目录
收集统计信息. 3
1. 通过DBMS_STATS包中的方法. 3
2、删除指定表的统计信息. 3
执行计划. 3
常用执行计划操作符. 4
统计指定sql执行号的所有操作符的执行时间. 5
HINT 5
并行操作:. 6
查询计划重用、结果集重用. 7
示例. 8
1、收集统计信息:. 8
3、对sql搜集统计信息. 9
2、添加索引. 9
使用优化器提示HINT:. 10
索引. 12
创建索引. 12
管理索引. 13
创建全局非分区索引. 14
创建全局分区索引. 14
创建局部索引. 15
创建聚集索引. 15
创建唯一索引. 15
索引查询. 16
重建索引. 16
删除索引. 16
查看索引信息. 16
数据库优化3个方面:
1、统计信息收集:统计信息准确,优化器选择执行计划才能真正做到最优。
2、建立合适的索引
3、DM.ini参数的优化
其他的:增加HINT,SQL改写等
收集统计信息
查看有没有收集统计信息:
select NUM_ROWS,LAST_ANALYZED,TEMPORARY from USER_TABLES where TABLE_NAME='EMP';
NUM_ROWS字段,如果没有收集通常是空
LAST_ANALYZED 代表收集的时间,如果没有收集这个字段也是空
TEMPORARY字段附带说明,N表示不是临时表临时表不需要收集
手动收集有三种可选方式
1. 通过DBMS_STATS包中的方法
(GATHER_TABLE_STATS、GATHER_INDEX_STATS 或 GATHER_SCHEMA_STATS)
DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','EMP',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
用户、表、不是分区表名填写NULL默认也是NULL区分大小写、采样百分比、保留参数默认写TRUE、控制列的统计信息集合和直方图的创建的格式默认填写FOR ALL COLUMNS SIZE AUTO表示所有列收集
或者:效果一样
SP_TAB_STAT_INIT ('SYSDBA','EMP');
2、删除指定表的统计信息
SP_TAB_STAT_DEINIT ('SYSDBA', 'DEPT');
执行计划
explain select * from emp;
1、缩进越深的越先执行。
2、同样缩进的上面的先执行,下面的后执行。
3、上下的优先级高于内外。
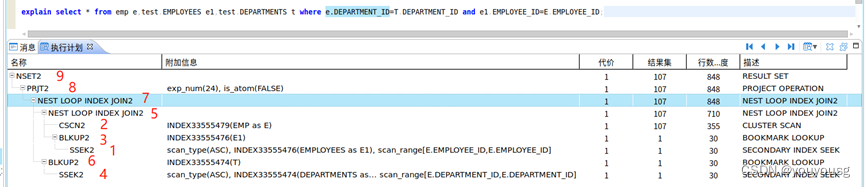
常用执行计划操作符
CSCN2:聚集索引全表扫描
SSCN:直接使用二级索引进行扫描
SSEK2:二级索引定位
CSEK2:聚集索引数据定位
BLKUP:二次回表
DISTINCT:除重
SLCT2:查询条件过滤操作符
DSCN:动态视图表扫描
ESCN:外部表扫描
SORT2:排序
STAT:统计信息计算
PRJT2:关系的投影(project) 运算,用于选择表达式项的计算
PRJT2:投影运算,选择表达式的计算
exp_num:映射列数
is_atom:是否要求单行数据
NSET2 表示收集结果集的操作符
表连接:
HASH JOIN:HASH链接 --大表和大表关联
NEST LOOP JOIN:嵌套循环连接 --小表和大表关联
MERGE JOIN:MERGE链接
执行顺序方式(1-2-3-5 - 4-6 - 7-8-9): --有分支的上下优先级最高
e1表二级索引扫描,e表全表扫描,e1根据索引二次回表查询,嵌套循环连接(e和e1都是小表)组成新的表
d表二级索引扫描,d表根据索引二次回表查询,前两个表(e和e1)组成的小表再与d表嵌套循环
返回结果
统计指定sql执行号的所有操作符的执行时间
需要ini参数:ENABLE_MONITOR=1、MONITOR_TIME=1 和 MONITOR_SQL_EXEC=1
MONITOR_SQL_EXEC为会话级动态参数,可以设置只针对当前会话开启,不建议参数级别开启。
select SF_GET_PARA_VALUE(1,'MONITOR_SQL_EXEC');
SP_SET_PARA_VALUE(1,'MONITOR_SQL_EXEC',1);
或
SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',1);
SP_SET_PARA_VALUE(1,'MONITOR_TIME',1);
ET( id_in bigint )
id_in sql执行后产生的执行号
HINT
DBA 对于数据分布是很清楚的,知道SQL语句按照哪种方法执行会最快。
在这种情况下,DBA 可以主动进行人工干预,指示优化器按照指定的方法去选择 SQL的执行计划。
人工干预优化器的方法称为 HINT。
它使优化器根据 DBA 的 HINT 提示来生成指定的执行计划。
如果优化器无法生成相应的执行计划,该 HINT 将会被忽略。
1)Hint格式
/*+ <具体的Hint内容> */
2)Hint在SQL中必须紧跟关键字SELECT、INSERT、UPDATE、DELETE或MERGE之后
{SELECT | INSERT | UPDATE | DELETE | MERGE} /*+ <具体的Hint内容> */
3)Hint中第一个星号(*)和加号(+)之间不能有空格
4)Hint中加号(+)和具体的Hint内容之间可以有空格,也可以没有空格,但通常都有空格。
5)Hint中的具体内容可以是单个Hint,也可以是多个Hint的组合,各个Hint间至少需要1个空格来彼此分隔。
6)Hint中指定具体对象时(比如指定表名或者索引名),不能带上该对象所在SCHEMA的名称,即使该SQL文本中已经有对应的SCHEMA名称。
explain select /*+ NO_INDEX(emp,EMP_IDX) */ * from sysdba.emp where EMPLOYEE_ID=100;
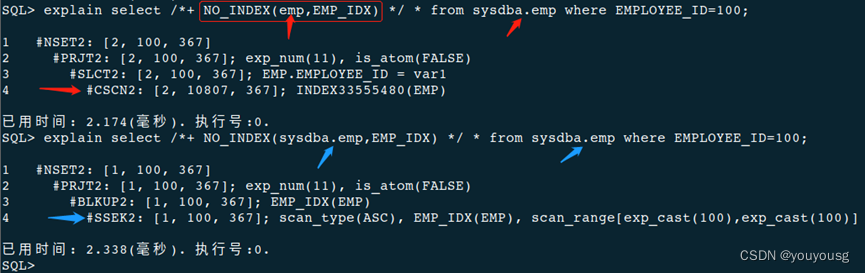
7)Hint中指定具体表名时,如果该表在对应SQL文本中有别名(alias),则应该使用该表的别名。
explain select /*+ NO_INDEX(e,EMP_IDX) */ * from emp e where e.EMPLOYEE_ID=100;
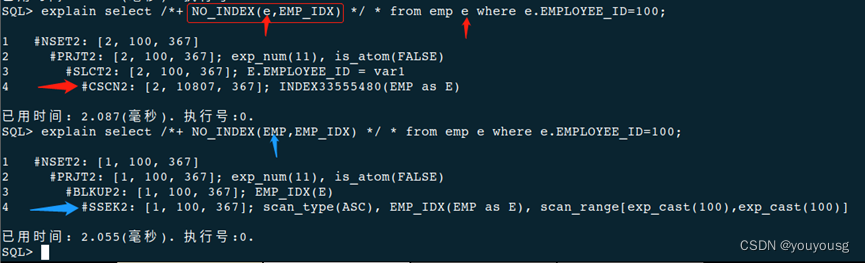
支持使用 HINT 的 INI 参数可通过 V$HINT_INI_INFO 动态视图查询。
select * from v$hint_ini_info where para_name='ENABLE_HASH_JOIN';
并行操作:
SELECT /*+ PARALLEL(emp 4) */ * FROM emp;
或者:多个重复hint以最后一个为准
SELECT /*+ PARALLEL(1) *//*+ PARALLEL(2) */ * FROM emp;
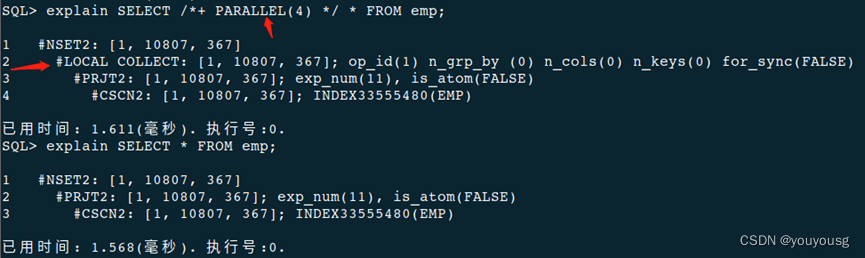
select SF_GET_PARA_VALUE(1,'PARALLEL_POLICY');
使用手动并行模式时,只需要在 INI 参数中设置好如下 2 个参数,然后执行并行 SQL查询语句时,需手动指定当前并行任务个数。
若不指定,将不使用并行。设置的 2 个参数如下:
PARALLEL_POLICY 2
PARALLEL_THRD_NUM 4
使用自动并行模式时,一般指定如下三个参数:
MAX_PARALLEL_DEGREE 3
PARALLEL_POLICY 1
PARALLEL_THRD_NUM 10
另外,当 PARALLEL_POLICY 为 0 时,即使有并行任务,也不支持并行。
查询计划重用、结果集重用
DBA 可以通过在 SQL 语句中设置 "RESULT_CACHE"或"NO_RESULT_CACHE" HINT手动指示查询的结果集是否缓存。如:
explain select /*+ RESULT_CACHE */ * from emp where emp.employee_id=100;
或者
explain select /*+ NO_RESULT_CACHE */ * from emp where emp.employee_id=100;
创建emp和dep各插入大量数据
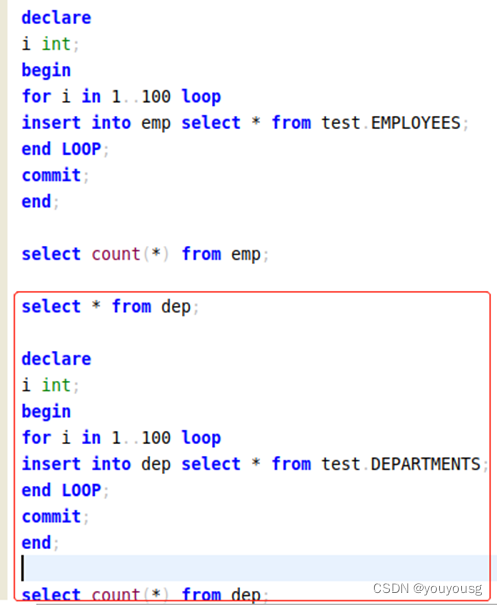
select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

