一、哈希表介绍
1、定义
哈希表,也叫散列表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。例如,下列键(key)为人名,value为性别。

2、常用的哈希结构
数组
map(映射)
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
| std::map | 红黑树 | key有序 | key不可以重复 | key不可以修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可以重复 | key不可以修改 | O(logn) | O(logn) |
| std::unordered_map | 哈希表 | key无序 | key不可以重复 | key不可以修改 | O(1) | O(1) |
set(集合)
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
| std::set | 红黑树 | 有序 | 否 | 否 | O(logn) | O(logn) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
2、优缺点及使用场景
优点:高效的查找和插入操作、适用于大数据量、灵活性、快速的删除操作
缺点:空间消耗、不适合有序数据、哈希冲突、依赖好的哈希函数
使用场景:快速查找需求、缓存实现、消除重复元素、分布式系统
3、决定哈希表结构的性能的三个因素:
哈希函数、哈希表的大小、碰撞处理方法。
4、基本操作
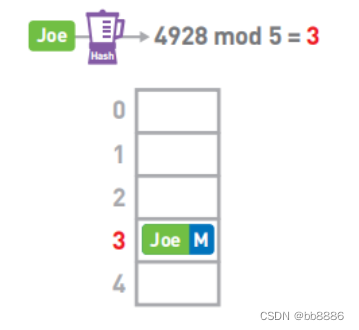
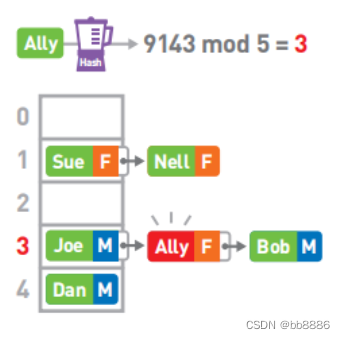
数据存储:假设我们需要存储5个元素,首先使用哈希函数(Hash)计算Joe的键,也就是字符串‘Joe’的哈希值,得到4928,然后将哈希值除以数组长度5(mod运算),求得其余数。因此,我们将Joe的数据存进数组的3号箱子中。
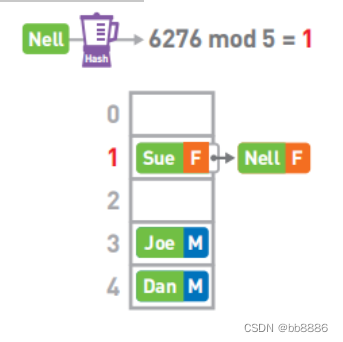
冲突:如果两个哈希值取余的结果相同,我们称这种情况为‘冲突’。假设Nell键的哈希值为6276,mod 5的结果为1。但此时1号箱已经存储了Sue的数据,可使用链表在已有的数据的后面继续存储新的数据。(本方法为链地址法,还有几种解决冲突的方法。其中,应用较为广泛的是“开放地址法”)。
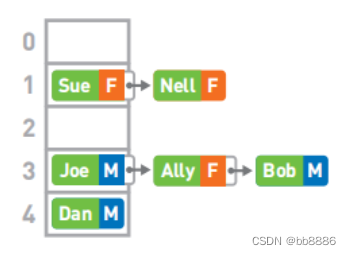
查询:假设最终的哈希表为
如果要查找Ally的性别,首先算出Alley键的哈希值,然后对它进行mod运算。最终结果为3。
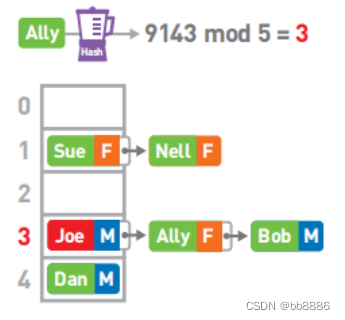
然而3号箱中数据的键是Joe而不是Ally。此时便需要对Joe所在的链表进行线性查找。找到了键为Ally的数据。取出其对应的值,便知道了Ally的性别为女(F)。
二、面试常考的算法
1、在数组中查找对称键值对
题目:给定一个整数对数组,找到所有对称对,即相互镜像的对。
示例:
Input: {3, 4}, {1, 2}, {5, 2}, {7, 10}, {4, 3}, {2, 5}
Output:{4, 3} | {3, 4} ,{2, 5} | {5, 2}
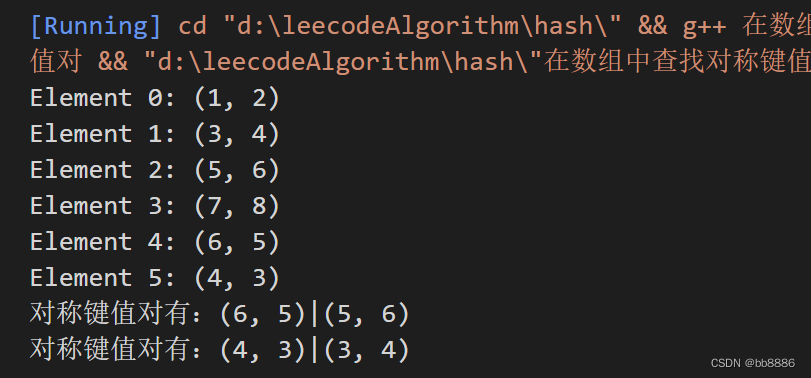
思路:使用一个哈希表map,将数组中第一个元素作为键,第二个元素作为值。遍历数组中的每对元素,对于每对元素,检查反向对是否已经存在于哈希表中。如果存在,说明找到了对称键值对,否则,将当前对插入到哈希表中。
map.find(2) //查找key为2的键值对是否存在 ,若没找到则返回map.end()。
map.end() //指向哈希表的最后一个容器,实则超出了哈希表的范围,为空。
#include<iostream>
#include<map>
#include<unordered_map>
using namespace std;// 查找对称键值对
void has_symmetric_pair(pair<int, int> intPairArray[], int length){unordered_map<int, int> map;for(int i = 0; i < length; i++){int key = intPairArray[i].first;int value = intPairArray[i].second;// 检查反向对是否存在于哈希表中 if (map.find(value) != map.end() && map[value] == key){cout << "对称键值对有:(" << key <<", " << value<< ")|" <<"(" << value << ", " <<key <<")\n";}// 将当前对插入哈希表map[key] = value;}
