实体
实体是语义相关特征的集合。用户定义实体以映射其用例的领域。
例如,打车车服务可以将客户和司机作为实体,这些实体将相关特征分组,对应于这些客户和司机。
driver = Entity(name='driver', join_keys=['driver_id']) # 司机实体
customer = Entity(name='customer', join_keys['customer_id']) # 乘客实体- name:实体名
- join_key:连接键,实体表的主键
Feast在许多情况下会使用到实体,如下所述:
- 定义和存储特征
- 检索特征
定义和存储特征
它是一组特征的集合(feature view(关键组件),特征视图映射到0个或多个实体,因为一个特征可以与以下内容相关联:
- 0个实体:例如全局特征,如num_daily_global_transactions(每日全球交易数量)
- 1个实体:例如用户特征,如user_age(用户年龄)或last_5_bought_items(最近购买的5个商品)
- 多个实体,即组合键:例如用户+商户类别特征,如num_user_purchases_in_merchant_category(某商户类别中用户的购买数量)
Feast将此特征视图的实体集合称为entity_key实体键,如下图:
实体应该在不同的特征视图中被重复使用。这有助于发现特征,因为它使数据科学家能够了解其他团队如何为他们最感兴趣的实体构建特征。
Feast将使用特征视图概念来定义低延迟在线仓库中一组特征的架构。(通过使用特征视图,我们可以更有效地组织和管理这些特征,从而降低查询和检索数据的延迟。)
特征检索
在训练过程中,此时用户控制想要查询的实体。例如,用户可以指定与训练、测试和验证划分对应的实体。然后,用户指定一个实体键和时间戳,以便获取在特定时间点的正确特征。这些特征将被用于生成训练数据集。
在服务过程中,此时用户可以指定一个或多个实体键。通过这种方式,用户可以获取最新的特征值,这些特征值可以驱动实时模型进行预测。例如,欺诈检测模型需要获取最新的交易用户特征来进行预测。在这种情况下,实时模型可以根据最新的特征值进行预测,从而提高预测的准确性和实时性。
这两个用例都强调了在训练和服务过程中获取和利用特征的重要性,以便为各种应用场景提供更好的性能和结果。
解释:在训练过程中,我们使用实体键来获取实体及其特征,以便生成训练数据集。在服务过程中,我们使用实体键来获取最新版本的实体特征,以驱动实时模型预测。这样做可以确保我们在训练和服务过程中使用最新、最准确的数据,从而提高模型性能。
问:我能检索所有实体的特征吗?
答:Feast:桥接机器学习模型和数据中搜索“我能检索所有实体的特征吗?”在“离线存储”部分有回答。
特征视图
注意:特征视图不支持非时间戳数据。一种解决方法是在数据中插入虚拟时间戳。
解释:
插入时间戳是一种权宜之计,它允许您将非时间戳数据转换为时间戳数据,从而使数据符合特征视图的要求。这可以帮助您在时间序列分析中使用这些数据,尽管这种方法可能会影响数据的真实性。
在实际应用中,您可能需要考虑这种方法对分析结果的影响。在非时间戳数据中插入虚拟时间戳。这样,数据就具有了时间戳,可以应用于特征视图进行分析。在非时间戳数据中插入虚拟时间戳。这样,数据就具有了时间戳,可以应用于特征视图进行分析。
特征视图(Feature View)是一个对象,它代表了一个逻辑组的时间序列特征数据,这些数据存在于一个特定的数据源中。根据特征视图的类型,它可能包含一些轻量级(实验性)的特征转换。这里的“轻量级特征转换”指的是对原始特征数据进行一定程度的处理和变换,以适应机器学习模型或其他用途。
特征视图(Feature Views)包括以下几个部分:
- 数据源(Data Source):特征视图的基础是数据源,它是提供数据的地方。数据源可以是各种类型,如关系型数据库、非关系型数据库、文件等。
- 0个或多个实体(Zero or more entities):实体是特征视图中的关键组件,它将数据源中的特征组织在一起。如果特征与特定对象无关,那么特征视图可能不包含实体。以下将介绍不含实体的特征视图。
- 名称(Name):特征视图具有一个名称,用于在项目中唯一标识此特征视图。
- (可选,但推荐)数据结构(Schema):数据结构定义了特征视图中的一组特征。如果没有提供数据结构,Feast 会通过读取数据源自动推断数据结构。
- (可选,但推荐)元数据(Metadata):元数据是关于特征视图的额外信息,例如描述或其他通过标签实现的自由形式元数据,标签的作用主要包括:
- 分类和识别:通过为特征视图分配特定的标签,可以更容易地在项目中识别和找到它们。例如,在这个例子中,driver_hourly_stats 特征视图与驾驶员表现团队相关。
- 过滤和筛选:标签可以帮助您根据项目需求对特征视图进行过滤和筛选。例如,您可以根据标签筛选出与特定团队或业务场景相关的特征视图。
- 数据治理:标签可用于记录数据来源、数据质量、数据使用等信息,有助于实现对数据的全生命周期管理。
- 共享和协作:在团队间共享标签可以帮助提高工作效率,因为团队成员可以快速找到其他团队成员创建的特征视图,从而避免重复工作。
- (可选)生存周期(Time-to-Live,TTL):生存周期限制了当生成历史数据集时,Feast 回溯的时间范围。这意味着在特定时间点之后的数据将被丢弃或不再使用。(ttl为0表示这组特性永远存在。注意:较大的ttl或ttl为0可能导致非常计算密集型的查询。)
特征视图允许Feast在离线(训练)和在线(服务)环境中以一致的方式建模现有的特征数据。特征视图通常包含特定对象的属性,在这种情况下,该对象被定义为实体,并包含在特征视图中。
from feast import BigQuerySource, Entity, FeatureView, Field
from feast.types import Float32, Int64driver = Entity(name="driver", join_keys=["driver_id"])driver_stats_fv = FeatureView(name="driver_activity", # 视图名,唯一标识entities=[driver], # s实体列表,0或多个 schema=[ # s数据结构,不指定会自动扫描数据源并推断数据类型 Field(name="trips_today", dtype=Int64),Field(name="rating", dtype=Float32),],source=BigQuerySource( # 数据源table="feast-oss.demo_data.driver_activity")# ttl=timedelta(da生存周期,0标识永久存储,1),tt或较大,都l为0可能导致非常计算密集型。# 查询online=True, # 表示是否为此特性视图启用在线# 检索tags={"team": "driver_performance"}, 标签,帮助组织、管理特征视图表现# owner(可选):特性视图的所有者,通常为主维护者的电子邮件# description(可选):描述
)特征视图(Feature Views)在以下三个方面的应用:
- 训练数据集生成:在生成训练数据集时,特征视图通过查询特征视图的数据源来查找历史特征值。一个训练数据集可能包含来自多个特征视图的特征。
- 特征值加载:特征视图用于确定在线存储中的存储模式。特征值可以从批处理源或流处理源加载到在线存储中。
- 在线存储中的特征检索:特征视图向Feast 提供模式定义,以便从在线存储中查找特征。
这样,特征视图在整个数据处理和分析过程中确保了数据的consistency(一致性),提高了工作效率和准确性。
无实体特征视图
如果一个特征视图中包含的不需要与特定实体相关的特征,那么这个特征视图可以不包含实体(仅需包含时间戳)。
global_stats_fv = FeatureView(name="global_stats", # 全局统计entities=[], # 没有实体schema=[Field(name="total_trips_today_by_all_drivers", dtype=Int64),],source=BigQuerySource(table="feast-oss.demo_data.global_stats")
