准备数据集
使用编码工具
首先需要加载编码工具,编码工具可以将抽象的文字转成数字,便于神经网络后续的处理,其代码如下:
# 定义数据集
from transformers import BertTokenizer, BertModel, AdamW
# 加载tokenizer
token = BertTokenizer.from_pretrained('bert-base-chinese')
print('token', token)
out:
token BertTokenizer(name_or_path=‘bert-base-chinese’, vocab_size=21128, model_max_length=512, is_fast=False, padding_side=‘right’, truncation_side=‘right’, special_tokens={‘unk_token’: ‘[UNK]’, ‘sep_token’: ‘[SEP]’, ‘pad_token’: ‘[PAD]’, ‘cls_token’: ‘[CLS]’, ‘mask_token’: ‘[MASK]’}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken(“[PAD]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken(“[UNK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken(“[CLS]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken(“[SEP]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken(“[MASK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
由上可知bert-base-chinese模型的字典中共有21128个词,编码器编码句子的最大长度为512个词,并且能够看到bert-base-chinese模型所使用的一些特殊符号,例如SEK,PAD等。
这里使用的编码工具是bert-base-chinese,编码工具和预训练模型往往是成对使用的,后续将使用同名的预训练语言模型作为backbone。
编码工具的试算
加载完成编码工具之后可以进行一次试算,观察编码工具的输入和输出,代码如下:
data = token.batch_encode_plus(batch_text_or_text_pairs=['关注博主,不迷路。','俺要带你上高速。'], truncation=True,padding='max_length',max_length=12,return_tensors='pt',return_length=True)
# 查看编码输出
for k,v in out.items():print(k,v.shape)
# 把编码还原成句子
print(token.decode(out['input_ids'][0]))
out:
input_ids torch.Size([2, 17])
token_type_ids torch.Size([2, 17])
length torch.Size([2])
attention_mask torch.Size([2, 17])
[CLS] 关 注 博 主 , 不 迷 路 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[CLS] 俺 要 带 你 上 高 速 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
编码工具的参数说明
对于编码工具的使用,特别是参数值的含义可以参考下面的两段代码:
"""使用简单的编码"""
# 编码两个句子
out = tokenizer.encode(# 句子1text = sents[0],text_pair = sents[1],# 当句子长度大于max_length时进行截断truncation=True,# 一律补充pad到max_length长度padding = 'max_length',add_special_tokens = True,# 许多大模型的阶段也是使用512作为最终的max_lengthmax_length=30,return_tensors=None,
)
"""增强的编码函数"""
# 增强的编码函数
out = tokenizer.encode_plus(text = sents[0],text_pair = sents[1],#当句子长度大于max_length时进行截断操作truncation = True,#一律补零到max_length长度padding='max_length',max_length=30,add_special_tokens=True,#可以取值tf,pt,np,默认返回list--->tensorflow,pytorch,numpyreturn_tensors=None,#返回token_type_idsreturn_token_type_ids=True,#返回attention_maskreturn_attention_mask=True,#返回special_tokens_mask 特殊符号标识return_special_tokens_mask=True,#返回offset_mapping标识每个词的起始和结束位置---》这个参数只能BertTokenizerFast使用#return_offsets_mapping=True,#返回length 标识长度return_length=True
