zookeeper(动物园管理员)是一个广泛应用于分布式服务提供协调服务Apache的开源框架
zookeeper集群特点
- zookeeper集群由一个领导者(Leader)和多个跟随者(Follower)组成。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所 以Zookeeper适合安装奇数台服务器。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,Client能读到最新数据。
本地模式安装
zookeeper由Java开发所有要运行zookeeper需要现安装jdk
安装jdk
可以下载免安装版jdk,解压后配置一下环境变量即可
linux下的环境变量配置文件在
/etc/profile然后在该文件下增加如下配置即可
export JAVA_HOME=/usr/java/jdk-21/jdk-21.0.1 // 我自己的jdk目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
然后从新加载配置文件,命令为
source /etc/profile 查看Java版本

则表示已成功安装Jdk
安装zookeeper
进入zookeeper官网,找到下载页面,下载-bin.tar.gz版即可,如果没有想要的版本则可以在下载页面的存档连接中找到
Apache ZooKeeper
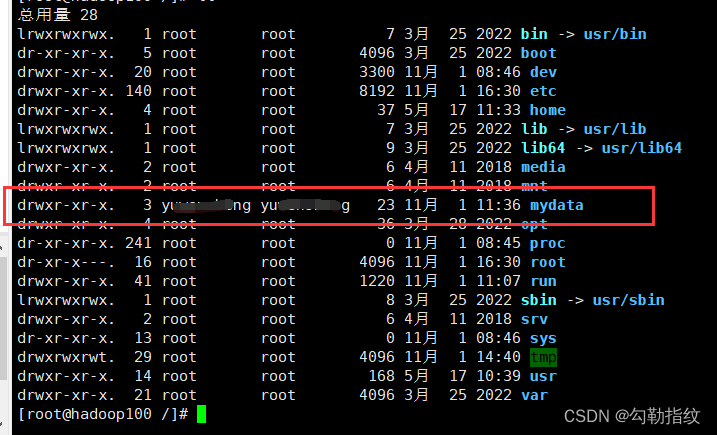
tar -zxvf apache-zookeeper-3.5.7- bin.tar.gz -C /mydata/zookeepermv apache-zookeeper-3.5.7 -bin/ zookeeper-3.5.7配置修改
1、将/mydata/zookeeper/zookeeper-3.5.7/conf这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
mv zoo_sample.cfg zoo.cfg2、打开 zoo.cfg 文件,修改 dataDir 配置的路径 修改为如下内容(默认的tmp路径是临时路径,一段时间后,linux会自动删除里面的文件,所有不适合正式环境使用)
dataDir=/mydata/zookeeper/zookeeper-3.5.7/data
3、在/mydata/zookeeper/zookeeper-3.5.7/这个目录上创建 data文件夹
操作zookeeper
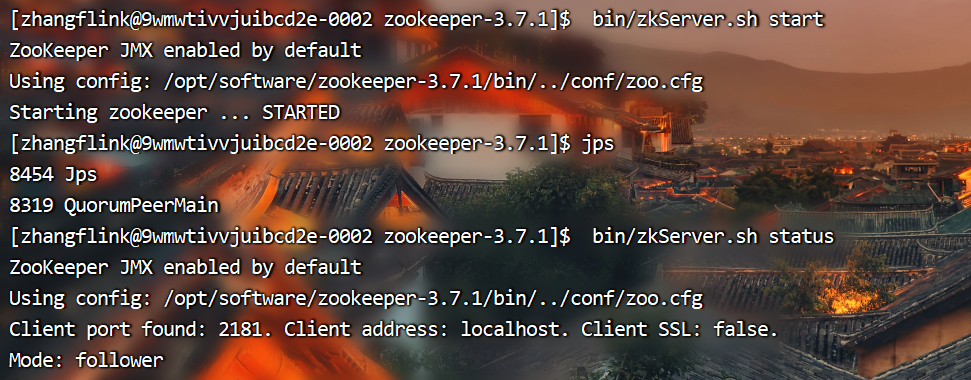
1、启动 Zookeeper