)特征推理(Feature inferencing)
是指在创建特征视图时,如果未指定schema参数,Feast 会通过创建每个底层数据源中的列对应的字段,来推断特征。这些列不包括特征视图中的实体列或特征视图数据源中的时间戳列。
换句话说,当创建特征视图时,如果没有指定架构参数,Feast会根据底层数据源中的列来推断特征。这些推断出的特征的字段名和值类型将使用其所属列的名称和数据类型。
这个过程的优点如下:
- 自动化:特征推理简化了创建特征视图的过程,节省了手动指定架构参数的时间和精力。
- 一致性:根据底层数据源中的列来推断特征,保证了特征视图与数据源的一致性。
- 可扩展:特征推理使得在新数据源或新列添加时,可以自动扩展特征视图,提高了系统的灵活性和可扩展性。
然而,需要注意的是,在某些情况下,自动推理出的特征可能不符合预期。在这种情况下,建议手动调整特征视图的架构参数,以确保特征推理的准确性。同时,在实际应用中,根据项目需求和数据特点,合理地设置特征视图的架构参数是非常重要的。
实体别名(Entity aliasing)
是指在创建特征视图时,可以指定将不匹配特征视图源表列名的实体datafream列进行连接。这种情况适用于以下情况:用户无法控制这些列名,或者存在多个实体是更通用实体的子类。
例如,spammer(垃圾邮件发送者)和reporter(报道者)可以作为user(用户)实体的别名,而origin(出发地)和destination(目的地)可以作为location(位置)实体的别名,如下所示:
entity_dataframe:
- entity_name: user
column_names: [spammer, reporter]
- entity_name: location
column_names: [origin, destination]
实体别名的作用是在实体datafream和源表之间建立映射,使得在不改变实体datafream列名的情况下,仍能正确地将数据连接到相应的实体。
建议使用.with_name动态指定新的特征视图名称,并使用.with_join_key_map覆盖连接键映射。这样,无需为每个新副本注册实体别名,从而简化了操作。
总之,实体别名功能使得在处理不同实体时更加灵活,可以适应列名不匹配或实体层次结构复杂的情况。通过使用实体别名,可以方便地在实体datafream和源表之间建立关联,提高数据处理的效率。
from feast import BigQuerySource, Entity, FeatureView, Field
from feast.types import Int32, Int64location = Entity(name="location", join_keys=["location_id"]) # 位置实体,连接键localtion_idlocation_stats_fv= FeatureView(name="location_stats", # 位置统计 特征是图entities=[location],schema=[Field(name="temperature", dtype=Int32), # 温度特征Field(name="location_id", dtype=Int64), # w位置特征],source=BigQuerySource( table="feast-oss.demo_data.location_stats),
)temperatures_fs = FeatureService(name="temperatures", # 温度 特征视图features=[location_stats_fv.with_name("origin_stats") # 特征新名称.with_join_key_map({"location_id": "origin_id"} # 连接键映射),location_stats_fv.with_name("destination_stats") # 特征新新名称.with_join_key_map({"location_id": "destination_id"} # 连接键映射),],
)字段/特征(Field)
字段或特征是个体可测量的属性,通常与特定实体相关,但也可以与实体无关。
字段可以是客户实体的平均每月交易次数,也可以是所有用户在上个月发布的总帖子数。Feast支持的字段类型可以在 sdk/python/feast/types.py中找到。
PRIMITIVE_FEAST_TYPES_TO_VALUE_TYPES = {"INVALID": "UNKNOWN","BYTES": "BYTES","STRING": "STRING","INT32": "INT32","INT64": "INT64","FLOAT64": "DOUBLE","FLOAT32": "FLOAT","BOOL": "BOOL","UNIX_TIMESTAMP": "UNIX_TIMESTAMP",
}字段作为特征视图的一部分进行定义。由于Feast不转换数据,字段本质上是一个仅包含名称和类型的架构。在Feast中,字段用于描述实体(如客户、产品等)的属性,以便在数据处理和分析过程中使用。这些字段可以用于构建数据模型、训练机器学习算法、实现数据挖掘等任务。通过使用字段,企业可以更好地了解其业务数据,从而做出更有意义的决策。
from feast import Field
from feast.types import Float32trips_today = Field(name="trips_today",dtype=Float32
)特征定义与数据源一起,告诉Feast在哪里查找特征值,例如特定Parquet文件或BigQuery表格中。特征定义还在从特征存储中读取特征时使用,通过特征引用实现。
特征名称必须在特征视图中唯一。每个字段都可以有与它相关的元数据,以键值标签的形式表示。这些元数据可以用于描述字段的更多详细信息,例如数据类型、单位、描述等。这有助于在分析和处理数据时更好地理解字段的含义和用途。
总之,特征定义在 Feast 中起着关键作用,它们定义了数据中的特征及其属性,使数据处理和分析更加准确和高效。通过为字段提供元数据,可以更好地管理和理解数据中的各种特征。在构建数据驱动的应用程序时,正确和详细地定义特征至关重要。
按需特征视图(On demand feature views)
按需特征视图允许数据科学家使用现有特征和请求时间数据(仅在请求时可用的特征)来转换和创建新特征。用户定义Python转换逻辑,该逻辑在历史检索和在线检索路径中都会被执行。
目前,这些转换在本地执行。这对于在线服务来说是没有问题的,但是当涉及到离线检索时,这种方法扩展性较差。这意味着随着数据量的增加,整体性能可能会受到影响。
为了解决这个问题,可以考虑将转换逻辑移至服务器端,以便在历史检索和在线检索过程中进行分布式处理。这可以提高离线检索性能,同时确保在线服务的高效运行。
总之,按需特征视图是一种灵活的数据转换方法,可用于创建新特征和处理请求时间数据。然而,随着数据量的增长,需要考虑优化转换逻辑的执行方式,以提高整体性能。
为什么使用按需特征视图:
-
-
-
- 数据科学家可以通过调用get_historical_features函数来生成一个训练dataframe。
- 在notebook中使用Pandas对特征工程进行迭代操作。
- 将转换逻辑复制到按需特征视图中,并将其提交到特征存储库的dev分支。
- 使用小数据集验证get_historical_features,确保转换在历史数据上产生预期的输出。
- 使用dev分支上的get_online_features验证转换是否正确地输出在线特征。
- 提交一个pull request到staging/prod分支,以影响生产流量。
-
-
通过这种方式,数据科学家可以灵活地调整和优化特征检索过程,以满足不断变化的需求和场景。同时使数据科学家在在线和离线场景中更快速地开发、测试和部署新特征和转换逻辑。
from feast import Field, RequestSource
from feast.on_demand_feature_view import on_demand_feature_view
from feast.types import Float64# 定义一个请求数据源input_request,其中包含仅在请求时间可用的特征:val_to_add、val_to_add_2
