文章目录
- 一、概念
- 二、实现方案
- 三、代码
一、概念
ReID,也就是 Re-identification,其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。
说白了,在监控拍不到人脸的情况下,ReID可以代替人脸识别来在视频序列中找到我要找到目标对象。那么他的应用就很广了,可以做安防,可以做个人定位,在商场上可以配合推荐系统,搭建出个性化的推荐服务等等。下面一张图可以生动的解释它在安防的一个应用场景。

ReID的概念最早在2006年的CVPR会议上被提出。2007年首个ReID数据集VIPeR被公布,之后越来越多的不同场景下的数据集先后被开源了出来,这些数据集也一定程度上推动了ReID的发展。
在2015年左右,深度学习还没有大热大火之前,ReID的研究大部分都是基于的特征的阶段,对于人工特征,如颜色、HOG特征等,之后的度量学习是寻找特征之间的最佳近似度,但这种方法学习复杂的场景数据效果不佳。随着AlphaGo取得令人瞩目的成就,以及最新硬件支持技术的发展也带来了深度学习的高产阶段,深度学习也逐渐渗透到人工智能的各个方面,包括ReID,利用深度学习的方法可以很好的学习出黑盒性质的特征,在一些方面可以超过了人类的识别水平,因而深度学习在CV中的应用已成为相关研究者关注的热点。
2017年和2018年ReID得到快速发展,在国内外各类顶级计算机视觉会议和顶级期刊上每年都有多篇ReID的文章。迁移学习的火热也使得在大数据量和算力下训练好的模型可以作为网络的初始化,使得网络的性能大大改善。对抗生成网络的出现也给ReID带来了新道路;虽然目前来说,ReID主流的方法仍然属于监督学习,但是迁移学习以及GAN网络也将是一个很有前景的方向。
二、实现方案
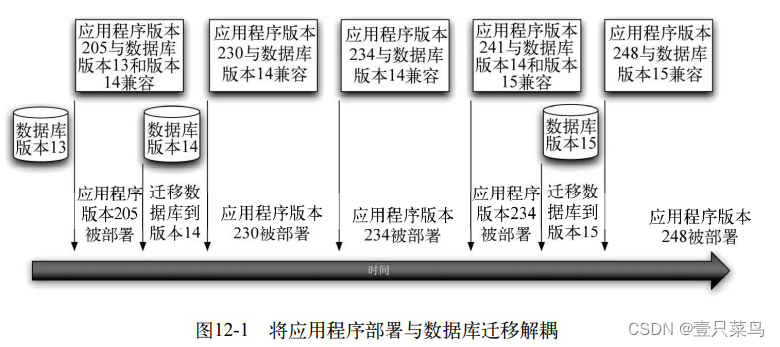
person-reid 又简称 reid,是旨在用来从图片序列或视频中检索行人的技术。可总体划分为以下5步:
- 原始数据采集: 主要来自于监控摄像头
- 行人框生成: 将图片中的行人裁剪出来,可通过人工或使用行人检测算法
- 训练数据标注: 可能包含行人属性、相机等,对于新场景,一般需要重新标注
- 模型训练: 模型集中于特征表示学习、距离度量学习或者二者的组合
- 行人检索: 给定 query(感兴趣的行人) 和 gallery 集合,用训练得到的模型抽取各自的特征表达,然后计算 query 和 gallery 中每个行人的相似度进行排序.
论文中将ReID技术分为 Closed-world 和Open-world 两大子集 , 本文主要记录 closed-world 的reid, 即常见的标注完整的有监督的行人重识别方法.