3、查看状态

4、启动客户端
./zkCli.sh
5、退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
6、停止 Zookeeper
.bin/zkServer.sh stop
配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
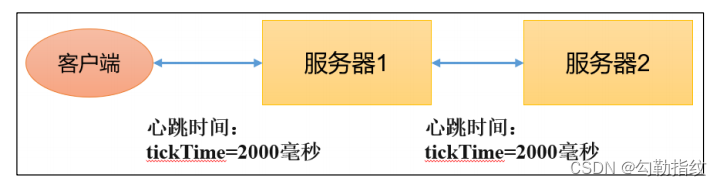

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
3)syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
zookeeper集群搭建
1)集群规划
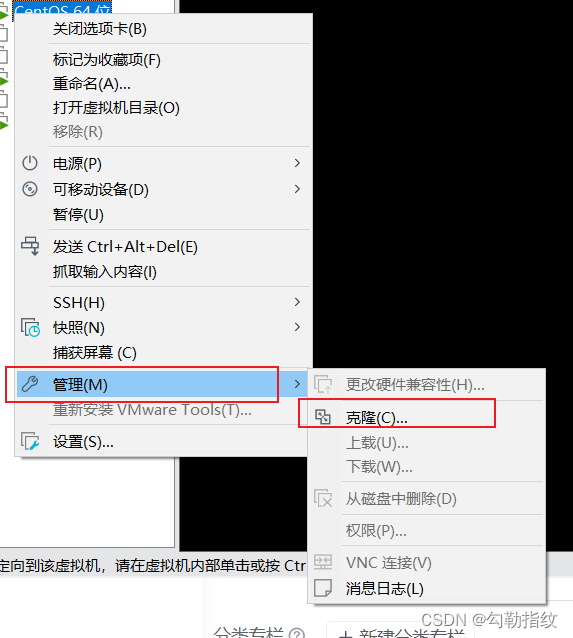
(1)修改克隆虚拟机的静态 IP
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="d7919ed1-15af-49fe-9b4e-aad1456eed3d"
DEVICE="ens33"
ONBOOT="yes"IPADDR=192.168.127.100
# wangGuan
GATEWAY=192.168.127.2
# DNS
DNS1=192.168.127.2
(2)查看 Linux 虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
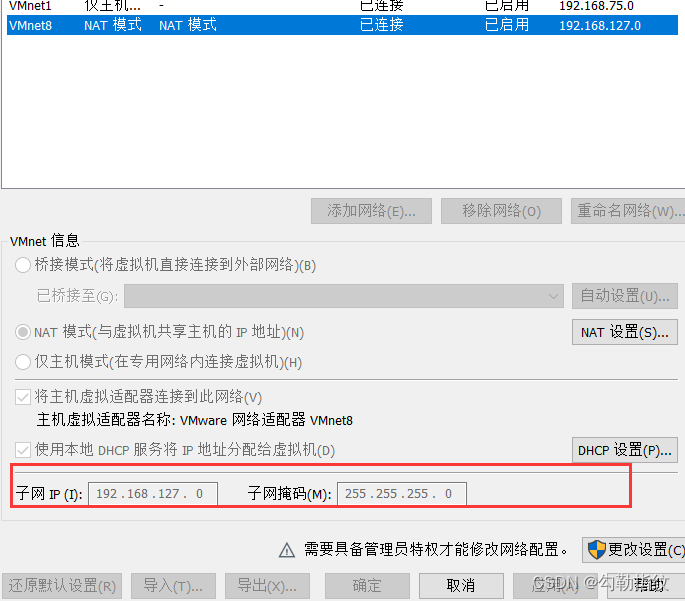
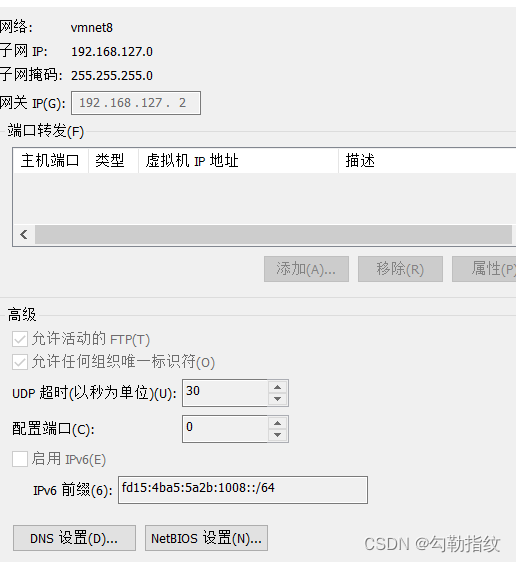
(3)查看 Windows 系统适配器 VMware Network Adapter VMnet8 的 IP 地址