input_request = RequestSource(name="vals_to_add",schema=[Field(name="val_to_add", dtype=PrimitiveFeastType.INT64),Field(name="val_to_add_2": dtype=PrimitiveFeastType.INT64),]
)# 按需转换特征视图
@on_demand_feature_view(sources=[driver_hourly_stats_view, # 将某个特征视图作为数据源input_request # 将请求数据源作为数据源],schema=[ # 在请求时创建两个新特征:conv_rate_plus_val1、conv_rate_plus_val2Field(name='conv_rate_plus_val1', dtype=Float64),Field(name='conv_rate_plus_val2', dtype=Float64)]
)
def transformed_conv_rate(features_df: pd.DataFrame) -> pd.DataFrame:df = pd.DataFrame() # 生成新特征df['conv_rate_plus_val1'] = (features_df['conv_rate'] + features_df['val_to_add'])df['conv_rate_plus_val2'] = (features_df['conv_rate'] + features_df['val_to_add_2'])return df这个例子展示了如何使用按需特征视图在请求时创建新特征。这种方法可以帮助数据科学家灵活地处理请求时间数据,并在在线和离线场景中实现所需的功能,同时降低将新特征和转换逻辑部署到生产环境的时间和成本。
[Alpha] 流式特征视图
流式特征视图是对普通特征视图的扩展。主要区别在于,流式特征视图同时具有流式和批处理数据源,而普通特征视图仅具有批处理数据源。
当有流式数据源(如Kafka和Kinesis)可用以在在线环境中提供新鲜特征时,应使用流式特征视图代替普通特征视图。以下是一个带有附加转换的流式特征视图的定义示例:
from datetime import timedeltafrom feast import Field, FileSource, KafkaSource, stream_feature_view
from feast.data_format import JsonFormat
from feast.types import Float32# 批处理 文件数据源
driver_stats_batch_source = FileSource(name="driver_stats_source",path="data/driver_stats.parquet",timestamp_field="event_timestamp",
)# Kafka流数据源
driver_stats_stream_source = KafkaSource(name="driver_stats_stream",kafka_bootstrap_servers="localhost:9092",topic="drivers",timestamp_field="event_timestamp", # 指定时间戳字段batch_source=driver_stats_batch_source, # 同时使用批处理文件源message_format=JsonFormat(schema_json="driver_id integer, event_timestamp timestamp, conv_rate double, acc_rate double, created timestamp"),watermark_delay_threshold=timedelta(minutes=5),
)# 定义流式特征视图
@stream_feature_view(entities=[driver], # 指定实体ttl=timedelta(seconds=8640000000), # 生存周期,过期时间为24小时mode="spark",# 处理模式为sparkschema=[Field(name="conv_percentage", dtype=Float32),Field(name="acc_percentage", dtype=Float32),],timestamp_field="event_timestamp", # 时间戳字段online=True, # 在线模式为 True,表示处理实时数据source=driver_stats_stream_source, # 指定流式数据源
)
def driver_hourly_stats_stream(df: DataFrame):from pyspark.sql.functions import colreturn (df.withColumn("conv_percentage", col("conv_rate") * 100.0).withColumn("acc_percentage", col("acc_rate") * 100.0) # 将conv_rate和acc_rate分别乘100.0得到百分比表示.drop("conv_rate", "acc_rate") # 删除原始的conv_rate和acc_rate字段)示例中,最终driver_hourly_stats_stream函数将接收实时数据流,并将其转换为包含conv_percentage和acc_percentage字段的DataFrame。这个流式特征视图可以用于进一步的实时数据处理和分析。
流式特征视图用于处理实时数据流,以便在需要时获取最新特征。这在使用Kafka、Kinesis等流式数据源时非常有用。与普通特征视图相比,流式特征视图具有以下优势:
-
-
-
- 实时性:流式特征视图可以处理实时数据流,从而使数据科学家和工程师能够更快地获取和利用新鲜特征。
- 灵活性:流式特征视图可以同时处理批处理和流式数据,使其在处理混合数据场景时更加灵活。
- 易于扩展:流式特征视图可以轻松地扩展到大规模数据集,从而提高处理速度和吞吐量。
- 降低成本:通过流式特征视图,可以在不需要额外硬件和资源的情况下实时处理数据,从而降低成本。
-
-
在这个示例中,流式特征视图使用Kafka作为数据源,并提供了一个附加转换。这个转换可以是一个实时计算任务,如对数据进行聚合、过滤或统计操作。这使得数据科学家和工程师能够实时地从流式数据中提取有价值的信息,并在在线环境中应用这些信息。总之,流式特征视图是一种强大且灵活的工具,可帮助用户实时地从流式数据中提取和利用特征。
特征检索
概述
特征检索是指从特征存储中获取和使用特征的过程。在Feast中,支持以下几种特征检索模式:
-
-
-
- 训练数据生成:通过feature_store.get_historical_features(...)方法,从特征存储中获取历史特征,用于生成训练数据。这种模式主要用于预处理数据,将特征数据存储在特征存储中,以便在训练模型时使用。
- 离线特征检索:通过feature_store.get_historical_features(...)方法,从特征存储中获取历史特征,用于批量评分。这种模式适用于在训练模型后,根据现有特征数据进行批量预测的场景。
- 实时特征检索:通过feature_store.get_online_features(...)方法或部署的特征服务器端点,从特征存储中获取实时特征,用于实时模型预测。这种模式适用于需要实时处理新数据、更新模型预测的场景。
- 通过 SDK 获取实时特征:使用feature_store.get_online_features(...)方法,从特征存储中获取实时特征。这种方法适用于在应用程序中使用Feast SDK的场景。
- 通过部署的特征服务器端点获取实时特征:通过向特征服务器发送POST请求(例如:requests.post('http://localhost:6566/get-online-features', data=json.dumps(online_request))),将实时特征请求发送到服务器,然后从服务器响应中获取实时特征。这种方法适用于已部署特征服务器的场景,可以通过外部应用程序或其他服务调用此端点获取实时特征。
