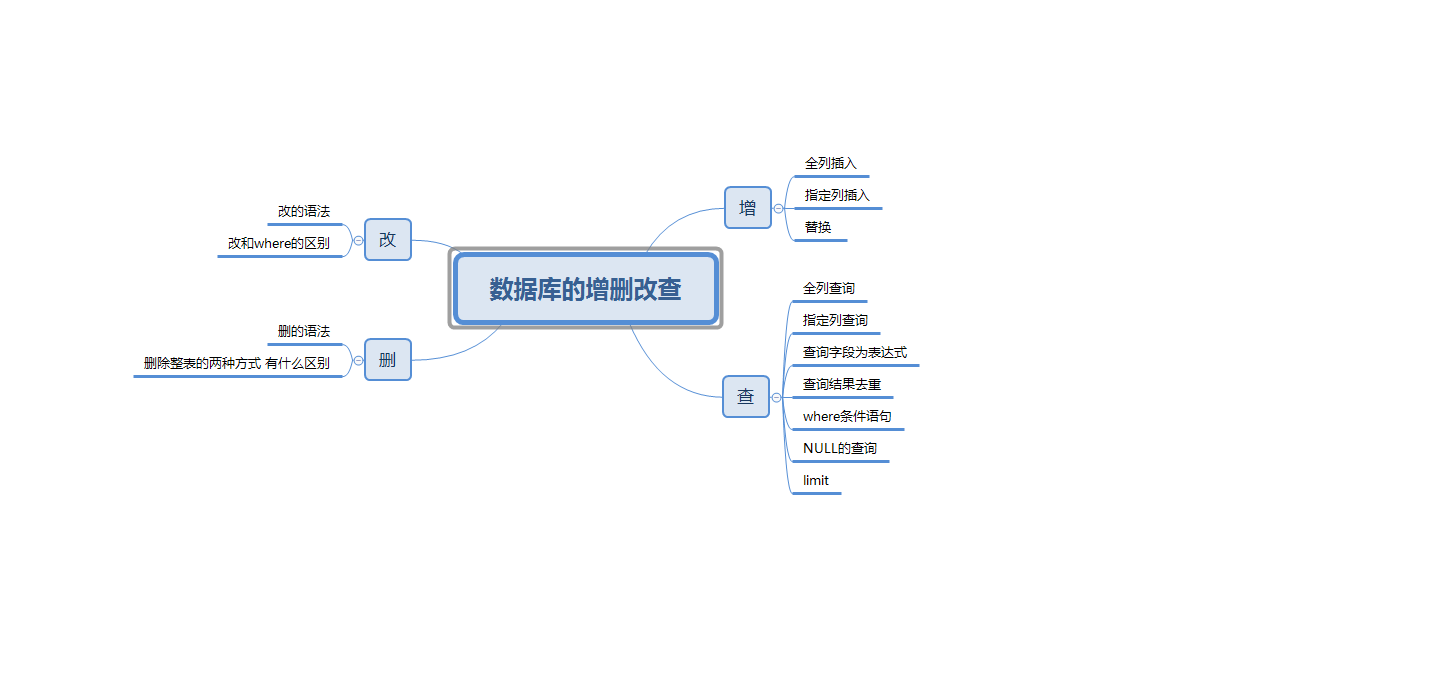
应用服务安全
- 1 应用服务安全
- 1.1 最小特权
- 1.1.1 基础知识
- 1.1.2 安全上下文
- 1.1.3 资源实践
- 1.1.4 特权基础
- 1.1.5 特权实践
- 1.1.5 PSP实践
- 1.2 策略方案
- 1.2.1 OPA简介
- 1.2.2 特权策略
- 1.2.3 策略进阶
- 1.3 资源限制
- 1.3.1 AppArmor简介
- 1.3.2 基础知识
- 1.3.2 应用实践
- 1.4 调用限制
- 1.4.1 Seccomp
- 1.4.2 应用实践
- 1.5 应用沙箱
- 1.5.1 gVisor应用
- 1.5.2 环境集成
- 1.5.3 Containerd集成
- 1.5.4 k8s集成
1 应用服务安全
1.1 最小特权
1.1.1 基础知识
学习目标
这一节,我们从 场景解读、细节解读、小结 三个方面来学习。
场景解读
应用安全攻击
随着基于容器部署方式的改变,软件的交付速度越来越快,而为了体现应用的价值快速变现,在软件研发模式、软件架构模式、软件交付模式、软件部署模式都做了相应的调整。虽然应用交付越来越快,但是业务受到的危害也越来越多,根据OWASP组织针对2021年全球互联网的网络安全攻击事件的统计分析,针对用户行为的攻击形式占据1/5的比例,而针对服务端软件结构漏洞的攻击占据了4/5,越来越多的攻击着重于用户数据、企业数据、相关数据的二次使用,基于这些数据进行大量的安全攻击,尤其是针对企业软件项目的安全攻击事件,很大程度上从用户的管理行为、数据泄露行为、安全管理制度漏洞等方面入手导致的安全攻击。
特点解读
我们会发现,越来越多的安全攻击事件,很大程度上是由于程序自己设计时候出现的漏洞、数据校验不合理、内部配置失误、安全体系建设等方面的不合理导致的,说白了,该进行信息紧密校验的地方我们没有做,或者说该缩小权限限制的地方我们没有加固。
方案思路
在很多项目的大部分实际的工作中,当一个开发人员或者其他相关人员请求开通访问权限时,系统管理员等负责权限的人员因为多种因素盲目的提供了访问权限,这导致了在组织内部有很多的漏洞,极有可能会造成重大安全风险。所以,目前行业中提出了一套所谓的最小特权原则(Understanding Principle of Least Privilage)来解决该问题。它的核心点是 将用户的项目操作权限限制到一个最小范围,然后从服务端入手,最大化减少安全攻击的机率
细节解读
最小特权原则
最小权限原则最早由 Saltzer 和 Schroeder 提出来的,它是指每个程序和系统用户都应该具有完成任务所必需的最小权限集合。它要求计算环境中的特定抽象层的每个模块只能访问当下所必需的信息或者资源。
最小权限的生活场景理解:使用方面 - 一个用户应该只能访问履行他的相关职责所需访问的数据和硬件。安全层面 - 每个合法动作最小权限,保护数据及功能,避免遭受恶意破坏的机率。
linux最小化原则示例
最小化原则对Linux系统安全来说非常重要,一般包括如下几个方面:
1.安装Linux系统最小化,即选包最小化,yum安装软件包也要最小化,没用的包不装。
2.开机自启动服务最小化,即没用的服务不开启。
3.操作命令最小化。例如:能用“rm -f 就不用 rm -rf 。
4.登录Linux用户最小化。平时没有特殊需求不登录root,用普通用户登录即可。
5.普通用户授权权限最小化,即只给用户必需的管理系统的命令。
6.Linux系统文件及目录的权限设置最小化,禁止随意创建、更改、删除文件。
原则的重要性
1 提高安全防御机率大部分的安全攻击手段,都是借助于信息检测漏洞、权限管理漏洞、配置管理漏洞等因素导致,通过加强该有的安全防护手段,提高安全防御的机率。
2 降低危险范围扩大通过在相关场景实施最小权限手段,常用的恶意攻击手段造成的影响和作用范围就会缩小,降低同等安全等级的攻击影响。
3 加强安全体系建设通过多层次的权限体系设计,有助于保护关键业务系统的稳定运行,尤其是可以借助于最小权限原则来帮助或者证明项目操作活动的合规性。
如何实施最小特权原则
用户层面 - 基于岗位角色划分与职位内容适配的权限
软件层面 - 基于数据的请求进行数据信息正确性检测
操作层面 - 根据场景的变化,灵活使用多层资源操作权限
管理层面 - 命令审计机制、操作合规性、内部管理培训等,避免用户违规操作。
服务层面 - 结合多种检测机制,有效监控和告警权限异常行为
小结
1.1.2 安全上下文
学习目标
这一节,我们从 基础知识、属性解析、小结 三个方面来学习。
基础知识
容器基础
我们知道容器一般是基于 6个命名空间实现资源的隔离,而一个 Pod 就是一个容器集合,包含多个容器,那么在这种情况下,这几者命名空间是按照下面方式来使用的:- 内部的所有容器共享底层 pause容器的 UTS|Network 量个名称空间资源- 可选共享命名空间:IPC,PID- MNT和USER 两个命名空间默认没有让他们共享 -- 细节应用的隔离。
Pod安全体系
pod在其生命周期中,涉及到多种场景(多容器的关联关系),我们将这种相关的作用关系 称为容器上下文,而涉及到权限、限制等安全相关的内容,我们称其为 安全上下文。我们也可以将其称之为 一组用于决定容器是如何创建和运行的约束条件,他们代表创建和运行容器时使用的运行时参数。它根据约束的作用范围主要包括三个级别:Pod级别:针对pod范围内的所有容器容器级别:仅针对pod范围内的指定容器PSP级别:PodSecurityPolicy,全局级别的Pod安全策略,涉及到准入控制相关知识
Pod的策略安全性级别
Pod 安全性标准定义了三种不同的策略(Policy),以广泛覆盖安全应用场景。 这些策略是叠加式的(Cumulative),安全级别从高度宽松至高度受限。Privileged 不受限制的策略,提供最大可能范围的权限许可。此策略允许已知的特权提升。此类策略通常针对由特权较高、受信任的用户所管理的系统级或基础设施级负载。Baseline 限制性最弱的策略,禁止已知的策略提升。允许使用默认的(规定最少)Pod 配置。此策略针对的是应用运维人员和非关键性应用的开发人员。Restricted 限制性非常强的策略,遵循当前的保护 Pod 的最佳实践。该类策略主要针对运维人员和安全性很重要的应用的开发人员,以及不太被信任的用户。
注意:PSP安全策略则是控制面用来对安全上下文以及安全性上下文之外的参数实施某种设置的机制。在2020年7月, Pod 安全性策略已被废弃,取而代之的是内置的 Pod 安全性准入控制器。
安全上下文作用
安全上下文包括但不限于:自主访问控制(Discretionary Access Control):基于用户ID和组ID来判定对对象的访问权限。安全性增强的Linux(SELinux):为对象赋予安全性标签。以特权模式或者非特权模式运行。Linux 权能: 为进程赋予 root 用户的部分特权而非全部特权。AppArmor:使用程序配置来限制个别程序的权能。Seccomp:过滤进程的系统调用。allowPrivilegeEscalation:控制进程是否可以获得超出其父进程的特权。 以特权模式运行具有 CAP_SYS_ADMIN 权能readOnlyRootFilesystem:以只读方式加载容器的根文件系统。
安全上下文属性
apiVersion: v1
kind: Pod
metadata: {…}
spec:securityContext: # Pod级别的安全上下文,对内部所有容器均有效runAsUser <integer> # 以指定的用户身份运行容器进程,默认由镜像中的USER指定runAsGroup <integer> # 以指定的用户组运行容器进程,默认使用的组随容器运行时supplementalGroups <[]integer> # 为容器中1号进程的用户添加的附加组;fsGroup <integer> # 为容器中的1号进程附加的一个专用组,其功能类似于sgidrunAsNonRoot <boolean> # 是否以非root身份运行seLinuxOptions <Object> # SELinux的相关配置sysctls <[]Object> # 应用到当前Pod上的名称或网络空间级别的sysctl参数设置列表windowsOptions <Object> # Windows容器专用的设置containers:- name: …image: …securityContext: # 容器级别的安全上下文,仅生效于当前容器runAsUser <integer> # 以指定的用户身份运行容器进程runAsGroup <integer> # 以指定的用户组运行容器进程runAsNonRoot <boolean> # 是否以非root身份运行allowPrivilegeEscalation <boolean> # 是否允许特权升级capabilities <Object> # 于当前容器上添加(add)或删除(drop)的操作内核某些资源的能力add <[]string> # 添加由列表格式定义的各内核能力drop <[]string> # 移除由列表格式定义的各内核能力privileged <boolean> # 是否运行为特权容器procMount <string> # 设置容器的procMount类型,默认为DefaultProcMount;readOnlyRootFilesystem <boolean> # 是否将根文件系统设置为只读模式seLinuxOptions <Object> # SELinux的相关配置windowsOptions <Object> # windows容器专用的设置注意:上面的属性,仅仅是最常用的属性,而不是所有的属性这些属性是在Pod资源对象的基础上来实施的
属性解析
容器用户级别的属性 runAsUser、runAsGroup 以指定的用户属性运行容器进程
相关的资源能力CAP_CHOWN 改变UID和GIDCAP_MKNOD: mknod(),创建设备文件; CAP_NET_ADMIN 网络管理权限; CAP_SYS_ADMIN 大部分的管理权限; CAP_NET_BIND_SERVER 允许普通用户绑定1024以内的特权端口更多的CAP相关的属性可以通过 capsh --print 命令来进行查看
特权权限能力修改宿主机相关内核参数
简单实践
定制资源清单文件
定制资源配置文件 01_kubernetes_server_secure_pod_test.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx-web
spec:containers:- name: nginx-webimage: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1env:- name: HELLOvalue: "Hello Nginx"创建资源
kubectl apply -f 01_kubernetes_server_secure_pod_test.yaml
检查效果
# kubectl get pod
# kubectl exec -it nginx-web -- id
uid=0(root) gid=0(root) 关闭资源
kubectl delete -f 01_kubernetes_server_secure_pod_test.yaml
容器用户实践
资源清单文件 02_kubernetes_server_secure_container_user.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx-web
spec:securityContext:runAsUser: 1000runAsGroup: 1000containers:- name: nginx-webimage: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1env:- name: HELLOvalue: "Hello Nginx"- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]
注意:这里使用的1000默认是容器内部的,而容器内部的1000本质上是映射宿主机上的1000id本地如果没有1000id,的话,ps查看的是1000,本地有1000的用户的话,ps查看到的是用户名如果忽略runAsGroup字段,则容器的主组 ID 将是 root(0)创建资源
kubectl apply -f 02_kubernetes_server_secure_container_user.yaml
查看pod运行在那个节点上
kubectl get pod nginx-web -o wide到制定node节点上用ps检查
[root@kubernetes-node2 ~]# id 1000
uid=1000(python) gid=1000(python) 组=1000(python)
[root@kubernetes-node2 ~]# ps aux | grep python
python 80649 0.0 0.0 980 4 ? Ss 12:54 0:00 /pause
python 80803 0.0 0.0 1304 4 ? Ss 12:54 0:00 sleep 1h
结果显示:busybox容器运行的用户就是我们指定的
由于容器内部的应用想要使用普通用户执行,必须让程序支持普通用户,否则的话容器应用无法正常运行
]# kubectl logs nginx-web -c nginx-web
/data/scripts/startup.sh: line 5: /usr/share/nginx/html/index.html: Permission denied
2022/09/11 04:54:18 [warn] 7#7: the "user" directive makes sense only if the master process runs with super-user privileges, ignored in /etc/nginx/nginx.conf:2
nginx: [warn] the "user" directive makes sense only if the master process runs with super-user privileges, ignored in /etc/nginx/nginx.conf:2
2022/09/11 04:54:18 [emerg] 7#7: mkdir() "/var/cache/nginx/client_temp" failed (13: Permission denied)
nginx: [emerg] mkdir() "/var/cache/nginx/client_temp" failed (13: Permission denied)
小结
1.1.3 资源实践
学习目标
这一节,我们从 容器级别、禁用root、小结 三个方面来学习。
容器级别
简介
Security Context有两种作用范围:Pod 内部所有应用容器 - pod.spec.securityContextPod 内部特定的应用容器- pod.spec.containers.securityContext
注意:这两种安全上下文的定制,容器内部的优先级要高一些。
简单实践
资源对象文件 03_kubernetes_server_secure_container_user.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-test
spec:securityContext:runAsUser: 1000runAsGroup: 1000containers:- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:runAsUser: 2000
应用资源清单文件
kubectl apply -f 03_kubernetes_server_secure_container_user.yaml确认效果