}int main() {// 创建一个整数对数组pair<int, int> intPairArray[6];int length = 6;// 分别给数组的元素赋值intPairArray[0] = make_pair(1, 2);intPairArray[1] = make_pair(3, 4);intPairArray[2] = make_pair(5, 6);intPairArray[3] = make_pair(7, 8);intPairArray[4] = make_pair(6, 5);intPairArray[5] = make_pair(4, 3);// 访问数组的元素for (int i = 0; i < 6; ++i) {std::cout << "Element " << i << ": (" << intPairArray[i].first << ", " << intPairArray[i].second << ")\n";}has_symmetric_pair(intPairArray, length);return 0;
}
2、追踪遍历的完整路径
题目:使用哈希实现树的遍历路径,输出每个叶子节点的路径。
示例:input:给定一颗树
output:Node 4 Path: 1 -> 2 -> 4 ->
Node 5 Path: 1 -> 2 -> 5 ->
Node 3 Path: 1 -> 3 ->
思路:在DFS的先序遍历中,逐步构建路径,当遇到叶子节点时,将该节点和对应的路径存储在哈希表中。最后,遍历哈希表输出结果。
#include <iostream>
#include <unordered_map>
#include <vector>
using namespace std;struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};unordered_map<TreeNode*, vector<int>> pathMap; void dfs(TreeNode* node, vector<int>& path) {if (node == nullptr) return;path.push_back(node->val);if (node->left == nullptr && node->right == nullptr) {pathMap[node] = path; } else {dfs(node->left, path);dfs(node->right, path);}path.pop_back();
}int main() {TreeNode* root = new TreeNode(1);root->left = new TreeNode(2);root->right = new TreeNode(3);root->left->left = new TreeNode(4);root->left->right = new TreeNode(5);vector<int> path;dfs(root, path);for (auto pair : pathMap) {cout << "Node " << pair.first->val << " Path: ";for (int val : pair.second) {cout << val << " -> ";}cout << endl;}delete root->left->right;delete root->left->left;delete root->left;delete root->right;delete root;return 0;
}

3、查找数组是否是另一个数组的子集
题目:输入两个数组,如果数组1是数组2的元素,则返回True,否则返回False。
示例:input:数组1[3,2,4],数组2[1,2,3,4,5,8] output:数组1是数组2的子集
思路:先将两个数组转换为 set,然后通过遍历第一个集合,检查其中的每个元素是否也在第二个集合中。
if(set2.find(num) != set2.end()) //判断找到了key为2的键值对
#include<set>
#include<iostream>
