Basics of Parallel Programming 并行编程的基础

核达到了上限,无法越做越快,只能通过更多的核来解决问题

Process 进程
有独立的存储单元,系统去管理,需要通过特殊机制去交换信息
Thread 线程
在进程之内,共享了内存。线程之间会分享很多内存,这些内存就是数据交换的通道。
管理Tasking的方法
Preemptive Multitasking 抢占式多任务:
当这个线程/任务在跑时,调度者scheduler决定中断和返回。任务自身无法决定
Non-preemptive Multitasking 非抢占式多任务:
反过来让任务自身决定何时结束。好处是,如果任务全都是自己给的,控制能力较强。但是容易发生卡死。比较少用,多用于一些实时性非常高的操作系统中

线程的切换很贵:
一个线程被中断的话是非常费的,至少需要2000 多个CPU cycle
并且新调进来的线程,数据不在各级缓存中,得从内存中重新调用,时间可能需要 10000 ~ 1000000 多个CPU cycle
Job System就是用来解决这些问题
并行化编程的两个问题:
1.Embarrassing Parallel Problem
让线程各自自主运行完毕,不会打断线程,不存在swaping 线程的问题。就是一堆独立的问题,各自算完,然后收口。例如Monte Carlo 积分的算法
2.Non-Embarrassing Parallel Problem
但是真实游戏案例里,无法把一个游戏所需的模拟分的那么清楚,各个系统之间有很多数据的依赖

Data Race 数据抢占。当读取和写入发生在一个数据,但是不同线程里,会导致读取后和操作时数据不一致
Locking Primitives 锁算法
Critical Section:这段代码只有当前线程可执行,并且相关数据只归于当前线程,其他线程不得修改。
是阻断式编程
阻断式编程
可能产生死锁。线程未解除锁定将卡死,并导致后续相关线程也卡死
在大型系统,上百个任务中,无法保证每个任务一定会成功,一个任务的失败可能导致整个系统的死锁
当高优先级的任务进来后,无法打断正在运行的低优先级任务,任务优先级失去了意义
因此lock尽量少用
原子性操作:
在硬件底层实现,保证对变量的读写操作,不会被多个任务抢占
Load:从内存中加载到一个对于Thread安全的存储空间,再查看数值
Store:将数据写入内存
核心的想法是避免锁住整段代码。保证执行的指令中对这一个数值的内存的操作是原子性的
空洞代表cpu正在等待
lock free编程:避免死锁
wait free:理论上的方式,通过一套数学方法尽可能避免cpu等待
cpu利用率100%几乎不可能。但是具体的,比如堆栈或者队列的操作,是可以做到wait free。比如高频的通讯协议。
需要严格的数学推演证明
高级语言在编译器编译后无法知道具体的汇编语言的顺序,只保证结果是一致的,但是会在多线程中出现很大问题
期望的逻辑是:
线程1里,a先等于2,b在等于0
线程2里,监测b等于0的时候,a应该要等于2
但实际编译器优化后,会任务a和b是两个无关的变量,
线程1里有可能b赋值给一个临时变量,然后b被赋值为0,a还未被赋值2,之后a是用临时变量来赋值2
此时线程2里看到了b等于0时,a等于2是不成立的
这是并行开发非常容易出现问题的地方
每个CPU和每个不同的架构都会导致不同的顺序
常出现的是:PC模拟器上和实机的运行是完全不一致的
C++ 11 中可以通过显式的要求执行顺序,但是性能更低
乱序的原因:有大量的数据存储,读取,因为cpu通常是饥饿的等待数据,不会等待指令一条条执行,根据指令读取数据,而是整块指令和数据混在一整块在cpu中运行
这也是debug正常,但release失效的原因。因为debug往往是顺序的,但是release是乱序
Parallel Framework of Game Engine 游戏引擎的并行框架


Fixed Multi-Thread 固定多线程
大部分传统引擎的做法,根据Task分类成固定的线程,彼此之间不侵犯,在每个Frame开始的时候交换数据。
在2-4核的情况下较好。
但是很难保证四个线程的workload是一样的,会有的轻,有的重,是个木桶效应,所有线程要等待最慢的线程完成任务。
并且很难把负载重的任务分出来给其他闲置的线程。因为通常一个线程访问的数据是尽可能地在一块地方。以保证数据是安全的。另一原因是不同场景不同线程的负载不一样,在风景的场景里渲染压力大,战斗场景里模拟线程压力大
大概会有1/3的资源浪费
如果固定的线程高于电脑配置的核数,还是会发生线程抢占问题。而8核16核的电脑会有浪费


