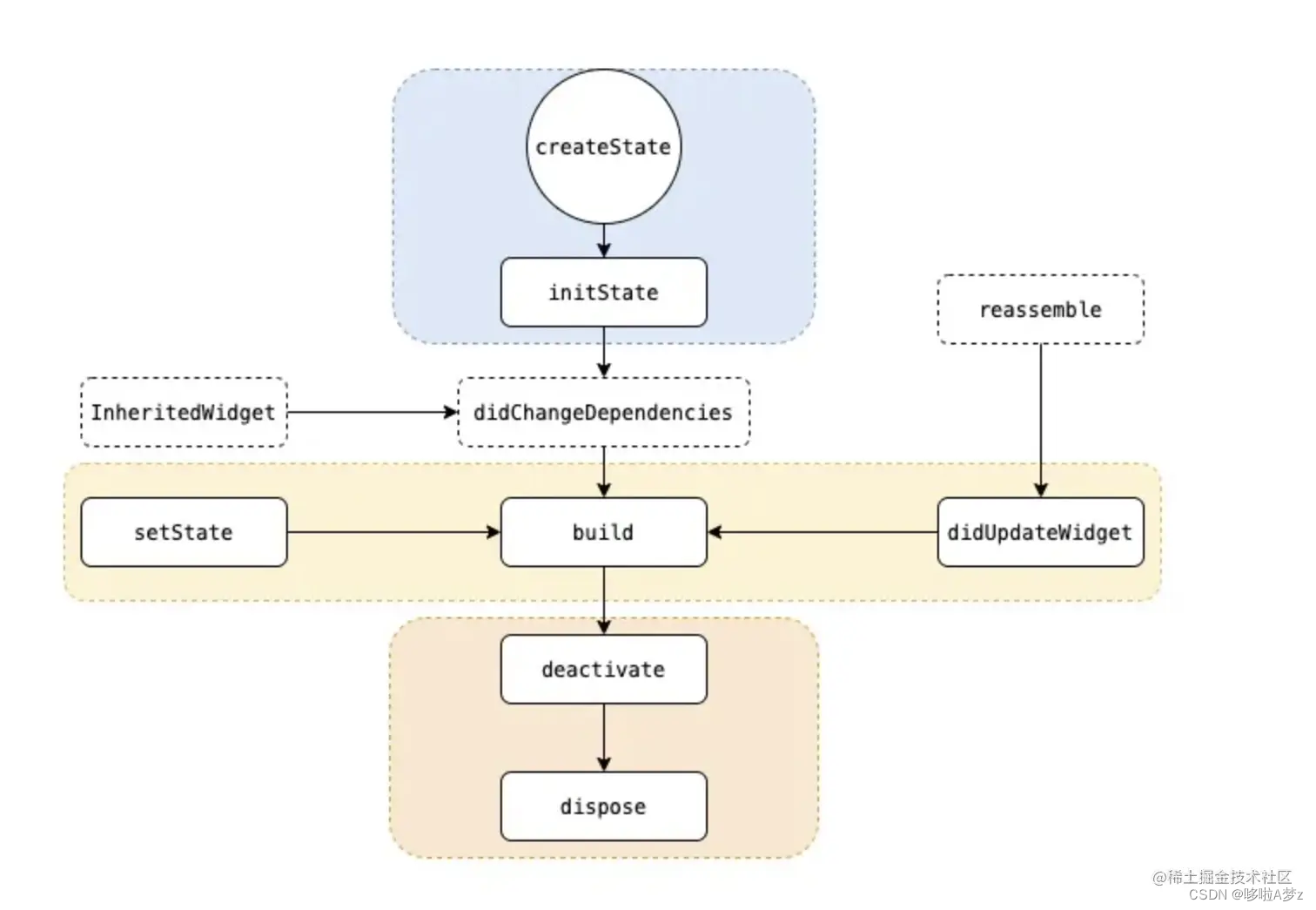
A2Attention的核心思想是首先将整个空间的关键特征收集到一个紧凑的集合中,然后自适应地将其分布到每个位置,这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。第一级的注意力集中操作有选择地从整个空间中收集关键特征,而第二级的注意力集中操作采用另一种注意力机制,自适应地分配关键特征的子集,这些特征有助于补充高级任务的每个时空位置。整体结构如下图所示。
论文地址:https://arxiv.org/pdf/1810.11579.pdf
代码仓库:https://github.com/pijiande/A2Net-DoubleAttentionlayer
模型结构
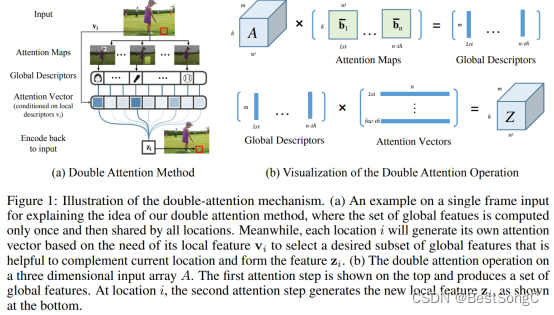
Double Attention Block的整体结构图如下所示:
Double Attention Block的整体结构分为Feature Gathering和Feature Distribution,整体结构还是整齐简单的,这两个模块分别包含维度减少(Dimention Reduction)
、卷积(Convolution)、Sofemax层、池化层(Bilinear Pooling)和矩阵相乘(Matrix Multiplication)操作。
实现代码
YOLOv5模型改进
