经过Analyzer的处理,Unresolved LogicalPlan已经解析成为Analyzed LogicalPlan。Analyzed LogicalPlan中自底向上节点分别对应Relation、Subquery、Filter和Project算子。
Analyzed LogicalPlan基本上是根据Unresolved LogicalPlan一对一转换过来的,对于SQL语句中的逻辑能够很好地表示。然而,在实际应用中,很多低效的写法会带来执行效率的问题,需要进一步对Analyzed LogicalPlan进行处理,得到更优的逻辑算子树。于是,针对SQL逻辑算子树的优化器Optimizer应运而生。
Optimizer概述
在分析Rule体系时就已经提到,Optimizer同样继承自RuleExecutor类,本身没有重载RuleExecutor中的execute方法,因此其执行过程仍然是调用其父类RuleExecutor中实现的execute方法。在QueryExecution中,Optimizer会对传入的Analyzed LogicalPlan执行execute方法,启动优化过程。
val optimizedPlan: LogicalPlan = optimizer.execute(analyzed)
与Analyzer类似,Optimizer的主要机制也依赖重新定义的一系列规则,同样对应RuleExecutor类中的成员变量batches,因此在RuleExecutor执行execute方法时会直接利用这些规则Batch。
如图1 所示,Optimizer继承自RuleExecutor,而SparkOptimizer又继承自Optimizer。在上述代码中,optimizer即是构造的SparkOptimizer类。从图中可以看出,Optimizer本身定义了12个规则Batch,在SparkOptimizer类中又添加了4个Batch。
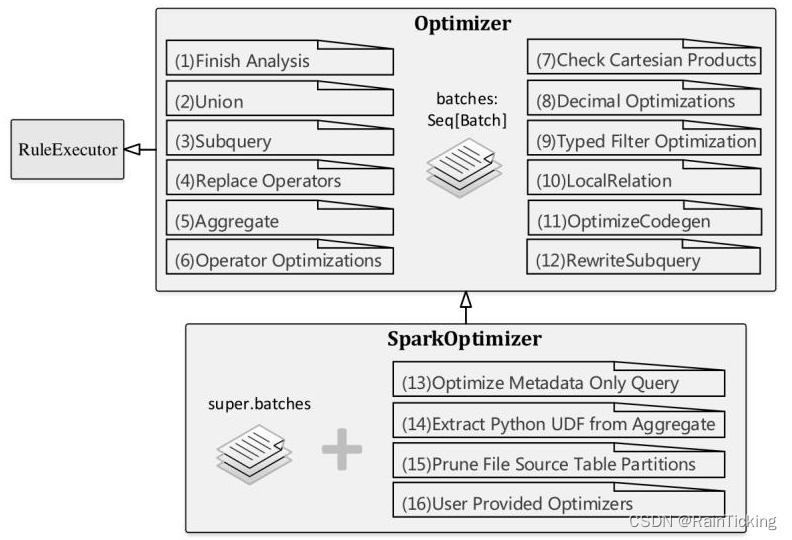
Optimizer 规则体系
Spark 2.1版本的SparkOptimizer中共实现了16个Batch,其中包含了53条优化规则,本节对这些优化规则进行系统的分析。
(1)Batch Finish Analysis
该Batch包含5条优化规则,分别是EliminateSubqueryAliases、ReplaceExpressions、ComputeCurrentTime、GetCurrentDatabase和RewriteDistinctAggregates,这些规则都只执行一次。
① EliminateSubqueryAliases:消除子查询别名,对应逻辑算子树中的SubqueryAlias节点。一般来讲,Subqueries仅用于提供查询的视角范围(Scope)信息,一旦Analyzer阶段结束,该节点就可以被移除,该优化规则直接将SubqueryAlias替换为其子节点。
② ReplaceExpressions:表达式替换,在逻辑算子树中查找匹配RuntimeReplaceable的表达式并将其替换为能够执行的正常表达式。这条规则通常用来对其他类型的数据库提供兼容的能力,例如,可以用“coalesce”来替换支持“nvl”的表达式。
③ ComputeCurrentTime:计算与当前时间相关的表达式,在同一条SQL语句中可能包含多个计算时间的表达式,即CurrentDate和CurrentTimestamp,且该表达式出现在多个语句中。为避免不一致,ComputeCurrentTime对逻辑算子树中的时间函数计算一次后,将其他同样的函数替换成该计算结果。
④ GetCurrentDatabase:获取当前数据库,在SQL语句中可能会调用CurrentDatabase函数来获取Catalog中的当前数据库,而这个方法没必要在执行阶段再进行计算。GetCurrentDatabase规则执行CurrentDatabase并得到结果,然后用此结果替换所有的CurrentDatabase表达式。
⑤ RewriteDistinctAggregates:重写Distinct聚合操作,对于包含Distinct算子的聚合语句,这条规则将其转换为两个常规的聚合表达式。