]# kubectl exec -it busybox-test -- id
uid=2000 gid=1000
结果显示:容器内部的安全上下文等级高一些还原环境
kubectl delete -f 03_kubernetes_server_secure_container_user.yaml
禁用root
简介
默认情况下,容器的启用是以root用户身份来进行启动的,有时候,我们为了提升容器的运行安全,会禁止容器使用root身份进行启动。对于这种场景,我们可以在securityContext中通过runAsNonRoot属性来快速实现。
如果 runAsNonRoot 字段配置为 true,kubelet 在启动容器时会进行检查,如果以 UID 为 0 运行,则禁止容器启动,该 Pod 的 STATUS 变为 CreateContainerConfigError,并生成 Warning 类型事件 Error: container has runAsNonRoot and image will run as root。只有当设置 runAsUser 或者镜像本身就不是以 Root 身份运行时,该 Pod 才能正常启动。
简单实践
资源对象文件 04_kubernetes_server_secure_container_noroot.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-test
spec:securityContext:runAsNonRoot: yescontainers:- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]- name: busybox-test2image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:runAsUser: 2000
应用资源清单文件
kubectl apply -f 04_kubernetes_server_secure_container_noroot.yaml确认效果
]# kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox-test 1/2 CreateContainerConfigError 0 5s
]# kubectl describe pod busybox-test
Events:Type Reason Age From Message---- ------ ---- ---- -------...Warning Failed 0s (x4 over 14s) kubelet Error: container has runAsNonRoot and image will run as root (pod: "busybox-test_default(7921d9a1-640e-4c22-a211-948d5215f27b)", container: busybox-test)
结果显示:容器因为安全上下文的属性而无法启动,只有满足条件的应用容器才可以正常启动还原环境
kubectl delete -f 04_kubernetes_server_secure_container_noroot.yaml
小结
1.1.4 特权基础
学习目标
这一节,我们从 特权解读、内核实践、小结 三个方面来学习。
特权解读
简介
默认情况下,容器是不可以访问宿主上的任何设备的,这可以实现一定程度上的容器安全,但是因为一些开发场景的需求 -- Docker-in-Docker,即在Docker的基础上,可以模拟宿主机操作docker等超越容器本身权限的一些功。像这种能够在容器内部执行特权指令的模式,我们把它们称之为特权模式。
注意:特权模式是为了方便容器应用在一定程度上能够操作宿主机相关的权限,但是无论是细粒度权限控制还是其他安全机制,用户都可以通过修改容器环境配置或在运行容器时指定参数来缩小或扩大约束。但是如果用户为不完全受控的容器提供了一些危险的配置参数,就为恶意攻击者提供了一定程度的攻击可能性。
示例:kubernetes的kube-proxy组件,它以pod样式存在,它的主要目的就是pod的流量访问规则的转换,也就是说它需要使用宿主机的内核功能,实现一些防火墙策略的规则生效,我们来看一下它的yaml文件是如何定制的。
[root@kubernetes-master1 ~]# kubectl get pod kube-proxy-594xs -n kube-system -o yaml
apiVersion: v1
kind: Pod
metadata:...name: kube-proxy-594xsnamespace: kube-system...
spec:...containers:...securityContext:privileged: true...
为了让pod获取宿主机内核的完整权限,pod 需要在特权模式下运行。这可以通过将容器securityContext 中的 privileged 设置为true实现。
资源清单文件 05_kubernetes_server_secure_container_privileged.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-test
spec:containers:- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]- name: busybox-test2image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:privileged: true
注意:这里使用securityContext 的 privileged 属性来开启pod的特权模式应用资源对象
kubectl apply -f 05_kubernetes_server_secure_container_privileged.yaml
查看效果
[root@kubernetes-master1 /data/kubernetes/server_secure]# kubectl exec -it busybox-test -c busybox-test -- ls /dev
core null shm termination-log
fd ptmx stderr tty
full pts stdin urandom
mqueue random stdout zero
[root@kubernetes-master1 /data/kubernetes/server_secure]# kubectl exec -it busybox-test -c busybox-test2 -- ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdc
结果显示:特权模式下的pod可以看到宿主机的很多内容
内核实践
简介
从 Kubernetes 1.23 版本开始,kubelet 支持使用 / 或 . 作为 sysctl 参数的分隔符。 从 Kubernetes 1.25 版本开始,支持为 Pod 设置 sysctl 时使用设置名字带有斜线的 sysctl。 也就是说,我们可以以如下的样式来设定系统的内核参数:点样式:kernel.shm_rmid_forced/样式:kernel/shm_rmid_forced
更多的内核参数:https://www.kernel.org/doc/Documentation/sysctl/README
内核参数
sysctl 参数分为安全和非安全的。 安全的 sysctl参数除了需要设置恰当的命名空间外,在同一节点上的不同Pod之间也必须是相互隔离的。这意味着Pod上设置安全sysctl参数有以下限制:必须不能影响到节点上的其他 Pod必须不能损害节点的健康必须不允许使用超出 Pod 的资源限制的 CPU 或内存资源。
大多数 有命名空间的 sysctl 参数不一定被认为是 安全 的。 以下几种 sysctl 参数是 安全的:kernel.shm_rmid_forced 表示是否强制将共享内存和一个进程联系在一起,这样的话可以通过杀死进程来释放共享内存net.ipv4.ip_local_port_range 表示pod允许使用的端口范围,示例:1024 65000net.ipv4.tcp_syncookies表示是否打开TCP同步标签,同步标签可以防止一个套接字在有过多试图连接时引起过载net.ipv4.ping_group_range(从 Kubernetes 1.18 开始)net.ipv4.ip_unprivileged_port_start(从 Kubernetes 1.22 开始)。注意:net.ipv4.tcp_syncookies 在Linux 内核 4.4 或更低的版本中是无命名空间的。
注意:所有安全的sysctl参数都默认启用,所有非安全的sysctl 参数都默认禁用,且必须由集群管理员在每个节点上手动开启。那些设置了不安全sysctl参数的Pod仍会被调度,但默认情况下无法正常启动。如需启用非安全的 sysctl参数,需要在每个节点上分别设置 kubelet 命令行参数,例如:kubelet --allowed-unsafe-sysctls '参数1,参数2' ...
简单实践
准备工作,kubernetes-node2 开启非安全参数,修改 kubelet的配置文件
[root@kubernetes-node2 ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS='--allowed-unsafe-sysctls=net.core.somaxconn'参数解析:net.core.somaxconn 网卡入栈的最大连接数在所有的node角色节点上配置该文件,然后重启该服务
[root@kubernetes-node2 ~]# systemctl restart kubelet
资源清单文件 06_kubernetes_server_secure_container_privileged_sysctl.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-test1
spec:securityContext:sysctls:- name: net.core.somaxconnvalue: "6666"nodeName: kubernetes-node1containers:- name: busybox-test1image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]
---
apiVersion: v1
kind: Pod
metadata:name: busybox-test2
spec:securityContext:sysctls:- name: net.core.somaxconnvalue: "6666"nodeName: kubernetes-node2containers:- name: busybox-test2image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]
属性解析:net.core.somaxconn 表示socket监听的队列数量上限应用资源清单文件
kubectl apply -f 06_kubernetes_server_secure_container_privileged_sysctl.yaml
检查效果
[root@kubernetes-master1 /data/kubernetes/server_secure]# kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox-test1 0/1 SysctlForbidden 0 13s
busybox-test2 1/1 Running 0 13s查看报错
[root@kubernetes-master1 /data/kubernetes/server_secure]# kubectl describe pod busybox-test1
Name: busybox-test1
Namespace: default
...
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning SysctlForbidden 92s kubelet forbidden sysctl: "net.core.somaxconn" not allowlisted
结果显示:小结
1.1.5 特权实践
学习目标
这一节,我们从 特权粒度、简单实践、小结 三个方面来学习。
特权粒度
简介
当我们为pod启用特权模式之后,就意味着我们为pod内部的容器提供了访问linux内核的所有能力,虽然k8s对于部分的内核参数做了一些所谓的策略限制,但是毕竟这还是很危险的,所以我们为了进一步提升特权模式下的安全,我们可以减少内核系统调用的供给 -- 使用Capabilities属性来限制能够使用的特权操作指令Capabiliteis 是一个内核级别的权限,它允许对内核调用权限进行更细力度的控制,而不是简单地以root身份进行资源的授权,这些权限包括文件权限、网络系统、系统管理等功能。
简单来说:privileged 属性的使用,代表启用特权模式安全风险比较大,不懂的话,不要乱用Capabilities 的目的是限制某些特殊权限的使用
查看常见的Capabilities权限内容
[root@kubernetes-node2 ~]# capsh --print
Current: = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,35,36+ep
Bounding set =cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,35,36
Securebits: 00/0x0/1'b0secure-noroot: no (unlocked)secure-no-suid-fixup: no (unlocked)secure-keep-caps: no (unlocked)
uid=0(root)
gid=0(root)
groups=0(root)
常见属性解析CAP_CHOWN:改变UID和GID; CAP_MKNOD:mknod(),创建设备文件; CAP_NET_ADMIN:网络管理权限; CAP_SYS_ADMIN:大部分的管理权限; CAP_SYS_TIME:更改系统的时钟CAP_SYS_MODULE:装载卸载内核模块CAP_NET_BIND_SERVER:允许普通用户绑定1024以内的特权端口
配置样式securityContext:capabilities:add: ["NET_ADMIN","SYS_TIME"] # 增加属性drop: ["CHOWN"] # 删减属性
简单实践
准备工作
构建nginx专属镜像,增加Dockerfile的暴露端口8000和iptables环境
[root@kubernetes-master1 /data/images/web/nginx]# cat Dockerfile
# 构建一个基于nginx的定制镜像
# 基础镜像
FROM kubernetes-register.superopsmsb.com/superopsmsb/nginx
# 镜像作者
MAINTAINER shuji@superopsmsb.com# 增加iptables命令
RUN apt update && apt install iptables -y# 添加文件
ADD scripts/startup.sh /data/scripts/startup.sh# 执行命令
CMD ["/bin/bash", "/data/scripts/startup.sh"]# 开放端口
EXPOSE 80 443 8000
构建镜像
docker build -t kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.3 .
