B B B的取值进行了敏感性分析,且进行了不同于ADP策略的方法比对,结果如下表所示。
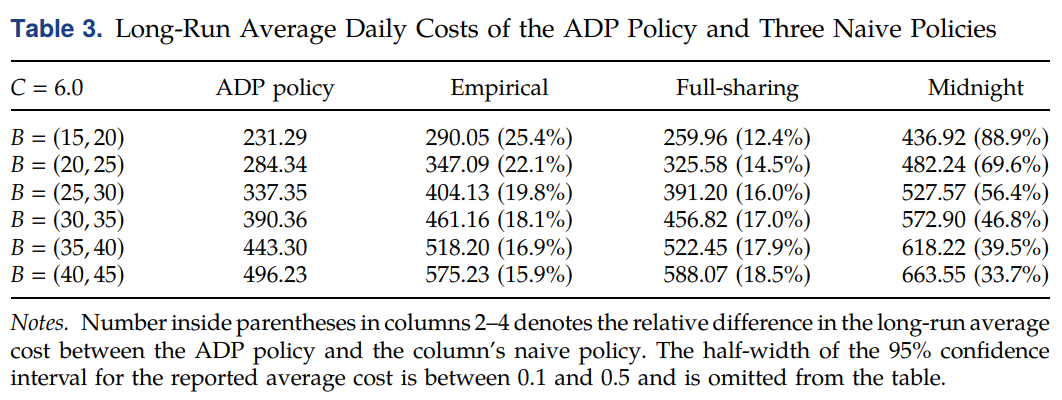
可以发现,(1)ADP策略的效果一般比其它三种策略高出10%~20%,有时甚至能高出30%之多;(2)当溢出成本较低时,ADP策略更像full-sharing策略,而当溢出成本较高时,ADP策略更像empirical或midnight策略。
作者还对其它因素进行了敏感性分析,具体如下表所示( B = ( 30 , 35 ) B=(30,35) B=(30,35)时的情形为Baseline)。
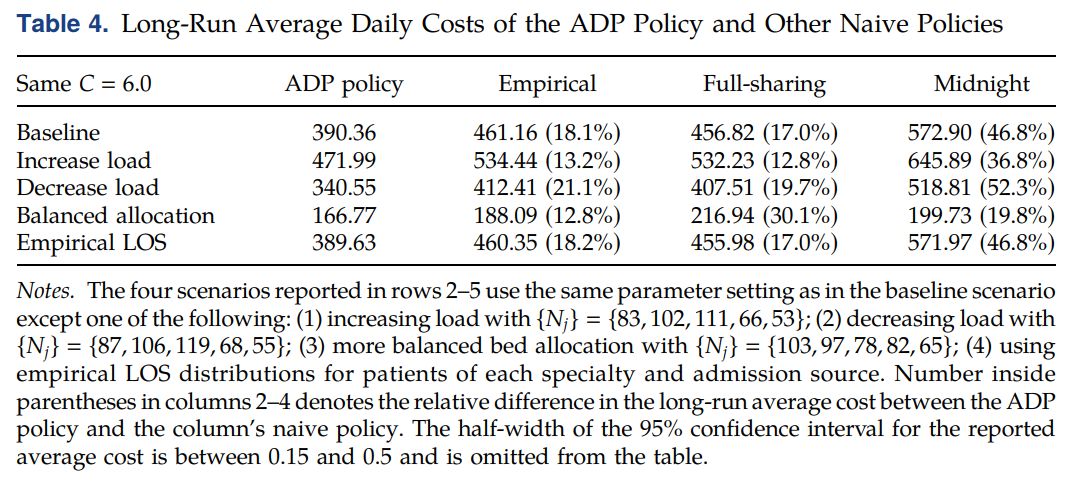
首先是容量(病床数量)的影响。可以发现,当病床数量变少(对应increase load一行),ADP策略的好处似乎变弱了,这是因为ADP主要通过白天的溢出策略来获得优势,而床位变少同时也意味着白天的可用床位数变少,ADP策略难以起作用。而一旦病床数变多(对应decrease load一行),ADP的好处变得明显。
其次是均衡床位数量分配的影响(对应balanced allocation一行)。如果,不同科室的床位数量分配更加合理,ADP的效果就会降低。因为合理的床位数量分配使得溢出的概率下滑。
最后是住院天数带来的影响(对应empirical LOS一行)。在原本的建模中,作者假设LOS服从几何分布。在这里,作者放宽了这一限制,作者将其替换成经验分布。此时,ADP策略仍然取得了理想的效果。且最后的结果与Baseline的结果几乎一致。很重要的原因是几何分布与经验分布差别较小。
作者在附录中还对病床分配的优先级进行了敏感性分析。在Baseline中,作者设置优先级依次为EL,DE,TR。而在Alternative setting 1中,作者设定优先级依次为EL,TR,DE;在Alternative setting 2中,作者设定服务规则为先到先得(FCFS)。与其它三种策略进行对比,结果如下表所示。