using namespace std;bool isSubSet(int nums1[], int nums2[], int length1, int length2){set<int> set1, set2;// int length1 = sizeof(nums1) / sizeof(nums1[0]);// int length2 = sizeof(nums2) / sizeof(nums2[0]);for(int i = 0; i < length1; i++){set1.insert(nums1[i]);}for(int j = 0; j < length2; j++){set2.insert(nums2[j]);}for(int num: set1){if(set2.find(num) == set2.end()){return false;}}return true;
}int main(){int nums1[] = {3, 2, 4};int nums2[] = {1, 2, 3, 4, 5, 8};int length1 = sizeof(nums1) / sizeof(nums1[0]);int length2 = sizeof(nums2) / sizeof(nums2[0]);bool result = isSubSet(nums1,nums2, length1, length2);if (result) {cout << "arr1 is a subset of arr2" << std::endl;} else {cout << "arr1 is not a subset of arr2" << std::endl;}}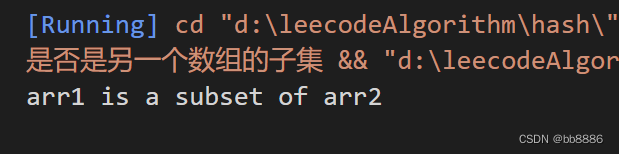
4、检查给定的数组是否不相交
题目:输入两个数组,如果数组1与数组2相交,则返回True,否则返回False。
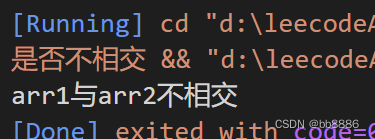
示例:input:数组1[9],数组2[3,2] output:数组1与数组2不相交。
思路:先将两个数组转换为set,然后使用set_intersection 函数找到它们的交集。如果交集为空,则数组不相交。
std::set_intersection是 C++ 标准库<algorithm>头文件中的一个函数,它用于求两个已排序容器(比如集合或数组)的交集。函数声明如下:
template<class InputIt1, class InputIt2, class OutputIt>
OutputIt set_intersection(InputIt1 first1, InputIt1 last1, InputIt2 first2, InputIt2 last2, OutputIt d_first);
first1, last1: 第一个容器的起始和结束迭代器。first2, last2: 第二个容器的起始和结束迭代器。d_first: 结果输出的目标容器的起始迭代器。
#include<iostream>
#include<set>
#include<algorithm>
using namespace std;
bool areDisjoint(int arr1[], int arr2[], int length1, int length2){set<int> set1, set2;for(int i = 0; i < length1; i++){set1.insert(arr1[i]);}for(int j = 0; j < length2; j++){set2.insert(arr2[j]);}// 同检查数组是否是另一个数组的子集// for(auto c: set1){// if(set2.find(c) != set2.end()){// return true;// }// }// return false;// 利用集合的交集来求set<int> intersection;set_intersection(set1.begin(), set1.end(), set2.begin(), set2.end(), inserter(intersection, intersection.begin()));if (intersection.empty()){return false;}return true;
}int main(){int arr1[] = {9};int arr2[] = {3, 2};int length1 = sizeof(arr1) / sizeof(arr1[0]);int length2 = sizeof(arr2) / sizeof(arr2[0]);bool res = areDisjoint(arr1, arr2, length1, length2);if (res){cout << "arr1与arr2相交";}else{cout << "arr1与arr2不相交";}
}

![[量化投资-学习笔记006]Python+TDengine从零开始搭建量化分析平台-MACD](https://img-blog.csdnimg.cn/a18d7d7ca1434c2c9fcf30a2da2f7072.png#pic_center)