提交镜像
docker push kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.3
简单实践
资源清单文件:07_kubernetes_server_secure_container_privileged_capabilities.yaml
apiVersion: v1
kind: Pod
metadata:name: nginx-web1
spec:containers:- name: nginximage: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.3
---
apiVersion: v1
kind: Pod
metadata:name: nginx-web2
spec:containers:- name: nginximage: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.3securityContext:capabilities:add: ["NET_ADMIN","SYS_TIME"]
---
apiVersion: v1
kind: Pod
metadata:name: nginx-web3
spec:containers:- name: nginximage: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.3securityContext:capabilities:add: ["NET_ADMIN","SYS_TIME"]drop: ["CHOWN"]
nginx-web1测试效果
[root@kubernetes-master1 /data/kubernetes/server_secure]# kubectl exec -it nginx-web1 -- /bin/bash
root@nginx-web1:/# date
Mon Sep 12 00:44:53 UTC 2062
root@nginx-web1:/# date -s 19:09
date: cannot set date: Operation not permitted
Mon Sep 12 19:09:00 UTC 2062root@nginx-web1:/# iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8000
结果显示:nginx-web1 上不可以更改系统的时间,也不允许设定iptabels防火墙
nginx-web2测试效果
[root@kubernetes-master1 ~]# kubectl exec -it nginx-web2 -- /bin/bash
root@nginx-web2:/# date -s 19:09
Mon Sep 12 19:09:00 UTC 2062
root@nginx-web1:/# iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8000
root@nginx-web1:/# iptables -vnL -t nat
结果显示:nginx-web2 上可以更改系统的时间还可以设定iptables防火墙
nginx-web2测试效果
[root@kubernetes-master1 ~]# kubectl logs nginx-web3
2022/09/12 19:09:08 [emerg] 7#7: chown("/var/cache/nginx/client_temp", 101) failed (1: Operation not permitted)
nginx: [emerg] chown("/var/cache/nginx/client_temp", 101) failed (1: Operation not permitted)
结果显示:因为我们将相关权限命令移除了,所以服务无法启动
小结
1.1.5 PSP实践
学习目标
这一节,我们从 案例解读、准入实践、小结 三个方面来学习。
案例解读
简介
我们曾经学习过的PSP,它的目的就是基于内置准入控制器的作用,实现pod级别的更加精细化的能力控制
启用psp功能
编辑 /etc/kubernetes/manifests/kube-apiserver.yaml 文件,添加如下配置--enable-admission-plugins=NodeRestriction,PodSecurityPolicy由于kubeadm集群中,api-server是以静态pod的方式来进行管控的,所以我们不用重启,稍等一会,环境自然就开启了PSP功能
因为PSP默认已经禁用所有的pod创建权限,所以默认情况下,我们也看不到api-server的pod的
kubectl get pod -n kube-system | grep api
注意:如果出现api-server的pod,是因为其他master启用PSP太慢导致的。我们只能通过端口方式来进行检测
[root@kubernetes-master1 ~]# netstat -atnulp | grep 6443
tcp 0 0 10.0.0.12:52818 10.0.0.12:6443 ESTABLISHED 108627/kube-control
tcp 0 0 10.0.0.12:36852 10.0.0.200:6443 ESTABLISHED 127389/kubelet
tcp 0 0 10.0.0.12:52350 10.0.0.12:6443 ESTABLISHED 123701/kube-schedul
tcp 0 0 10.0.0.12:36314 10.0.0.200:6443 ESTABLISHED 3109/kube-proxy
...
结果显示:只要我们能够看到 6443,说明kube-apiserver服务已经启动成功了
测试效果
kubectl run nginx-web --image kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1
kubectl get pod
准入实践
简单实践
资源清单文件 08_kubernetes_server_secure_container_privileged_psp.yaml
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:name: psp-restrictive
spec:privileged: false # 禁用特权模式runAsUser:rule: MustRunAsNonRoot: yesfsGroup:rule: RunAsAnysupplementalGroups:rule: RunAsAnyvolumes:- '*'创建资源对象
kubectl apply -f 08_kubernetes_server_secure_container_privileged_psp.yaml
定制角色权限
kubectl create clusterrole psp-restrictive --verb=use --resource=podsecuritypolicies --resource-name=psp-restrictive --dry-run=clientkubectl create clusterrole psp-restrictive --verb=use --resource=podsecuritypolicies --resource-name=psp-restrictive --dry-run=client -o yaml >> 09_kubernetes_server_secure_container_privileged_rbac.yaml
echo '---' >> 09_kubernetes_server_secure_container_privileged_rbac.yaml
定制角色授权
kubectl create clusterrolebinding psp-restrictive --clusterrole=psp-restrictive --group="system:serviceaccounts" --dry-run=client -o yamlkubectl create clusterrolebinding psp-restrictive --clusterrole=psp-restrictive --group="system:serviceaccounts" --dry-run=client -o yaml >> 09_kubernetes_server_secure_container_privileged_rbac.yaml
应用资源清单文件
kubectl apply -f 09_kubernetes_server_secure_container_privileged_rbac.yaml
测试效果
kubectl delete pod nginx-web
kubectl run nginx-web --image kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1
kubectl get pod
结果显示:正常的资源可以正常的创建
清理环境
kubectl delete -f 08_kubernetes_server_secure_container_privileged_psp.yaml
kubectl delete -f 09_kubernetes_server_secure_container_privileged_rbac.yaml
小结
1.2 策略方案
1.2.1 OPA简介
学习目标
这一节,我们从 场景解读、细节解读、小结 三个方面来学习。
场景解读
简介
虽然我们可以借助于RBAC + PSP + 安全上下文 能够实现相当层次的pod应用安全(包括对特权容器、主机网络、Capability、加载卷类型等内容进行限制),但是这套方案有以下限制:1 PSP 在1.21版本就被弃用,在1.25版本被删除 -- 整合进准入控制器2 PSP 仅仅支持Pod级别的策略3 方案使用起来很复杂,而且操作的技术门槛较高,容易引起很大的漏洞。
对于Kubernetes来说,虽然未来弃用了PSP能力,但是对于CIS Kubernetes Benchmark来说,它目前仍然将PSP作为集群安全加固的检测条目,而且很多Kubernetes 安全相关软件也会据此进行检查。所以我们有必要在未来的Kubernetes版本中去寻找PSP的替代方案,常见的替代方案有:升级 PSP- 加强PSP能力第三方策略引擎OPA Gatekeeper 和 Kyverno,从另外一条路实现PSP的能力缺省启用宽松策略- 特殊应用无需PSP的能力
参考资料:https://kubernetes.io/docs/concepts/security/pod-security-policy/https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/migrate-from-psp/https://kubernetes.io/blog/2021/04/06/podsecuritypolicy-deprecation-past-present-and-future/https://kubernetes.io/blog/2019/08/06/opa-gatekeeper-policy-and-governance-for-kubernetes/https://github.com/open-policy-agent/gatekeeperhttps://github.com/kyverno/kyverno
功能定位
如果您需要在 Kubernetes平台上寻找如何控制终端用户在集群上的行为,以及如何确保集群符合公司政策,或者说在不牺牲开发敏捷性和运营独立性的前提下确保运维合规性的话,以下策略是可以参考的点:所有镜像必须来自获得批准的存储库所有入口主机名必须是全局唯一的所有 Pod 必须有资源限制所有命名空间都必须具有列出联系的标签策略引擎的目的是使用户能够通过配置(而不是代码)自定义控制许可,并使用户了解集群的状态,而不仅仅是针对评估状态的单个对象,在这些对象准许加入的时候。大量的第三方策略引擎产品中,Gatekeeper是Kubernetes的一个可定制的许可webhook,它由Open Policy Agent (OPA)强制执行,OPA是Cloud Native环境下的策略引擎,由 CNCF 维护。
引擎简介
Gatekeeper的发展现后经历了 v1.0、v2.0、v3.0的阶段,前两个阶段是以sidecar的方式来存在,目前它是以准入控制器的方式集成在一起,用来实施基于 CRD 的策略,并可以可靠地共享已完成声明配置的策略。Gatekeeper目前的策略相关的配置需要借助于Rego语法来定制策略模板。官方文档:https://www.openpolicyagent.org/https://play.openpolicyagent.org/

细节解读
简介
Gatekeeper 是基于OPA的一个Kubernetes策略解决方案,可以从另外一个角度实现PSP+RBAC+安全上下文的部分功能。对于Gatekeeper来说,我们需要部署相关的环境组件,然后作为APIServer的代理人来存在,用于对所有资源的创建、更新、删除操作请求的校验,只有校验通过的请求才可以进行正常的执行,否则就被拒绝
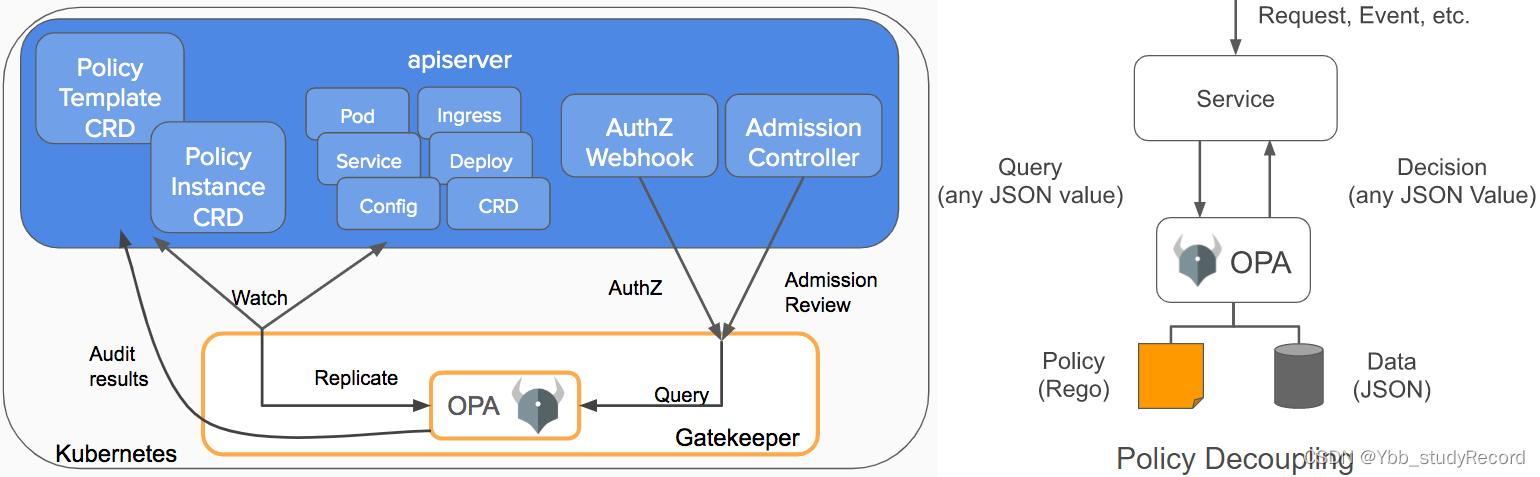
github地址:https://github.com/open-policy-agent/gatekeeperhttps://open-policy-agent.github.io/gatekeeper/website/docs/install/
环境部署
获取资源对象
cd /data/kubernetes/server_secure
mkdir gatekeeper && cd gatekeeper
wget https://raw.githubusercontent.com/open-policy-agent/gatekeeper/master/deploy/gatekeeper.yaml
cp gatekeeper.yaml{,.bak}
查看镜像文件
]# grep image: gatekeeper.yaml | uniqimage: openpolicyagent/gatekeeper:v3.10.0-beta.1获取镜像
docker pull openpolicyagent/gatekeeper:v3.10.0-beta.1
docker tag openpolicyagent/gatekeeper:v3.10.0-beta.1 kubernetes-register.superopsmsb.com/google_containers/gatekeeper:v3.10.0-beta.1
docker push kubernetes-register.superopsmsb.com/google_containers/gatekeeper:v3.10.0-beta.1
docker rmi openpolicyagent/gatekeeper:v3.10.0-beta.1修改文件
sed -i 's#openpolicyagent#kubernetes-register.superopsmsb.com/google_containers#g' gatekeeper.yaml确认效果
]# grep image: gatekeeper.yaml | uniq image: kubernetes-register.superopsmsb.com/google_containers/gatekeeper:v3.10.0-beta.1
部署Gatekeeper
应用资源对象
kubectl apply -f gatekeeper.yaml确认效果
]# kubectl get all -n gatekeeper-system
NAME READY STATUS RESTARTS AGE
pod/gatekeeper-audit-574546775d-245k2 1/1 Running 0 32s
pod/gatekeeper-controller-manager-7bfd877599-j2nzc 1/1 Running 0 32s
pod/gatekeeper-controller-manager-7bfd877599-mj4wv 1/1 Running 0 32s
pod/gatekeeper-controller-manager-7bfd877599-tmx75 1/1 Running 0 32sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/gatekeeper-webhook-service ClusterIP 10.110.191.72 <none> 443/TCP 33sNAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/gatekeeper-audit 1/1 1 1 33s
deployment.apps/gatekeeper-controller-manager 3/3 3 3 33sNAME DESIRED CURRENT READY AGE
replicaset.apps/gatekeeper-audit-574546775d 1 1 1 33s
replicaset.apps/gatekeeper-controller-manager-7bfd877599 3 3 3 33s
确认CRD资源
]# kubectl get crd | grep gate
assign.mutations.gatekeeper.sh 2062-09-12T03:38:24Z
assignmetadata.mutations.gatekeeper.sh 2062-09-12T03:38:25Z
configs.config.gatekeeper.sh 2062-09-12T03:38:25Z
constraintpodstatuses.status.gatekeeper.sh 2062-09-12T03:38:25Z
constrainttemplatepodstatuses.status.gatekeeper.sh 2062-09-12T03:38:25Z
constrainttemplates.templates.gatekeeper.sh 2062-09-12T03:38:25Z
modifyset.mutations.gatekeeper.sh 2062-09-12T03:38:25Z
mutatorpodstatuses.status.gatekeeper.sh 2062-09-12T03:38:26Z
providers.externaldata.gatekeeper.sh 2062-09-12T03:38:26Z
小结
1.2.2 特权策略
学习目标
这一节,我们从 属性解读、简单实践、小结 三个方面来学习。
属性解读
策略简介
Gatekeeper 的策略通常是由两个资源对象组成的:Template 和 Constraint。Template包括两部分组成:crd 的确是一个 CRD 定义,也就是说生成一个 Template CR 对象,会随之生成一个 CRDtargets 则是一组 rego 为主体的代码包,定制阻止资源创建的规则。Contsraint:定制资源对象创建的约束信息基于 Template 生成的 CRD对象,创建被CRD约束的资源对象列表和范围
模板示例
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: 自定义资源名称
spec:crd:spec:names:kind: 定制资源类型targets:- target: admission.k8s.gatekeeper.shrego: |package admission # 定制检测规则# 检测结果如果为True(默认),则表明违反约束限制信息,无法创建资源对象violation[{"msg": msg}] {# input.review.object 从接收的资源对象中获取信息# spec.template.spec.containers 指的是从资源对象的属性信息中获取检测值containers = input.review.object.spec.template.spec.containers...msg := sprintf() # 打印相关的信息}
约束示例
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: 自定义资源的类型名称
metadata:name: 自定义约束的名称
spec:match: # 匹配的资源对象信息namespaces: ["default"]kinds:- apiGroups: ["apps"]kinds:- "Deployment"
简单实践
定制策略模板
策略模板文件 08_kubernetes_server_secure_gatekeeper_template.yaml
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: deploy-privileged
spec:crd:spec:names:kind: deploy-privilegedtargets:- target: admission.k8s.gatekeeper.shrego: |package admissionviolation[{"msg": msg}] {containers := input.review.object.spec.template.spec.containerscontainer_name := containers[0].namecontainers[0].securityContext.privilegedmsg := sprintf("提示: Deployment资源对象内部的 %v 容器禁止启用特权模式", [container_name])}
---
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: pod-privileged