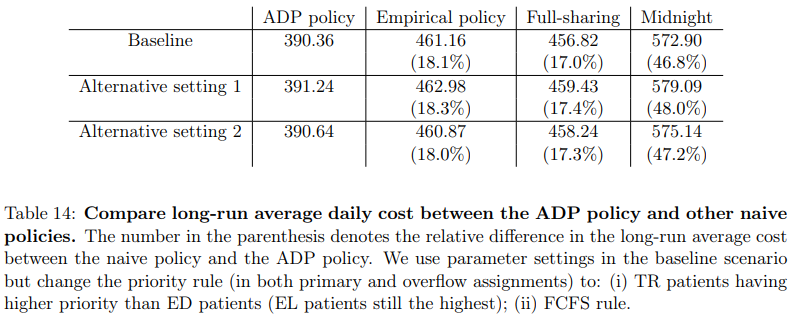
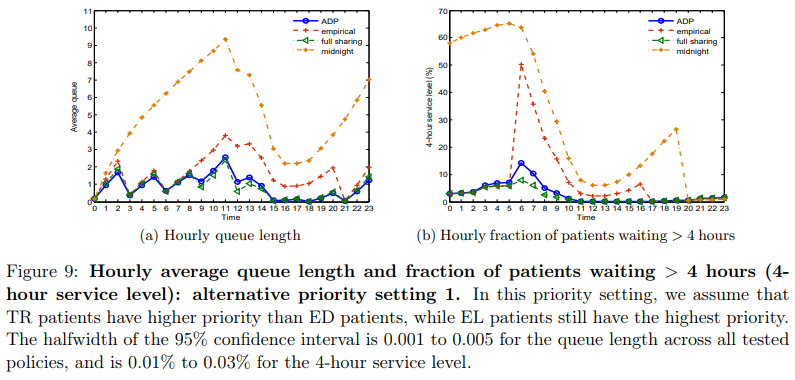
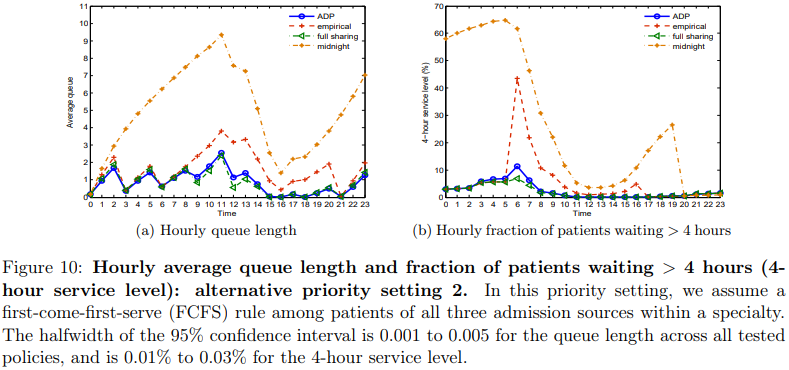
下面两张图片分别展示了这两种优先级设置下,各种分配策略下ED患者的平均排队长度与ED患者等待时间超过4小时的比例。可以发现,ADP策略对优先级设置并不敏感。
7. 总结与讨论
作者将住院的病人流建模为并行多类别多池的排队网络,并把住院病人溢出决策问题表述为离散时间无限时域的平均成本MDP。MDP明确地将时变特征纳入患者到达和出院过程中。为了解决维数诅咒,作者开发了一种基于仿真的ADP算法,其中相对值函数由精心选择的基函数近似。
作者通过大量的数值实验证明,ADP算法在相对现实的设置中可以有效地找到良好的溢出策略,并可以帮助医院管理者设计操作策略以实现预期的性能。敏感性分析还表明,当医院负荷适中且床位分配不完全平衡时,ADP算法获得更大的效益。
作者还提出了如下几个研究局限和未来的研究方向:
- 作者的模型基于离散时间系统,但现实可能更加动态。
- 深入研究作者所提ADP算法在理论上的性能,而作者在本文侧重于算法的数值实验。
- 参数估计。例如研究溢出成本 B i j B_{ij} Bij和持有成本 C j C_j Cj在实际生活中的取值,作者在本文中只是简单地设定了一些取值进行数值实验。
参考文献:
J. G. Dai, Pengyi Shi (2019) Inpatient Overflow: An Approximate Dynamic Programming Approach. Manufacturing & Service Operations Management 21(4):894-911.

![[C++]——带你学习类和对象](https://img-blog.csdnimg.cn/a24cb591144a4a0db98c75e6da32d77e.png)