Springboot使用pdfbox提取PDF图片
- PDFBox的介绍
- Springboot集成PDFBox
- 一、提取pdf首页为图像
- 1. 实现需求
- 2. 项目代码
- 3. 执行结果
- 二、将pdf内容全部转换为图像
- 1. 实现需求
- 2. 项目代码
- 3. 执行结果
- 4.注意事项
- 1.优化项目代码
- 2.提升Java heap size
PDFBox的介绍
PDFBox是一个用于创建和处理PDF文档的Java库。它可以使用Java代码创建、读取、修改和提取PDF文档中的内容。
PDFBox的功能:
Extract Text - 使用PDFBox,您可以从PDF文件中提取Unicode文本。
Split & Merge - 使用PDFBox,您可以将单个PDF文件分成多个文件,并将它们合并为一个文件。
Fill Forms - 使用PDFBox,您可以在文档中填写表单数据。
Print - 使用PDFBox,您可以使用标准Java打印API打印PDF文件。
Save as Image - 使用PDFBox,您可以将PDF保存为图像文件,如PNG或JPEG。
Create PDFs - 使用PDFBox,您可以通过创建Java程序创建新的PDF文件,还可以包含图像和字体。
Signing - 使用PDFBox,您可以将数字签名添加到PDF文件。
Springboot集成PDFBox
本项目除了引入pdfbox的依赖之外,还引入了解决图像问题的其他依赖。
例如:jai-imageio-jpeg2000和jai-imageio-core是为了解决在转换图像时报错:Cannot read JPEG2000 image: Java Advanced Imaging (JAI) Image I/O Tools are not installed
jbig2-imageio依赖引入是为了解决使用pdfbox2.0将PDF转换为图片时后台报Cannot read JBIG2 image: jbig2-imageio is not installed错误