spec:crd:spec:names:kind: pod-privilegedtargets:- target: admission.k8s.gatekeeper.shrego: |package admissionviolation[{"msg": msg}] {containers := input.review.object.spec.containerscontainer_name := containers[0].namecontainers[0].securityContext.privilegedmsg := sprintf("提示: Pod资源对象内部的 %v 容器禁止启用特权模式 ", [container_name])}
注意:package 标记go程序的入口,首行必须是它先创建模板,再创建约束,约束的name必须与模板的名称一样,否则无法使用,使用方式类似于RBAC%v 代表默认的数据格式
功能:校验成功,标识匹配成功,需要拒绝请求,否则拒绝规则匹配失败,允许请求通过
应用资源对象
kubectl apply -f 08_kubernetes_server_secure_gatekeeper_template.yaml确认效果
]# kubectl get constrainttemplate
NAME AGE
privileged 20s
定义约束
约束资源文件 09_kubernetes_server_secure_gatekeeper_constraint.yaml
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: deploy-privileged
metadata:name: deploy-privileged
spec:match:namespaces: ["default"]kinds:- apiGroups: ["apps"]kinds:- "Deployment"
---
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: pod-privileged
metadata:name: pod-privileged
spec:match:namespaces: ["default"]kinds: - apiGroups: [""]kinds:- "Pod"
应用资源清单文件
kubectl apply -f 09_kubernetes_server_secure_gatekeeper_constraint.yaml确认效果
kubectl get privileged
定制资源测试文件 10_kubernetes_server_secure_gatekeeper_test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-web
spec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- image: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1name: nginxsecurityContext:privileged: true
---
apiVersion: v1
kind: Pod
metadata:name: busybox-test1
spec:containers:- name: busybox1image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]- name: busybox2image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:privileged: true
---
apiVersion: v1
kind: Pod
metadata:name: busybox-test2
spec:containers:- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:privileged: true
测试效果
]# kubectl apply -f 10_kubernetes_server_secure_gatekeeper_test.yaml
pod/busybox-test1 created
Error from server (Forbidden): error when creating "10_kubernetes_server_secure_gatekeeper_test.yaml": admission webhook "validation.gatekeeper.sh" denied the request: [deploy-privileged] 提示: Deployment资源对象内部的 nginx 容器禁止启用特权模式
Error from server (Forbidden): error when creating "10_kubernetes_server_secure_gatekeeper_test.yaml": admission webhook "validation.gatekeeper.sh" denied the request: [pod-privileged] 提示: Pod资源对象内部的 busybox-test 容器禁止启用特权模式]# kubectl apply -f 10_kubernetes_server_secure_gatekeeper_test.yaml -n superopsmsb
deployment.apps/nginx-web created
pod/busybox-test1 created
pod/busybox-test2 created
结果显示:无论是pod还是deployment级别的问题都检测出来了由于检测规则的漏洞所以导致default空间中的一个pod被创建成功了
小结
1.2.3 策略进阶
学习目标
这一节,我们从 SA检测、镜像检测、小结 三个方面来学习。
SA检测
简介
创建SA资源对象的时候,登录用户名必须与命名空间名称一致
简单实践
策略模板文件 11_kubernetes_server_secure_gatekeeper_nscheck.yaml
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: namespace-check
spec:crd:spec:names:kind: namespace-checktargets:- target: admission.k8s.gatekeeper.shrego: |package nsuserviolation[{"msg": msg}] {sa_name = input.review.userInfo.usernamenamespace = input.review.object.metadata.namespacenot startswith(sa_name, namespace)msg := sprintf("提示: 服务账号 %v 不允许到 %v 命名空间中创建SA ", [sa_name, namespace])}
---
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: namespace-check
metadata:name: namespace-check
spec:match:kinds:- apiGroups: [""]kinds: ["ServiceAccount"]应用资源清单文件
kubectl apply -f 11_kubernetes_server_secure_gatekeeper_nscheck.yaml
注意:因为ConstraintTemplate必须在constraints之前创建,所以有可能需要执行两遍
测试效果
查看当前登录用户
]# kubectl config view | grep 'user: 'user: kubernetes-admin尝试创建sa
]# kubectl create sa nihao
error: failed to create serviceaccount: admission webhook "validation.gatekeeper.sh" denied the request: [namespace-check] 提示: 服务账号 kubernetes-admin 不允许到 default 命名空间中创建SA创建Sa
kubectl create ns kubernetes-admin
kubectl create sa nihao -n kubernetes-admin
结果显示:由于登录用户和namespace的名称一致,则创建成功
简介
创建资源对象的时候,镜像的仓库名称必须符合特定的要求
简单实践
策略模板文件 12_kubernetes_server_secure_gatekeeper_imagecheck.yaml
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: imagecheck
spec:crd:spec:names:kind: imagecheckvalidation:openAPIV3Schema:properties:prefix:type: stringtargets:- target: admission.k8s.gatekeeper.shrego: |package imageviolation[{"msg": msg}] {containers = input.review.object.spec.template.spec.containerssome iimage := containers[i].imagenot startswith(image, input.parameters.prefix)msg := sprintf("提示: 镜像 '%v' 的仓库不符合要求.", [image])}
---
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: imagecheck
metadata:name: imagecheck
spec:match:kinds:- apiGroups: ["apps"]kinds:- "Deployment"parameters:prefix: "kubernetes-register.superopsmsb.com/"应用资源清单文件
kubectl apply -f 12_kubernetes_server_secure_gatekeeper_imagecheck.yaml
注意:因为ConstraintTemplate必须在constraints之前创建,所以有可能需要执行两遍
测试效果
尝试创建deployment
]# kubectl create deployment my-deploy --image=nginx
error: failed to create deployment: admission webhook "validation.gatekeeper.sh" denied the request: [imagecheck] 提示: 镜像 'nginx' 的仓库不符合要求.创建deployment
]# kubectl create deployment my-deploy --image=kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1
deployment.apps/my-deploy created
结果显示:只有符合要求的资源对象才会进行正常的创建
小结
1.3 资源限制
1.3.1 AppArmor简介
学习目标
这一节,我们从 软件简介、环境部署、小结 三个方面来学习。
软件简介
场景定位
网络攻击越来越复杂,攻击频率越来越高,目前来说,由网络犯罪造成的损失每年将达到 数万亿美元。防火墙和系统等传统防御措施在网络外围运行的入侵检测系统不再足以保护当今的分布式企业网络。相反,需要一种“纵深防御”方法来保护组织数字基础设施的所有方面。在理想的世界中,应用程序将没有安全漏洞,但一旦受到损害,即使是受信任的应用程序也可能变得不可靠。AppArmor 为应用程序提供了关键的安全层。通过提供将应用程序允许的操作列入白名单的功能,AppArmor 使管理员能够将最小权限原则应用于应用程序。安装后,AppArmor 可以阻止攻击,并在发生违规时最大限度地减少或防止损坏。
AppArmor 是一项重要的安全功能,自 Ubuntu 7.10 起默认包含在 Ubuntu 中。但是,它在后台安静地工作,因此您可能不知道它是什么以及它在做什么。AppArmor 阻止易受攻击的进程,限制这些进程中的安全漏洞可能造成的损害。AppArmor 也可用于锁定 Mozilla Firefox 以增加安全性,但默认情况下不这样做。
AppArmor 类似于 SELinux,在 Fedora 和 Red Hat 中默认使用。尽管它们的工作方式不同,但 AppArmor 和 SELinux 都提供“强制访问控制”(MAC)安全性。实际上,AppArmor 允许 Ubuntu 开发人员限制进程可以采取的操作。

简介
AppArmor是一个高效和易于使用的Linux系统安全应用程序,本质上AppArmor 是一个 Linux 内核安全模块,它通过基于 Debian 的系统中的每个应用程序配置文件实现强制访问控制 (MAC) 安全性。AppArmor对操作系统和应用程序所受到的威胁进行从内到外的保护,甚至是未被发现的0day漏洞和未知的应用程序漏洞所导致的攻击。
例如,在 Ubuntu 的默认设置中受限的一个应用程序是xxPDF查看器。该软件为了方便操作PDF资源,会在您的主机上启动一个用户帐户运行,而且它仅具有运行和处理 PDF 文档所需的最低权限。如果在 PDF 查看器中发现漏洞并打开了存在恶意代码的PDF文件,AppArmor 将限制 xxPDF查看器 可能造成的损害。在传统的 Linux 安全模型中,xxPDF查看器 可以访问您可以访问的所有内容。使用 AppArmor,您只能访问 PDF 查看器需要访问的内容。AppArmor 特别适用于限制可被利用的软件,例如 Web 浏览器或服务器软件。
AppArmor安全策略可以完全定义个别应用程序可以访问的系统资源与各自的特权。AppArmor包含大量的默认策略,它将先进的静态分析和基于学习的工具结合起来,AppArmor甚至可以使非常复杂的应用可以使用在很短的时间内应用成功作为对传统Unix的自主访问控制模块的补充,AppArmor提供了强制访问控制机制,它已经被整合到2.6版本的Linux内核中。
工作模式
Apparmor有两种工作模式:enforcement、complain/learningEnforcement(强制模式)配置文件里列出的限制条件都会得到执行,并且对于违反这些限制条件的程序会进行日志记录。Complain(记录模式)配置文件里的限制条件不会得到执行,Apparmor只是对程序的行为进行记录。也就是说,我不禁止危险程序执行,但是我会记录相关信息。主要应用于程序的调试
应用场景
Apparmor可以对程序进行多方面的限制,主要作用的场景如下:文件系统的访问控制Apparmor可以对某一个文件,或者某一个目录下的文件进行访问控制r(读)、w(写)、a(追加)、k(文件锁定)、l(链接)、x(可执行)资源限制Apparmor可以提供类似系统调用setrlimit一样的方式来限制程序可以使用的资源。set rlimit [resource] <= [value]访问网络Apparmor可以程序是否可以访问网络进行限制network [ [domain] [type] [protocol] ]capability条目Apparmor可以限制程序是否可以进行列表里的操作capability setgid,
SELinux vs Apparmor
SELinux比Apparmor更安全,更灵活,同时配置起来也更复杂。Apparmor使用文件名(路径名)最为安全标签,配置很简单,但是可以通过改文件名而绕过限制SELinux使用文件的inode作为安全标签,inode在文件系统中具有唯一性。
环境部署
需求
AppArmor 软件包默认安装在 Ubuntu 上,所有默认配置文件都在系统启动时加载。配置文件包含存储在etc/apparmor.d/,所以我们需要准备一个ubuntu的系统环境。确认ubuntu主机是否默认启用了AppArmor能力# ls /sys/module/apparmor/parameters uevent# cat /sys/module/apparmor/parameters/enabledY
准备工作
master节点 跨主机免密码认证
ssh-copy-id root@10.0.0.29
ssh root@10.0.0.29 "mkdir /data/scripts -p"
echo '10.0.0.29 kubernetes-node4.superopsmsb.com kubernetes-node4' >> /etc/hostsmaster节点 传递相关文件
cd /data/scripts
scp 02_kubernetes_kernel_conf.sh root@10.0.0.29:/data/scripts/
for i in {13..17} 29
doscp /etc/hosts root@10.0.0.$i:/etc/hosts
done
ssh root@10.0.0.29 "hostnamectl set-hostname kubernetes-node4"
node节点 内核参数调整
/bin/bash /data/scripts/02_kubernetes_kernel_conf.sh
执行容器环境部署
/bin/bash /data/scripts/03_kubernetes_docker_install.sh
部署docker的专用脚本
#!/bin/bash
# 功能: 安装部署Docker容器环境
# 版本: v0.1
# 作者: 书记
# 联系: superopsmsb.com# 准备工作# 软件源配置
softs_base(){# 安装基础软件apt-get install apt-transport-https ca-certificates curl gnupg lsb-release -y# 定制软件仓库源curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo \"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null# 更新软件源apt-get update
}# 软件安装
soft_install(){# 安装最新版的docker软件apt-get -y install docker-ce docker-ce-cli containerd.io
}# 加速器配置
speed_config(){# 定制加速器配置
cat > /etc/docker/daemon.json <<-EOF
{"registry-mirrors": ["http://74f21445.m.daocloud.io","https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn"],"insecure-registries": ["kubernetes-register.superopsmsb.com"],"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF# 重启docker服务systemctl restart docker
}# 环境监测
docker_check(){process_name=$(docker info | grep 'p D' | awk '{print $NF}')[ "${process_name}" == "systemd" ] && echo "Docker软件部署完毕" || (echo "Docker软件部署失败" && exit)
}# 软件部署
main(){softs_basesoft_installspeed_configdocker_check
}# 调用主函数
main
master节点 准备cri-dockerd服务
scp /usr/local/bin/cri-dockerd root@10.0.0.29:/usr/local/bin/
scp /etc/systemd/system/cri-dockerd.service root@10.0.0.29:/etc/systemd/system/cri-dockerd.service
scp /usr/lib/systemd/system/cri-docker.socket root@10.0.0.29:/usr/lib/systemd/system/cri-docker.socketnode节点 查看效果
systemctl daemon-reload
systemctl enable cri-dockerd.service cri-docker.socket
systemctl start cri-dockerd.service
master节点获取集群信息
[root@kubernetes-master1 ~]# kubeadm token list | awk '{print $1,$2}'
TOKEN TTL
abcdef.0123456789abcdef 27y
[root@kubernetes-master1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
2e32fbe869258151ac547ec1649af9a60d79a6080d822923bf20cf3cb6a581ce
node节点安装软件
apt-get install -y kubelet=1.24.4-00 kubeadm=1.24.4-00node加入集群
kubeadm join 10.0.0.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:2e32fbe869258151ac547ec1649af9a60d79a6080d822923bf20cf3cb6a581ce --cri-socket unix:///var/run/cri-dockerd.sock
测试效果
[root@kubernetes-master1 ~]# kubectl get nodes | grep node4
kubernetes-node4 Ready <none> 4m23s v1.24.4[root@kubernetes-master1 ~]# kubectl describe nodes | egrep 'Name:|AppArmor'
Name: kubernetes-master1
...