-
-
总之,Feast提供了多种特征检索模式,以满足不同场景下的需求。从训练数据生成到实时模型预测,都可以通过不同的方法从特征存储中获取和使用特征。这些模式有助于简化数据处理和模型预测任务,提高整个机器学习流程的效率。
每种检索机制都接受:
-
-
-
- 指定实体(用来获取特征)
- 指定获取特征的方法,可以是通过特征服务(按模型版本组织所需特征)或特征引用。
-
-
在开始之前,需要创建一个用于了解如何解析注册表的本地FeatureStore对象。
要查看以下代码示例,请查看使用feast init -t [YOUR TEMPLATE]生成的仓库(gcp、snowflake和aws模板最为完整)。
概念
在深入研究如何检索功能之前,我们需要了解Feast中的一些高级概念。
以下是涉及到的主要概念:
特征(Features):特征是用于训练和预测模型的数据属性。在 Feast 中,特征是以结构化的方式存储在特征存储中的。
实体(Entities):实体是具有唯一标识符的实体,例如用户、订单等。在 Feast 中,实体是用于关联特征和数据的关键。
特征版本(Feature Version):特征版本是一个特征在不同时间点的快照。随着新数据的到来,特征版本会不断更新。每个特征版本都有一个唯一的版本号。
特征服务(Feature Service):特征服务是一种组织和管理特征版本的方法。它将多个特征版本组合在一起,以便在训练模型时使用。特征服务有助于简化模型版本的切换和更新。
注册表(Registry):注册表是用于存储和管理特征、实体、特征版本和特征服务等信息的数据存储。注册表有助于实现对数据的全局视图,以便更好地管理和维护数据。
数据源(Data Source):数据源是数据传入 Feast 的途径。可以通过数据管道将数据从各种数据源(如 MySQL、Snowflake、CSV 等)导入到 Feast 中的注册表。
处理器(Processor):处理器是在 Feast 中处理数据的一种组件。处理器用于执行数据转换、清洗和预处理等操作,以便将数据存储为特征版本。
特征存储(Feature Store):特征存储是用于存储和管理特征数据的地方。它负责存储实体、特征版本和特征服务等信息。在 Feast 中,特征存储可以是本地化的,也可以是分布式的。
服务端点(Endpoints):服务端点是用于与特征存储和特征服务进行通信的接口。通过这些端点,可以执行诸如获取特征、更新特征版本等操作。
Feast SDK:Feast SDK 是一组用于与 Feast 平台交互的客户端库。通过 SDK,可以在应用程序中轻松地使用 Feast 功能,如检索特征、创建和更新特征版本等。
特征服务(Feature Services)
一个代表来自一个或多个特征视图的逻辑特征组的对象。
特征服务允许特征视图内的特征根据需要被机器学习(ML)模型使用。期望用户可以为每个模型版本创建一个特征服务,以便跟踪模型使用的特征。
在这里,特征服务的作用是将相关特征组合在一起,以便在ML模型训练和预测过程中更容易地使用它们。通过创建特征服务,用户可以确保在不同模型版本之间跟踪和使用相同的特征。这有助于保持模型的一致性,并便于对模型进行比较和优化。
例如,假设一个用户正在构建一个预测房价的ML模型。该用户可能需要使用房屋的面积、卧室数量、浴室数量等特征。通过创建一个特征服务,该用户可以将这些特征组合在一起,以便在模型训练和预测过程中轻松使用。这样用户可以专注于优化模型性能,而不必担心在不同模型版本中丢失重要特征。
总之,特征服务是一种组织和管理特征的方式,以便在ML模型中更有效地使用它们。通过为每个模型版本创建特征服务,用户可以跟踪使用的特征,确保模型的一致性,并简化模型的比较和优化过程。
from driver_ratings_feature_view import driver_ratings_fv
from driver_trips_feature_view import driver_stats_fv# 特征服务
driver_stats_fs = FeatureService(name="driver_activity", # 特征服务名# driver_stats_fv特征视图所有特征 和 driver_ratings_fv特征视图中的lifetime_rating特征features=[driver_stats_fv, driver_ratings_fv[["lifetime_rating"]]]
)特征服务在以下场景中使用:
-
-
-
-
- 训练数据生成时:当查询特征视图以查找历史特征值时。单个训练数据集可能包含来自多个特征视图的特征。通过使用特征服务,可以更容易地在训练数据生成过程中查找和组合这些特征。
- 批量评分时:从离线存储(例如,使用所有时间戳均为现在的实体dataframe)中检索特征。在这里,特征服务可以帮助检索所需的特征,以便对批量数据进行评分。
- 在线推理时:从在线存储中检索特征以进行在线推理(如较小批量大小)。从在线存储中检索的特征可能也属于多个特征视图。特征服务在此场景中帮助检索和组合这些特征,以便在在线推理过程中使用。
-
-
-
总之,特征服务在不同数据处理场景中发挥着重要作用,例如训练数据生成、批量评分和在线推理。它们可以帮助查询和检索来自多个特征视图的历史特征值,并在不同应用中使用这些特征。这使得特征管理和组合变得更加简单,有助于提高ML模型和相关应用的性能。
注意:应用特征服务并不会实际部署一个服务。这句话的意思是,使用特征服务并不会导致一个实际的service实例被部署到生产环境或其他地方。特征服务实际上是一种抽象的概念,它将多个相关特征组合在一起,以便在ML模型和应用程序中更方便地使用这些特征。
特征服务允许引用特征视图中的所有或部分特征。
使用特征服务从在线存储中检索相关特征:
from feast import FeatureStore
feature_store = FeatureStore('.')feature_service = feature_store.get_feature_service("driver_activity")
features = feature_store.get_online_features(features=feature_service, entity_rows=[entity_dict]
)使用特征服务从离线存储中检索相关特征:
from feast import FeatureStore
feature_store = FeatureStore('.') # Initialize the feature storefeature_service = feature_store.get_feature_service("driver_activity")
feature_store.get_historical_features(features=feature_service, entity_df=entity_df)特征引用(Feature References)
一种在Feast中标识特征值的方法。这种方式主要用于在实验阶段检索特征。当你想要启动实验或服务模型时,建议使用特征服务(Feature Services)。
特征引用在Feast 中具有唯一性,可以唯一地标识特征值。特征引用的字符串结构如:。
其中:
-
-
-
-
- feature_view:特征视图的名称,用于组织和管理相关特征。特征视图是将多个特征组合在一起的方式,以便在实验和模型中更方便地使用。
- feature:特征视图中的特定特征名称。通过组合特征视图和特征名称,可以唯一地标识所需特征的值。
-
-
-
在实验阶段,特征引用可以帮助你快速检索和组合特征,以便在模型训练和评估过程中使用。然而,在实际生产环境中,建议使用特征服务,因为它们提供了更好的版本控制、性能优化和部署管理。
特征引用(Feature references)用于从Feast中检索特征(features):
online_features = fs.get_online_features(features=['driver_locations:lon','drivers_activity:trips_today'],entity_rows=[# {join_key: entity_value}{'driver': 'driver_1001'}]