)
从上面的代码中的参数max_length=500可以看出经过编码后的句子的长度一定是12个词的长度。如果源句子超出则会进行截断,如果源句子不足则会进行填充PAD,其运行结果如下:
{'input_ids': tensor([[ 101, 1068, 3800, 1300, 712, 8024, 679, 6837, 6662, 511, 102, 0],[ 101, 939, 6206, 2372, 872, 677, 7770, 6862, 511, 102, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'length': tensor([11, 10]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]])}
input_ids torch.Size([2, 12])
token_type_ids torch.Size([2, 12])
length torch.Size([2])
attention_mask torch.Size([2, 12])
[CLS] 关 注 博 主 , 不 迷 路 。 [SEP] [PAD]
[CLS] 俺 要 带 你 上 高 速 。 [SEP] [PAD] [PAD]
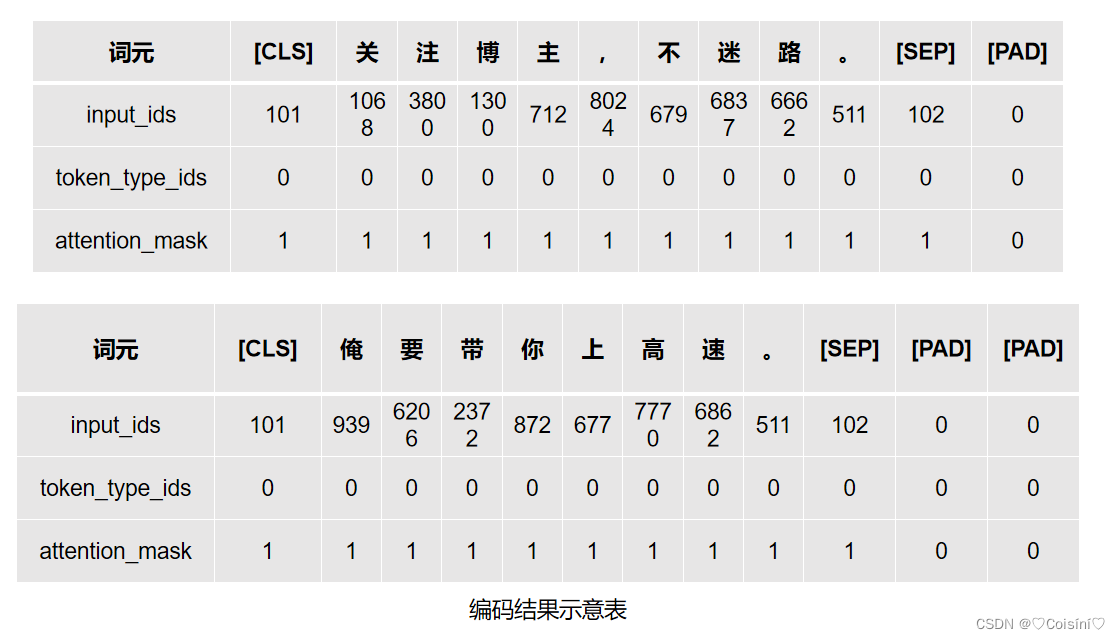
编码工具首先是对一条完整的句子进行了tokenizer,把句子分成了一个个token。同时,对于不同的编码工具,分词的结果也不一定一致。这里采用的bert-base-chinese编码工具中,它是以字为词,即把每个字当做一个词进行处理。
这些编码的结果对于预训练模型的计算十分重要,在后面将会使用编码器将所有的句子进行编码,用于输入到预训练模型中进行计算。
定义数据集
这里使用的数据集为ChnSentiCorp数据集,Dataset类如下:
# import torch
from datasets import load_dataset
class Dataset(torch.utils.data.Dataset):def __init__(self, split):self.dataset = load_dataset(path='lansinuote/ChnSentiCorp', split=split)def __len__(self):return len(self.dataset)def __getitem__(self, i):text = self.dataset[i]['text']label = self.dataset[i]['label']return text, label
dataset = Dataset('train')
print(len(dataset))
print(dataset[0])
在上述代码中加载了ChnSentiCorp数据集,并使用Pytorch中的Dataset对象进行封装,利用__getitem__()得到每一条数据,每条数据中包含text和labels两个字段,最后初始化训练数据集并查看训练数据集的长度和第一条数据样例。
out: 9600
('选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 1)
由上面的输出可知训练数据集包括9600条数据,每条数据包含一条评论文本和一个标识,表明这一条评论是好评还是差评。注意:这里的数据集是单纯的原始文本数据,并没有进行编码。
定义计算设备
这里将使用CUDA作为计算设备,这样可以极大加速模型的训练和测试的过程,代码如下:
device = 'cpu'
if torch.cuda.is_available():device = 'CUDA'
print('选用的计算设备:',device)
在该段代码中默认使用CPU进行计算,如果存在CUDA的话则选用CUDA作为计算设备。
定义数据整理函数
正如上面所述的那样,ChnSentiCorp数据集中的每一条数据是抽象的文本数据,并没有进行任何的编码操作,而预训练模型是需要编码之后的数据才能进行计算,所以需要一个将文本句子转成编码的过程。
另外,在训练模型时数据集往往很大,如果一条一条地处理则效率会太低,在现实中我们往往一批一批地处理数据,这样可以快速地处理数据集,同时从梯度下降的角度来讲,批数据的梯度方差相较于一条条数据的梯度小,可以让模型更加稳定地更新参数。