select /*+ RESULT_CACHE */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;
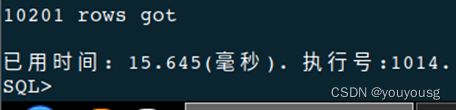
select /*+ NO_RESULT_CACHE */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

本示例中结果集重用不重用本次基本没效果。
示例
查看执行计划
explain select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

全是CSCN2全表扫描,且执行计划预估值偏差很大7221行实际返回10201行
1、收集统计信息:
select NUM_ROWS,LAST_ANALYZED,TEMPORARY from USER_TABLES where TABLE_NAME='EMP';
SP_TAB_STAT_INIT ('SYSDBA','EMP');
SP_TAB_STAT_INIT ('SYSDBA','DEP');
再次执行
select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

这里基本没效果:貌似因为不是执行计划步骤问题,虽然执行计划预估值有问题,但是执行计划步骤没问题,不管是否收集统计信息均按执行计划步骤走,所以这里效果不明显。
3、对sql搜集统计信息
--先创建索引后又收集sql统计信息
SP_SQL_STAT_INIT ('select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100');
explain select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;
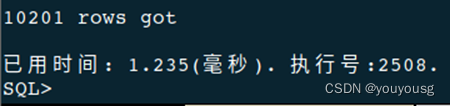
效果显著
2、添加索引
create index emp_idx on emp(EMPLOYEE_ID);
create index dep_idx on dep(DEPARTMENT_ID);

