文章目录
- 摘要
- 引言
- 算法
- 多模态语言建模
- 图像解码器对齐
- 微调instruction
- 实验
- 结论
论文: 《Kosmos-G: Generating Images in Context with Multimodal Large Language Models》
github: https://github.com/microsoft/unilm/tree/master/kosmos-g
摘要
当前text-to-image、vision-language-to-image已经取得不错进展,但对于多张图输入仍有待探索。本文提出KOSMOS-G,使用多模态大语言模型(MLLM)能力处理上述挑战。通过文本模态作为anchor,将MLLM与CLIP输出空间对齐,通过组合引导指令进行调优模型。KOSMOS-G证明一种独特zero-shot多群体目标驱动生成能力;instruction微调不需要更改图像解码器,因此可无缝替换CLIP,容易与UNET技术相结合。KOSMOS-G尝试在图像生成中将图像看做一种语言输入。
引言
MLLM优势:
1、内在的视觉-语言对齐;
2、其结构支持视觉-语言交错输入,容纳多张图像;
本文贡献如下
1、使用文本模态作为anchor,将MLLM输出空间与CLIP对齐;
2、提出一种组合指令微调任务;
3、得分蒸馏技术使得KOSMOS-G可与UNet技术结合;
算法
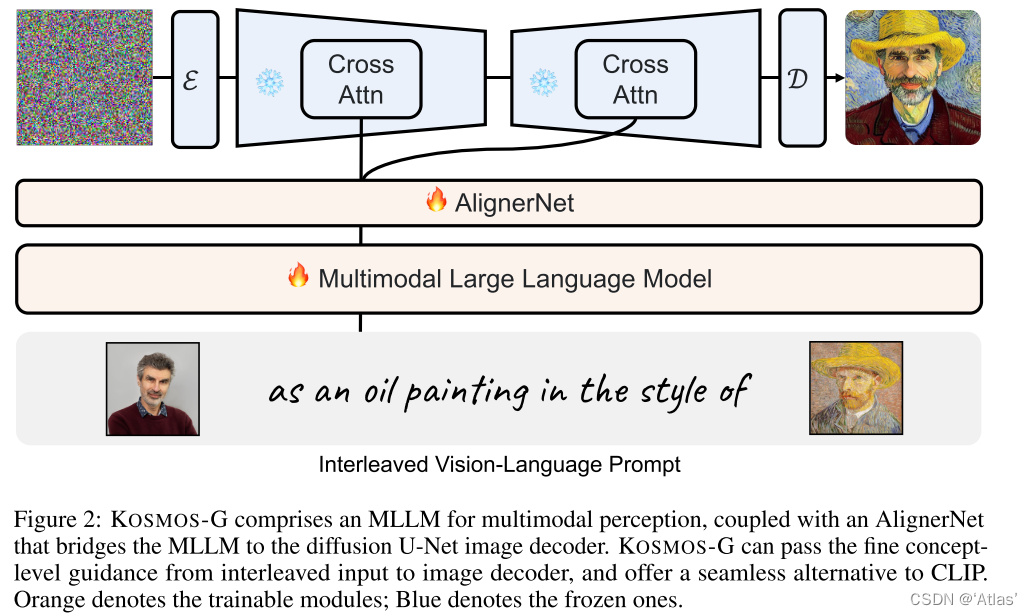
KOSMOS-G结构如图2,训练过程分为三步:
1、多模态语言模型。在多模态语料库上,从头开始预训练MLLM。包括单模态数据,跨模态成对数据,交错的多模态数据;
2、图像解码对齐。在文本数据上训练AlignerNet,通过CLIP监督对齐KOSMOS-G输出空间与U-Net的输入空间;
3、Instruction微调。基于图文组合生成任务微调KOSMOS-G。
多模态语言建模
