Ceph简介
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。
在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。
RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
Ceph特点
• 高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
• 高可用性
a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。
• 高可扩展性
a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
• 特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
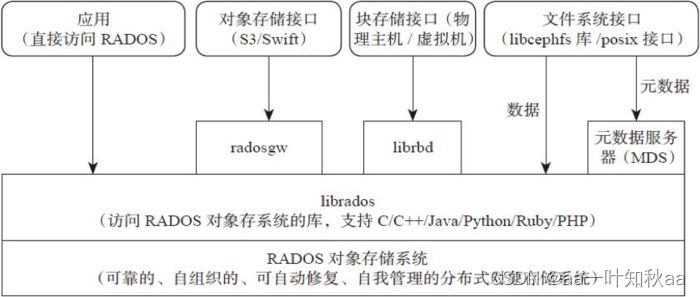
Ceph架构
支持三种接口:
• Object:有原生的API,而且也兼容Swift和S3的API。
• Block:支持精简配置、快照、克隆。
• File:Posix接口,支持快照。
Ceph核心组件及概念介绍
• Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
• OSD
OSD全称Object Storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD。
• MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
• Object
Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据。
• PG
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
• RADOS
RADOS全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
• Libradio
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
• CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
• RBD
RBD全称RADOS block device,是Ceph对外提供的块设备服务。
• RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
• CephFS
CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