效果非常明显

使用优化器提示HINT
需要注意的是:如果 HINT 的语法没有写对或指定的值不正确,DM 并不会报错,而是直接忽略 HINT 继续执行。
支持 HINT 的INI 参数分为两类:
一是 HINT_TYPE 为"OPT",表示分析阶段使用的参数;
二是HINT_TYPE为"EXEC",表示运行阶段使用的参数,运行阶段使用的参数对于视图无效。
explain select * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

不使用hash join连接
explain select /*+ ENABLE_HASH_JOIN(0) */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

EXPLAIN SELECT /*+ ENABLE_HASH_JOIN(1) */ * FROM T1,T2 WHERE T1.C1 = T2.D1; --这个还是next loop嵌套循环啊
使用了 HINT,指明在执行此 SQL 时参数 ENABLE_HASH_JOIN 被置为 1。
SELECT /*+ INDEX(T1, IDX_T1_ID) */ * FROM T1 ;
SELECT /*+ INDEX(A IDX_T1_NAME)*/ * FROM T1 A WHERE ID > 2011 AND NAME < 'XXX' ORDER BY NAME;
explain select /*+ NO_INDEX(EMP,EMP_IDX) */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

EXPLAIN SELECT /*+ USE_HASH(T1,T2) */ * FROM T1,T2 WHERE T1.C1 = T2.D1; --这个才是使用hash连接
EXPLAIN SELECT /*+ NO_USE_HASH(T1,T2) */ * FROM T1, T2 WHERE T1.C1 = T2.D1; --不使用hash连接
explain select /*+ NO_USE_HASH(emp,dep) */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100; --这个没效果

--强制两个表间使用嵌套循环连接
EXPLAIN SELECT /*+ USE_NL(A, B) */ * FROM T1 A, T2 B WHERE A.C1 = B.D1;
explain select /*+ USE_NL(emp,dep) */ * from emp,dep where emp.DEPARTMENT_ID=DEP.DEPARTMENT_ID and EMP.EMPLOYEE_ID=100;

NO_USE_NL 强制两个表间不能使用嵌套循环连接
USE_NL_WITH_INDEX 当连接情况为左表+右表索引时,强制两个表间使用索引连接
EXPLAIN SELECT /*+ USE_NL_WITH_INDEX(T1, IDX_T1_C1) */ * FROM T1, T2 WHERE T1.C1 = T2.D1;
NO_USE_NL_WITH_INDEX 当连接情况为左表+右表索引时,强制两个表间不能使用索引连接
USE_MERGE强制两个表间使用归并连接。归并连接所用的两个列都必须是索引列。
NO_USE_MERGE强制两个表间不能使用归并连接
等。
貌似还可以直接指定dm.ini文件中的参数
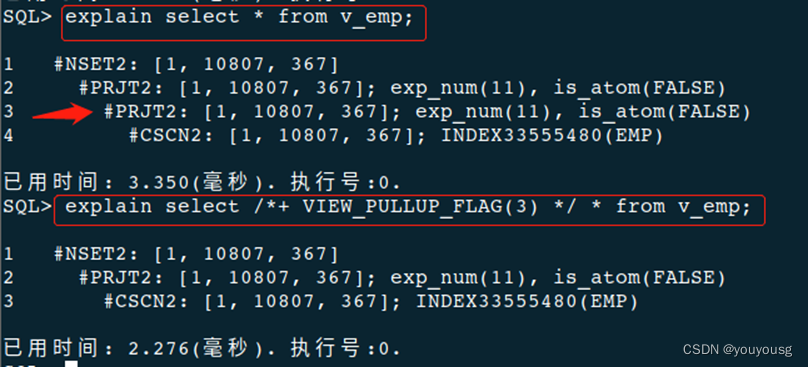
select * from v$hint_ini_info where para_name='VIEW_PULLUP_FLAG';