<!-- pdf提取封面依赖-->
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.22</version>
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-tools</artifactId><version>2.0.22</version>
</dependency>
<dependency><groupId>org.apache.pdfbox</groupId><artifactId>jbig2-imageio</artifactId><version>3.0.2</version>
</dependency>
<!-- 解決提取pdf "Cannot read JPEG2000 image"封面失败问题 -->
<dependency><groupId>com.github.jai-imageio</groupId><artifactId>jai-imageio-core</artifactId><version>1.3.1</version>
</dependency>
<dependency><groupId>com.github.jai-imageio</groupId><artifactId>jai-imageio-jpeg2000</artifactId><version>1.3.0</version>
</dependency>
一、提取pdf首页为图像
1. 实现需求
单个或者批量提取pdf的首页作为封面,或者可以实现提取指定pdf页为图像
2. 项目代码
核心工具类方法:PdfUtils.getPdfFirstImage
package com.zhouquan.utils;import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.IOException;/*** @author ZhouQuan* @desciption pdf工具类* @date 2023/6/17 9:52*/
@Slf4j
public class PdfUtils {/*** 提取pdf首页作为封面** @param pdfFile* @param dpi the DPI (dots per inch) to render at* @return*/public static BufferedImage getPdfFirstImage(File pdfFile, float dpi) {long startTime = System.currentTimeMillis();if (!pdfFile.isFile() || !pdfFile.exists()) {return null;}try (PDDocument document = PDDocument.load(pdfFile)) {PDFRenderer pdfRenderer = new PDFRenderer(document);// 设置页数(首页从0开始)、每英寸点数、图片类型BufferedImage bufferedImage = pdfRenderer.renderImageWithDPI(0, dpi, ImageType.RGB);log.info("提取耗时:{}ms", System.currentTimeMillis() - startTime);return bufferedImage;} catch (Exception e) {log.error(e.getMessage());e.printStackTrace();return null;}}
}
service方法类,负责将读取的pdf的bufferedImage对象写入指定的图片对象中
package com.zhouquan.service.impl;import com.zhouquan.service.PdfService;