• Pool:存储池,是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本
分布策略;支持两种类型:副本(replicated)和 纠删码(Erasure Code)
> 一个Pool里有很多PG;
> 一个PG里包含一堆对象;一个对象只能属于一个PG;
> PG属于多个OSD,分布在不同的OSD上;
实验环境
server153 centos7 192.168.121.153 系统盘sda OSD: sdb sdc 20GB ceph-deploy mon X 1 osd X 2
server154 centos7 192.168.121.154 系统盘sda OSD: sdb sdc 20GB mon X 1 osd X 2
server155 centos7 192.168.121.155 系统盘sda OSD: sdb sdc 20GB mon X 1 osd X 2
首先就是环境的准备,我这里选用三台主机
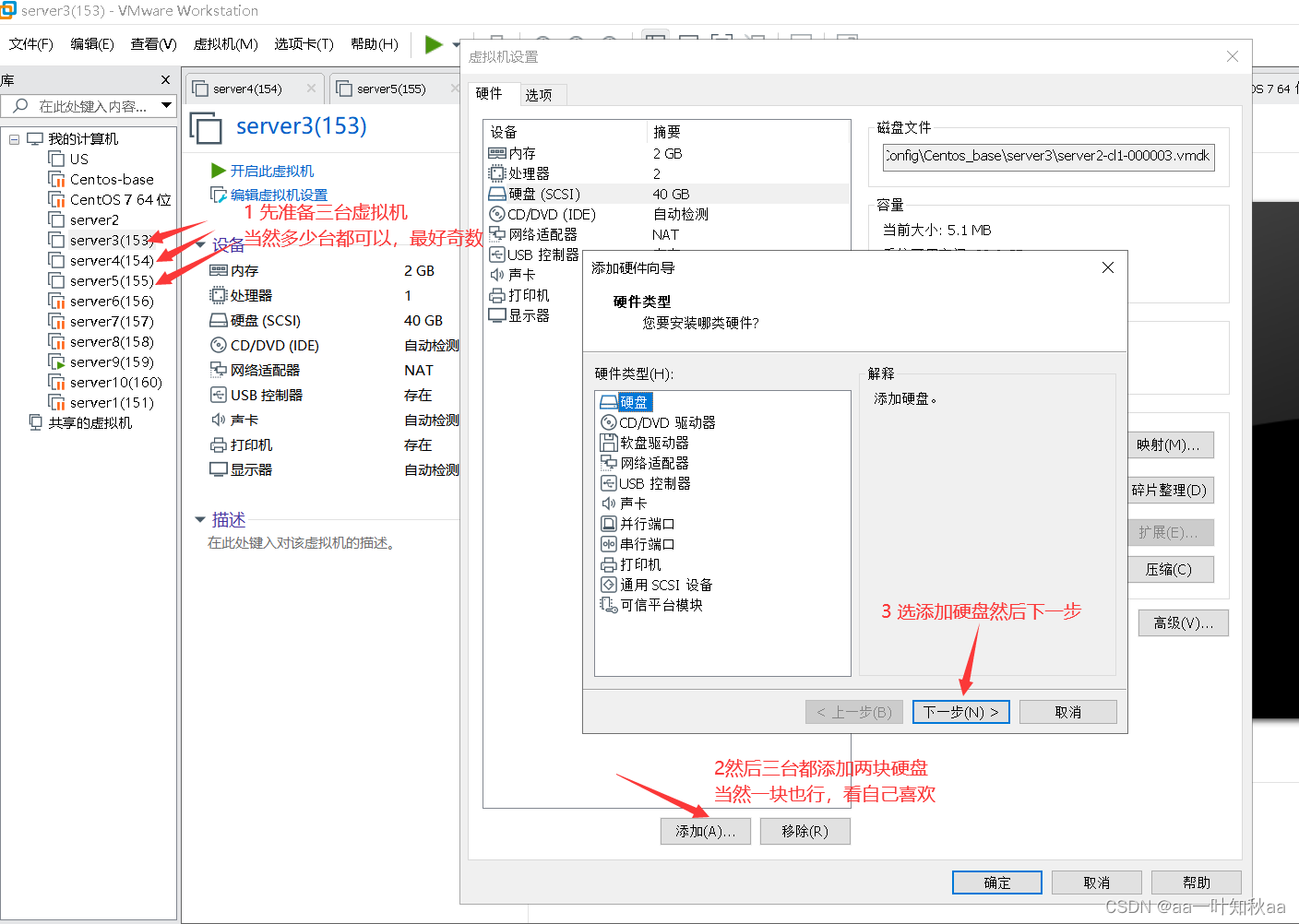
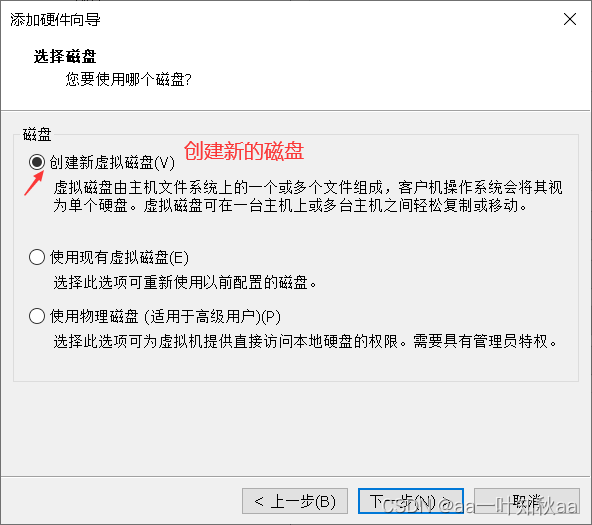
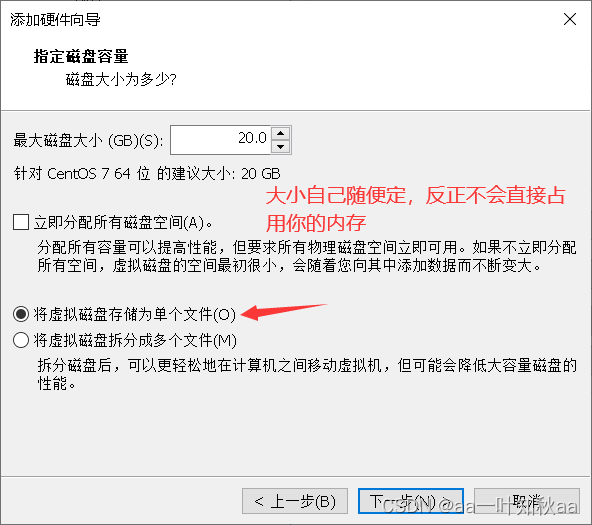
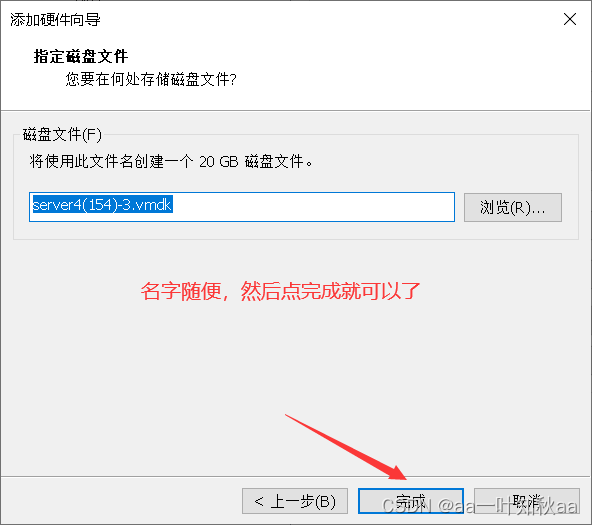
这样环境就准备好了,接下来启动三台主机
先同步所有机器的时间,ceph分布式存储系统对时间的要求还是比较严格的
yum install -y ntpdate
ntpdate ntp.aliyun.com
然后配置主机间的解析,这个看自己的集群来配
vim /etc/hosts
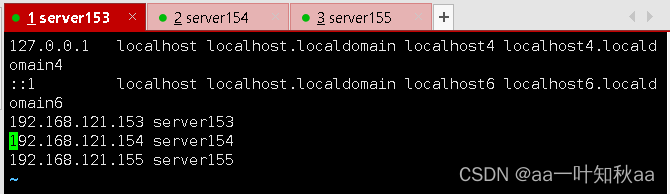
关闭selinux
setenforce 0
sed -i '/SELINUX=/cSELINUX=disabled' /etc/selinux/config
然后配置各主机之间的ssh密钥互信,这里我就不介绍了
这个我在之前的作品中有详细介绍过,忘记了的话可以去看看
ssh密钥互信的配置
还要注意一点,对自己主机的密钥互信也要配,不是其它两台而已
然后修改最大打开文件数
cat > /etc/security/limits.conf << EOF
* soft nofile 65535
* hard nofile 65535
EOF
然后退出重连,让配置文件在当前环境生效
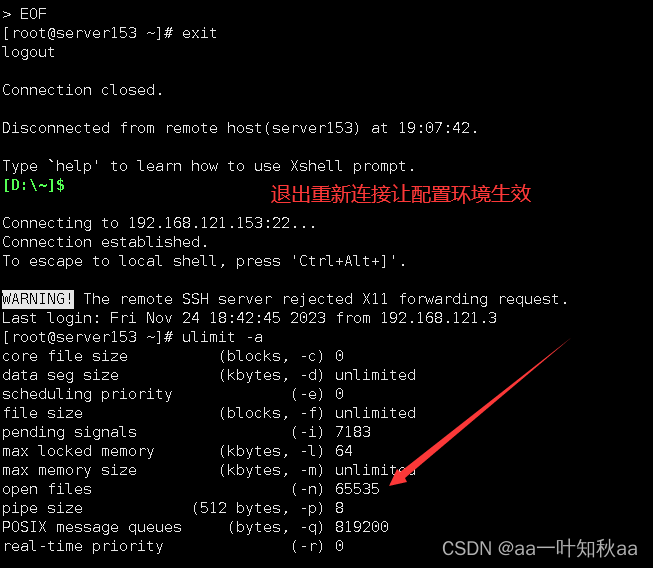
配置软件包下载的yum源,在阿里源就有
配置阿里的epel源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
然后配置ceph的yum源,阿里也有,根据自己的系统来选,我用的是centos7
这个是阿里镜像源

cat > /etc/yum.repos.d/ceph.repo << EOF