explain select /*+ VIEW_PULLUP_FLAG(3) */ * from v_emp;
索引
创建索引
create index emp_idx on emp(employee_id);
select name,id,subtype$ from sysobjects where subtype$='INDEX' and name='EMP_IDX';
索引占用空间(页数)
select index_used_space(33555482);
索引使用页数
select index_used_pages(33555482);
指定聚集索引键:--每张表中只允许有一个聚集索引
1. CLUSTER PRIMARY KEY:指定列为聚集索引键,并同时指定为主键,称为聚集主键;
2. CLUSTER KEY:指定列为聚集索引键,但是是非唯一的;
3. CLUSTER UNIQUE KEY:指定列为聚集索引键,并且是唯一的。
查询主键(聚簇索引键并删除修改)
SELECT CONSTRAINT_NAME,TABLE_NAME FROM ALL_CONSTRAINTS WHERE CONSTRAINT_TYPE='P' and TABLE_NAME='EMP1';
alter table emp1 drop constraint "CONS134218794"; --主键可以直接删,聚集主键不能直接删,需要再创建一个聚集主键而使其变为非聚集主键后再删。(create cluster index name_dept on dept(name); )
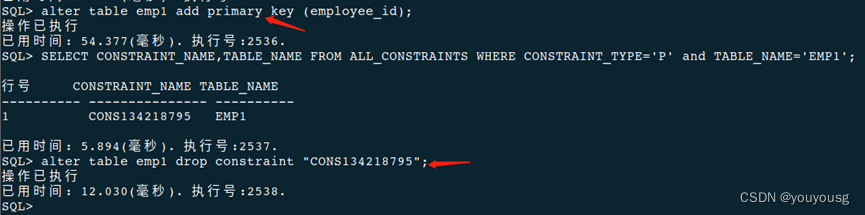
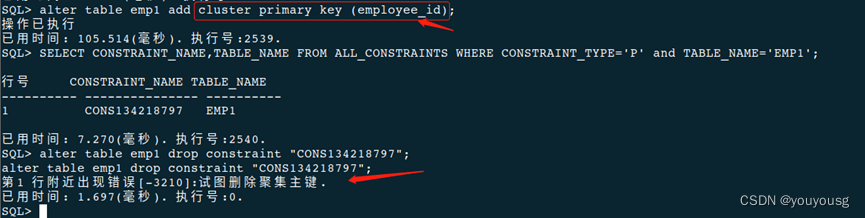
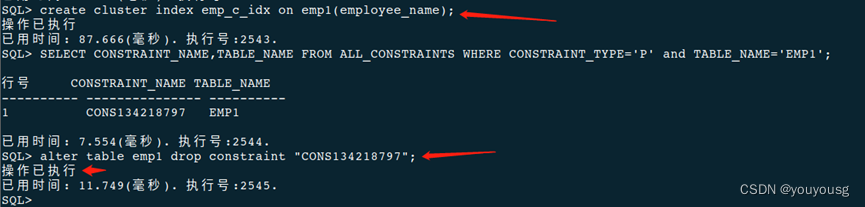
create cluster index emp_c_idx on emp1(employee_name);
--创建聚集主键后上面创建的聚集索引 自动删除了。
--创建聚集索引后上面创建的聚集主键 没有自动删除,但是可以执行手动删除了。
管理索引
索引分类:
物理存储角度
聚集索引:表数据存储在 B 树叶子节点上,定位索引可直接在B树中找到数据。每一个表有且只有一个聚集索引。同一张表创建另一个聚集索引时,前一个貌似会被自动删除。
非聚集索引:二级索引列和聚集索引列共同存储在B 树叶子节点上。如果查找索引键值以外的数据,则需要回到一级索引中进行查找。每一个表可以有多个非聚集索引。
create cluster index EMP1 on t1(EMPLOYEE_NAME); --聚集索引
create index s1 on EMP1(EMPLOYEE_ID); --非聚集索引
==
select name,id,subtype$ from sysobjects where subtype$='INDEX' and name='EMP_C_IDX';
SELECT CONSTRAINT_NAME,TABLE_NAME FROM ALL_CONSTRAINTS WHERE CONSTRAINT_TYPE='P' and TABLE_NAME='EMP1'; --聚集索引不是约束,这里查不到,之前创建主键或者聚集主键时是约束
==
功能角度分类
可分为唯一索引、函数索引、位图索引、位图连接索引、全文索引、空间索引、数组索引、普通索引。
虚实角度分类
分为虚索引和实索引。
虚索引:创建 PRIMARY KEY 主键约束或 UNIQUE 唯一约束时,系统会自动创建一个相关的唯一索引。因为不需要用户创建,因此称为虚索引。
实索引:虚索引以外的索引均为实索引。
索引键值个数分类:
单列索引和复合索引。
分区的角度进行分类:
全局索引和局部索引。全局索引和局部索引均为二级索引,专门用于水平分区表中。
全局索引 (GLOBAL) 是以整张表的数据为对象而建立的索引。全局索引的日常维护成本高于局部索引。
全局索引具体分为两种:全局非分区索引和全局分区索引。指定了<PARTITION 子句>的索引即为分区索引。只有 DMDPC 功能支持分区索引。
创建全局非分区索引
create index part_dept_idx on dept_part(id) global;
explain select * from dept_part where id = 2; --全局分区索引查询
explain select * from dept_part partition (p2022) where id = 2; --直接对分区子表查询,则使用全局本地索引
创建全局分区索引