)一次请求即可从多个特征视图中检索特征,Feast 能够合并来自多个表的特征以构建训练数据集。然而,同时引用(或检索)多个项目的特征是不可能的。
在这句话中,提到了两个关键点:
1. 一次请求即可从多个特征视图中检索特征。这意味着,如果我们需要使用Feast数据库中的多个特征,我们不需要为每个特征发出单独的请求。相反,我们可以使用单一请求来获取这些特征。这有助于提高检索效率,尤其是在处理大量特征时。
2. Feast 能够合并来自多个表的特征以构建训练数据集。这意味着,在构建训练数据集时,我们可以将来自不同表的特征进行组合。这有助于扩大数据集的范围,提高模型的性能。
然而,这句话也指出了一个限制:同时引用(或检索)多个项目的特征是不可能的。这意味着,如果我们想要使用来自不同项目的特征,我们需要分别请求它们。
提示:如果你在使用特征视图(Feature views)时没有使用实体(entities),那么可以在实体行(entity_rows)参数中不添加额外的实体值,直接将特征添加到这里。
事件时间戳
事件时间戳是指在特征视图数据源中发生的事件的时间戳。事件时间戳描述了观察或生成特征的时间点。
在数据处理和分析过程中,事件时间戳有以下两个主要用途:
-
-
-
-
- 点对点连接(point-in-time joins):在将特征视图中的最新特征值与实体行进行连接时,使用事件时间戳确保从特征视图中获取的是最新的事件时间点的特征值。这样可以确保分析结果的准确性和有效性。
- 在线服务(online serving):事件时间戳用于确保在在线服务过程中,模型不会接收到过时的特征值。这样可以确保模型在处理实时数据时具有较高的准确性和有效性。
-
-
-
数据集
数据集(Dataset):数据集是由从Feast进行历史检索生成的若干行组成的集合,用于训练模型。数据集通过将一个或多个特征视图与实体dataframe连接而产生。因此,一个数据集可能包含来自多个特征视图的特征。
特征视图与数据集的区别:特征视图包含了数据的结构(schema)以及数据在哪里可以被找到的引用(通过其数据源)。特征视图主要用于查询数据源,而数据集是查询结果的实际数据表现。
数据集与数据源的区别:数据集是历史检索的输出,而数据源是输入。在创建数据集的过程中,可以使用一个或多个数据源。
概括:数据集是训练模型所需的实际数据,通过连接多个特征视图和entity dataframe生成。特征视图则包含了数据的结构和引用,用于指导数据集的生成。数据源是数据集的来源,为数据处理和分析提供原始数据。
检索历史特征(用于训练数据或批量评分)
通过Feast的get_historical_features接口,可以抽象地处理点对点连接(point-in-time join)的复杂性。
示例代码
生成训练数据
entity_df = pd.DataFrame.from_dict({"driver_id": [1001, 1002, 1003, 1004, 1001],"event_timestamp": [datetime(2021, 4, 12, 10, 59, 42),datetime(2021, 4, 12, 8, 12, 10),datetime(2021, 4, 12, 16, 40, 26),datetime(2021, 4, 12, 15, 1, 12),datetime.now()]}
)
training_df = store.get_historical_features(entity_df=entity_df, # 实体dataframefeatures=store.get_feature_service("model_v1"), # 特征服务
).to_df() # 将获取到的历史特征转换为dataframe
print(training_df.head())检索离线特征以进行批量评分
与训练数据生成相比,entity dataframe中时间戳的处理方式是不同的。为了获取所有实体的最新特征值,你需要传入当前时间。
from feast import FeatureStorestore = FeatureStore(repo_path=".")# 获取特定时间段内特定实体的最新特征值,查询结果将 driver_id 和 event_timestamp 作为列返回
entity_sql = f"""SELECTdriver_id,CURRENT_TIMESTAMP() as event_timestampFROM {store.get_data_source("driver_hourly_stats_source").get_table_query_string()}WHERE event_timestamp BETWEEN '2021-01-01' and '2021-12-31'GROUP BY driver_id
"""
batch_scoring_features = store.get_historical_features(entity_df=entity_sql,features=store.get_feature_service("model_v2"),
).to_df()
# predictions = model.predict(batch_scoring_features) # 使用模型进行预测问:event_timestamp都已经当作条件了,为什么还要使用CURRENT_TIMESTAMP()自己去生成event_timestamp。
答:使用CURRENT_TIMESTAMP()作为event_timestamp的原因是为了确保在查询结果中使用当前时间戳。它可以确保查询结果反映在查询执行时刻的最新数据。虽然WHERE子句中已经设置了event_timestamp的范围限制(在'2021-01-01'和 '2021-12-31'之间),但在实际执行过程中,数据库可能会以不同的时间间隔更新数据。因此,使用CURRENT_TIMESTAMP()可以确保查询结果反映了在查询执行时刻的最新数据。
步骤1:定义特征
在这个步骤中,你需要指定用于模型版本的特征服务(feature services)和特征引用(feature references)。
作用:帮助你组织和规划模型所需的特征。
1. 特征服务(Feature Services):特征服务是一个组织模型所需特征的逻辑容器。它将一组相关的特征组合在一起,以便在模型训练和部署过程中更容易管理和使用。特征服务可以帮助你组织和管理模型版本中的特征,使得团队在开发和部署模型时能够更高效地协作。
2. 特征引用(Feature References):特征引用是用于引用特征服务中特定特征的标识符。在定义特征引用时,你需要指定特征服务的名称以及要在其中查找的特征名称。特征引用可以用于构建查询,以便在数据管道中使用特定特征。
查询特征服务(推荐)
推荐使用查询特征服务的方式来获取所需的特征数据。这种方式有助于简化模型训练和部署过程中的数据处理任务。
training_df = store.get_historical_features(entity_df=entity_df,features=store.get_feature_service("model_v1"),
).to_df()查询特征引用列表
特征引用是用于引用特征服务中特定特征的标识符,通过查询这个列表,你可以一次性获取到多个特征数据。这种方式有助于提高数据处理和模型训练的效率。
training_df = store.get_historical_features(entity_df=entity_df,features=["driver_hourly_stats:conv_rate","driver_hourly_stats:acc_rate","driver_daily_features:daily_miles_driven"],
).to_df()步骤2:定义实体
实体是具有唯一标识的主键字段和时间戳的表格数据。在这个过程中,你可以使用两种方法来定义实体:
-
-
-
-
- 使用Pandas DataFrame作为entity dataframe:你可以将一个包含实体主键字段和时间戳的Pandas DataFrame作为entity dataframe提供给Feast。这种方式适用于已经整理好的实体数据,你可以将其直接导入平台进行后续处理。
- 使用SQL查询生成实体:如果你希望在平台上动态生成实体,可以使用SQL查询来获取所需的数据。这种方式适用于你需要根据某种条件从数据库中检索实体的情况。.