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
gpgcheck=0
priority=1[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
gpgcheck=0
priority=1[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
gpgcheck=0
priority=1
EOF
重新制作yum缓存
yum clean all
yum makecache fast
选一台主机来安装ceph-deploy,用于集群的初始化
可以用别的主机,也可以用这三台中的某一台,我这里选用153
用pip来安装,因为yum安装的版本太低
[root@server153 ~]# pip install ceph-deploy==2.0.1 -i https://mirrors.aliyun.com/pypi/simple/
查看ceph版本是否对
[root@server153 ~]# ceph-deploy --version
2.0.1没问题就开始初始化集群
先创建一个目录来执行后面的命令,因为后面会产生一些配置文件,都是在这个目录里执行才有效
[root@server153 ~]# mkdir ~/ceph-cluster
[root@server153 ~]# cd ~/ceph-cluster/
开始创建集群
[root@server153 ceph-cluster]# ceph-deploy new server153 server154 server155
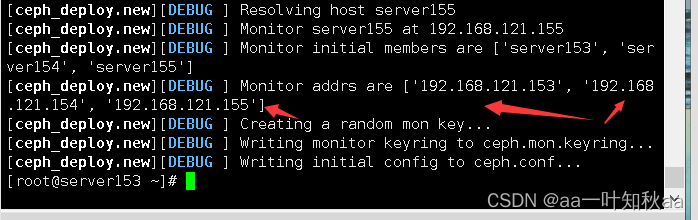
这样集群就创建好了
然后所有节点安装 ceph 组件包,当然了在ceph-deploy执行就可以了
[root@server153 ceph-cluster]# ceph-deploy install --no-adjust-repos server153 server154 server155
部署 monitor 服务,产生相关的管理秘钥
[root@server153 ceph-cluster]# ceph-deploy mon create-initial
查看当前目录产生的文件
[root@server153 ceph-cluster]# ls
ceph.bootstrap-mds.keyring ceph.client.admin.keyring
ceph.bootstrap-mgr.keyring ceph.conf
ceph.bootstrap-osd.keyring ceph-deploy-ceph.log
ceph.bootstrap-rgw.keyring ceph.mon.keyring查看启动的服务和端口

将配置文件分发给所以节点