(4)保证 Linux 系统 ifcfg-ens33 文件中 IP 地址、虚拟网络编辑器地址和 Windows 系统 VM8 网络 IP 地址在同一网段。
2)修改克隆机主机名,以下以 hadoop100 举例说明
(1)修改主机名称
vim /etc/hostnamehadoop102
(2)配置 Linux 克隆机主机名称映射 hosts 文件,打开/etc/host
[root@hadoop100 ~]# vim /etc/hosts
192.168.127.100 hadoop100
192.168.127.101 hadoop101
192.168.127.102 hadoop102
192.168.127.103 hadoop103
192.168.127.104 hadoop104
192.168.127.105 hadoop105
192.168.127.106 hadoop106
192.168.127.107 hadoop107
192.168.127.108 hadoop108
192.168.127.132 qingmangmall
3)重启克隆机 hadoop100
[root@hadoop100 ~]# reboot
4)修改 windows 的主机映射文件(hosts 文件)
- (a)进入 C:\Windows\System32\drivers\etc 路径
- (b)打开 hosts 文件并添加如下内容,然后保存
192.168.127.100 hadoop100
192.168.127.101 hadoop101
192.168.127.102 hadoop102
192.168.127.103 hadoop103
192.168.127.104 hadoop104
192.168.127.105 hadoop105
192.168.127.106 hadoop106
192.168.127.107 hadoop107
192.168.127.108 hadoop108
192.168.127.132 qingmangmall
3)集群分发
将zookeeper分发给其他服务
[user@hadoop102 ~]$ sudo chown user:user -R /mydata
[user@ hadoop102 ~]$ scp -r /mydata/zookeeper user@hadoop103:/mydata
100
scp -r /mydata/zookeeper/zookeeper-3.5.7/data user@hadoop103:/mydata/zookeeper/zookeeper-3.5.7
配置zoo.cfg文件
[user@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
[user@hadoop102 conf]$ vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
#######################cluster##########################server.100=hadoop100:2888:3888server.103=hadoop103:2888:3888server.132=qingmangmall:2888:3888
集群操作
[user@hadoop100 zookeeper-3.5.7]$ bin/zkServer.sh start[user@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start[user@qingmangmall zookeeper-3.5.7]$ bin/zkServer.sh start
[user@hadoop100 zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: follower[user@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: leader[user@qingmangmall zookeeper-3.5.7]# bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfgMode: follower
附录
1)创建用户 并设置文件所属组
[root@hadoop100 ~]# useradd user[root@hadoop100 ~]# passwd user
[root@hadoop100 ~]# vim /etc/sudoers
## Allow root to run any commands anywhereroot ALL=(ALL) ALL## Allows people in group wheel to run all commands% wheel ALL=(ALL) ALLuser ALL=(ALL) NOPASSWD:ALL
mkdir /mydata
[root@hadoop100 ~]# chown user:user /mydata