作者使用 < s >及< /s >表示序列的开始和结束,< image >及< /image >表示图像表征的开始和结束,使用vision Transformer处理输入图像,获得输入序列embedding后送入Transformer-based decoder,通过自回归方式从左到右处理序列,通过softmax输出每个token的可能性;
图像解码器对齐
通过KOSMOS-G替换SD中CLIP文本编码器,主要关注点在于解决KOSMOS-G与图像解码器之间不对齐问题,作者发现如果直接fientune 会导致轻微不对齐以及图像质量受损。
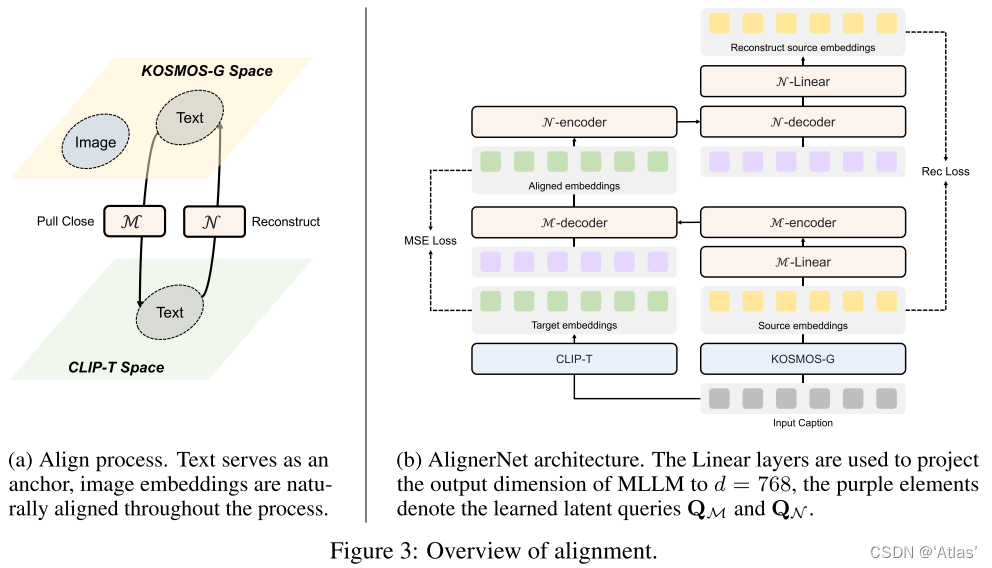
作者通过AlignerNet,包括编码器M,解码器N,学习对齐KOSMOS-G的源空间S及CLIP目标空间T,使用仅包含文本的caption C进行训练,该过程如图3a,损失函数如式5,6,
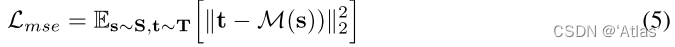
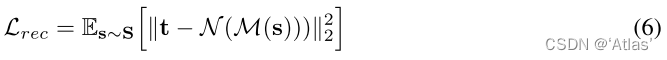
AlignerNet结构如图3b
微调instruction
图像作为一个外部语言用于图像生成,使用等式3中扩散损失进一步微调KOSMOS-G。
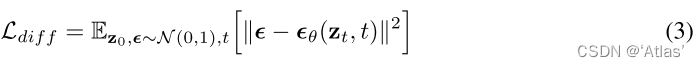
为了重构所需数据,首先对图像进行caption,然后从caption提取实体,从图像获得分割结果,如图4所示,
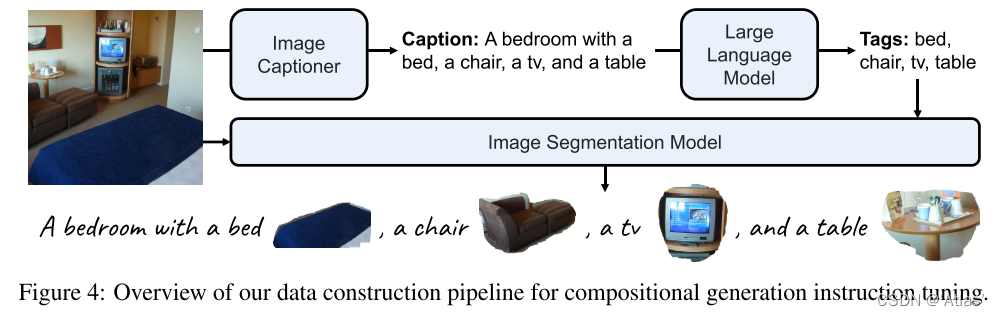
实验
如图5,KOSMOS-G展示惊艳的零样本生成结果;

表1左为与DreamBench量化比较结果,右为与MS-COCO结果比较;
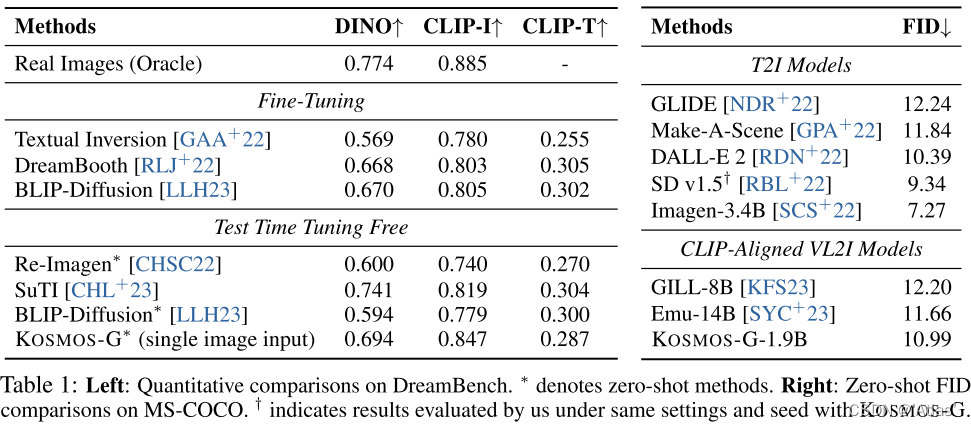
表2表明end-to-end微调导致没能生成合理图片
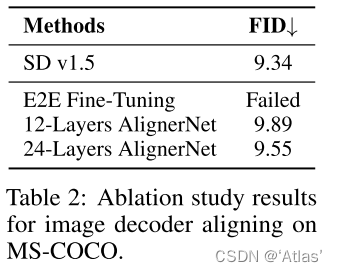
图7为一些应用案例

结论
KOSMOS-G,使用视觉+语言作为输入用于生成高保真度图像。使用在instruction之前先进行对齐的预训练策略。