具体的数据可以回看上一条博客。我们先来始化三个空列表,用于存储后续计算的预测得分、交叉验证得分的平均值和交叉验证得分的方差。
pred,score,var = [], [], []2. 再定义一个列表,包含了我们想要尝试的分箱数量。
binsrange = [2,5,10,15,20,30]3. 设置一个for循环,对`binsrange`列表中的每个元素(即每个分箱数量)进行一次迭代。
for i in binsrange:#实例化分箱类enc = KBinsDiscretizer(n_bins=i,encode="onehot")#转换数据X_binned = enc.fit_transform(X)line_binned = enc.transform(line)#建立模型LinearR_ = LinearRegression()#全数据集上的交叉验证cvresult = CVS(LinearR_,X_binned,y,cv=5)score.append(cvresult.mean())var.append(cvresult.var())#测试数据集上的打分结果pred.append(LinearR_.fit(X_binned,y).score(line_binned,np.sin(line)))再来画图:
#绘制图像
plt.figure(figsize=(6,5))
plt.plot(binsrange,pred,c="orange",label="test")
plt.plot(binsrange,score,c="k",label="full data")
plt.plot(binsrange,score+np.array(var)*0.5,c="red",linestyle="--",label = "var")
plt.plot(binsrange,score-np.array(var)*0.5,c="red",linestyle="--")
plt.legend()
plt.show()每一行的具体注释如下:
GitHub Copilot: 这段代码的主要目的是通过改变分箱的数量,来观察线性回归模型的性能如何变化。下面是对每行代码的详细解释:
'''1. `pred,score,var = [], [], []`: 这行代码初始化了三个空列表,用于存储后续计算的预测得分、交叉验证得分的平均值和交叉验证得分的方差。2. `binsrange = [2,5,10,15,20,30]`: 这行代码定义了一个列表,包含了我们想要尝试的分箱数量。3. `for i in binsrange:`: 这行代码开始了一个循环,对`binsrange`列表中的每个元素(即每个分箱数量)进行一次迭代。4. `enc = KBinsDiscretizer(n_bins=i,encode="onehot")`: 这行代码创建了一个`KBinsDiscretizer`对象,用于将连续的特征值转换为离散的"箱子"。`n_bins=i`表示分箱的数量,`encode="onehot"`表示使用one-hot编码。5. `X_binned = enc.fit_transform(X)`: 这行代码对训练数据`X`进行分箱操作,并将结果保存在`X_binned`中。6. `line_binned = enc.transform(line)`: 这行代码对测试数据`line`进行相同的分箱操作,并将结果保存在`line_binned`中。7. `LinearR_ = LinearRegression()`: 这行代码创建了一个线性回归模型。8. `cvresult = CVS(LinearR_,X_binned,y,cv=5)`: 这行代码对线性回归模型进行5折交叉验证,并将结果保存在`cvresult`中。9. `score.append(cvresult.mean())`: 这行代码计算交叉验证得分的平均值,并将结果添加到`score`列表中。10. `var.append(cvresult.var())`: 这行代码计算交叉验证得分的方差,并将结果添加到`var`列表中。11. `pred.append(LinearR_.fit(X_binned,y).score(line_binned,np.sin(line)))`: 这行代码首先在分箱后的训练数据上训练线性回归模型,然后计算模型在分箱后的测试数据上的得分,并将结果添加到`pred`列表中。12. `plt.figure(figsize=(6,5))`: 这行代码创建了一个新的图形,大小为6x5。13. `plt.plot(binsrange,pred,c="orange",label="test")`: 这行代码绘制了测试得分随着分箱数量变化的曲线。14. `plt.plot(binsrange,score,c="k",label="full data")`: 这行代码绘制了交叉验证得分的平均值随着分箱数量变化的曲线。15. `plt.plot(binsrange,score+np.array(var)*0.5,c="red",linestyle="--",label = "var")`: 这行代码绘制了交叉验证得分的平均值加上方差的一半随着分箱数量变化的曲线。16. `plt.plot(binsrange,score-np.array(var)*0.5,c="red",linestyle="--")`: 这行代码绘制了交叉验证得分的平均值减去方差的一半随着分箱数量变化的曲线。17. `plt.legend()`: 这行代码添加了图例。18. `plt.show()`: 这行代码显示了图形。'''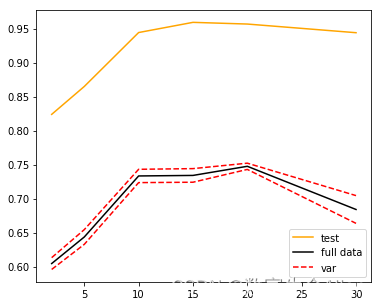
可以看到,箱子数为20时,拟合效果最好。score表示模型的预测得分的均值,而var表示这些得分的方差。通过绘制`score+np.array(var)*0.5`和`score-np.array(var)*0.5`这两条线,我们可以看到预测得分的变化范围,这可以帮助我们理解模型的预测性能的稳定性。如果这个范围较小,那么说明模型的预测性能比较稳定;如果这个范围较大,那么说明模型的预测性能有较大的波动。这两条线实际上构成了一个置信区间,它表示的是我们对模型预测得分的不确定性。这是一种常见的可视化方法,可以帮助我们更好地理解和解释模型的性能。
接下来我们看看20箱时,模型的拟合效果怎么样:
enc = KBinsDiscretizer(n_bins=20,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)fig, ax2 = plt.subplots(1,figsize=(5,4))LinearR_ = LinearRegression().fit(X_binned, y)
print(LinearR_.score(line_binned,np.sin(line)))
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)ax2.plot(line #横坐标, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果, linewidth=2, color='green', linestyle='-', label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',linestyle=':', label='decision tree')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()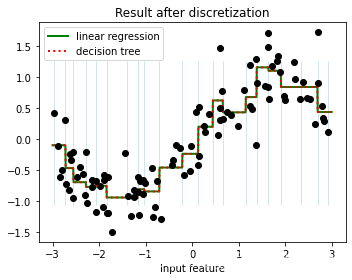
可以看到模型非常接近正弦曲线,且R2 = 0.94,已经很接近1了。