严格来讲,Finish Analysis这个Batch中的一些规则更多的是为了得到正确的结果(例如ComputeCurrentTime),并不涉及优化操作,从逻辑上更应该归于Analyzer的分析规则中。但是考虑到Analyzer中会进行一些规范化的操作,因此将EliminateSubqueryAliases和ComputeCurrentTime规则放在优化的部分,实际上真正的优化过程从下一个Batch开始。
(2)Batch Union⇒CombineUnions
针对Union操作的规则Batch,中间包含一条CombineUnions优化规则。在逻辑算子树中,当相邻的节点都是Union算子时,可以将这些相邻的Union节点合并为一个Union节点。在该规则中,flattenUnion是核心方法,用栈实现了节点的合并。需要注意的是,后续的优化操作可能会将原来不相邻的Union节点变得相邻,因此在后面的规则Batch中又加入了CombineUnions这条规则。
(3)Batch Subquery⇒OptimizeSubqueries
该Batch目前只包含OptimizeSubqueries这一条优化规则。当SQL语句包含子查询时,会在逻辑算子树上生成SubqueryExpression表达式。OptimizeSubqueries优化规则在遇到Subquery-Expression表达式时,进一步递归调用Optimizer对该表达式的子计划并进行优化。
(4)Batch ReplaceOperators
该Batch中的优化规则主要用来执行算子的替换操作。在SQL语句中,某些查询算子可以直接改写为已有的算子,避免进行重复的逻辑转换。Replace Operators中包含ReplaceIntersectWithSemiJoin、ReplaceExceptWithAntiJoin和ReplaceDistinctWithAggregate这3条优化规则。
① ReplaceIntersectWithSemiJoin:将Intersect操作算子替换为Left-Semi Join操作算子,从逻辑上来看,这两种算子是等价的。需要注意的是,ReplaceIntersectWithSemiJoin优化规则仅适用于INTERSECTDISTINCT类型的语句,而不适用于INTERSECTALL语句。此外,该优化规则执行之前必须消除重复的属性,避免生成的Join条件不正确。
② ReplaceExceptWithAntiJoin:将Except操作算子替换为Left-Anti Join操作算子,从逻辑上来看,这两种算子是等价的。与上一条优化规则一样,ReplaceExceptWithAntiJoin优化规则仅适用于EXCEPTDISTINCT类型的语句,而不适用于EXCEPTALL语句。此外,该优化规则执行之前必须消除重复的属性,避免生成的Join条件不正确。
③ ReplaceDistinctWithAggregate:该优化规则会将Distinct算子转换为Aggregate语句。在某些SQL语句中,Select直接进行Distinct操作,这种情况下可以将其直接转换为聚合操作。ReplaceDistinctWithAggregate规则会将Distinct算子替换为对应的Group By语句。
从以上描述中可以看出,ReplaceOperators主要针对的是集合类型的操作算子。
(5)Batch Aggregate
该Batch主要用来处理聚合算子中的逻辑,包括RemoveLiteralFromGroupExpressions和RemoveRepetitionFromGroupExpressions两条规则。RemoveLiteralFromGroupExpressions优化规则用来删除Group By语句中的常数,这些常数对于结果无影响,但是会导致分组数目变多。此外,如果Group By语句中全部是常数,则会将其替换为一个简单的常数0表达式。RemoveRepetitionFromGroupExpressions优化规则将重复的表达式从Group By语句中删除,同样对结果无影响。
(6)Batch Operator Optimizations
类似Analyzer中的Operator解析规则,该Batch包含了Optimizer中数量最多同时也是最常用的各种优化规则,共31条。从整体来看,这31条优化规则(如表1所示)可以分为3个模块:算子下推(Operator Push Down)、算子组合(Operator Combine)、常量折叠与长度削减(Constant Folding and Strength Reduction)。
算子下推:算子下推是数据库中常用的优化方式,表1中所列的前8条规则都属于算子下推的模块。顾名思义,算子下推所执行的优化操作主要是将逻辑算子树中上层的算子节点尽量下推,使其靠近叶子节点,这样能够在不同程度上减少后续处理的数据量甚至简化后续的处理逻辑。以常见的列剪裁(ColumnPruning)优化为例,假设数据表中有A、B、C 3列,但是查询语句中只涉及A、B两列,那么ColumnPruning将会在读取数据后剪裁出这两列。又如Lim itPushDown优化规则,能够将LocalLimit算子下推到Union All和Outer Join操作算子的下方,减少这两种算子在实际计算过程中需要处理的数据量。
算子组合:算子组合类型的优化规则将逻辑算子树中能够进行组合的算子尽量整合在一起,避免多次计算,以提高性能。表1中间6条规则(从CollapseRepartition到CombineUnions)都属于算子组合类型的优化。可以看到这些规则主要针对的是重分区(repartition)算子、投影(Project)算子、过滤(Filter)算子、Window算子、Limit算子和Union算子,其中CombineUnions在之前已经提到过。需要注意的是,这些规则主要针对的是算子相邻的情况。
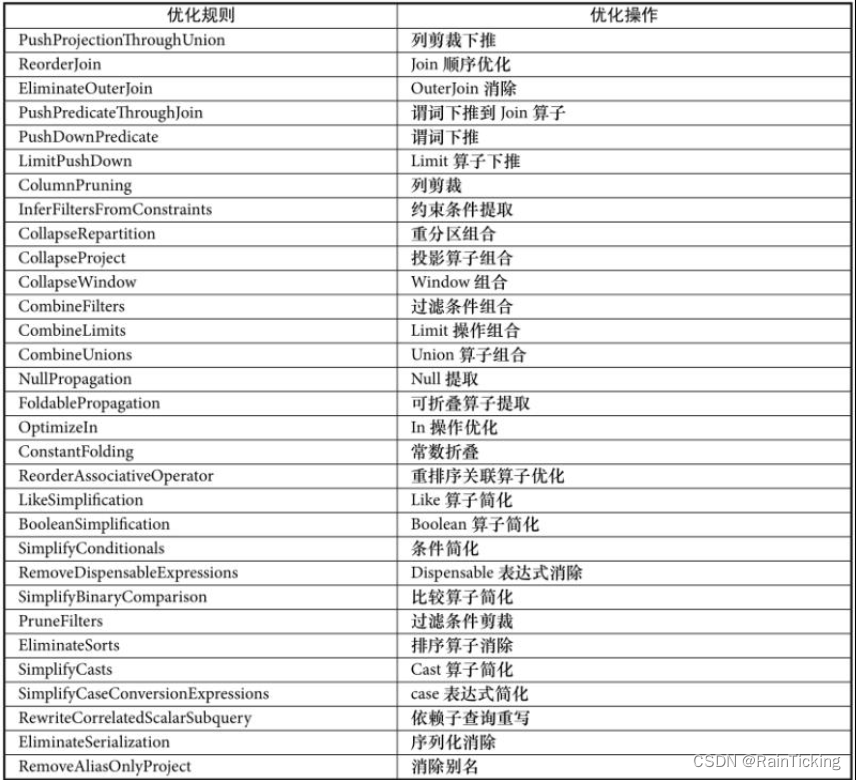
常量折叠与长度削减:对于逻辑算子树中涉及某些常量的节点,可以在实际执行之前就完成静态处理。常量折叠与长度削减类型的优化规则主要针对的就是这种情况。表1中的后17条优化规则都属于这种类型。例如,在ConstantFolding规则中,对于能够foldable(可折叠)的表达式会直接在EmptyRow上执行evaluate操作,从而构造新的Literal表达式;PruneFilters优化规则会详细地分析过滤条件,对总是能够返回true或false的过滤条件进行特别的处理。
(7)Batch Check Cartesian Products⇒CheckCartesianProducts
该Batch只有CheckCartesianProducts这一条优化规则,用来检测逻辑算子树中是否存在笛卡儿积类型的Join操作。如果存在这样的操作,而SQL语句中没有显示地使用cross join表达式,则会抛出异常。CheckCartesianProducts规则必须在ReorderJoin规则执行之后才能执行,确保所有的Join条件收集完毕。需要注意的是,当“spark.sql.crossJoin.enabled”参数设置为true时,该规则会被忽略。
(8)Batch DecimalOptim izations⇒DecimalAggregates
该Batch只有DecimalAggregates这一条优化规则,用于处理聚合操作中与Decimal类型相关的问题。一般情况下,如果聚合查询中涉及浮点数的精度处理,性能就会受到很大的影响。对于固定精度的Decimal类型,DecimalAggregates规则将其当作unscaled Long类型来执行,这样可以加速聚合操作的速度。
(9)Batch Typed Filter Optimization⇒CombineTypedFilters
该Batch仅包含CombineTypedFilters这一条优化规则,用来对特定情况下的过滤条件进行合并。当逻辑算子树中存在两个TypedFilter过滤条件且针对同类型的对象条件时,CombineTypedFilters优化规则会将它们合并到同一个过滤函数中。
(10)Batch LocalRelation⇒ConvertToLocalRelation|PropagateEmptyRelation
该Batch主要用来优化与LocalRelation相关的逻辑算子树,包含ConvertToLocalRelation和PropagateEmptyRelation两条优化规则。ConvertToLocalRelation将LocalRelation上的本地操作(不涉及数据交互)转换为另一个LocalRelation,目前该规则实现较为简单,仅处理Project投影操作。PropagateEmptyRelation优化规则会将包含空的LocalRelation进行折叠。
(11)Batch OptimizeCodegen⇒OptimizeCodegen
该Batch只有OptimizeCodegen这一条优化规则,用来对生成的代码进行优化。OptimizeCodegen规则主要针对的是casewhen语句,当casewhen语句中的分支数目不超过配置中的最大数目时,该表达式才能执行代码生成。
(12)Batch RewriteSubquery⇒RewritePredicateSubquery|CollapseProject
该Batch主要用来优化子查询,目前包含RewritePredicateSubquery和CollapseProject两条优化规则。RewritePredicateSubquery将特定的子查询谓词逻辑转换为left-semi/anti join操作。其中,EXISTS和NOTEXISTS算子分别对应semi和anti类型的Join,过滤条件会被当作Join的条件;IN和NOT IN也分别对应semi和anti类型的Join,过滤条件和选择的列都会被当作join的条件。CollapseProject优化规则比较简单,类似CombineTypedFilters优化规则,会将两个相邻的Project算子组合在一起并执行别名替换,整合成一个统一的表达式。
(13)Batch OptimizeMetadataOnly Query⇒OptimizeMetadataOnlyQuery
该Batch仅执行一次,只有OptimizeMetadataOnlyQuery这一条规则,用来优化执行过程中只需查找分区级别元数据的语句。需要注意的是,OptimizeMetadataOnlyQuery优化规则适用于扫描的所有列都是分区列且包含聚合算子的情形,而且聚合算子需要满足以下情况之一:聚合表达式是分区列;分区列的聚合函数有DISTINCT算子;分区列的聚合函数中是否有DISTINCT算子不影响结果。
(14)Batch Extract Python UDF from Aggregate⇒ExtractPythonUDFFrom Aggregate
该Batch仅执行一次,只有ExtractPythonUDFFrom Aggregate这一条规则,用来提取出聚合操作中的Python UDF函数。该规则主要针对的是采用PySpark提交查询的情形,将参与聚合的Python自定义函数提取出来,在聚合操作完成之后再执行。
(15)Batch Prune FileSource TablePartitions⇒PruneFileSourcePartitions
该Batch仅执行一次,只有PruneFileSourcePartitions这一条规则,用来对数据文件中的分区进行剪裁操作。当数据文件中定义了分区信息且逻辑算子树中的LogicalRelation节点上方存在过滤算子时,PruneFileSourcePartitions优化规则会尽可能地将过滤算子下推到存储层,这样可以避免读入无关的数据分区。
(16)Batch User Provided Optimizers⇒ExperimentalMethods.extraOptimizations
顾名思义,该Batch用于支持用户自定义的优化规则,其中ExperimentalMethods的extraOptim izations队列默认为空。可以看到,Spark SQL在逻辑算子树的转换阶段是高度可扩展的,用户只需要继承Rule[LogicalPlan]虚类,实现相应的转换逻辑就可以注册到优化规则队列中应用执行。
Optimized LogicalPlan的生成过程
上述内容对SparkOptimizer中的优化规则进行了系统概述,现在回到案例对应的Analyzed LogicalPlan。接下来,将会重点分析Optimzer对该逻辑算子树进行优化处理的具体流程。
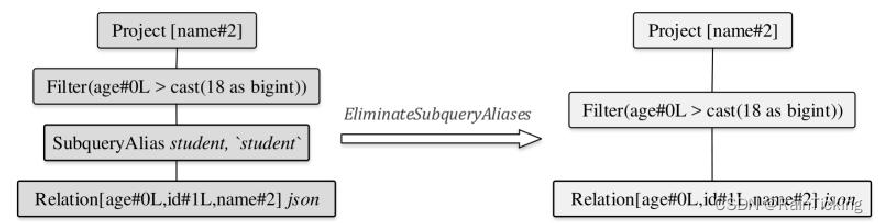
对于案例生成的Analyzed LogicalPlan,首先执行的是Finish Analysis这个Batch中的Eliminate-SubqueryAliases优化规则,用来消除子查询别名的情形。
EliminateSubqueryAliases优化规则的实现逻辑如以下代码所示,可以看到,该规则的实现非常简单,直接将SubqueryAlias逻辑算子树节点替换为其子节点。经过EliminateSubqueryAliases规则优化后的逻辑算子树如图2所示。可见SubqueryAlias节点被删除,Filter节点直接作用于Relation节点。
object EliminateSubqueryAliases extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {case SubqueryAlias(_, child, _) = child }
}
第2步优化将匹配OperatorOptimizations这个Batch中的InferFiltersFromConstraints优化规则,用来增加过滤条件。InferFiltersFromConstraints优化规则会对当前节点的约束条件进行分析,生成额外的过滤条件列表,这些过滤条件不会与当前算子或其子节点现有的过滤条件重叠,具体实现如以下代码片段所示(注:案例逻辑算子树中不涉及Join查询语句,因此这里的代码片段中未包含Join算子的匹配部分)。
object InferFiltersFromConstraints extends Rule[LogicalPlan] with PredicateHelper {def apply(plan: LogicalPlan): LogicalPlan = plan transform {case filter @ Filter(condition, child) => val newFilters = filter.constraints -- (child.constraints ++ splitConjunctivePredicates(condition))if (newFilters.nonEmpty) {Filter(And(newFilters.reduce(And), condition), child)} else {filter}}
}
从上述代码逻辑可知,对于上一步生成的逻辑算子树中的Filter节点,会构造新的过滤条件(newFilter)。当新的过滤条件不为空时,会与现有的过滤条件进行整合,构造新的Filter逻辑算子节点。
经过InferFiltersFromConstraints规则优化之后的逻辑算子树如图3所示,Filter逻辑算子树节点中多了“isnotnull(age#0L)”这个过滤条件。该过滤条件来自于Filter中的约束信息,用来确保筛选出来的数据age字段不为null。
最后一步,上述逻辑算子树会匹配Operator Optimizations这个Batch中的ConstantFolding优化规则,对LogicalPlan中可以折叠的表达式进行静态计算直接得到结果,简化表达式。
object ConstantFoldingFolding extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan transform {case q: LogicalPlan => q transformExpressionsDown {case l: Literal => lcase e if e.foldable => Literal.create(e.eval(EmptyRow), e.dataType)}}
}

在ConstantFolding规则中,如果LogicalPlan中的表达式可以折叠(foldable为true),那么会将EmptyRow作为参数传递到其eval方法中直接计算,然后根据计算结果构造Literal常量表达式。经过该规则优化后的逻辑算子树如图4所示。
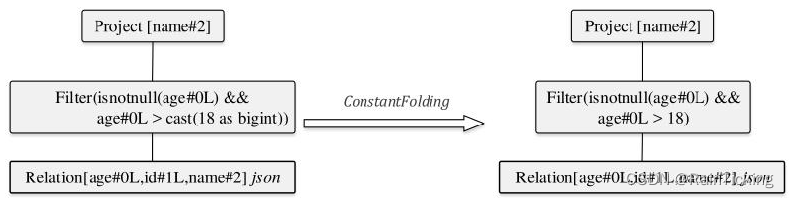
可见,Filter过滤条件中的“cast(18,bigint)”表达式经过计算成为“Literal(18,bigint)”表达式,即输出的结果为18。在原来的Cast表达式中,其子节点Literal表达式的foldable值为true,因此Cast表达式本身的foldable值也为true,在匹配该优化规则时,Cast表达式会被直接计算。
经过上述步骤,Spark SQL逻辑算子树生成、分析与优化的整个阶段都执行完毕。最终生成的逻辑算子树包含Relation节点、Filter节点和Project节点,同时每个节点中又包含了由对应表达式构成的树。