背景
之前的业务链路
负载均衡–>nginx–>cvm(业务后端node)
上云后链路
负载均衡–>nginx–>pod(业务后端node)
上云后nginx日志隔几个小时就出现一波502,查看nginx的日志有两个特征,就是request_time=0,upstream_response_time=0,当时的第一个反应就是nginx这里出了问题,因为后端确实也没有日志。
近一天日志

发现只要触发502了,502主要集中在1分钟(其实当时从这里就应该敏感的发现fail_timeout=60s)
根据502产生的时间,查询nginx的error日志,如下所示:
error.log日志

从nginx日志可以看到,upstream的地址竟然一个是ip一个是new_node_vip(因为单独的配置了upstream文件,所以理论上这里是会映射出IP的),然后查询现网status:200的日志。
status:200日志
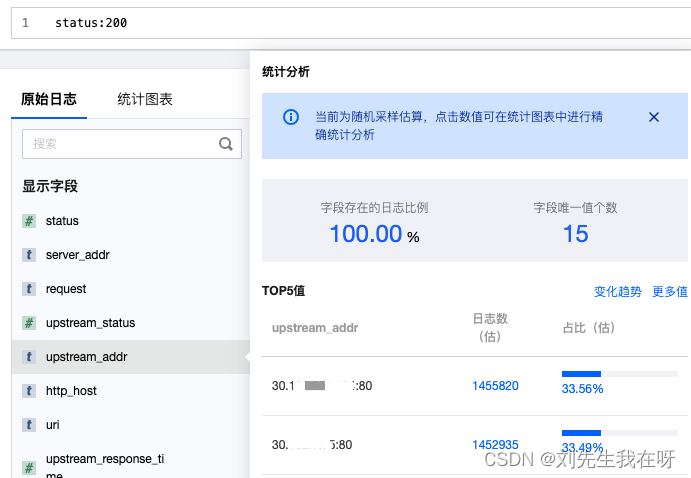
到这里虽然知道是upstream 配置的变量没有映射为IP导致的问题。但是还不知道怎么解决。
原因定位
最后还是从nginx的报错信息可以确认是上游也就是node那里发送的断开连接
upstream prematurely closed connection while reading response header from upstream,最后联想到了nginx默认有配置长链接超过60s会发起断开,因为上云后配置的vip只有2个,所以就出现了两个同时达到了max_fails=1的阈值,导致此刻没有upstream的后端地址,最后nginx就返回了502。
问题解决
1、增加max_fails次数,让nginx可以多次重试
2、增加后端pod的数量
参考文章:
nginx长链接导致502



![Maven详见及在Idea中的使用方法[保姆级包学包会]](https://img-blog.csdnimg.cn/66e7a6798f244818821c0c358fe8cf83.png)