-
-
-
无论是哪种方法,你都需要指定完整的实体关键字段以及时间戳。在完成实体定义后,Feast会将这些实体与特征数据进行连接,以便在后续步骤中进行数据处理、模型训练和预测。
用于生成训练数据的entity dataframe
entity_df = pd.DataFrame.from_dict({"driver_id": [1001, 1002, 1003, 1004, 1001], # 实体主键"event_timestamp": [ # 时间戳datetime(2021, 4, 12, 10, 59, 42),datetime(2021, 4, 12, 8, 12, 10),datetime(2021, 4, 12, 16, 40, 26),datetime(2021, 4, 12, 15, 1, 12),datetime.now()]}
)
training_df = store.get_historical_features( # 获取历史数据,生成训练数据entity_df=entity_df, # entity dataframefeatures=["driver_hourly_stats:conv_rate", # 特征引用"driver_hourly_stats:acc_rate","driver_daily_features:daily_miles_driven"],
).to_df()用于生成训练数据的实体SQL查询
你可以传入一个SQL字符串来生成上述entity dataframe。这在从一个数据源中获取某个时间段内的所有实体时非常有用。
entity_sql = f"""SELECTdriver_id,event_timestampFROM {store.get_data_source("driver_hourly_stats_source").get_table_query_string()}WHERE event_timestamp BETWEEN '2021-01-01' and '2021-12-31'
"""
training_df = store.get_historical_features( # 获取历史数据,用于生成训练数据集entity_df=entity_sql,# SQL entity dataframefeatures=["driver_hourly_stats:conv_rate", # 特征引用"driver_hourly_stats:acc_rate","driver_daily_features:daily_miles_driven"],
).to_df()检索在线特征(用于模型推理)
在线特征是指实时更新的特征数据,这些数据用于模型推理和预测。
Feast会确保已注册特征的最新值可用。在检索时,你需要提供实体列表以及要检索的相关特征。与get_historical_features类似,建议使用特征服务作为组织模型版本中特征的方法。
注意:与get_historical_features不同,实体行(entity_rows)不需要时间戳,因为每个实体键只需求一个特征值。
获取在线特征以进行实时模型推理有两种方式:
-
-
-
- 通过SDK:可以使用Feast 提供的SDK(软件开发工具包)来检索在线特征。SDK 提供了方便的API,这种方法适用于集成Feast功能到你的应用程序中,以便实时获取和应用在线特征。
- 通过特征服务器:另一种检索在线特征的方法是通过Feast提供的特征服务器。特征服务器是一个独立的 service,负责管理和提供在线特征。你可以通过RESTful API(面向资源的架构)或其他协议访问特征服务器,从而获取在线特征。这种方法适用于在分布式环境中部署和访问在线特征,以及需要跨多个客户端和服务器实例共享特征数据的应用程序。
-
-
Python SDK
from feast import RepoConfig, FeatureStore
from feast.repo_config import RegistryConfig
# 配置项目、提供者和注册表
repo_config = RepoConfig(registry=RegistryConfig(path="gs://feast-test-gcs-bucket/registry.pb"),project="feast_demo_gcp",provider="gcp",
)
store = FeatureStore(config=repo_config)features = store.get_online_features(features=["driver_hourly_stats:conv_rate", # 特征引用"driver_hourly_stats:acc_rate","driver_daily_features:daily_miles_driven",],entity_rows=[ # 不需要时间戳的实体行entity_rows{"driver_id": 1001,}],
).to_dict()Feature Server
这种方法需要您部署一个特征服务器(请参阅 Python 特征服务器)。
online_request = {"features": ["driver_hourly_stats:conv_rate", # 特征引用],"entities": {"driver_id": [1001, 1002]}, # 没有时间戳的实体行entity rows
}
r = requests.post('http://localhost:6566/get-online-features', data=json.dumps(online_request))
print(json.dumps(r.json(), indent=4, sort_keys=True))连接时间点(Point-in-time joins)
在特定时间点将两个或多个数据表连接在一起,以便在同一时间点查询多个数据表的相关数据。
在Feast中,特征值被视为时间序列记录。以下是一个驾驶者特征视图的示例,其中包含两个特征列(trips_today行驶次数和earnings_today收入):
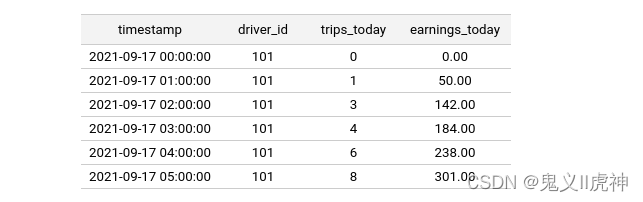
上述表格可以通过以下方式在Feast中注册特征视图:
from feast import Entity, FeatureView, Field, FileSource
from feast.types import Float32, Int64
from datetime import timedelta# 实体
driver = Entity(name="driver", join_keys=["driver_id"])# 特征视图
driver_stats_fv = FeatureView(name="driver_hourly_stats", # 视图名,唯一entities=[driver], # 实体列表 0或多个schema=[ # 特征视图结构,不指定自动扫描推测Field(name="trips_today", dtype=Int64),Field(name="earnings_today", dtype=Float32),],ttl=timedelta(hours=2),# 生存周期,2小时source=FileSource(path="driver_hourly_stats.parquet") # 数据源