Name: kubernetes-node4Ready True Tue, 13 Sep 2022 11:02:04 +0800 Tue, 13 Sep 2022 10:20:49 +0800 KubeletReady kubelet is posting ready status. AppArmor enabled
结果显示:只有node4我们开启了AppArmor功能
或者这种方式检查kubelet是否支持AppArmor功能
[root@kubernetes-master1 ~]# kubectl get nodes -o=jsonpath=$'{range .items[*]}{@.metadata.name}: {.status.conditions[?(@.reason=="KubeletReady")].message}\n{end}'
kubernetes-master1: kubelet is posting ready status
...
kubernetes-node4: kubelet is posting ready status. AppArmor enabled
apparmor环境
确认node4节点上的apparmor服务状态
方法1:systemctl status apparmor.service
方法2:aa-status 或者 apparmor_statusaa-status --pretty-json (以json方式检查状态效果)确认apparmor的环境状态
root@kubernetes-node4:~# apparmor_status
apparmor module is loaded.
# 有 33 个配置文件作为 AppArmor 配置文件加载,默认情况下全部设置为强制模式
33 profiles are loaded.
33 profiles are in enforce mode./snap/snapd/16292/usr/lib/snapd/snap-confine...
0 profiles are in complain mode. # 记录模式
2 processes have profiles defined.
# cups-browsed 和 cupsd 2 个进程由具有强制模式的配置文件定义,并且在抱怨模式下没有进程
2 processes are in enforce mode./usr/sbin/cups-browsed (903)/usr/sbin/cupsd (845)
0 processes are in complain mode.
0 processes are unconfined but have a profile defined.
结果显示:AppArmor 模块已加载,主要包括两部分的信息:配置文件和进程信息33 个配置文件已加载33 个配置文件处于强制模式。
要安装您想要限制的应用程序和一些有用的 AppArmor 实用程序,请运行以下命令:
apt install apparmor-easyprof apparmor-notify apparmor-utils certspotter apparmor-profiles
常见软件包apparmor-profiles 预定义的profile文件apparmor-utils 管理profile的常用命令
小结
1.3.2 基础知识
学习目标
这一节,我们从 配置解读、命令实践、小结 三个方面来学习。
场景解读
相关配置
apparmor在安装完毕后会有一系列的目录信息配置目录 /etc/apparmor配置文件 /etc/apparmor/parser.conf控制目录 /etc/apparmor.d/文件目录 /sys/kernel/security/apparmor日志目录 /var/log/apparmor/
配置目录
配置文件存储在目录中/etc/apparmor.d.这些配置文件是可以包含注释的纯文本文件
root@kubernetes-node4:~# ls /etc/apparmor.d
abstractions sbin.dhclient usr.bin.man usr.sbin.mdnsd
...
注意:被管理的文件有固定的格式,比如/usr/sbin/cupsd 将创建为usr.sbin.cupsd配置文件仅在执行时应用于流程。在重新启动进程之前,已经运行的程序将不会执行任何强制措施。
依赖是相关通用配置
root@kubernetes-node4:~# ls /etc/apparmor.d/abstractions/
apache2-common gnome openssl ...root@kubernetes-node4:~# ls /etc/apparmor.d/disable/
usr.bin.firefox usr.sbin.rsyslogd
usr.bin.firefox 在 /etc/apparmor.d/disable 目录下,标识默认情况下不启用该服务
root@kubernetes-node4:~# ll /etc/apparmor.d/disable/usr.bin.firefox
lrwxrwxrwx 1 root root 31 8月 16 02:27 /etc/apparmor.d/disable/usr.bin.firefox -> /etc/apparmor.d/usr.bin.firefox
结果显示:他其实就是被apparmor管理的服务文件的链接而已
查看管理配置文件
AppArmor 模块配置文件定义以纯文本文件的形式储存在 /etc/apparmor.d 目录中
root@kubernetes-node4:~# cat /etc/apparmor.d/bin.ping
...
#include <tunables/global>
# profile定制规则名称 ping ,flags代表是配置文件标识
profile ping /{usr/,}bin/{,iputils-}ping flags=(complain) {#include <abstractions/base> # include直接导入其他配置文件#include <abstractions/consoles>#include <abstractions/nameservice>capability net_raw,capability setuid,network inet raw,network inet6 raw,# 第一列是文件或路径,支持正则符号或者通配符# 第二列是权限限定,r(读取)\w(更改)\x(执行)\m(内存映射可执行文件)/{,usr/}bin/{,iputils-}ping mixr,/etc/modules.conf r,# Site-specific additions and overrides. See local/README for details.#include <local/bin.ping>
}
配置文件标识模式标志 - 标记配置规则是以哪种模式进行控制- complain(记录模式) 和 空(省略-强制模式)相对标志 - 指出配置文件的路径- chroot_relative(基于chroot)或 namespace_relative(默认,非chroot)附加标志 - 是否为名称空间路径前方添加“/”字符- attach_disconnected 或 no_attach_disconnected(不加)其他配置属性file # 允许所有文件读写deny /path/** w, # 拒绝/path/目录下的所有文件写
命令实践
常用命令
服务管理命令systemctl start|stop|status|reload apparmor.service
管理命令aa-status|apparmor_status 查看AppArmor的配置文件状态apparmor_parser 加载AppArmor的配置文件<profile> 加载到内行中,覆盖现有配置文件-r <profile> 重新加载到内行中-R <profile> 删除内核中的现有配置文件-a <profile> 在强制模式下加载新配置文件的默认操作。-C <profile> 在记录模式下加载新的配置文件。-q <context> 直接基于内容创建配置信息,无配置文件aa-complain 调整AppArmor为记录模式aa-enforce 调整AppArmor为强制模式
aa-genprof 生成profile文件
aa-logprof 查询处于apparmor的日志记录
移除无效配置实践
卸载不再位于 /etc/apparmor.d/ 中的所有 AppArmor 配置文件
root@kubernetes-node4:~# aa-remove-unknown
Skipping profile in /etc/apparmor.d/disable: usr.bin.firefox
Skipping profile in /etc/apparmor.d/disable: usr.sbin.rsyslogd
Removing 'snap.snap-store.ubuntu-software-local-file'
...
Removing '/snap/snapd/16292/usr/lib/snapd/snap-confine'
注意:这条命令不要随便乱执行,因为他会将一些第三方集成应用的规则移除查看默认加载的配置
root@kubernetes-node4:~#cat /sys/kernel/security/apparmor/profiles
模式切换实践
确认强制模式的进程
root@kubernetes-node4:~# aa-status | grep -A2 'processes are in enforce'
2 processes are in enforce mode./usr/sbin/cups-browsed (903)/usr/sbin/cupsd (845)确认记录模式的进程
root@kubernetes-node4:~# aa-complain /usr/sbin/cupsd
Setting /usr/sbin/cupsd to complain mode.
root@kubernetes-node4:~# aa-status
...
1 processes are in enforce mode./usr/sbin/cups-browsed (903)
1 processes are in complain mode./usr/sbin/cupsd (845)
...
设定强制模式
root@kubernetes-node4:~# aa-enforce /usr/sbin/cupsd
Setting /usr/sbin/cupsd to enforce mode.
root@kubernetes-node4:~# aa-status
...
2 processes are in enforce mode./usr/sbin/cups-browsed (903)/usr/sbin/cupsd (845)...
访问限制实践
准备命令
root@kubernetes-node4:~# whereis ls
ls: /usr/bin/ls /usr/share/man/man1/ls.1.gz
root@kubernetes-node4:~# cp -a /usr/bin/ls /usr/bin/nihao
root@kubernetes-node4:~# nihao
root@kubernetes-node4:~# ll /usr/bin/ls
-rwxr-xr-x 1 root root 142144 9月 5 2019 /usr/bin/ls*
root@kubernetes-node4:~# ll /usr/bin/nihao
-rwxr-xr-x 1 root root 142144 9月 5 2019 /usr/bin/nihao*
生成配置文件
root@kubernetes-node4:~# aa-genprof /usr/bin/nihao
Writing updated profile for /usr/bin/nihao.
Setting /usr/bin/nihao to complain mode.Before you begin, you may wish to check if a
profile already exists for the application you
wish to confine. See the following wiki page for
more information:
https://gitlab.com/apparmor/apparmor/wikis/Profiles分析中: /usr/bin/nihaoPlease start the application to be profiled in
another window and exercise its functionality now.Once completed, select the "Scan" option below in
order to scan the system logs for AppArmor events.For each AppArmor event, you will be given the
opportunity to choose whether the access should be
allowed or denied.
# 注意:此处另开一个终端执行nihao命令,示例:
# cd
# nihao
# cd /media
# nihao
# cd /tmp/
# nihao
[(S)can system log for AppArmor events] / (F)inish
# 然后在当前页面按 S 键
Reading log entries from /var/log/syslog.
Updating AppArmor profiles in /etc/apparmor.d.
Complain-mode changes:配置文件: /usr/bin/nihao
路径: /root/
New Mode: owner r
严重性: 未知[1 - owner /root/ r,]
(A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / (O)wner permissions off / Abo(r)t / (F)inish
# 此处按 A 键,代表允许到/root/目录执行nihao命令
Adding owner /root/ r, to profile.配置文件: /usr/bin/nihao
路径: /media/
New Mode: owner r
严重性: 未知[1 - owner /media/ r,]
(A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / (O)wner permissions off / Abo(r)t / (F)inish
# 此处按 D 键,代表不允许到/media/目录执行nihao命令
Adding deny owner /media/ r, to profile.配置文件: /usr/bin/nihao
路径: /tmp/
New Mode: owner r
严重性: 未知[1 - #include <abstractions/user-tmp>]2 - owner /tmp/ r,
(A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / (O)wner permissions off / Abo(r)t / (F)inish
# 此处按 A 键,代表允许到/tmp/目录执行nihao命令
Adding #include <abstractions/user-tmp> to profile.= Changed Local Profiles =The following local profiles were changed. Would you like to save them?[1 - /usr/bin/nihao]
(S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
# 此处按 S 键,代表保存配置
Writing updated profile for /usr/bin/nihao.分析中: /usr/bin/nihaoPlease start the application to be profiled in
another window and exercise its functionality now.Once completed, select the "Scan" option below in
order to scan the system logs for AppArmor events.For each AppArmor event, you will be given the
opportunity to choose whether the access should be
allowed or denied.[(S)can system log for AppArmor events] / (F)inish
Setting /usr/bin/nihao to enforce mode.
# 此处按 F 键,代表退出配置
重启 AppArmor 到强制模式请考虑贡献您的新配置文件!
参阅以下 wiki 页面获取更多信息:
https://gitlab.com/apparmor/apparmor/wikis/Profiles已完成为 /usr/bin/nihao 生成配置文件。
确认效果
root@kubernetes-node4:~# ls /etc/apparmor.d/*.nihao
/etc/apparmor.d/usr.bin.nihao
root@kubernetes-node4:~# cat /etc/apparmor.d/usr.bin.nihao
# Last Modified: Tue Sep 13 17:18:38 2022
#include <tunables/global>/usr/bin/nihao {#include <abstractions/base>#include <abstractions/user-tmp>deny owner /media/ r,/usr/bin/nihao mr,owner /root/ r,}
确认效果
root@kubernetes-node4:~# aa-status
apparmor module is loaded.
33 profiles are loaded.
34 profiles are in enforce mode..../usr/bin/nihao
另开新终端确认效果
root@kubernetes-node4:/tmp# cd /media/
root@kubernetes-node4:/media# nihao
nihao: 无法打开目录 '.': 权限不够
oot@kubernetes-node4:/media# cd /etc/systemd/
root@kubernetes-node4:/etc/systemd# nihao
nihao: 无法打开目录 '.': 权限不够
将命令置于complain模式
root@kubernetes-node4:~# aa-complain /usr/bin/nihao
Setting /usr/bin/nihao to complain mode.
root@kubernetes-node4:~# aa-status
...
1 profiles are in complain mode./usr/bin/nihao执行命令效果
root@kubernetes-node4:/media# cd /etc/docker/
root@kubernetes-node4:/etc/docker# nihao
daemon.json key.json
结果显示:在记录模式下,它并不会阻止命令的执行
查看日志效果
root@kubernetes-node2:~# aa-logprof
Reading log entries from /var/log/syslog.
Updating AppArmor profiles in /etc/apparmor.d.
Complain-mode changes:配置文件: /usr/bin/nihao
路径: /etc/docker/
New Mode: owner r
严重性: 未知[1 - owner /etc/docker/ r,]
(A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / (O)wner permissions off / Abo(r)t / (F)inish
# 此处按 A 键,代表允许
Adding owner /etc/docker/ r, to profile.