Thread Fork-Join
提取出游戏中一致性非常高,但是计算量很大,比如动画,物理模拟的一些运算,到一定时间,这些固定好的线程,会Fork一些子任务出来专门传递到Work Thread(预先申请好的),然后计算完后回收Task的结果
可以动态的生成work thread
很多基于unity和unreal的游戏都是这种做法
但还是会造成cpu闲置

虚幻中提供两种Thread:
Named Thread :明确的告诉是给Game, Logic,Render 等
Worker Thread:用于处理物理,动画,粒子等

一种更加复杂的架构
可以创建很多任务,设置好任务的dependency,都扔给核去处理,核会自动根据任务之间的dependency来决定执行顺序和并行任务
游戏是有很强的dependency的 Task Graph具体实现:
Task Graph具体实现:
在代码中直接加入Link,构建好dependency后自动生成Graph
问题:
task树的构建是不透明的
真实游戏引擎里task的dependency是动态的,不是静态的(task graph动态的生成节点是非常复杂的,早期并没有wait功能)
Job System

协程
是非常轻量的多线程执行的一种方式
实际上是:通过Yield可以从函数执行的任意阶段跳出挂起,让出执行权。然后可以通过Invoke激活从跳出的节点继续执行
核心就是,在任务执行中间,能让道出去,并且能回来
现代高级语言里很多原生支持,如c#,go。但c++里协程很难实现
线程是一个调硬件的中断,也就是整个环境context,栈stack都会重置,所以创建和中断的消耗性能非常高,是直接通知到操作系统的 OS
协程是由程序自己定义的,在一个线程里可以在很多的协程里来回切换,从cpu上看还是在一个线程里,通过程序来定义切换和激活,并没有激活核的切换
有栈协程
关键是跳出再重新激活后,本地的变量是不会被污染或清空的

无栈协程
相当于本地的变量直接清空。c++中实现就相当于汇编中的Go To。对实施者要求很高,一旦没写好,会产生大量的bug
最大的好处是不需要保存和恢复整个栈的状态,切换成本很低。一般是非常底层可能用到
Stackful ,是更适合面向更多开发者的协程
Stackless ,是用在更加底层,只有少数人用的,需要更多知识经验的人
协程一个很大的难点在于,在不同的操作系统,包括原生语言c,c++,汇编语言等底层语言,并不支持协程的机制。不同平台需要不同的机制
基于光纤的任务系统
高速的线程管道,可以高速的载入各种Job并且自由的进行协程切换, 同时Job还可以设置dependency和priority。 
该申请多少个Work Thread?
尽可能的一个work thread 对应一个 核,可以是逻辑核,可以是物理核,一般是逻辑核
让thread的swap几乎为0 
一个个生成的Job直接载入Thread然后处理
Job有优先级和依赖问题
根据Job的优先级,依赖关系和Work Thread 的饱和状态分配Job给working thread
与 Fork-join不同的就是在这里,是一个全并行化的方法
执行模型:先进先出,先进后出
游戏引擎的工程实现中,实现Job System时,一般会有LIFO。因为游戏里很多job的产生,都是前一个job执行到一半,可能会产生多个不同的job。彼此之间是dependency的关系。也就是所,当前job所产生的新的job如果未完成的话,自身是执行不了的。因此是先进后出的模型。类似堆栈
Scheduler会把Yield的Job扔到一个waiting list里。然后执行下一个任务
因为并不能预估每个Job所需要占用的时间
比如 等待IO, 复杂的运算,产生非常多的dependency等
从而导致Work Thread的分配不均
Scheduler会通过Job Stealing 把重负担Work Thread未执行的任务分配给空闲的Work Thread
优点:
容易实现schedule
容易设计依赖关系
每个堆栈彼此独立
不存在 Thread Switch
缺点:
C++不能原生支持,可以参考Boost源码
不同OS实现方法不同
具体的底层工程非常复杂
Programming Paradigms 编程范式

早期就是POP为主
现代基本都是OOP
OOP问题1:
有很多二义性。也就是设计上的问题,
如上图例子,是在玩家里写攻击敌人还是敌人里写收到攻击? 即一个动作(function)归属于哪个类
而且不同的人对于这个的写法是不一致的
问题2:OOP是一个非常深的继承树。
如上图,就受到魔法伤害这个Function来说,到底是写在Go那一层,还是Monster这一层,还是具体的蜘蛛怪物这一层?
且每个人对这个问题的看法是不一样的。 
问题3:基类会非常庞大臃肿,派生类可能只需要基类的几个功能