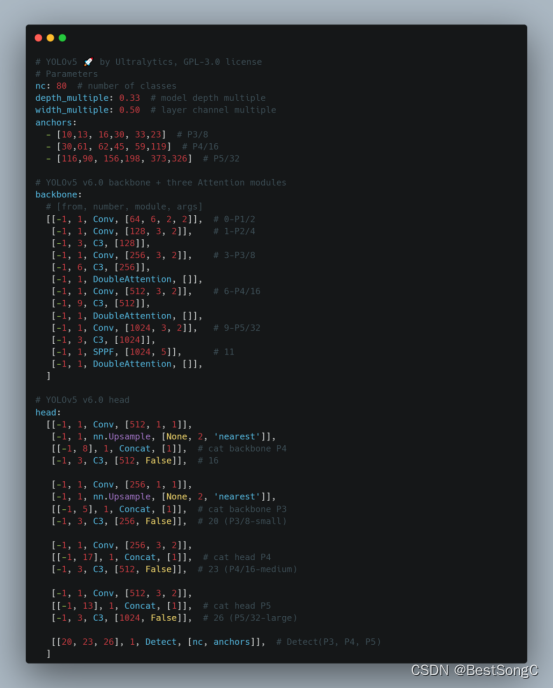
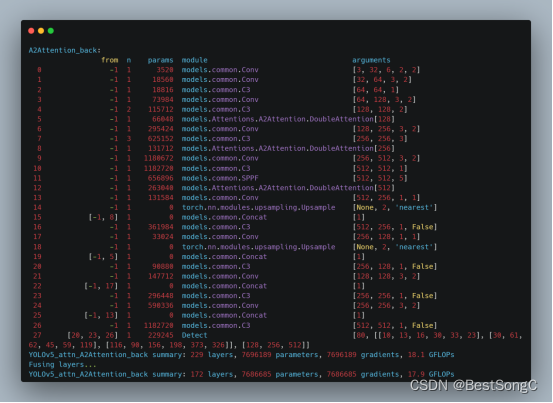
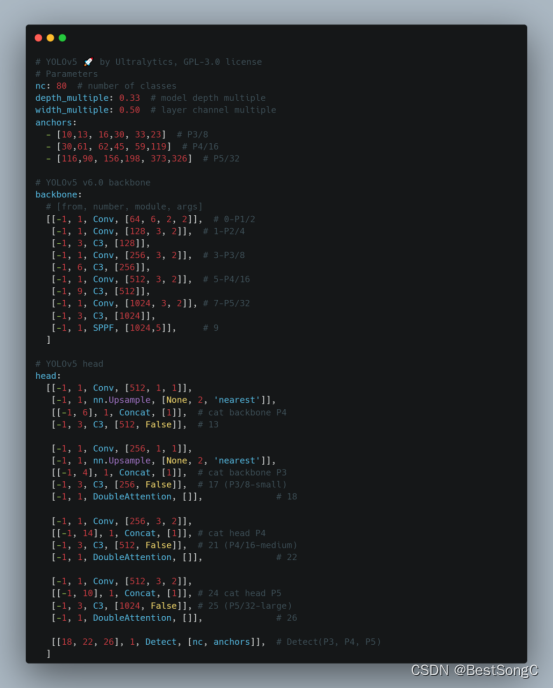
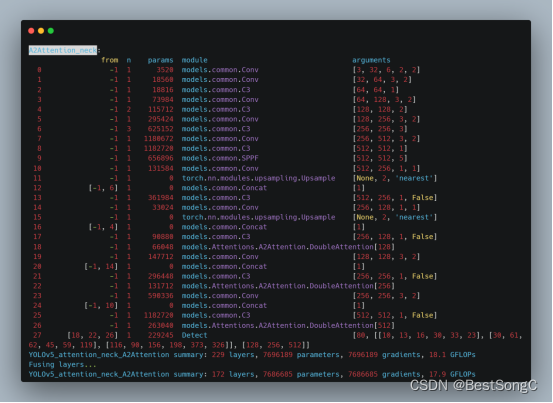
本文在YOLOv5目标检测算法的Backbone和Head部分分别加入DoubleAttention来增强目标提取能力,以下分别是在Backbone以及Head中改进的模型结构和参数(以YOLOv5s为例)。
在Backbone部分
在Head部分
总结
A2Attention首先将整个空间的关键特征收集到一个紧凑的集合中,然后自适应地将其分布到每个位置,这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。此外,DoubleAttention可进一步应用于YOLOv7、YOLOv8等模型中,欢迎大家关注本博主的微信公众号 BestSongC,后续更多的资源如模型改进、可视化界面等都会在此发布。另外,本博主最近也在MS COCO数据集上跑了一些YOLOv5的改进模型,实验表明改进后的模型能在MS COCO 2017验证集上分别涨点1-3%,感兴趣的朋友关注后回复YOLOv5改进
![[SHCTF]web方向wp](https://img-blog.csdnimg.cn/155b18c2a92044c180fda0db701850fb.png)