create index part_dept_idx_f on dept_part(name) global partition by range(name)
(
partition p1 values less than (100) storage(on TS_HR_IDX),
partition p2 values less than (maxvalue) storage(on TS_HR_IDX)
);
explain select * from dept_part where name = 'dd'; //当数据量很大时
explain select * from dept_part index part_dept_idx_f where name = 'dd'; //或直接指定全局索引
explain select * from DEPT_PART partition (p2022) where name = 'dd'; //直接对分区子表查询,则使用全局本地索引
局部索引:局部索引是在分区表的每个分区上创建的索引。
未指定 GLOBAL 关键字创建的索引即为局部索引。局部索引暂时不支持分区。创建局部索时,会在水平分区表的主表上创建局部索引和在每个子表上创建一个子表局部索引。索引数据存储在子表局部索引上。
创建局部索引
必须缺省 GLOBAL 关键字
create index idx1 on dept_part(name)
storage(on TS_HR_IDX);
在 WHERE 中指定索引列,可使用索引 idx1 查询
explain select * from t1 where name = 'dd';
直接对分区子表查询,则使用子表局部索引
explain select * from DEPT_PART partition (p2022) where name = 'dd';
创建聚集索引
create cluster index clu_emp_name on emp(ename);
若指定索引键,表中数据都会根据指定索引键排序。
建表后,DM8 也可以用创建新聚集索引的方式来重建表数据,并按新的聚集索引排序。
新建聚集索引会重建这个表以及其所有索引,代价非常大的操作。
创建唯一索引
create unique index dept_unique_index on dept(dname);
位图索引:
针对含有大量相同值的列而创建。
索引查询
SELECT CONSTRAINT_NAME,INDEX_NAME,TABLE_NAME FROM ALL_CONSTRAINTS WHERE CONSTRAINT_NAME= 'CONS134218800';
SELECT CONSTRAINT_NAME,INDEX_NAME,TABLE_NAME FROM ALL_CONSTRAINTS WHERE CONSTRAINT_TYPE='P' and TABLE_NAME='EMP2';
SELECT INDEX_NAME,UNIQUENESS FROM ALL_INDEXES WHERE INDEX_NAME='INDEX33555495';
重建索引
当一个表经过大量的增删改操作后,表的数据在物理文件中可能存在大量碎片,从而影响访问速度。
sp_rebuild_index(schema_name varchar(256),index_id int);
select name,id,subtype$ from sysobjects where subtype$='INDEX' and name='EMP_IDX';
sp_rebuild_index('SYSDBA',33555482);
删除索引
DROP INDEX IF EXISTS emp_ename;
不能直接删除与已启用的 UNIQUE KEY 键或 PRIMARY KEY 键约束相关的索引。要删除一个与约束相关的索引,必须停用或删除该约束本身。
ALTER TABLE emp DROP CONSTRAINT pk_emp_name;
删除 emp 表的聚集索引
DROP INDEX clu_emp_name;
删除表就自动删除了所有与其相关的索引。
查看索引信息
INDEXDEF(INDEX_ID int, PREFLAG int); --PREFLAG 表示返回信息中是否增加模式名前缀。
select name,id,subtype$ from sysobjects where subtype$='INDEX' and name='EMP_IDX';
SELECT INDEXDEF(33555482,0);
select * from SYSINDEXES where id=33555482;