Enforce-mode changes:= Changed Local Profiles =The following local profiles were changed. Would you like to save them?[1 - /usr/bin/nihao]
(S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
Writing updated profile for /usr/bin/nihao.
查看修改后的配置
root@kubernetes-node4:/etc/apparmor.d# cat /etc/apparmor.d/usr.bin.nihao
# Last Modified: Tue Sep 13 17:28:29 2022
#include <tunables/global>/usr/bin/nihao {#include <abstractions/base>#include <abstractions/evince>#include <abstractions/user-tmp>deny owner /media/ r,/usr/bin/nihao mr,owner /etc/docker/ r, # 结果显示:这个目录可以正常的访问了owner /opt/ r,owner /root/ r,
}
移除配置实践
移除内存中的限制
root@kubernetes-node2:~# apparmor_parser -R /etc/apparmor.d/usr.bin.nihao
root@kubernetes-node2:~# aa-status | grep nihao确认效果
root@kubernetes-node4:/etc/systemd# nihao
journald.conf network pstore.conf ...
结果显示:一旦内存中的规则移除后,限制就没有了
虽然内存规则移除,但是规则文件还在
root@kubernetes-node2:~# ls /etc/apparmor.d/usr.bin.nihao
/etc/apparmor.d/usr.bin.nihao如果不移除规则文件的话,重启apparmor规则,仍然会生效,所以我们需要把规则文件也需要移除
root@kubernetes-node2:~# rm -f /etc/apparmor.d/usr.bin.nihao这样的话,重启服务,规则也不会有了
root@kubernetes-node2:~# systemctl restart apparmor
root@kubernetes-node2:~# aa-status | grep nihao
小结
1.3.2 应用实践
学习目标
这一节,我们从 配置解读、简单实践、小结 三个方面来学习。
配置解读
简介
apparmor 配置文件定义了目标受限应用程序可以访问系统上的哪些资源(如网络、系统功能或文件),如果要为运行 Pod 容器指定的 AppArmor 配置文件,需要在pod的元数据位置通过添加注释的方式来实现启用AppArmor的功能:container.apparmor.security.beta.kubernetes.io/<container_name>: <profile_ref>
属性解析:<container_name> 的名称是容器的简称<profile_ref>用于设定AppArmor的位置,常见样式如下:- runtime/default 应用运行时的默认配置- localhost/<profile_name> 从本地主机加载 <profile_name> 的配置文件- unconfined 表示不加载配置文件
注意:如果容器指定了AppArmor规则,而本地主机没有的话,则pod不会启动
示例:
apiVersion: v1
kind: Pod
metadata:name: helloannotations:# 通过注释信息定制容器使用的本地策略container.apparmor.security.beta.kubernetes.io/superopsmsb: localhost/apparmor_profile
spec:containers:- name: superopsmsb...
简单实践
参考资料:https://kubernetes.io/zh-cn/docs/tutorials/security/apparmor/#setting-up-nodes-with-profiles
创建资源访问策略
apparmor在内存中生成配置规则
apparmor_parser -q <<EOF
#include <tunables/global>
profile kubernetes-deny-write flags=(attach_disconnected) {#include <abstractions/base>file,# Deny all file writes.deny /tmp/** w,
}
EOF'
简单实践
资源对象文件 13_kubernetes_server_secure_apparmor_podtest.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-testannotations:container.apparmor.security.beta.kubernetes.io/busybox-test: localhost/kubernetes-deny-write
spec:nodeName: kubernetes-node4containers:- name: busybox-testimage: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]创建资源清单文件
kubectl apply -f 13_kubernetes_server_secure_apparmor_podtest.yaml检查效果
kubectl get pod
确认效果
]# kubectl exec -it busybox-test -- /bin/sh
/ # ls /tmp/
/ # echo nihao > /tmp/nihao.txt
/bin/sh: can't create /tmp/nihao.txt: Permission denied
/ # echo nihao > nihao.txt
/ #
结果显示:借助于apparmor的策略规则实现了容器内部资源操作的限制能力了
小结
1.4 调用限制
1.4.1 Seccomp
学习目标
这一节,我们从 基础知识、Seccomp简介、小结 三个方面来学习。
基础知识
简介
所谓的系统调用,其实就是用户空间进程无法直接操作底层的设备,我们只能向内核空间发起请求调用,由内核空间的驱动程序来对底层设备进行相关的操作。这样的话,用户层只需要关注业务层面的操作,通过技术手段借助于系统调用实现资源相关的操作,从而实现业务和技术层面的解耦

在 Docker Driver 的实现中,可以分为以下三类驱动。graphdriver 负责容器镜像的管理主要就是镜像的存储和获取,当镜像下载的时候,会将镜像持久化存储到本地的指定目录;networkdriver 负责容器网络环境的管理主要就是 Docker 运行时进行 IP 分配端口映射以及启动时创建网桥和虚拟网卡;execdriver 负责容器命令执行的管理主要就是通过操作 Lxc 或者 libcontainer 实现资源隔离。它负责创建管理容器运行命名空间、管理分配资源和容器内部真实进程的运行;通过调用 libcontainer 加载容器配置 container,继而创建真正的 Docker 容器。
namespace
容器可以创建出一个相对隔离的环境,就容器技术本身来说,容器的核心部分是利用了我们操作系统内核的虚拟化技术,在 Linux 内核中,实现各种资源隔离功能的技术就叫 Linux Namespace,它可以隔离一系列的系统资源。在Docker容器环境下,这些namespace主要体现在如下七个层面:
PID Namespace:保障进程隔离,每个容器都以 PID=1 的 init 进程来启动,其他进程的 PID 会依次递增。PID Namespace 使用了的参数 CLONE_NEWPID。父 NameSpace 可以拿到全部子 NameSpace 的状态,但每个子 NameSpace 之间是互相隔离的。User Namespace:用于隔离容器中 UID、GID 以及根目录等。User Namespace 使用了 CLONE_NEWUSER 的参数,可配置映射宿主机和容器中的 UID、GID。UID 在当前的 Namespace 下,是具有容器 root 权限的,不是宿主机的。UTS Namespace:保障每个容器都有独立的主机名或域名。UTS Namespace 使用了的参数 CLONE_NEWUTS,用来隔离 hostname 和 NIS Domain name。Mount Namespace: 保障每个容器都有独立的目录挂载路径。Mount Namespace 使用了的参数 CLONE_NEWNS,用来隔离各个进程看到的挂载点视图。NET Namespace:保障每个容器有独立的网络栈、socket 和网卡设备。NET Namespace 使用了参数 CLONE_NEWNET,隔离了和网络有关的资源,如网络设备、IP 地址端口等。IPC Namespace:保障每个容器进程 IPC 通信隔离。IPC Namespace 使用了的参数 CLONE_NEWIPC,用来隔离 系统IPC 和 POSIX message队列在相同 IPC 命名空间的容器进程之间才可以共享内存、信号量、消息队列通信。Cgroup Namespace:保障容器容器中看到的 cgroup 视图,像宿主机一样以根形式来呈现让容器内使用 cgroup 变得更安全。
系统调用
这7 类 Namespace 主要使用如下 3 个系统调用函数,其实也就是和进程有关的调用函数。clone:创建新进程,根据传入上面的不同 NameSpace 类型,来创建不同的 NameSpace 进行隔离,对应的子进程也会被包含到这些 Namespace 中。unshare:将进程移出某个指定类型的 Namespace,并加入到新创建的 NameSpace 中容器中 NameSpace 也是通过 unshare 系统调用创建的。setns:将进程加入到 Namespace 中
Seccomp简介
场景需求
kubernetes的所有业务活动都会以容器的方式来实现,但是有些应用业务需要涉及到底层资源的操作,所以默认情况下存在多种系统调用的方式来提升业务的高效实现。但是这些便捷性也为黑客通过进入容器,然后借助于提权操作,进入到宿主机上,进行更大的破坏提供了便捷性。所以我们要限制容器使用系统调用的能力。
Seccomp方案
Seccomp 代表安全计算(Secure Computing)模式,自 2.6.12 Linux 内核版本以来,一直是 Linux 内核的一个特性。 它可以用来沙箱化进程的权限,限制进程从用户态到内核态的调用。 Kubernetes 能使你自动将加载到 节点上的 seccomp 配置文件应用到你的 Pod 和容器。注意:seccomp的配置文件目录/var/lib/kubelet/seccomp是不存在,需要自建
对于1.19版本之后的kubernetes来说,Seccomp可以在securityContext中进行使用:样式1:pod.spec.containers.securityContext.seccompProfile样式2:pod.spec.securityContext.seccompProfilelocalhostProfile- 在type为Localhost的时候使用,指定profile文件的位置typeLocalhost - 使用节点本地的配置文件。默认目录是/var/lib/kubelet/seccomp.RuntimeDefault - 使用容器默认的配置文件.Unconfined - 不用任何配置文件.
注意:因为涉及到系统调用,所以测试的时候,一定要对特定的主机进行seccomp限制
小结
1.4.2 应用实践
学习目标
这一节,我们从 属性解读、简单实践、小结 三个方面来学习。
属性解读
策略文件样式
{"defaultAction": "SCMP_ACT_ERRNO", # 默认不执行系统调用,发起调用失败"architectures": ["SCMP_ARCH_X86_64",...],"syscalls": [{"names": [ # 该动作发起系统调用的名称列表"accept4",...],"action": "SCMP_ACT_ALLOW" # 允许执行系统调用}]
}
参考资料:https://kubernetes.io/zh-cn/docs/tutorials/security/seccomp/
常见的系统调用
进程控制相关fork、clone、execve、exit、pause、wait、ptrace等
文件系统相关文件读写操作 open、creat、close、read、write等文件系统操作 access、chdir、chmod、chown、mkdir、rmdir等
系统控制相关ioctl、reboot、sysinfo、time等
内存管理相关mlock、mmap、getpagesize、sync、cacheflush等
网络管理相关getdomainname、setdomainname、gethostname、sethostname等
socket管理相关socketcall、socket、bind、connect、accept、send、listen等
用户管理相关getuid、setuid、getgid、setgid、getgroups、setgroups等
进程间通信相关sigaction、sigprocmask、signal、kill、pipe、semctl等
环境准备
以 node2 节点为例
mkdir /var/lib/kubelet/seccomp/profiles -p
cd /var/lib/kubelet/seccomp/profiles
简单实践
准备策略文件
在node2上准备策略文件 /var/lib/kubelet/seccomp/profiles/change_test.json
{"defaultAction": "SCMP_ACT_ALLOW","syscalls": [{"names": ["chmod","chown","rmdir" ],"action": "SCMP_ACT_ERRNO"}]
}重启kubelet服务
systemctl restart kubelet
资源对象实践
资源对象文件 14_kubernetes_server_secure_seccomp_test.yaml
apiVersion: v1
kind: Pod
metadata:name: busybox-test
spec:nodeName: kubernetes-node2containers:- name: busybox-test1image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]- name: busybox-test2image: kubernetes-register.superopsmsb.com/superopsmsb/busyboxcommand: [ "sh", "-c", "sleep 1h" ]securityContext:seccompProfile:type: LocalhostlocalhostProfile: profiles/change_test.json应用资源对象