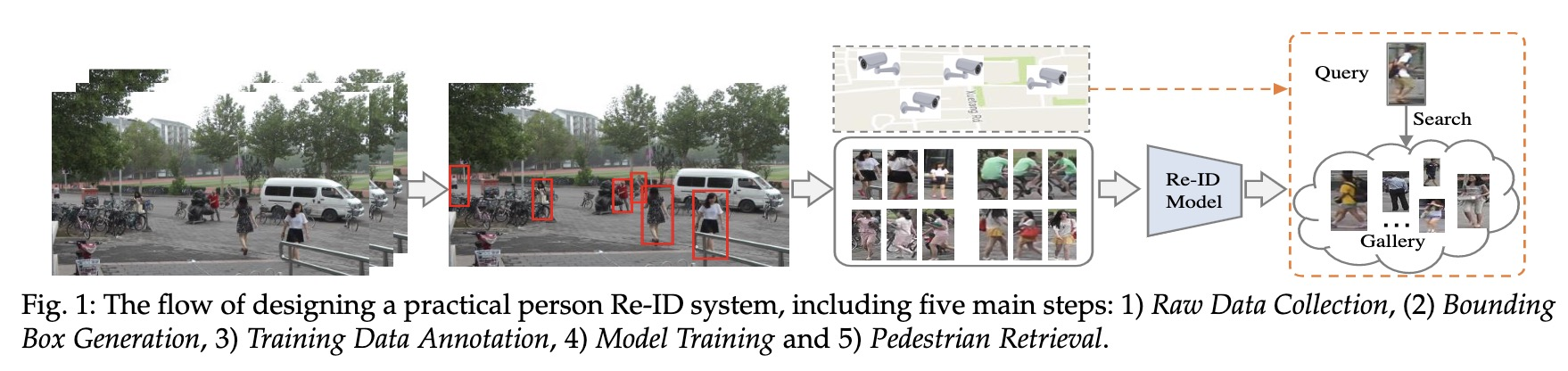
从前面讲的,我们已经大致知道ReID是干什么的了,似乎就是去检索出一个目标对象。这里我会具体去讲这个任务如何去做。

上面这张图向我们展示了ReID的一个任务过程
- 首先要做的是Detection,也就是检测出行人,其实这一步数据集已经帮我们做到了,下面介绍数据集的时候会讲到不同数据集采用的不同的目标检测方法以及ID的标注方式。
- 剩下的部分,就是要去训练一个特征提取网络,根据特征所计算的度量距离得到损失值
- 我们选用一个优化器去迭代找到loss最小值,并不断更新网络的参数达到学习的效果。
- 在测试的时候,我们用将要检索的图片(称为query或者probe),在底库gallery中,根据计算出的特征距离进行排序,选出最TOP的几张图片,来达到目标检索的目的。下面两张图分别是训练阶段和测试阶段的示意图:

测试阶段中,我们利用训练后的网络计算特征从所有搜索到的图像中提取特征,并计算搜索图与地库之间的特征距离。然后根据计算出的距离对它们进行排序。排名越高,相似性越高,上图中,绿色边框的是正确检索的结果,红色边框的是错误检索的结果。
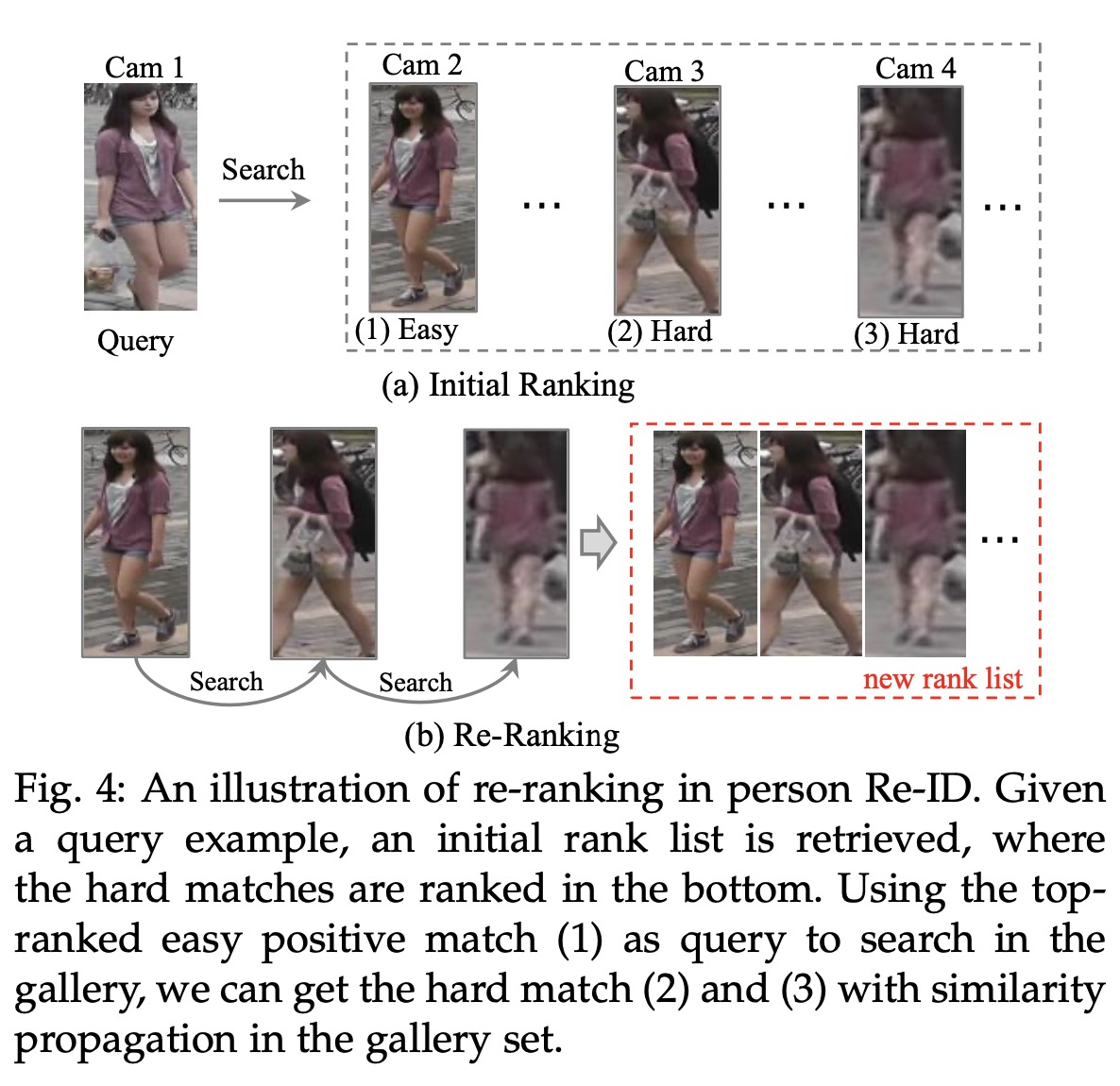
用学习好的reid特征得到初始的检索排序结果后,利用图片之间的相似性关系来进行初始的检索结果优化,主要有:
- re-rank
- rank-fusion
三、代码
import numpy as np
import jsonwith open('gallery.json', 'r') as res_lst:gallery = res_lst.readlines()
with open('query.json', 'r') as res_lst:query = res_lst.readlines()if __name__ == '__main__':for idx1, res1 in enumerate(query):res1_dic = json.loads(res1)vector1 = res1_dic['data']max_smi = 0max_target_idx = -1for idx2, res2 in enumerate(gallery):res2_dic = json.loads(res2)vector2 = res2_dic['data']# 计算向量的内积dot_product = np.dot(vector1, vector2)# 计算向量的模长norm1 = np.linalg.norm(vector1)norm2 = np.linalg.norm(vector2)# 计算余弦相似度similarity = dot_product / (norm1 * norm2)if similarity > max_smi:max_smi = similaritymax_target_idx = idx2print('idx1={},max_target_idx={},max_smi={}'.format(idx1, max_target_idx, max_smi))
若两个向量完全相同,则其余弦相似度接近 1