import com.zhouquan.utils.PdfUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.apache.pdfbox.tools.imageio.ImageIOUtil;
import org.springframework.stereotype.Service;import java.awt.image.BufferedImage;
import java.io.File;/*** @author ZhouQuan* @desciption pdf提取相关类* @date 2023/6/17 9:40*/
@Slf4j
@Service
public class PdfServiceImpl implements PdfService {/*** 提取封面的存放路径*/private static String coverPath = "D:/pdf_test/cover";/*** 提取封面的文件后缀*/private static final String coverExt = "png";/*** pdf 提取封面** @param pdfFile pdf文件*/@Overridepublic void pickupCover(File pdfFile) {//要渲染的DPI(每英寸点数),可以理解为生成图片的清晰度,值越高生成质量越高int dpi = 300;try {//提取封面工具类BufferedImage bufferedImage = PdfUtils.getPdfFirstImage(pdfFile, dpi);//获取pdf文件名String fileName = FilenameUtils.getBaseName(pdfFile.getName());String currentCoverPath = coverPath + "/" + fileName + "." + coverExt;// 创建图片文件对象FileUtils.createParentDirectories(new File(currentCoverPath));// 将图片写入到图片对象中ImageIOUtil.writeImage(bufferedImage, currentCoverPath, dpi);byte[] coverByte = PdfUtils.bufferedImageToByteArray(bufferedImage);log.info("提取封面大小为: {}MB", String.format("%.2f", coverByte.length / 1024 / 1024.0));} catch (Exception e) {log.error(e.getMessage());}}
}
测试类
package com.zhouquan;import com.zhouquan.service.PdfService;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import javax.annotation.Resource;
import java.io.File;@SpringBootTest
public class PdfTests {@Resourcepublic PdfService pdfService;/*** 提取单个文件封面*/@Testpublic void pickupCover() {String pdfFilePath = "D:/pdf_test/pdf/三体三部曲-刘慈欣.pdf";pdfService.pickupCover(new File(pdfFilePath), 0);}/*** 批量单个文件封面*/@Testpublic void batchPickupCover() {String pdfFilePath = "E:/开发项目/h化工出版社/opt";File[] files = new File(pdfFilePath).listFiles();if (files != null && files.length > 0) {for (File file : files) {pdfService.pickupCover(file, 0);}}}