kubectl apply -f 14_kubernetes_server_secure_seccomp_test.yaml
确认效果
]# kubectl exec -it busybox-test -c busybox-test1 -- /bin/sh/ # cd /tmp/
/tmp # mkdir nihao
/tmp # chown 1000:1000 nihao
/tmp # chmod +x nihao
/tmp # rmdir nihao
/tmp # ls
/tmp # exit
结果显示:第一个容器操作没有任何异常
确认效果
]# kubectl exec -it busybox-test -c busybox-test2 -- /bin/sh
/ # cd /tmp/
/tmp # mkdir nihao
/tmp # chown 1000:1000 nihao
chown: nihao: Operation not permitted
/tmp # chmod +x nihao
chmod: nihao: Operation not permitted
/tmp # rmdir nihao
rmdir: 'nihao': Operation not permitted
/tmp # ls
nihao
/tmp # exit
结果显示:第二个容器操作受到我们的seccomp的策略管控,系统调用无法执行
小结
1.5 应用沙箱
1.5.1 gVisor应用
学习目标
这一节,我们从 软件简介、原理解读、小结 三个方面来学习。
软件简介
场景
根据我们对于应用服务安全的基础了解,基于容器方式的应用程序在正常运行的时候,不可避免的在一些场景下需要直接访问linux内核的系统调用,虽然我们可以通过namespace和cgroup等方式实现一定程度上的资源隔离,但是安全性还是比较弱的,容器里的应用程序依然可以访问很多系统资源,事实上跟没有跑在容器里的应用程序一样,容器里的应用程序可以直接通过linux内核的系统调用陷入到内核,任何一个被允许的系统调用的缺陷都可以被恶意的应用程序利用,这也直接导致各种基于容器环境的漏洞借助于系统内核调用的方式实现宿主机的攻击。
虽然linux内核在不断的增强自身的安全特性,但是由于linux内核的功能限制,它不可能面面俱到最好的方式是以更高级别或者更全方位层次的实现安全隔离,最好能像程序代码松耦合一样,阻断容器内部程序对于宿主机的依赖。
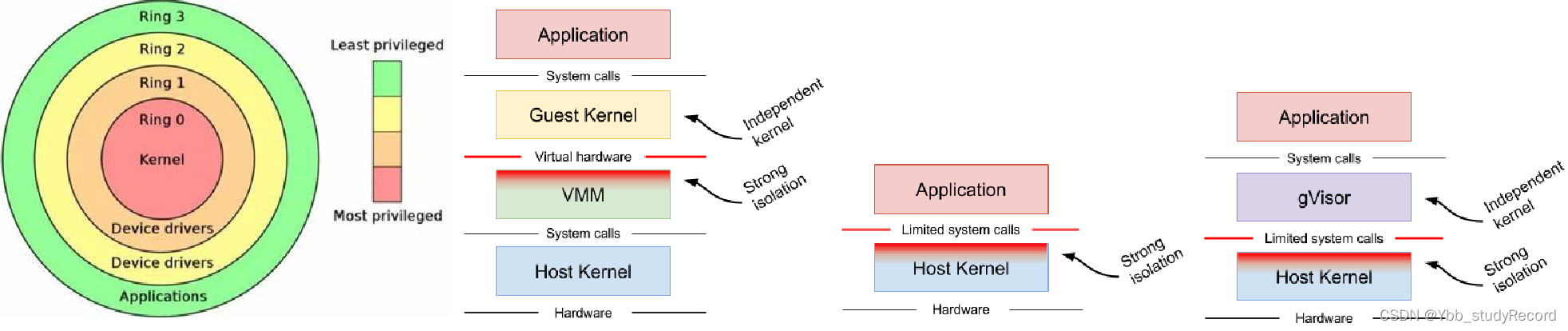
解决方案
样式1: 基于VM虚拟机的方案,将潜在恶意的应用程序隔离在独立的虚拟机中,例如kata linux,基于VM的方案提高了很好的隔离,但相应额外消耗的内存会多一些。在有需要运行大量container的场景下的额外资源消耗不能被忽略。虽然它可以很好的与Docker和Kubernetes进行集成。大规模场景中,对于资源消耗比较高,成本比较高。
样式2:基于规则的执行(如seccomp,SELinux和AppArmor等)允许为应用程序或容器指定细粒度的安全策略,虽然这是隔离应用程序和保持本机性能的绝佳方式,但是这些规则的技术门槛比较高,导致实现起来很不方便甚至某些场景无法实现。
样式3:Google开源的一种gVisor技术提供了另外一种sandbox思路,gVisor非常轻量级,额外的内存消耗非常小,但同时提供了和VM方案相当隔离等级。gVisor遵循了OCI标准,所以可以作为容器的一个runtime方式来执行,它可以很好的与Docker和Kubernetes进行集成。由于其以运行场景的限制,它可能会在系统调用繁重的工作负载时表现出较差的性能。
Gvisor
gVisor是Google开源的有关容器安全的组件,是用Go语言编写的 -- "用户空间内核(UML)",它实现了大部分的Linux系统调用命令(240+),它限制了应用程序直接访问主机内核,同时能保持应用程序所期望的访问结果。也就是说,gVisor它利用现有的主机内核功能以普通的用户空间的方式运行 -- gVisor通过Linux底层实现Linux进程。
官网地址:https://gvisor.dev/github地址:https://github.com/google/gvisor
原理解读
gvisor结构
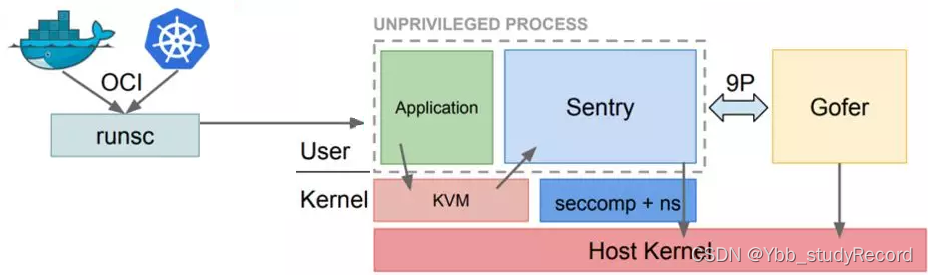
runsc - 容器入口gvisor包含一个叫了runsc的OCI运行时,目的是提供应用程序与主机内核之间的边界隔离,runsc实现了多个命令来执行各种功能,例如启动、停止、列出和查询容器的状态。gVisor将应用程序加载到runsc的内存空间中并运行,目前runsc运行时已经与Docker和Kubernetes做了集成,使运行沙箱容器sandbox变得很简单。
Sentry - 系统调用Sentry 是 gVisor 的最大组件。它实现了应用程序所需的所有内核功能,包括:系统调用、信号传递、内存管理和页面错误逻辑、线程模型等等。当应用程序进行系统调用时, 平台基于ptrace syscall截获并将调用重定向到Sentry,Sentry将做必要的工作来服务它。需要注意的是,Sentry 不会将系统调用传递给主机内核。作为一个用户空间应用程序,Sentry 会进行一些宿主系统调用来支持它的操作,但它不允许应用程序直接控制它进行的系统调用。例如,Sentry不能直接打开文件;超出沙盒的文件系统操作(不是内部/proc文件、管道等)被发送到 Gofer。
Gofer - IO代理Gofer 是一个标准的主机进程,它从每个容器开始,并通过 9P 协议通过套接字或共享内存通道与 Sentry 通信。Sentry 进程在受限的 seccomp 容器中启动,无法访问文件系统资源。Gofer 调解对这些资源的所有访问,提供额外的隔离级别。
镜像应用
关于gvisor所支持的docker镜像有很多,官方帮我们测试了很多的基础应用镜像文件,这些文件有:elasticsearch、golang、httpd、java8、jenkins、mariadb、memcached、mongo、mysql、nginx、node、php、postgres、prometheus、python、redis、registry、tomcat、wordpress、等参考资料:https://gvisor.dev/docs/user_guide/compatibility/
gvisor所运行的容器环境中,可以执行通用的一些linux命令,这些常见的命令有:apt-get、bundle、cat、curl、dd、df、dig、drill、env、find、gcore、gdb、gosu、grep、ifconfig、ip、less、ls、lsof、mount、nc、nmap、netstat、nslookup、ping、ps、route、ss、sshd、strace、tar、tcpdump、top、uptime、vim、wget等
小结
1.5.2 环境集成
学习目标
这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
基础知识
环境需求
对于gVisor软件的部署,他有一些基本要求:要求linux 内核 4.14.77+要求Docker 版本 17.09.0+参考资料:https://github.com/google/gvisor#installing-from-source
linux内核
官方资料:https://www.kernel.org/
最新版本:6.0.2
更新内核
检查节点的内核版本
[root@kubernetes-node3 ~]# uname -r
3.10.0-1160.el7.x86_64
解析:3(主版本号).10(次版本号).0(修订版本号)-1160(补丁版本).el7.x86_64注意:次版本号是偶数表示稳定版本,奇数表示开发版本
导入该源的秘钥
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
启用该源仓库
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
查看有哪些内核版本可供安装
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
安装长期支持版本(5.4.218)
yum --enablerepo=elrepo-kernel install kernel-lt -y
设置 GRUB 默认的内核版本
sed -i 's#GRUB_DEFAULT=.*#GRUB_DEFAULT=0#' /etc/default/grub重新配置grub
grub2-mkconfig -o /boot/grub2/grub.cfg重启主机
reboot
确认效果
[root@kubernetes-node3 ~]# uname -r
5.4.218-1.el7.elrepo.x86_64
结果显示:内核已经升级完毕了
简单实践
安装步骤
参考资料:https://gvisor.dev/docs/user_guide/install/
部署gvisor
Centos7部署runsc
(set -eARCH=$(uname -m)URL=https://storage.googleapis.com/gvisor/releases/release/latest/${ARCH}wget ${URL}/runsc ${URL}/runsc.sha512 \${URL}/containerd-shim-runsc-v1 ${URL}/containerd-shim-runsc-v1.sha512sha512sum -c runsc.sha512 \-c containerd-shim-runsc-v1.sha512rm -f *.sha512chmod a+rx runsc containerd-shim-runsc-v1sudo mv runsc containerd-shim-runsc-v1 /usr/local/bin
)
gvisor与docker集成
更新runsc
/usr/local/bin/runsc install
确认效果
[root@kubernetes-node3 ~]# cat /etc/docker/daemon.json
{...,"runtimes": {"runsc": {"path": "/usr/local/bin/runsc"}}
}
重载docker服务
sudo systemctl reload docker确认效果
[root@kubernetes-node3 ~]# docker info | grep RuntimeRuntimes: runc runscDefault Runtime: runc
结果显示:Docker的运行时环境变成了runsc了
如果想要让Default Runtime也更换成runsc,需要修改docker的服务文件
[root@kubernetes-node3 ~]# vim /lib/systemd/system/docker.service
...
ExecStart=/usr/bin/dockerd --default-runtime runsc -H fd:// --containerd=/run/containerd/containerd.sock
...重启相关服务
[root@kubernetes-node3 ~]# systemctl daemon-reload
[root@kubernetes-node3 ~]# systemctl restart docker.service注意:由于我们定制的镜像有可能不被gvisor所承认,所以在没有必要的情况下,不要更好默认的runc
runc模式测试效果
普通模式运行容器
[root@kubernetes-node2 ~]# docker run -d -p 555:80 --name nginx-test kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1
b10a55c3c0ce1d70e0884466f53bb266c5571d03615342a1d6c06ff4f635734c[root@kubernetes-node2 ~]# curl 10.0.0.16:555
Hello Nginx, b10a55c3c0ce-1.23.1默认运行的容器以系统进程的样式存在
[root@kubernetes-node2 ~]# ps aux | grep nginx
root 72852 0.0 0.0 8844 3480 ? S 22:52 0:00 nginx: master process nginx -g daemon off;
101 72867 0.0 0.0 9232 1536 ? S 22:52 0:00 nginx: worker process
101 72868 0.0 0.0 9232 1768 ? S 22:52 0:00 nginx: worker process
root 73138 0.0 0.0 112824 988 pts/0 S+ 22:52 0:00 grep --color=auto nginx
查看底层的系统内核
[root@kubernetes-node2 ~]# docker exec -it nginx-test uname -r
3.10.0-1160.el7.x86_64管理容器的方式
[root@kubernetes-node2 ~]# ps -ef | grep runc
root 1932 1 0 19:08 ? 00:00:03 /usr/bin/containerd-shim-runc-v2 -namespace moby -id d0a246513ea3225fd1a7be69b5c3ac009d395dcd809b1cbc1d555196d271a5c5 -address /run/containerd/containerd.sock
...
结果显示:容器都是有runc来进行管理的
runsc模式测试效果
测试效果
[root@kubernetes-node3 ~]# docker run -d -p 666:80 --name nginx-test --runtime=runsc kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1[root@kubernetes-node3 ~]# curl 10.0.0.17:666
Hello Nginx, 76afcde42b20-1.23.1默认运行的容器,不再以系统进程样式存在了
[root@kubernetes-node3 ~]# ps aux | grep nginx
root 15293 0.0 0.0 112832 2276 pts/1 S+ 22:54 0:00 grep --color=auto nginx
查看底层的系统内核
[root@kubernetes-node3 ~]# docker exec -it nginx-test uname -r
4.4.0管理容器的方式
[root@kubernetes-node3 ~]# ps -ef | grep runsc
root 15014 14998 0 22:53 ? 00:00:00 runsc-gofer --root=/var/run/docker/runtime-runc/moby --log=/run/containerd/io.containerd.runtime.v2.task/moby/76afcde42b2030cc959517bccff743c913aaba52b21c9c635df638bde709597f/log.json --log-format=json --systemd-cgroup=true --log-fd=3 gofer --bundle
...