问题4:OOP的性能很低。
内存是分散的,数据会被分散到各个object里
虚函数在内存上各种跳跃,函数的重载,会有很多指针,导致代码执行时跳来跳去
问题5:OOP的可测试性。
OOP测试需要创建所有的环境,所有的对象。来测试其中的某个函数是否正确。因为所有的数据被包含在对象当中。对象一层套一层,很难写单元测试
Data-Oriented Programming 面向数据编程

CPU的速度越来越快,但是内存的访问速度是跟不上,导致现代计算机有很复杂的缓存机制
Cache 缓存
L1 Cache就是距离CPU最近的缓存,速度最快
L2 Cache是稍微远点的,速度略逊于L1
L3 Cache是直接链接内存的,速度也是Cache里最慢的
cpu从L1开始一层层查询数据
想cache友好要尊从数据紧凑型。即数据尽量呆在一起
SIMD:对4个float的加减乘除,看作一个vector,一次性做完,一次性读4个空间,一次性写4个空间。大部分硬件都有支持
LRU:Cache被填满后 → 最近还在使用的留住 → 最近没用的东西剔除,
还有一种随机剔除算法,基于概率
每次读写取的是一个cache line。
假设有一个数据,这个数据在各级cache之间。每个cache和memory都有一段,cpu要保证三个cache和memory中的数据都是一致的。因此是一层层读取,一层层写到内存, 这也是为什么逐行读取数据的效率会比逐列读取数据的效率快上很多倍原因,原因就是往下读会导致跳跃Cache Line 造成 Cache Miss
这也是为什么逐行读取数据的效率会比逐列读取数据的效率快上很多倍原因,原因就是往下读会导致跳跃Cache Line 造成 Cache Miss
DOP的核心思想:游戏世界里所有的表达都是数据

代码自身也是数据
主要考虑的就是尽量减少Cache Miss的问题
在DOP中,会把数据和代码看作一个整体,尽可能保证数据和代码在cache中紧密地在一起(内存中可能是分开的)。保证代码执行完后,数据刚好能处理完。
相当于数据的处理者和要处理的数据是在一起的
例子:
把Cache看作一家工厂而言,code是工人,数据就是产品的材料,每个工人都只能处理特定的材料
如果发生在工厂里的材料不是工厂里的工人能够处理的,就需要材料等可以处理的工人进来; 或者工厂里的功人不能处理现在工厂里的材料,也就需要等待新的材料进来
所以最佳实践就是工人和对应能处理的材料一起进入工厂,这也就是DOP想要实现的东西
Performance-Sensitive Programming 性能敏感编程

减少执行顺序的依赖度,让代码之间的执行尽量不存在上下依赖关系

有两个函数,一个在读,一个在写同一个变量时,当两个线程同时读写的变量在同一个cache line里,会加重系统负载
因此,要尽量避免两个线程会同时读写一个cache line。即不要让两个线程同时访问很碎的数据,尽量让每个线程访问的数据就是自己的一块
现代CPU中会对 Branch 语句,比如If 或者 Switch进行优化,会直接把预测执行的代码直接加载到cache里。如果发现条件不满足,则要swap掉提前加载好的代码,可能需要到冷数据(内存或硬盘)中去读取,会等很久
上述例子,会反复在if,else之间跳动,从而导致反复切换cache,导致性能下降的很低1
优化方式是,执行前先进行一次排序。这样只需要执行一次cache切换
提前将数据分组,避免复杂的 If 和 Else, 使用不同的容器来分组数据,让一组容器对应一个处理代码从而减少处理代码在Cache中的swap
Performance-Sensitive Data Arrangements 性能敏感数据编程


当使用OOP的思想去定义一个东西一般使用的是Structure来定义其属性,而每一个这个东西都是使用这个整的structure来定义。如左图所示的粒子的定义。这就是AOS架构
这样来定义的话,假设我希望修改所有粒子的位置和速度,我们却需要去跳跃内存中的其他属性比如颜色和生命周期,这样就不利于高性能编程
但是如果使用SOA就可以直接把一整个数组pass进Cache,处理会高效很多,这样的思想就很像写Shader,因为GPU天生的就是数据驱动的
Entity Component System ECS 架构


Component-Based系统最自然的实现方式是使用OOP的方式来实现
但是会导致很多问题:
过多的虚函数指针问题
大量的代码是分散在各个类里
数据也是非常分散的
这样的代码实现效率是非常低的
Entity:非常轻量,就是一个id,id指向了一组component。即用了哪些数据
Component:一块数据。没有任何业务逻辑,没有任何借口。纯数据(注意之前讲的Component base有很多接口,如tick,setProperty,getProperty)。可以进行读写操作,但是他本身并不知道自己的意义
System:用于处理component。业务逻辑所在地。可能会同时处理好几类的数据。例如有一个moving system,根据速度该position。health system会根据damage去调整health的值。
ECS 本质是一个理论框架,目的是充分利用Cache,多线程和DOP的特性达到高效的目的

