用了好多年微服务架构了,我经常会反思,这个项目为啥用微服务?真的能帮我们解决一些痛点吗?这个项目有必要用微服务吗?这个项目体现出微服务的价值了吗?
我是从2017年开始入手微服务,距今已经五六年了。在此期间,遇到的大小项目,基本都是用微服务架构开发的,其中有数字化工厂项目、教辅系列平台、政府行政审批系列、商城门户SASS平台、大数据平台等待。在这篇文章中,我就不给大家普及微服务的概念及微服务组件框架,主要讨论微服务架构的发展和核心思想。
只要学会举一反三,懂得总结归纳,从常见事务中剥离方法论,你就会发现,其实软件架构的发展,到现在的微服务,都是有迹可循。
先聊聊历史政治的历程
个人认知,说几个关键历程
-
最初的人文部落管理,扁平化管理,大家都跟着部落首领干,男的打猎,女的耕织,部落首领说了算。规模不大,统治者一言堂,管得过来。
-
随着各部落的壮大发展,部落间混战,最终轩辕氏皇帝征服其他部落,成部落联盟首领,再到后来的夏商周三代,基本形成了分封制的管理格局。规模越来越大,管不过来了。分封而治,权利下放。
-
春秋战国,诸侯崛起,周王室衰落,最终秦一统天下。吸取权利下放导致尾大不掉的弊病。于是始皇帝建立郡县制的同时,统一制度,统一思想,收缴天下兵马。权利下放,各管各的,容易失控。需要将权利按职能分类,选择性下放,同时建立统一的管理制度。
-
值得一提的,汉孝武黄帝,提出了天下第一阳谋的“推恩令”,彻底维护了郡县制的落实,防止了重返分封制。
-
随着长期发展,直到今日,形成了围绕中央政权,成立个多个司法部门,按职能管理的格局。高内聚(按职能成立各种司法部门,统一管理),低耦合(金字塔模式,建立省市县镇村多级。将部分权利逐层下放,各管一方)
简说创业者管理旅程
-
常规创业者,创业一开始,所有的活,从生产到销售一条龙服务,都是老板自己干,亲力亲为。
-
业务发展到一定规模,老板忙不过来了,请了几个员工一起干,干的好的,积累了经验,可能撇开老板自己出去创业了跟自己竞争了,管理失控,老板尴尬了。
-
于是,招聘了不同能力的人,划分智能部门干活,让专业的人干专业的事,离了萝卜坑还在,只要体系在,就能稳固发展,铁打的营盘流水的兵。
-
随着公司业务规模越来越大,光靠只能职能部门也没办法管理庞大的业务,于是成立分公司,子公司,大区部门等,建立金字塔模式,逐层下放。这时候的老板管理基本就靠制度、企业文化、战略、组织架构、机制等来管理企业了。
软件架构的发展
软件架构的发展,其实也是一样的,都有个从0到1(质变),从1到n(量变)的过程。不同时期下的管理思想在一定程度上是相似的。(结合个人经验,以web发展发展为例说起)
-
从微软asp框架说起,asp框架将html,js,css(前端),c#/vb(后端代码),jdbc-sql(数据库),系统配置等全部放在.asp文件中,开发一个功能,直接操作数据库,查询到数据,就遍历渲染了,很直接。开发起来真的很方便简介,但维护起来却非常困难,后期文件极其臃肿,且代码复用性极差,当遇到大的项目,需要大的开发团队,分工、管理、规划就显得极难。
-
后来,asp.net框架出来,做到前后端分离(文件维度)html,js,css(前端)放在.asp文件,c#(后端代码)放在.cs文件中。甚至MVC框架的出现,将软件架构进一步拆分为前端展现层-后端(业务控制层-业务处理层-数据库持久层) 4层,从上到下,底层代码的复用性得到了极大的提高,每一层可以隔离开发。(PS:当时我也转JAVA了,java跨平台太香了。asp.net有点对应java的SSH三大框架,以下以java为例接着说)。
-
