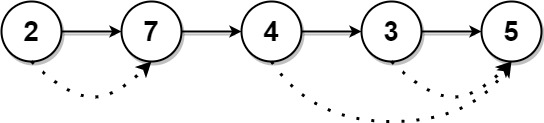
类似 多线程竞争,需要加锁来保护类似,但实现原理不同,reduction 并不会像多线程原子操作那样影响效率,因为它使用了高等代数里的单位元和结合律思想,为每个线程定义一个单位元,开始 分段积累运算操作。
1, 不可避免竞争的示例
hello_without_reduction.cpp
#include <omp.h>
#include <math.h>
#include <iostream>int main()
{float sum = 0;omp_set_num_threads(4);#pragma omp parallel{#pragma omp forfor(int i=0; i<17; i++){sum += cos(i) + sin(i);//printf("%d , th=%d\n", i, omp_get_thread_num());}}std::cout<< sum <<std::endl;}_______
Makefile:
CXX:=g++hello_nr: hello_without_reduction.o${CXX} -o $@ $< -fopenmp#${CXX} -o $@ -fopenmp $<hello_without_reduction.o: hello_without_reduction.cpp${CXX} -c -o $@ $< -fopenmp.PHONY:clean
clean:-rm -f hello_without_reduction hello_without_reduction.o出错效果:

2,避免了竞争的示例
hello_with_reduction.cpp
#include <omp.h>
#include <math.h>
#include <iostream>int main()
{float sum = 0;omp_set_num_threads(4);#pragma omp parallel{#pragma omp for reduction(+:sum)for(int i=0; i<17; i++){sum += cos(i) + sin(i);//printf("%d , th=%d\n", i, omp_get_thread_num());}}std::cout<< sum <<std::endl;}_______________________________________________________________
Makefile:
CXX:=g++hello_nr: hello_with_reduction.o${CXX} -o $@ $< -fopenmp#${CXX} -o $@ -fopenmp $<hello_with_reduction.o: hello_with_reduction.cpp${CXX} -c -o $@ $< -fopenmp.PHONY:clean
clean:-rm -f hello_with_reduction hello_with_reduction.o无错效果图: