Unsupervised MVS论文笔记
- 摘要
- 1 引言
- 2 相关工作
- 3 实现方法
Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and Martial Hebert. Tejas Khot and Shubham Agrawal and Shubham Tulsiani and Christoph Mertz and Simon Lucey and Martial Hebert. arXiv: 1905.02706, 2019.
https://doi.org/10.48550/arXiv.1905.02706
摘要
在2019年6月6日,作者提出了一种基于学习的多视图立体视觉(MVS)的方法。虽然目前的深度MVS方法取得了令人印象深刻的结果,但它们关键地依赖于真实的3D训练数据,而获取这种精确的3D几何图形用于监督是一个主要障碍。相反,作者的框架利用多个视图之间的光度一致性作为监督信号,在一个较宽的基线MVS设置中学习深度预测。然而,仅用光度一致性约束是不可取的。为了克服这一问题,作者提出了一个有效的损失公式: a)强制一阶一致性,b)对每个点,有选择性地强制与一些视图进行一致性,从而隐式地处理遮挡。在不使用真实数据集进行3D监督的情况下,此方法是有效的,并表明提出的有效损失每个组成部分都对重建结果具有显著的改进。作者定性地观察到,作者的重建往往比获得的事实数据更完整,进一步显示了这种方法的优点。
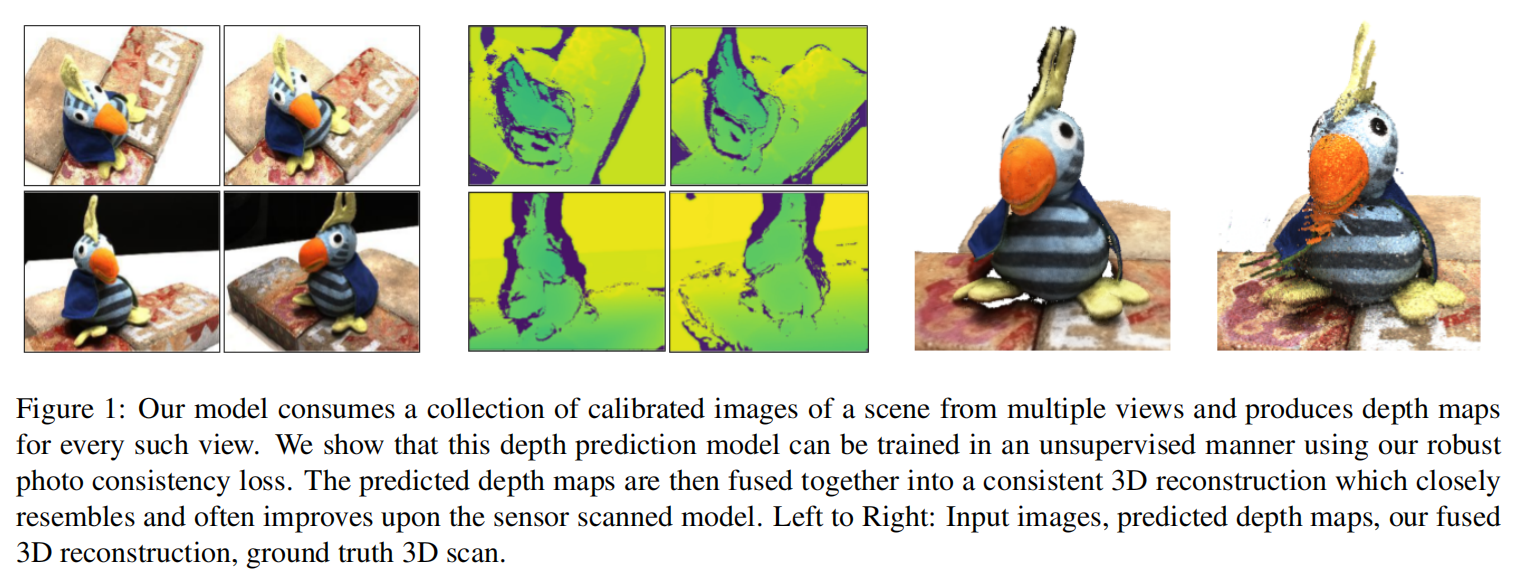
1 引言
从图像中恢复场景密集的三维结构一直是计算机视觉的一个长期目标。多年来,有几种方法通过利用潜在的几何和光度约束来解决这个多视图立体视觉(MVS)任务——一个图像中的一个点沿着极线投射到另一个图像上,并且正确的匹配在光学上是一致的。虽然实施这一见解导致了显著的成功,但这些纯粹的基于几何的方法对每个场景独立,并无法对世界隐式地捕获和利用通用先验,例如表面往往是平的,因此当信号稀疏时有时表现不佳,如无纹理表面。
为了克服这些限制,一项新兴的工作集中于基于学习的MVS任务解决方案,通常训练CNN来提取和合并跨视图的信息。虽然这些方法产生了令人印象深刻的性能,但它们在学习阶段依赖于真实的3D数据。作者认为,这种形式的监督过于繁琐,不是自然可行的,因此,寻求不依赖这种3D监督的解决方案具有实用和科学意义。
作者建立在最近的这些基于学习的MVS方法的基础上,这些方法呈现了具有几何归纳偏差的CNN架构,但在用于训练这些CNN的监督形式上存在显著差异。作者不依赖于真实的三维监督,而是提出了一个以无监督的方式学习多视图立体视觉的框架,仅依赖于多视图图像的训练数据集。能够使用这种形式的监督的见解类似于经典方法中使用的见解——正确的几何形状将产生光学上一致的重投影,因此可以通过最小化重投影误差来训练CNN。
虽然类似的重投影损失已经被最近的方法成功地用于其他任务,如单眼深度估计,但作者注意到,天真地将它们应用于学习MVS是不够的。这是因为不同的可用图像可能捕获到不同的可见场景。因此,一个特定的点(像素)不需要在光度学上与所有其他视图一致,而是只需要那些它没有被遮挡的视图。然而,明确地推理遮挡来恢复几何,提出了一个鸡和蛋的问题,因为遮挡的估计依赖于几何,反之亦然。