再后来,随着angularJS、restApi的出现,前端只需要接口提供的数据就可完独立完成交互,不再依赖后端渲染,权限、配置控制等,可独立部署,掀起来前后端分离的格局(项目维度),随后angularJS2+、vue、react + spring boot的架构得到开发者青睐。这时候迎来了前后端独立的大发展阶段,前端没了后端的束缚,基于mockjs或node,迅速响应市场,快速提供可见软件,并逐步形成前端框架;后端也是从业务角度,解耦业务,拆分项目,形成一个前端,需要多个后端服务提供接口的局面,然而后端面服务拆分的越多,越难管控。
-
微服务框架的诞生就是为这些业务服务提供一系列工具组件去统一管理起来。
总结一下,如下图:

再回头看一下微服务架构,你会发现,核心业务被一堆抽离出来的职能管理服务团团包围。
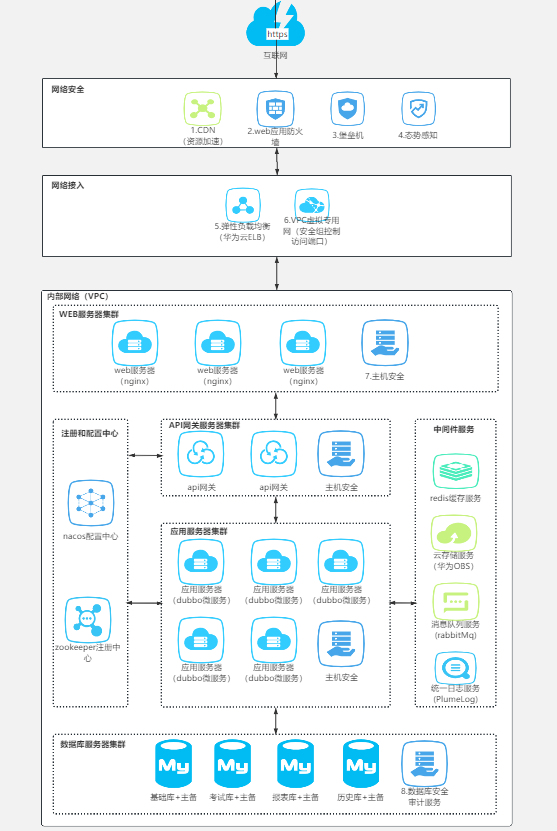
微服务架构的核心思想
软件架构的核心思想是“高内聚、低耦合”,所以任何架构的改造和设计模式都是向这两个核心思想靠拢。
微服务最关键的是拆分微服务,按业务属性和功能属性,可以分为纵向拆分和横向拆分。其拆分的目的,主要还是为了业务解耦。业务解耦的目的:
-
并行开发
大的项目,一般开发周期会比较长,如果规划的好,微服务可以并行开发,提高人效和缩短开发周期;
-
复用性和可移植性
一个独立完整的功能,可以复用,降低维护成本,提高功能价值。
-
降低隐患范围,风险最小化
防止了牵一发动全身,因为一个问题,导致系统全部瘫痪。系统更新,也可以无感局部更新。
-
有益于持续交付
基于微服务低依赖性,更容易做单元测试和功能交付。
-
灵活交付
特别是toB产品,不同的企业,可能要的功能范围不一样,他不想出那么多钱买你全套,只要部分功能,用微服务就可以很灵活搭配,打包不同范围的产品。
我做过很多大型项目,为了缩短工期,为了能并行开发,敏捷管理,持续交付可用功能,才选型微服务架构。然而,微服务不止是为了解决这些问题,微服务的诞生,更多是为了解决toC高并发,响应慢的问题,单体服务再性能方面扩展有限,且成本很大。而微服务通过集群部署,可以很灵活、很方便的进行性能扩展,同时保证了系统的稳定性。集群部署的目的:
-
高并发
通过部署多节点,并发处理业务,突破业务并发瓶颈。
-
消灾、灭灾
防止服务宕机,造成系统瘫痪,多节点部署,有备无患。
-
热部署
不停机更新服务,系统升级(兼容升级)客户无感知。
举个例子,统计整个学校学生的兴趣爱好。如果没有系统,只能线下统计,大家都能想到最快的方式,逐层统计,由下到上,班主任统计自己班的,统计完交给年级主任,年级主任统计完各年级的交给学段部,学段部校长统计完交给总校长统计。这样一个庞大的工作拆分成四级,由多人完成。不同的人干不同的事,同级别可并行处理,这极大地提升了干活的效率。这也是微服务分布式处理思想的体现,可以很好的纵向扩展业务,不限层级。但是,在统计过程中,逐层上报,汇总的时候,要去重分组筛选,越到后边工作量越来越大,总校长事务繁多,实践投入又很少,总的统计过程还是效率很低。怎么办,很简单,根据实际情况,给他们配备不同数量的助手,协助完成统计工作。即不同的人干同一件事,这降低了流水线上单个节点的压力,同时保证了流水线的运作,每件事,保证始终有人干就行。
这是微服务的集群处理思想的体现,根据业务容量大小,可以灵活横向扩展节点,不限个数,同时保障了系统的可用性。微服务的架构思想,其实还是源于日常生活,没那么复杂,只是有些人善于归纳,提炼方法论并应用到其他领域罢了!毕!
文章转载自:·志坚行远·
原文链接:https://www.cnblogs.com/luze/p/17202222.html