}
3. 执行结果
1.单本pdf提取封面
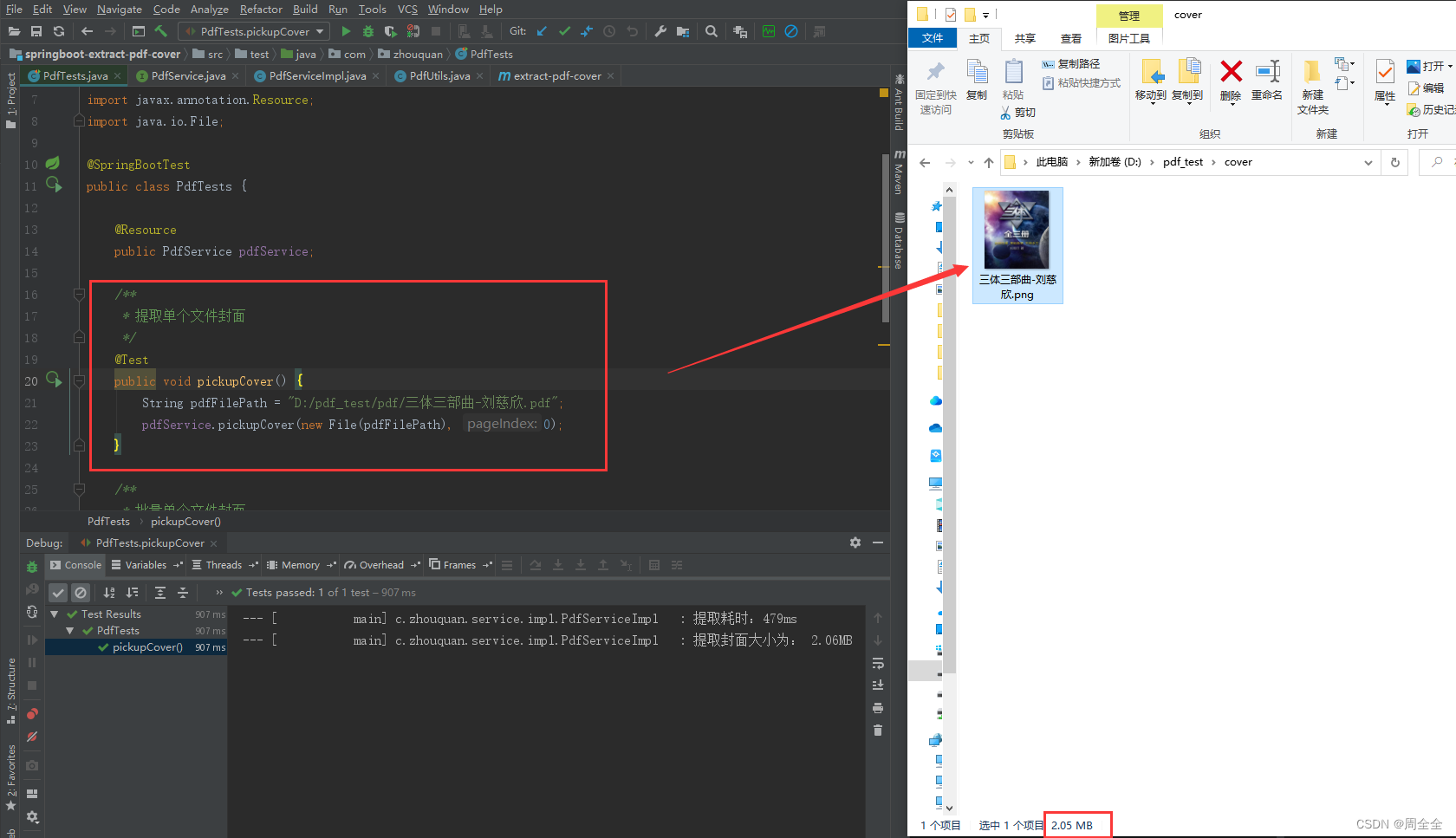 2.批量提取pdf封面
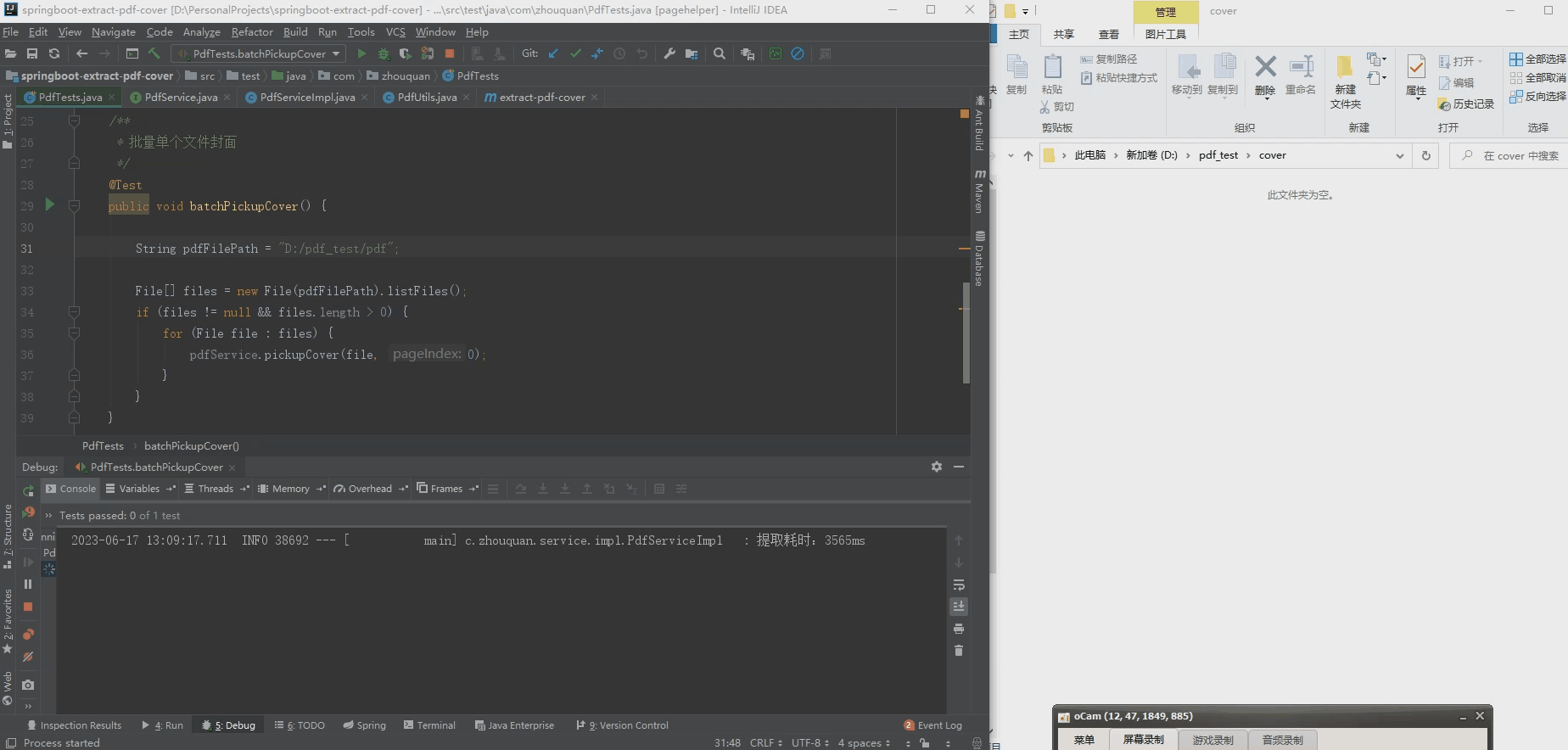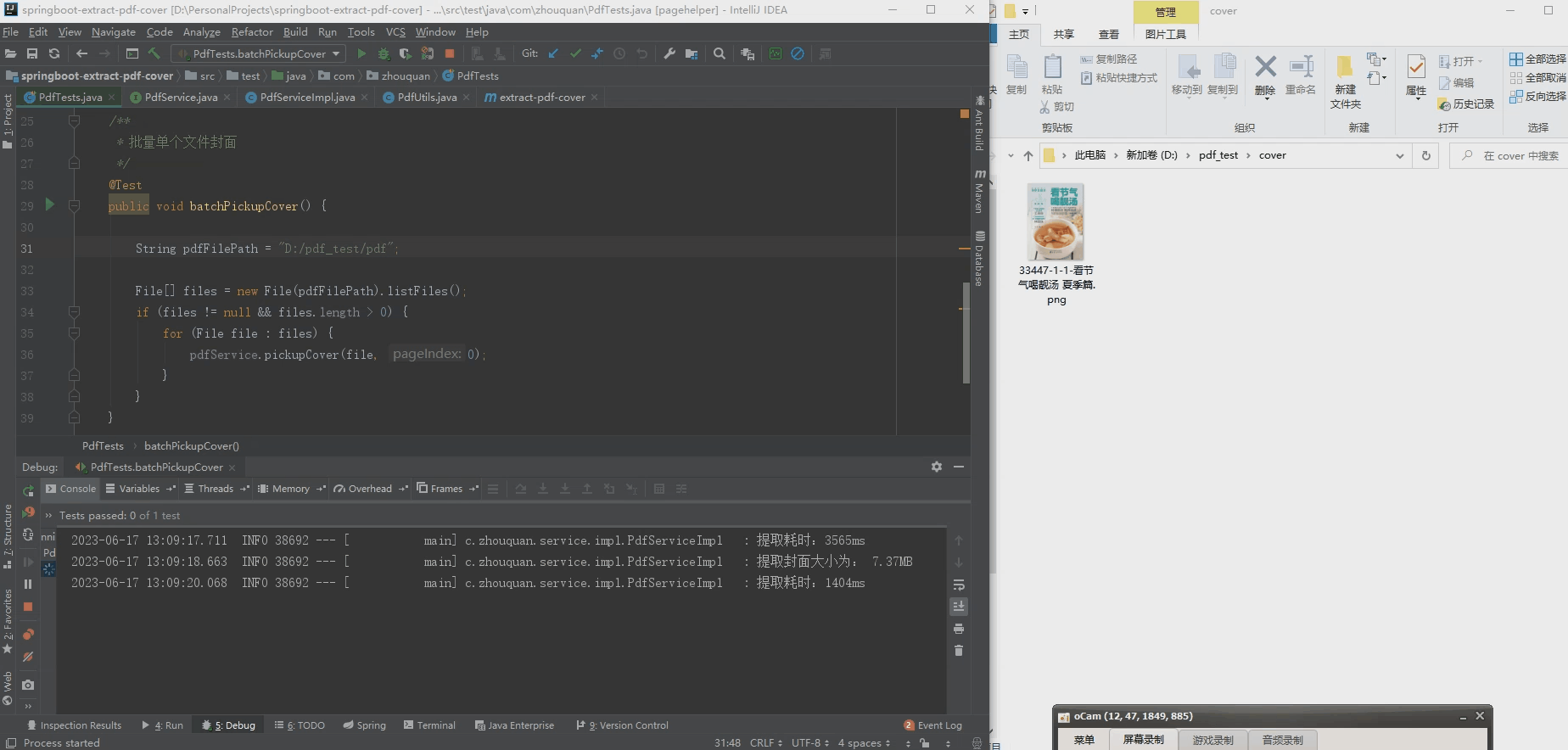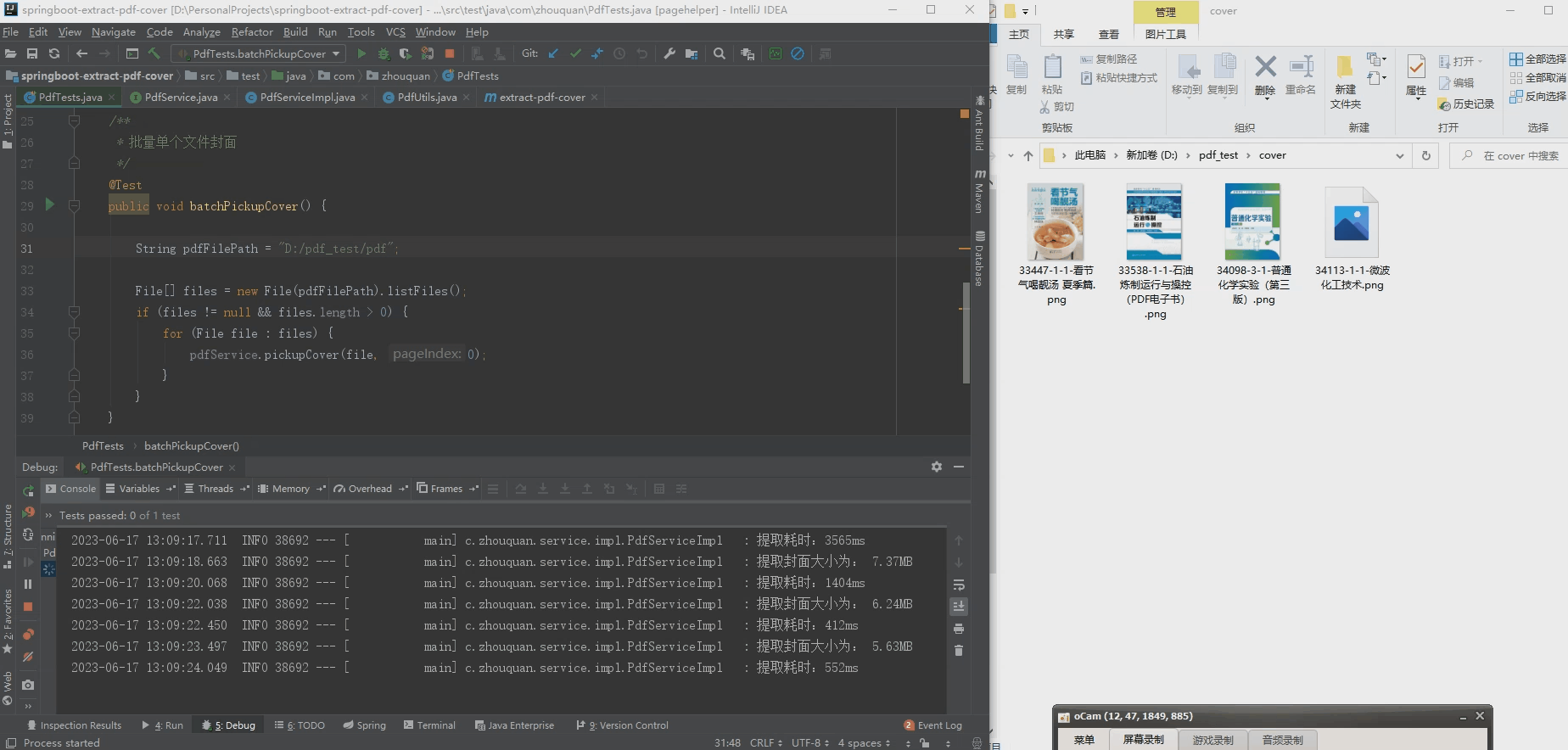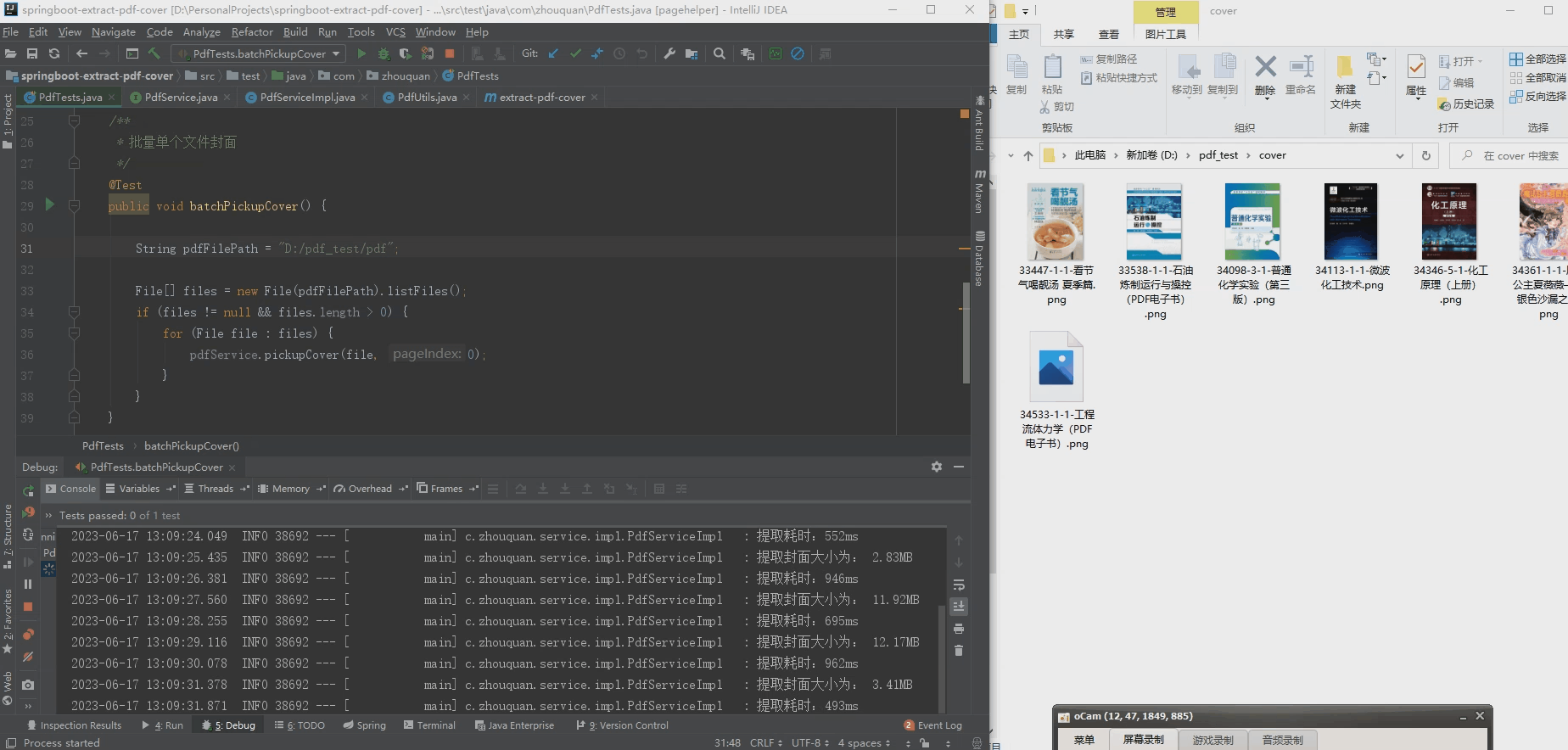
2.批量提取pdf封面
二、将pdf内容全部转换为图像
1. 实现需求
将pdf中所有的页转换为图片
2. 项目代码
核心工具类方法:PdfUtils.getPdfAllImage
/*** 加载读取pdf并返回所有的BufferedImage对象** @param pdfFile pdf文件对象* @param dpi the DPI (dots per inch) to render at* @return*/public static List<BufferedImage> getPdfAllImage(File pdfFile, float dpi) {if (!pdfFile.isFile() || !pdfFile.exists()) {return null;}//创建PDFDocument对象并加载PDF文件try (PDDocument document = PDDocument.load(pdfFile)) {//创建一个PDFRenderer对象并将PDDocument对象传递给它PDFRenderer pdfRenderer = new PDFRenderer(document);List<BufferedImage> bufferedImages = new ArrayList<>();BufferedImage bufferedImage;for (int pageIndex = 0; pageIndex < document.getNumberOfPages(); pageIndex++) {System.out.println("pageIndex:" + pageIndex);// 设置页数(首页从0开始)、每英寸点数、图片类型bufferedImage = pdfRenderer.renderImageWithDPI(pageIndex, dpi, ImageType.RGB);bufferedImages.add(bufferedImage);}return bufferedImages;} catch (Exception e) {log.error(e.getMessage());e.printStackTrace();return null;}}
service方法类,负责将读取的pdf的bufferedImage列表对象按顺序写入指定目录的图片文件中
@Overridepublic void pickupPdfToImage(File pdfFile) {//要渲染的DPI(每英寸点数),可以理解为生成图片的清晰度,值越高生成质量越高int dpi = 100;try {//提取封面工具类List<BufferedImage> pdfAllImage = PdfUtils.getPdfAllImage(pdfFile, dpi);log.info("共提取到{}页",pdfAllImage.size());String fileName = FilenameUtils.getBaseName(pdfFile.getName());String currentCoverPath;for (int i = 0; i < pdfAllImage.size(); i++) {currentCoverPath = coverPath + "/" + fileName + " 第" + i + "页" + "." + coverExt;// 创建图片文件对象FileUtils.createParentDirectories(new File(currentCoverPath));// 将图片写入到图片对象中ImageIOUtil.writeImage(pdfAllImage.get(i), currentCoverPath, dpi);}} catch (Exception e) {log.error(e.getMessage());}}
测试类
/*** 批量提取文件封面*/@Testpublic void pickupPdfToImage() {String pdfFilePath = "D:/pdf_test/pdf/三体三部曲-刘慈欣.pdf";pdfService.pickupPdfToImage(new File(pdfFilePath));}
3. 执行结果
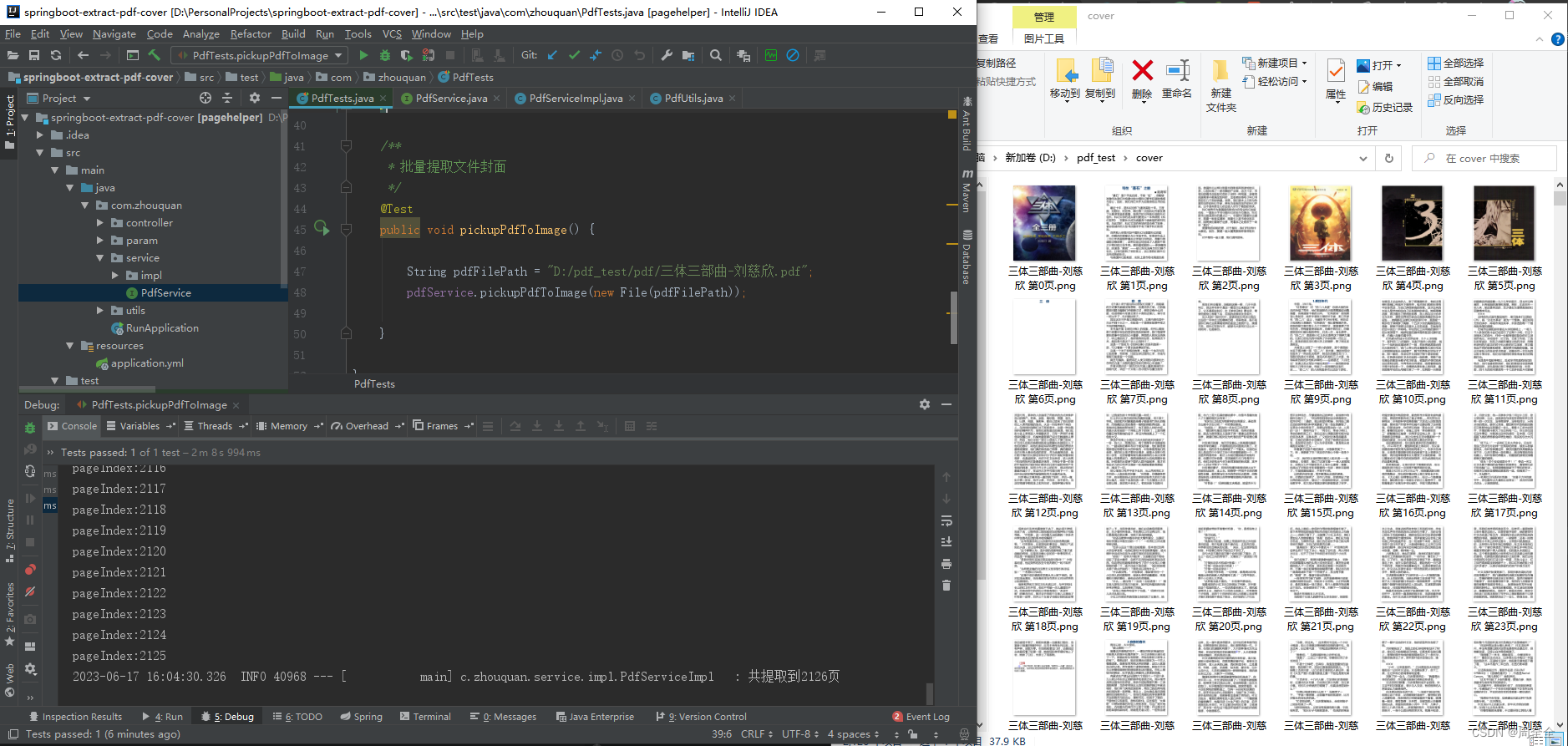
4.注意事项
由于pdf的提取是将pdf文件加载到堆内存中进行操作,因此在提取过程中容易导致堆内存溢出Java heap space,简单来说就是在创建新的对象时, 堆内存中的空间不足以存放新创建的对象,导致此种问题的发生。
解决方案如下:
1.优化项目代码
根据报错信息定位到内存消耗较大的代码,然后对其进行重构或者优化算法。如果是在生产环境,务必要在内存消耗过大的代码出增加日志信息输出,否则容易像我定位一晚上才找到问题所在
2.提升Java heap size
增加堆内存空间设置,此种方式容易操作。可以较快解决当前问题,但是总体来说还是需要找到项目代码中的问题才是最优解,毕竟内存总是有限的
根据自己的硬件配置进行分配对空间,例如8G内存配置的内存参数:
-Xms4096m
-Xmx4096m
关于pdfbox比较好的学习文档:
https://iowiki.com/pdfbox/pdfbox_overview.html