为了避免这一点,作者注意到,虽然正确的几何估计不需要与所有视图的光度一致性,但它应该至少与某些视图一致性。此外,在MVS设置中,跨视图的照明变化也很重要,因此只在像素空间中强制执行一致性是不可取的,而作者认为强制执行额外的基于梯度的一致性。
作者提出了一个有效的重投影损失,使我们能够捕获上述要求的照片,并允许使用所需的监督形式学习MVS。该方法的公式允许处理遮挡,但没有明确地为图像建模。该方法的设置和示例输出如上图1所示。该模型在没有三维监督的情况下进行训练,以一组图像作为输入,预测每幅图像的深度图,然后将其结合起来,得到一个密集的三维模型。
总之,该论文的主要贡献是:
1)提出一个以无监督的方式学习多视图立体视觉的框架,只使用来自新视图的图像作为监督信号。
2)一种用于学习无监督深度预测的有效多视图光度一致性损失,允许隐式地克服跨训练视图之间的照明变化和遮挡。
2 相关工作
多视图立体视觉重建
关于MVS的工作有着悠久而丰富的历史。在这里只讨论有代表性的作品,感兴趣的读者可以进行相关调查。MVS的实现有四个主要步骤:视图选择、传播方案、补丁匹配和深度图融合。已经有研究为每个像素聚合多个视图的方案,作者的构思可以看作是在训练过程中通过损失函数整合了其中的一些想法。基于补丁匹配的立体匹配的方法取代了经典的种子和扩展传播方案。补丁匹配已被用于多视图立体视觉结合迭代实现传播方案,深度估计和法线。深度图融合将单个深度图合并到一个单一点云中,同时确保结果点在多个视图之间保持一致,并删除不正确的估计。深度表示继续主导MVS基准测试和寻找深度图像作为输出的方法,从而将MVS问题解耦成更易于处理的部分。
基于学习的MVS
利用CNN学习到的特征能够很自然地适合于MVS的第三步:匹配图像补丁。CNN特征已被用于立体匹配,同时使用度量学习来定义相似度的概念。这些方法需要一系列的后处理步骤来最终生成成对的视差图。专注于学习MVS所有步骤的工作相对较少。体素表示自然地从不同的视图编码表面可见性,这已经在一些工作中得到证实。选择这种表示的常见缺点是不清楚如何将它们缩放到更多样化和大规模的场景。有些工作使用CNN特征创建代价体,视差值通过可微soft argmin操作回归获得。结合上述方法的优点,并借鉴经典方法的见解,最近的工作为多个视图生成深度图像,并将它们融合以获得三维重建。至关重要的是,上述所有方法都依赖于3D监督,本篇工作放宽了这一要求。
无监督深度估计
由于减少监督需求的类似动机,最近的一些单目]或双目立体深度预测方法利用了光度一致性损失。作为监督信号,这些图像依赖于训练过程中来自双目图像对或单目视频的图像。作为可见性推理的手段,网络用于预测可解释性、失效掩模或通过加入观察置信度的概率模型。这些方法在一个狭窄的基线设置上运行,在训练过程中使用的帧之间的视觉变化有限,因此不会由于遮挡和照明变化而遭受显著的影响。当前的目标是在MVS设置中利用光度损失进行学习,因此Unsupervised MVS提出一个有效的构思来处理这些挑战。






![[计算机网络实验]头歌 实验二 以太网帧、IP报文分析(含部分分析)](https://img-blog.csdnimg.cn/4a40c35e26b04992b33bf02651dd6a79.png)