)Feast能够以点时刻正确的方式将来自一个或多个特征视图的特征连接到entity dataframe中。这意味着Feast能够重现过去某个特定时刻特征的状态。
给定以下实体dataframe,假设用户希望将上述driver_hourly_stats特征视图连接到其中,同时保留trip_success列: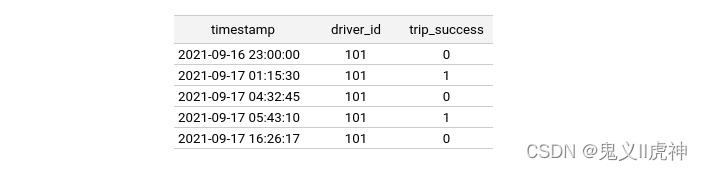
上述实体dataframe中的时间戳是我们希望重现时刻(即在特定时间点特征值的状况)的事件。为了进行点时刻连接(Point-in-time join),用户需要加载实体dataframe并运行历史检索。
# 读取entity dataframe
entity_df = pd.read_csv("entity_df.csv")training_df = store.get_historical_features(entity_df=entity_df,features = ['driver_hourly_stats:trips_today', # 特征引用'driver_hourly_stats:earnings_today'],
)对于实体dataframe的每行,Feast会将 适当特征视图数据源 中 选定的特征查询 连接到实体dataframe。从实体dataframe的时间戳开始,Feast会将查询结果回溯到距今不超过指定TTL(Time To Live,生存时间)的时间点。
总之,Feast通过对entity dataframe中的每行进行点时刻查询和连接,以及回溯时间限制,为用户提供了一个灵活且准确的数据分析工具。这有助于用户更好地了解和分析数据,从而做出更有价值的业务决策。
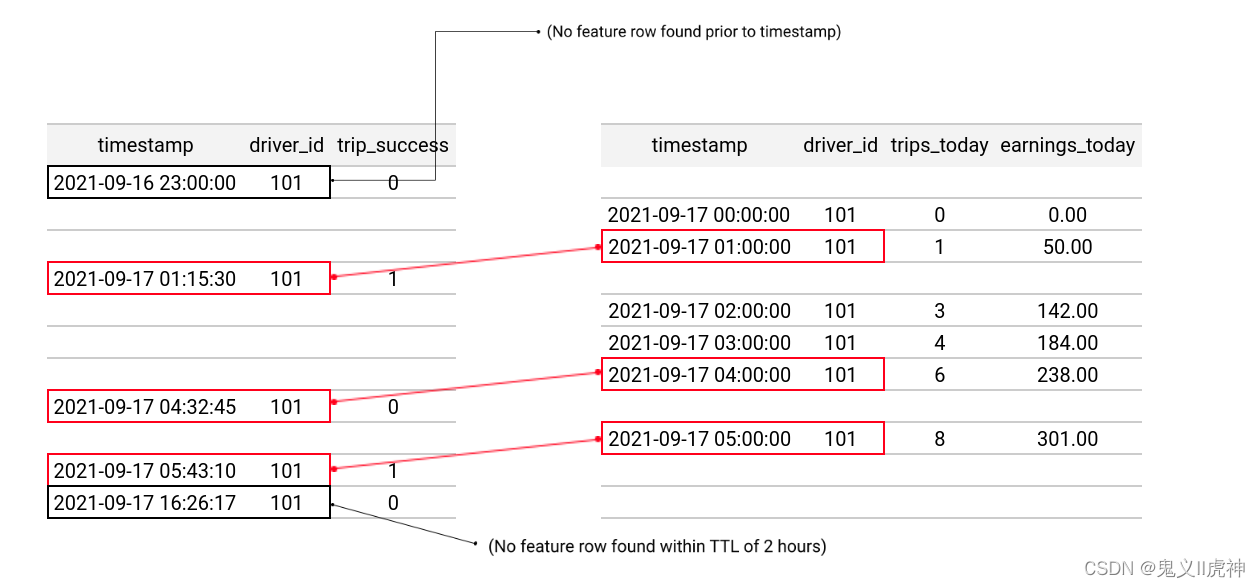
注意:TTL(生存时间)是与实体数据框中的每个时间戳相对的。TTL不是相对于查询时间的。当运行查询时,系统会根据entity dataframe中的每个时间戳来计算对应的TTL。
以下是对接后的训练数据框。它包含了原始实体行和连接到的特征值: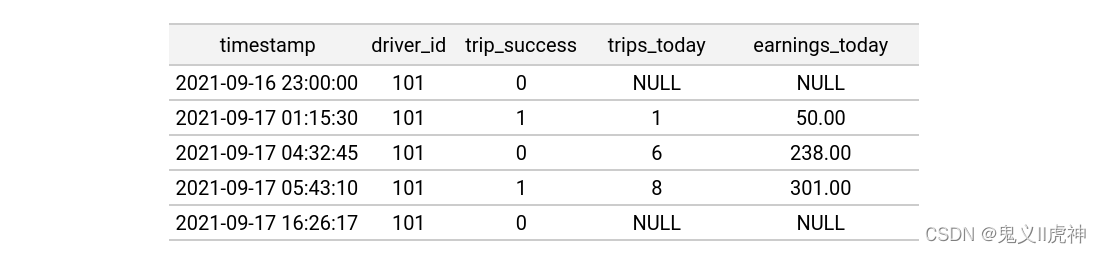
在将特征数据与实体数据框进行连接的过程中,有3个特征行的数据成功与实体dataframe中的相应行进行了匹配。
其中实体dataframe中的第一行(oldest row)由于其时间戳早于特征视图中的第一行时间戳,所以无法与特征数据进行连接。同样,实体数据框中的最后一行(the last row)由于其时间戳超过了TTL(生存时间)范围(事件发生在特征行后的11小时),也无法与特征数据进行连接。
注册表
Feast系统使用一个注册表来存储所有已经创建和应用的Feast对象,包括但不限于特征视图、实体等。
注册表提供了一组API,用于管理这些对象的生命周期:
-
-
- apply:应用于,即创建和配置Feast对象,如创建一个新的特征视图或实体。
- list:列出,即检索注册表中所有已应用的 Feast 对象。
- retrieve:检索,即根据对象标识符或其他条件查找并获取特定Feast对象。
- delete:删除,即从注册表中移除指定的 Feast 对象。
-
注册表作为一个抽象层,可以支持多种实现。这意味着在实际应用中,可以根据需求选择不同的注册表实现,以满足不同场景下的性能、可靠性等要求。这种设计使得Feast系统具有较高的灵活性和可扩展性,可以适应各种复杂环境。
注册表实现选项
基于文件的注册表
默认情况下,Feast使用基于文件的注册表实现,它将注册表的Protocol Buffers(简称protobuf)表示作为序列化文件存储。这个注册表文件可以存储在本地文件系统上,也可以存储在云端存储(如Amazon S3、Google Cloud Storage或Azure等)。
使用feast init的快速入门指南将使用本地文件系统的注册表。为了使Feast能够配置一个远程文件注册表,你需要创建一个Feast能够识别的Google Cloud Storage(GCS)/ Amazon S3(S3)存储桶:
本地文件注册表
project: feast_project
# By default, the registry is a file (but can be turned into a more scalable SQL-backed registry)
registry: data/registry.db
# The provider primarily specifies default offline / online stores & storing the registry in a given cloud
provider: local
online_store:type: sqlitepath: data/online_store.db
entity_key_serialization_version: 2S3文件注册表
project: feast_demo_aws
provider: aws
registry: path: s3://[YOUR BUCKET YOU CREATED]/registry.pbcache_ttl_seconds: 60
online_store: null
offline_store:type: fileGCS文件注册表
project: feast_demo_gcp
provider: gcp
registry:path: gs://[YOUR BUCKET YOU CREATED]/registry.pbcache_ttl_seconds: 60
online_store: null
offline_store:type: file基于文件的注册表在处理并发修改时存在一些固有的问题。当注册表中的一个字段发生更改时,整个注册表文件都需要重新写入。这种情况在多个并发写入者的情况下可能导致以下问题:
-
-
-
- 数据丢失:由于整个注册表文件需要重新写入,因此在并发写入期间可能会发生数据丢失。例如,两个并发操作修改注册表中的同一个字段时,其中一个操作可能会覆盖另一个操作的更改。
- 写入瓶颈:由于所有更改都需要序列化,因此在运行多个特征视图或时间范围的物化操作时,注册表的写入可能会受到瓶颈限制。这可能导致性能下降,尤其是在高并发场景下。
-
-
除了并发导致等问题,还有其它缺点:
-
-
-
- 可用性:当注册表文件较大时,可能会影响系统的可用性,尤其是在分布式环境中。
-
-
当然基于文件的注册表实现肯定有很多优点,要不也没人用,优点包括:
-
-
-
- 易于部署和迁移:由于注册表文件可以存储在本地或云端,因此可以在不同环境之间轻松部署和迁移。
- 灵活性:基于文件的注册表可以适应各种规模和复杂性的应用场景。
- 兼容性:与其他基于Protocol Buffers的数据结构和服务兼容,如Google Cloud Datastore、Bigtable等。
-
-
SQL注册表
SQL注册表是一种更具可扩展性的注册表实现方式,配置大致如下:
project: <your project name>
provider: <provider name>
online_store: redis
offline_store: file
registry:registry_type: sqlpath: postgresql://postgres:mysecretpassword@127.0.0.1:55001/feastcache_ttl_seconds: 60这种方式支持任何与SQLAlchemy兼容的数据库作为后端。
更新注册表
-
-
- 更新注册表:建议用户将 Feast特征定义存储在版本控制仓库中,并通过持续集成/持续部署(CI/CD)使其与注册表保持同步。这样可以确保特征定义的最新版本在注册表中得到体现。
- 多个注册表:用户通常需要为不同环境(如开发、staging 和生产环境)创建不同的注册表。这是因为每个环境中的数据和需求可能有所不同。在staging和生产环境中,注册表的写入权限应受到限制,以防止误操作影响真实用户的流量。
- 有关如何在生产环境中设置多个注册表的详细信息,请参阅《在生产环境中运行Feast》文档。
-
总之,这段话强调了在版本控制仓库中存储Feast特征定义,并通过CI/CD自动同步以确保注册表中的数据最新。此外,针对不同环境使用多个注册表,并限制staging和生产环境中注册表的写入权限,以确保系统稳定性和安全性。
从客户端访问注册表
用户可以通过feature_store.yaml配置文件或编程方式指定注册表。我们经常看到团队更喜欢编程方式,因为它使得Notebook驱动的开发变得非常简单:
通过编程方式指定注册表
repo_config = RepoConfig(registry=RegistryConfig(path="gs://feast-test-gcs-bucket/registry.pb"), # 指定注册表的路径,用的Google Cloud Storage(GCS)project="feast_demo_gcp", # 项目名称provider="gcp", offline_store="file", # 离线存储设置,这里是file表示使用文件系统存储离线数据。您可以使用其他离线存储配置,例如FileOfflineStoreConfig。online_store="null", # 在线存储设置,这里是null"表示不使用在线存储。您可以使用其他在线存储配置,例如 RedisOnlineStoreConfig。
)
store = FeatureStore(config=repo_config)实例化一个FeatureStore对象,并将其指向一个名为"."的仓库路径。
project: feast_demo_aws
provider: aws
registry: s3://feast-test-s3-bucket/registry.pb
online_store: null
offline_store:type: filerepo_path设置为".",表示FeatureStore对象的仓库位于当前目录。这意味着您需要在当前目录下创建一个名为 "feature_store.yaml"的文件。
在实际部署时,需要将repo_path更改为指向部署环境中相应的仓库路径。
保存的数据集(Saved dataset)
Feast数据集允许您方便地将包含特征和entity dataframe保存到系统中,以便后续进行数据分析和模型训练。这是创建数据集概念的主要动机。
数据集的元数据(如数据集名称、描述、创建时间等)存储在Feast注册表中。注册表是一个集中管理数据集信息的地方,方便您查看和管理您的数据。
数据集的元数据存储在Feast注册表中,而原始数据(特征、实体、附加输入键和时间戳)存储在离线存储中。
可以从哪些途径创建数据集:
-
-
- 历史检索结果:您可以从历史检索的结果中创建数据集。这些结果可能包括按时间顺序收集的各类数据,如特征、实体等。
- [计划中] 特征服务期间的日志记录:您可以计划在特征服务期间记录日志请求(包括按需转换的输入)和响应。这有助于您了解特征服务的执行情况,以便在需要时进行调试和优化。
- [计划中] 向在线存储写入数据时的特征日志:当您将数据(从批量源或流式源)写入在线存储时,可以记录相关的特征信息。这有助于您跟踪数据的流入和转换过程,以确保数据的正确性和完整性。
-
总之,通过以上途径创建数据集,您可以收集和整合各种来源的数据,以便在后续进行数据分析和模型训练。这些数据集将为您提供有关业务场景的丰富信息,帮助您更好地了解和优化业务流程。.
从历史检索结果中创建一个保存的数据集
如何从历史特征创建一个保存的数据集,以便后续检索或分析。用户需要首先调用get_historical_features方法,然后将返回的检索任务传递给create_saved_dataset方法。
-
-
- get_historical_features:此方法用于获取历史特征数据。调用此方法后,系统将返回一个检索任务,其中包含您所需的历史数据。
- create_saved_dataset:此方法接收检索任务作为参数,并触发该检索任务(通过调用.persist()方法)将数据存储在指定的存储系统中。存储类型必须与全局配置的离线存储类型相同(例如,不可能将数据持久化到不同的离线源)。
- 创建SavedDataset对象:create_saved_dataset方法还会创建一个包含相关元数据的SavedDataset 对象,并将该对象写入注册表。这样,您可以在需要时检索和分析这些数据。
-
总之,要创建一个从历史特征中获取的保存的数据集,您需要先获取历史数据,然后将数据存储在指定的离线存储中。此外,您还需要创建一个包含相关元数据的SavedDataset对象,并将其存储在注册表中。这样,您就可以在需要时检索和分析这些数据。
from feast import FeatureStore
from feast.infra.offline_stores.bigquery_source import SavedDatasetBigQueryStoragestore = FeatureStore()# 获取历史特征数据
historical_job = store.get_historical_features(features=["driver:avg_trip"],entity_df=...,
)# 将数据存储在指定的离线存储中
dataset = store.create_saved_dataset(from_=historical_job,name='my_training_dataset',storage=SavedDatasetBigQueryStorage(table_ref='<gcp-project>.<gcp-dataset>.my_training_dataset'),tags={'author': 'oleksii'}
)dataset.to_df()保存的数据集可以使用特征平台中的get_saved_dataset方法在后续进行检索:
dataset = store.get_saved_dataset('my_training_dataset')
dataset.to_df()