是类似于模板或者原型的概念
比如一个NPC就需要几个特定的Component,
Archetype类似 type of GO
目的是当ECS对上千个Entity检查的时候,不能去一个一个与检查Entity是否有特定的Component,这个访问就很慢。但是Archetype就节省了很多步骤。 
Chunk
将内存定义成一个个Chunk, 然后把一类Archetype的所有的Component按照他的类型一个个去放进去。 一个Chunk里一定是同一类的Archetype
好处是当为了需要处理这个Chunk的时候可以直接提取整条的数据,没有损耗的忽略其他数据










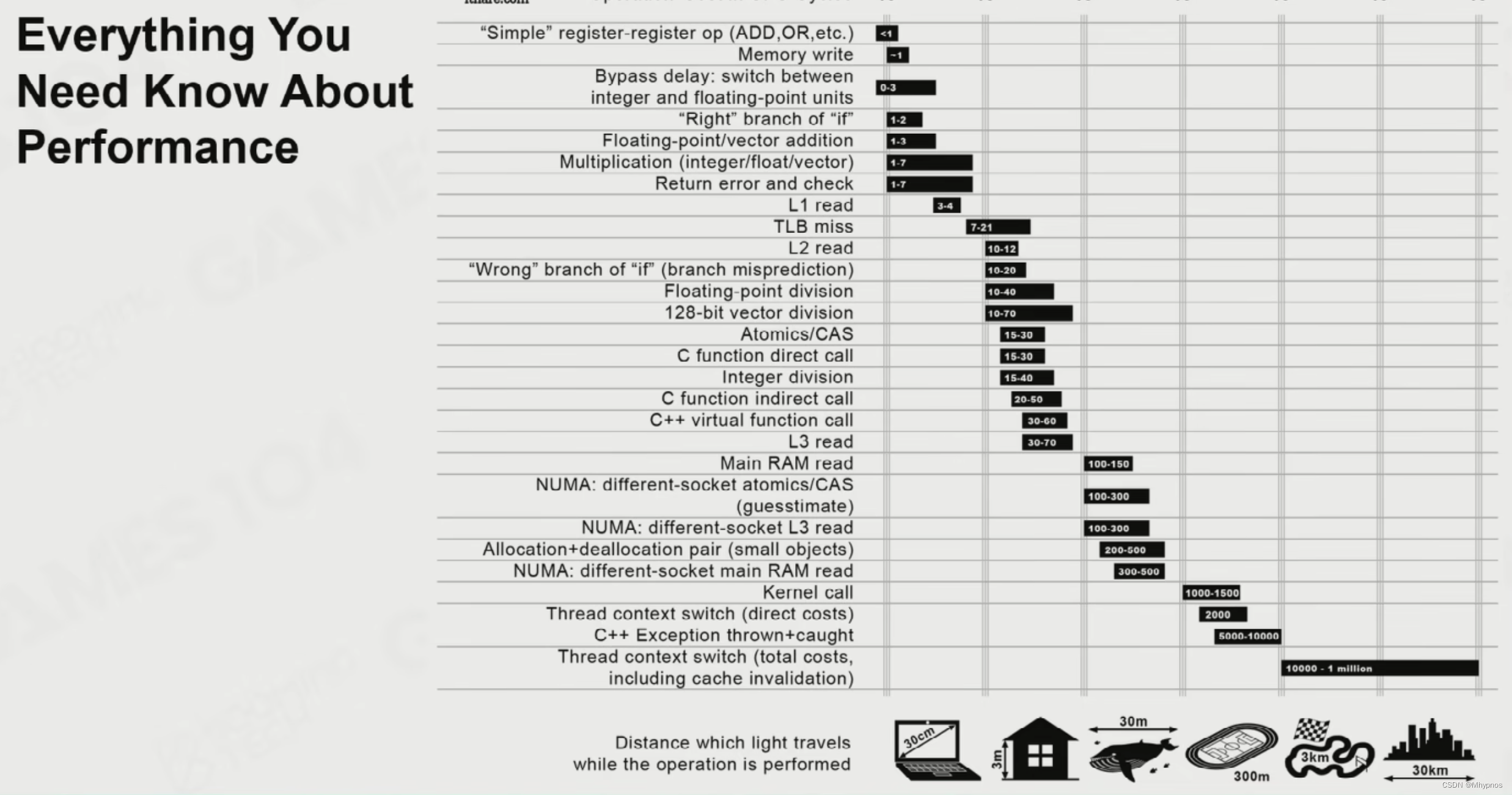
大部分CPU操作的耗时