三维重建以及神经渲染中的学习
公众号AI知识物语
本文内容为参加过去一次暑期课程学习时的笔记,浅浅记录下。
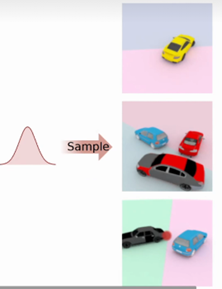
三维图形可控生成:
1:学习一个图形生成模型
2:具有可控三维变量:1物体形状;2物体位置;3物体颜色;4物体位姿
3:三五监督难获取,仅以无相机位子的二维观察为监督
4:无分割、深度、物体位姿等额外监督
Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
CVPR 2020
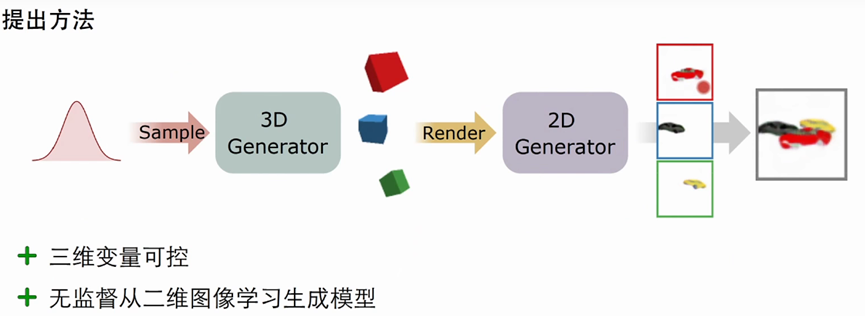

第一步:3D generator中,只生成前景/背景的primitives,每个primitive表示为o_i =(R_i, t_i , s_i, Φ_i) 理解为--------旋转、平移、skill、以及 appearance feature
第二步:对于每个primitive,采用一个相机位置,并把他渲染到二维的图像上,然后单独渲染每个primitive,得到特征图X,Alpha图A以及深度图D
第三步:采用2D Generator 把特征图转变为 RGB图以及图像本书的mask和它的深度,基于深度顺序,采用Alpha composition 组合多个前景以及背景。
第四步:Loss_adv 用来判别 完整/背景图形 ; L_com约束紧致性,L_geo 约束多视角一致性