[root@server153 ceph-cluster]# ceph-deploy admin server153 server154 server155
然后查看我们添加的两块磁盘
ls: cannot access blk: No such file or directory
[root@server153 ceph-cluster]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 400M 0 part /boot
└─sda2 8:2 0 39.6G 0 part ├─centos-lv_root 253:0 0 37.6G 0 lvm /└─centos-lv_swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sr0 11:0 1 1024M 0 rom 每个节点都一样的
现在将他们创建为osd对象
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdb server153
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdb server154
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdb server155
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdc server153
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdc server154
[root@server153 ceph-cluster]# ceph-deploy osd create --data /dev/sdc server155然后部署 MGR 服务
[root@server153 ceph-cluster]# ceph-deploy mgr create server153 server154 server155
然后查看集群情况
[root@server153 ceph-cluster]# ceph -s
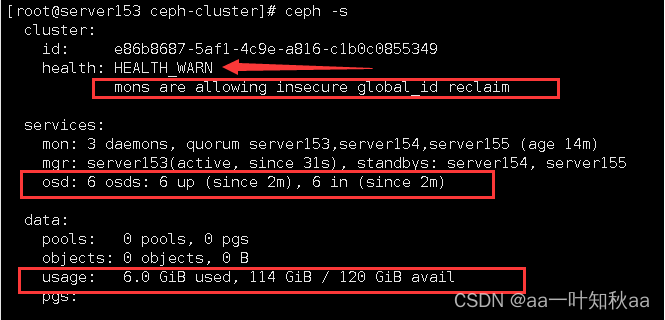
可以看到是正常的,但是有一个警告,提示 mon允许运行在 全局 非安全环境下
所以我们现在去解决这个问题
[root@server153 ceph-cluster]# ceph config set mon auth_allow_insecure_global_id_reclaim false
然后再查看集群的情况
[root@server153 ceph-cluster]# ceph -s

这样集群就正常了
ceph分布式存储系统的安装这样就完成了
希望对大家有用
下一篇再讲ceph分布式存储系统的使用