# 定义批处理函数
def collate_fn(data):sents = [i[0] for i in data]labels = [i[1] for i in data]# 编码data = token.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True,padding='max_length',max_length=500,return_tensors='pt',return_length=True)# input_ids:编码之后的数字# attention_masks:补0的位置都是0,其他位置都是1input_ids = data['input_ids']attention_mask = data['attention_mask']token_type_ids = data['token_type_ids']labels = torch.LongTensor(labels)# print(data['length'],data['length'].max())return input_ids, attention_mask, token_type_ids, labels在这段代码中,参数data表示一批数据,取出其中的句子和标识,它们都是list类型,在上述代码中会将两者分别赋给sents和labels,然后是使用编码器编码该批句子,在参数中将编码后的结果指定为固定的500个词的大小,与上面的例子同理超出500个词的部分会被截断(这里是通过truncation=True控制),同时少于500个词的句子会被[PAD]填充(这里主要是通过 padding='max_length'控制)。另外,在编码过程中通过 return_tensors='pt'参数,将编码后的结果返回torch中的tensor类型,免去了后面转换数据格式的麻烦(也就是说后面可以通过数据格式转换可以将‘tf’转成‘pt’格式)。
之后取出编码后的结果,并将labels也转成Pytorch中的Tensor格式,再把它们移动到之前已经定义好的计算设备device上,最后把这些数据全部返回,到这里数据整理函数的工作已经全部完成。
数据处理函数的例子
上述定义了数据处理函数,为了实验其效果也可使用下面的例子:(本用例已加狗头保命~)
data = [('选择新大的原因当然不是为了延毕。',1),('笔记本的内存确实小。',0),('宿舍没有风扇。其他都很好。',1),('今天才知道这本书还有第10000卷,真是太屌了。',1),('机器的背面似乎被撕了张什么标签,残胶还在。',0),('为什么有人在校园里尖叫,是疯了还是giao。',0)
]# 狗头保命版试算
input_ids,attention_mask,token_type_ids,labels = collate_fn(data)
print('input_ids.shape',input_ids.shape)
print('attention_mask.shape',attention_mask.shape)
print('token_type_ids.shape',token_type_ids.shape)
print('labels:',labels)
在该段代码中首先是模拟了一批数据,这批数据中包含4个句子,通过将该批数据输入到整理函数以后,运行结果如下:
input_ids.shape torch.Size([6, 500])
attention_mask.shape torch.Size([6, 500])
token_type_ids.shape torch.Size([6, 500])
labels: tensor([1, 0, 1, 1, 0, 0])
可见编码之后的结果都是确定的500个词的长度,并且每个结果都会被移动到可用的计算设备上,这样可以方便后续的计算。
定义数据加载器
上述代码中定义了数据集和数据整理函数以后,下面我们将定义一个数据加载器DataLoader,它可以使用数据整理函数来完成成批地处理数据集中的数据,通俗来讲每一批的数据我们可以称为batch。
# 定义数据加载器并查看数据样例
loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=16,collate_fn=collate_fn,shuffle=True,drop_last=True)
对于上述代码,我们使用了Pytorch提供的工具类定义数据集加载器,其参数说明可参考下图:

数据加载器的例子
为了更好地使用数据加载器,这里我们查看一批数据样例,将这批数据输入到数据加载器中,可以发现其结果会与数据整理函数的运行结果相似,只不过是句子的数量增多了。
上述代码依次打印了加载器中批次数目、加载器中输入数据的input_ids和掩蔽注意力的形状
attention_mask_shape、词元的ids类型形状token_type_ids_shape以及标签labels
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(loader):break
print(len(loader))
print('input_ids', input_ids)
print('attention_mask_shape', attention_mask.shape)
print('token_type_ids_shape', token_type_ids.shape)
print('labels', labels)
- input_ids 就是编码后的词
- token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1
- attention_mask pad的位置是0,其他位置都是1
- special_tokens_mask 特殊符号的位置是1,其他位置都是0
定义模型
因为我们是要利用Huggingface的预训练语言模型,所以需要做两件事情:加载预训练模型PLM以及定义下游任务模型。
【待更新~】