结果显示:当容器发生系统调用的时候走的都是虚拟内核,如果要对内核做破坏那么也是对虚拟内核做破坏,对宿主机的内核没什么影响
小结
1.5.3 Containerd集成
学习目标
这一节,我们从 基础知识、简单实践、小结 三个方面来学习。
场景解读
kubernetes操作容器
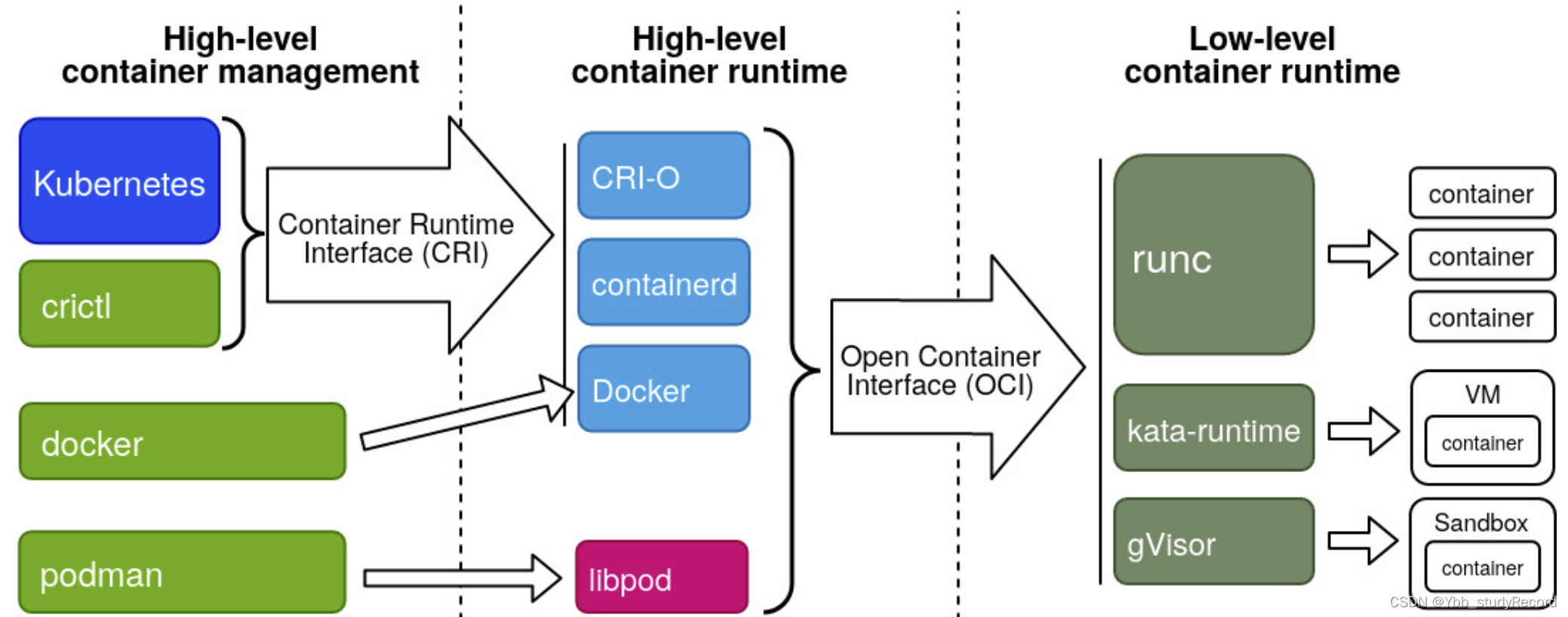
High-level container management负责kubernetes集群环境操作容器高阶运行时的工具,比如kubelet和crictl。High-level conatiner runtime高阶运行时负责容器镜像的传输和管理、解包镜像以及使用OCI传递给低级运行时来运行容器。目前三个主要的高级容器运行时:containerd: Kubernetes的默认CRI容器运行时,它支持所有 OCI 兼容的运行时,并有一个特殊的 shim 用于kata-run;CRI-O:Kubernetes独立创建的配套CRI运行时,不是k8s发行版的默认模式cridockerd: 兼容 Docker 容器引擎平台的一种方式。Low-level contianer runtime。专注于运行容器的实际容器运行时。低级别的容器运行时都需要遵循OCI开放容器标准,方便高级别容器运行时进行调用。常见的运行时主要有:runc:Docker、Podman和contained等高阶容器运行时的默认设置。kata-run: Kata Containers贡献的运行时,借助轻量级 VM 中实现容器之间的安全隔离。gVisor: 谷歌贡献的运行时,通过安全沙箱中实现容器的深层次隔离。
10.0.0.29节点进行containerd配置
准备工作
apt-get install apt-transport-https ca-certificates curl gnupg lsb-release -y
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo \"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
安装Containerd服务
apt-get update
apt-get install containerd.io cri-tools -y
生成配置文件
systemctl enable containerd --now
containerd config default > /etc/containerd/config.toml
修改配置文件
[plugins]
...[plugins."io.containerd.grpc.v1.cri"]...# 修改pause镜像地址sandbox_image = "kubernetes-register.superopsmsb.com/google_containers/pause:3.7"...[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]...[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]...[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]...# 修改Cgroup驱动为systemdSystemdCgroup = true[plugins."io.containerd.grpc.v1.cri".registry]...# 定制专属的私有镜像仓库[plugins."io.containerd.grpc.v1.cri".registry.configs][plugins."io.containerd.grpc.v1.cri".registry.configs."kubernetes-register.superopsmsb.com".tls]insecure_skip_verify = true[plugins."io.containerd.grpc.v1.cri".registry.configs."kubernetes-register.superopsmsb.com".auth]username = "shuji"password = "A12345678a"[plugins."io.containerd.grpc.v1.cri".registry.headers]# 定制专属的镜像仓库[plugins."io.containerd.grpc.v1.cri".registry.mirrors][plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]endpoint = ["http://74f21445.m.daocloud.io","https://docker.mirrors.ustc.edu.cn"][plugins."io.containerd.grpc.v1.cri".registry.mirrors."kubernetes-register.superopsmsb.com"]endpoint = ["http://kubernetes-register.superopsmsb.com"]
配置命令工具
crictl config runtime-endpoint unix:///var/run/containerd/containerd.sock
重启containerd服务
systemctl restart containerd; systemctl enable containerd
简单实践
镜像操作
操作方式1:有命名空间的操作限制查看空间:ctr ns list应用空间:export CONTAINERD_NAMESPACE=k8s.io查看镜像:ctr i list获取镜像:ctr i pull image名称
操作方式2:无限制查看镜像:crictl images获取镜像:crictl pull image名称删除镜像:crictl rmi image名称
注意:关于增删改查的操作,最好使用一套命令,不要A样式创建,然后B样式删除
获取镜像
crictl pull docker.io/nginx
crictl pull kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1确认效果
root@kubernetes-node4:/etc/containerd# crictl image list
IMAGE TAG IMAGE ID SIZE
docker.io/library/nginx latest 605c77e624ddb 56.7MB
kubernetes-register.superopsmsb.com/superopsmsb/nginx_web v0.1 1f0791fd0a992 56.7MB
命令升级
因为ctr 和 crictl 相关的命令与docker命令的格式有些许差别,当我们习惯使用docker命令后,为了方便使用containerd,我们可以改造命令,使用nerdctl工具来操作,格式与docker的格式完全一致。因为该工具依赖于cni的插件,所以我们还需要下载特定的cni插件参考资料: https://github.com/containerd/nerdctl/releaseshttps://github.com/containernetworking/plugins/releases
获取软件
mkdir /data/softs && cd /data/softs
wget https://github.com/containerd/nerdctl/releases/download/v0.23.0/nerdctl-0.23.0-linux-amd64.tar.gz
https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz
获取软件
tar zxvf nerdctl-0.23.0-linux-amd64.tar.gz
mkdir -p /opt/cni/bin/
tar zxf cni-plugins-linux-amd64-v1.1.1.tgz -C /opt/cni/bin/
mv nerdctl /bin/
定制命令补全功能
echo 'source <(nerdctl completion bash)' >> /etc/profile
source /etc/profile
确认效果
声明环境变量
root@kubernetes-node4:~# export CONTAINERD_NAMESPACE=k8s.io查看镜像信息
root@kubernetes-node4:~# nerdctl images
REPOSITORY TAG IMAGE ID ... SIZE BLOB SIZE
nginx latest 0d17b565c37b ... 149.1 MiB 54.1 MiB
...
获取镜像
root@kubernetes-node4:~# nerdctl pull nginx:latest
root@kubernetes-node4:~# nerdctl pull kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1 --insecure-registry删除镜像
root@kubernetes-node4:~# nerdctl rmi nginx:latest --force
运行容器
root@kubernetes-node4:~# nerdctl run -d --name=web1 --restart=always kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1查看容器
root@kubernetes-node4:~# nerdctl ps
CONTAINER ID IMAGE ...
76d751060dbe kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1 ...查看进程
root@kubernetes-node4:~# ps aux | grep nginx
root 70577 0.0 0.1 8860 5588 ? S 09:39 0:00 nginx: master process nginx -g daemon off;
systemd+ 70578 0.0 0.0 9280 2544 ? S 09:39 0:00 nginx: worker process
systemd+ 70579 0.0 0.0 9280 2544 ? S 09:39 0:00 nginx: worker process
关闭容器
root@kubernetes-node4:~# nerdctl stop web1
web1删除容器
root@kubernetes-node4:~# nerdctl rm web1
web1
Ubuntu部署gVisor
准备工作
apt-get update
apt-get install -y apt-transport-https ca-certificates curl gnupg
软件源配置
curl -fsSL https://gvisor.dev/archive.key | sudo gpg --dearmor -o /usr/share/keyrings/gvisor-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/gvisor-archive-keyring.gpg] https://storage.googleapis.com/gvisor/releases release main" | sudo tee /etc/apt/sources.list.d/gvisor.list > /dev/null
安装runsc
apt-get update && sudo apt-get install -y runsc
containerd使用gVisor环境
编辑containerd的config.toml文件
[plugins]...[plugins."io.containerd.grpc.v1.cri"]...[plugins."io.containerd.grpc.v1.cri".containerd]...[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]# 增加对于runsc的支持[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runsc]runtime_type = "io.containerd.runsc.v1"[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]...runtime_type = "io.containerd.runc.v2"...
重启containerd服务
systemctl daemon-reload ; systemctl restart containerd
确认效果
root@kubernetes-node4:/etc/containerd# crictl info | egrep 'runtimes|runtimeType'"runtimes": {"runtimeType": "io.containerd.runc.v2","runtimeType": "io.containerd.runsc.v1",
测试沙箱能力
运行容器
root@kubernetes-node4:~# nerdctl run -d --name=web1 --runtime=runsc -p 666:80 kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1查看容器
root@kubernetes-node4:~# nerdctl ps
CONTAINER ID IMAGE ...
76d751060dbe kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1 ...访问容器
root@kubernetes-node4:/etc/containerd# curl 10.0.0.29:666
Hello Nginx, 6e0ec44d040c-1.23.1
查看进程
root@kubernetes-node4:~# ps aux | grep nginx
结果显示:没有任何进程可以显示查看runsc进程
root@kubernetes-node4:/etc/containerd# ps aux | grep runsc
root 75417 0.3 0.4 745432 19688 ? Sl 09:53 0:00 runsc-gofer --root=/run/containerd/runc/k8s.io --log=/run/containerd/io.containerd.runtime.v2.task/k8s.io/...
结果显示:容器的进程被gVisor的沙箱管理起来了
环境收尾
nerdctl stop web1
nerdctl rm web1
小结
1.5.4 k8s集成
学习目标
这一节,我们从 节点添加、简单实践、小结 三个方面来学习。
节点添加
准备工作
master节点 跨主机免密码认证
ssh-copy-id root@10.0.0.29
ssh root@10.0.0.29 "mkdir /data/scripts -p"
echo '10.0.0.29 kubernetes-node4.superopsmsb.com kubernetes-node4' >> /etc/hosts
master节点 传递相关文件
cd /data/scripts
scp 02_kubernetes_kernel_conf.sh root@10.0.0.29:/data/scripts/
for i in {13..17} 29
doscp /etc/hosts root@10.0.0.$i:/etc/hosts
done
ssh root@10.0.0.29 "hostnamectl set-hostname kubernetes-node4"
node节点 内核参数调整
/bin/bash /data/scripts/02_kubernetes_kernel_conf.sh
软件源配置
更新软件源
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
apt update
添加节点
master节点获取集群信息
[root@kubernetes-master1 ~]# kubeadm token list | awk '{print $1,$2}'
TOKEN TTL
abcdef.0123456789abcdef 27y
[root@kubernetes-master1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
2e32fbe869258151ac547ec1649af9a60d79a6080d822923bf20cf3cb6a581ce
node节点安装软件
apt-get install -y kubelet=1.24.4-00 kubeadm=1.24.4-00node加入集群
kubeadm join 10.0.0.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:2e32fbe869258151ac547ec1649af9a60d79a6080d822923bf20cf3cb6a581ce --cri-socket unix:///run/containerd/containerd.sock
测试效果
[root@kubernetes-master1 /data/scripts]# kubectl get nodes | grep node4
kubernetes-node4 Ready <none> 26s v1.24.4
k8s支持gVisor
在node4上,修改文件,让kubelet也能使用gVisor(runsc)
cat > /etc/systemd/system/kubelet.service.d/0-cri-containerd.conf <<EOF
[Service]
Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --runtime-request-timeout=15m
--container-runtime-endpoint=unix:///run/containerd/containerd.sock"
EOF重启kubelet服务,让配置生效
systemctl daemon-reload ; systemctl restart kubelet.service
简单实践
准备工作
mkdir /data/kubernetes/gvisor/
cd /data/kubernetes/gvisor/
创建资源清单文件 01-superopsmsb-runtimeclass.yaml
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:name: superopsmsb-runtimeclass
handler: runsc
应用资源清单文件
kubectl apply -f 01-superopsmsb-runtimeclass.yaml检查效果
[root@kubernetes-master1 /data/kubernetes/gvisor]# kubectl get runtimeclasses.node.k8s.io
NAME HANDLER AGE
superopsmsb-runtimeclass runsc 63s
pod测试
创建资源清单文件 02-superopsmsb-runtimeclass-podtest.yaml
apiVersion: v1
kind: Pod
metadata:name: superopsmsb-podtest
spec:runtimeClassName: superopsmsb-runtimeclassnodeName: kubernetes-node4containers:- image: kubernetes-register.superopsmsb.com/superopsmsb/nginx_web:v0.1imagePullPolicy: IfNotPresentname: nginxwebresources: {}
应用资源清单文件
kubectl apply -f 02-superopsmsb-runtimeclass-podtest.yaml查看效果
[root@kubernetes-master1 /data/kubernetes/gvisor]# kubectl get pod -o wide
NAME ... STATUS ... NODE ...
superopsmsb-podtest ... Running ... kubernetes-node4 ...检查进程
root@kubernetes-node4:~# ps aux | grep podtest
结果显示:容器应用被应用在沙箱里面了
确认容器的运行效果
[root@kubernetes-master1 /data/kubernetes/gvisor]# kubectl exec superopsmsb-podtest -- dmesg
[ 0.000000] Starting gVisor...
...
[ 3.223390] Ready!
查看pod容器的标识
[root@kubernetes-master1 /data/kubernetes/gvisor]# kubectl describe pod superopsmsb-podtest | grep containerdContainer ID: containerd://edfe3cfd5746fe82e90c83d37f7c9f28b1f0aaebf7611f13cdd1e6754599b915
查看gVisor的效果
root@kubernetes-node4:~# ps aux | grep runsc | grep edfe3cfd5746fe82e90c
root 91118 0.0 0.4 754200 18784 ? Sl 10:27 0:00 runsc-gofer --root=/run/containerd/runsc/k8s.io --log=/run/containerd/io.containerd.runtime.v2.task/k8s.io/edfe3cfd5746fe82e90c83d37f7c9f28b1f0aaebf7611f13cdd1e6754599b915/log.json ...
结果显示:pod已经通过runsc以沙箱的形式运行了


![Yocto系列讲解[技巧篇]92 - armv8 aarch64兼容armv7 32位程序运行环境](https://img-blog.csdnimg.cn/f64e1f114d7045eaa57a680daec4395b.png)