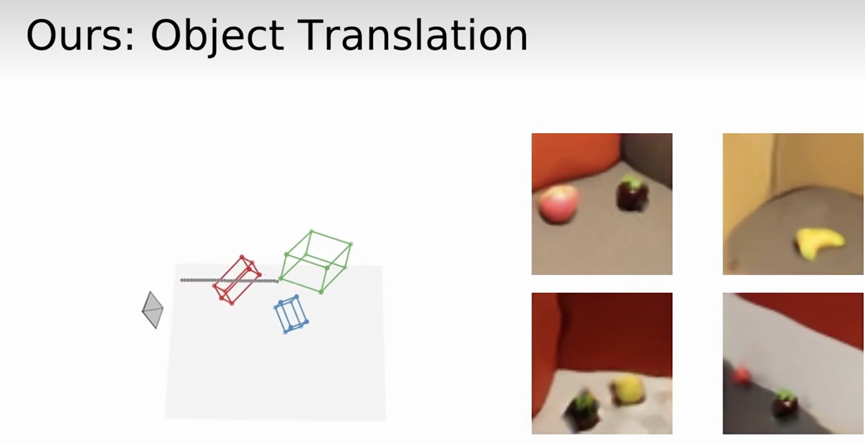
结果:
目前的不足
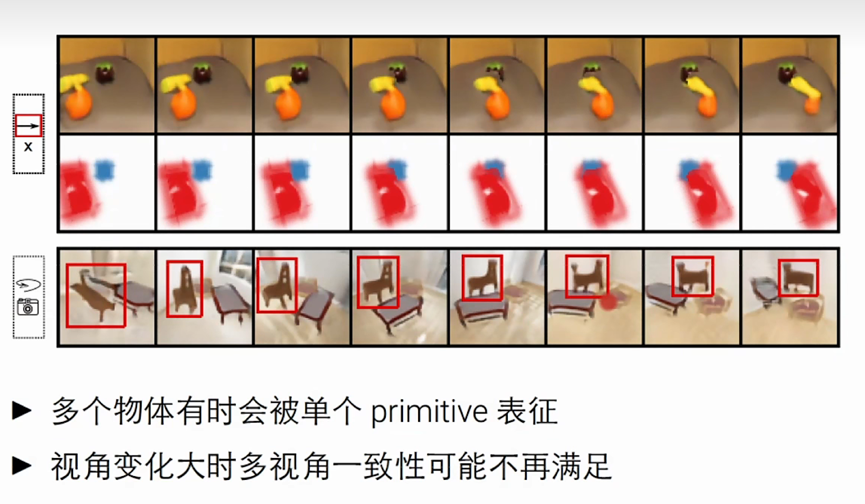
多个物体有时候会被单个primitive表征
视角变化大的时候多视角一致性可能不再满足
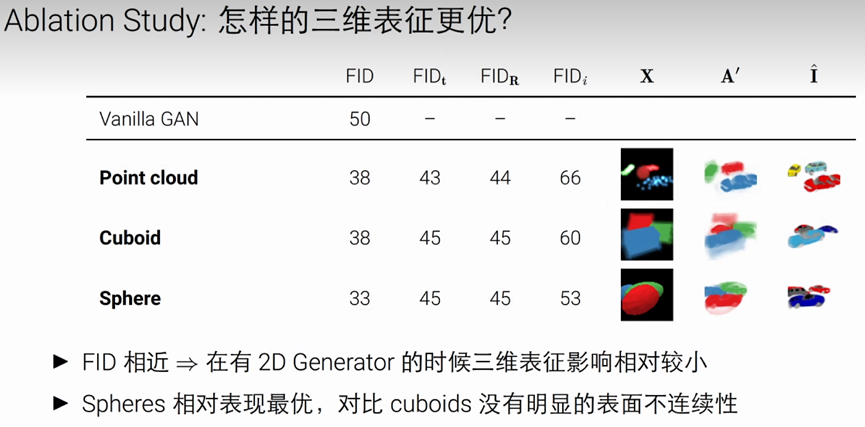
如何改善三维表征提高一致性
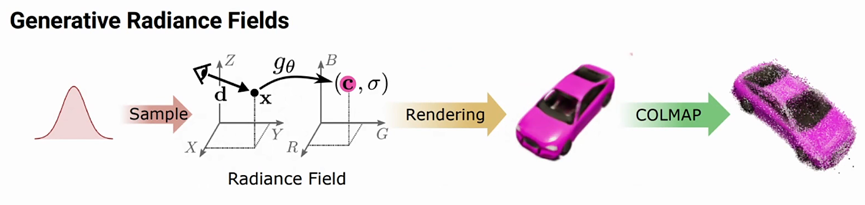
1:采用Volume Rendering生成图片,避免2D Generator引起的视角不一致
2:采用神经隐式表征,内存占用不随分辨率增长
GRAF: Generative Radiance Fields
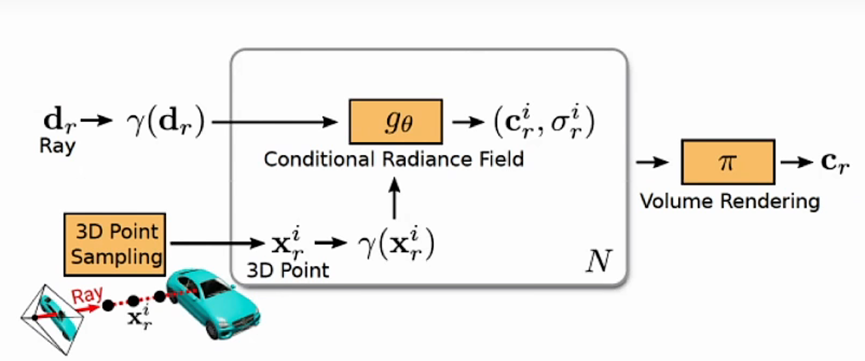
Radiance field 把三维坐标以及视角向量转换为 颜色以及密度
通过在射线上采样N个点,通过体渲染公式获得对应像素颜色
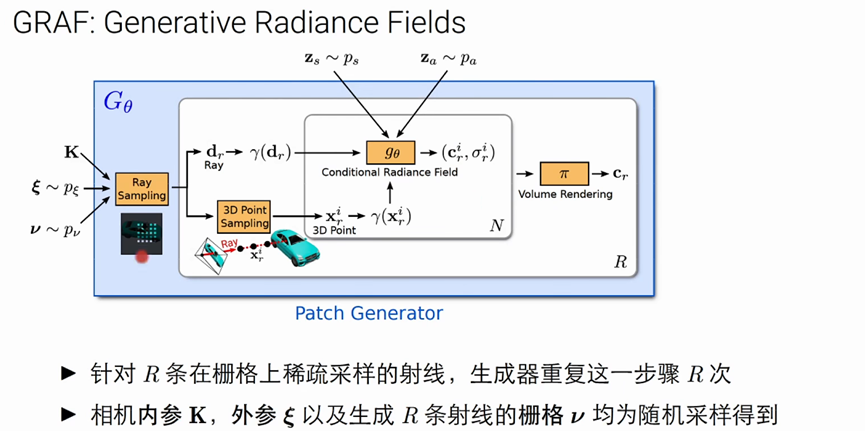
区别是:
(1)GRAF 引入2个隐变量z作为radiance field 的输入
(2)z_s为形状隐变量 z_a为颜色隐变量
(3)针对R条稀疏采样的射线,生成器重复这一步骤
(4)相机内参、外惨以及生成R条射线的栅格V均为随机采样得到
(5)生成大小32×32的图片块,常数内存占用以及渲染时间
(6)随机采样过程控制了该图片块的位置以及覆盖大小