共享变量是什么
Spark中的两个重要抽象一个是RDD,另一个就是共享变量。
在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。
但是,有时候,需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark提供了两种类型的变量:广播变量(broadcast variables)和累加器(accumulators):
广播变量(broadcast variable)用来把变量在所有节点的内存之间进行共享。
累加器(accumulator)则支持在所有不同节点之间进行累加计算(比如计数或者求和)。
总之:
累加器:用来对信息进行聚合,主要用于累计计数等场景;
广播变量:主要用于在节点间高效分发大对象,在内存的所有节点中被访问,用于缓存变量;
广播变量
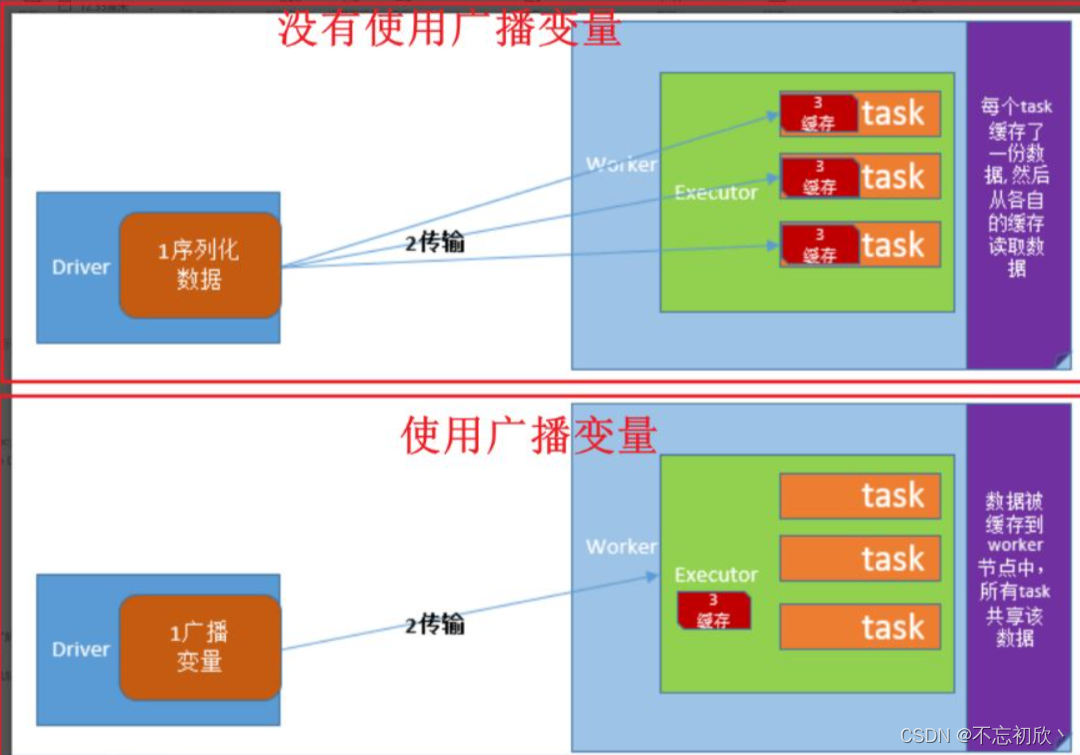
广播变量(broadcast variables)允许程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。通过这种方式,就可以非常高效地给每个节点(机器)提供一个大的输入数据集的副本。Spark的“动作”操作会跨越多个阶段(stage),对于每个阶段内的所有任务所需要的公共数据,Spark都会自动进行广播。通过广播方式进行传播的变量,会经过序列化,然后在被任务使用时再进行反序列化。这就意味着,显式地创建广播变量只有在下面的情形中是有用的:当跨越多个阶段的那些任务需要相同的数据,或者当以反序列化方式对数据进行缓存是非常重要的。
可以通过调用SparkContext.broadcast(v)来从一个普通变量v中创建一个广播变量。这个广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获得这个广播变量的值,
图解:
编码方式
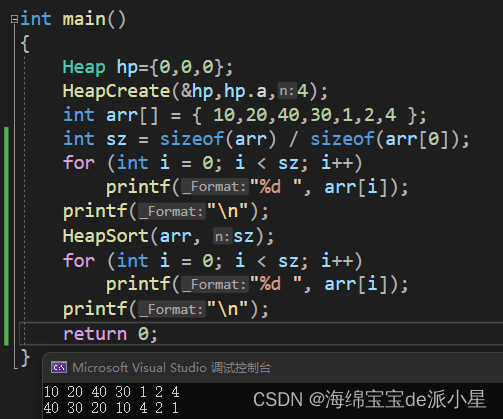
//本地创建Array
scala> val bc = sc.broadcast(Array(12,123,1234,234))
bc: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
//从bc对象中取出Array对象即可
scala> bc.value
res0: Array[Int] = Array(12, 123, 1234, 234)
这个广播变量bc被创建以后,在集群中的任何函数中,都应该使用广播变量bc的值,而不是使用v的值,这样就不会把v重复分发到这些节点上。此外,一旦广播变量创建后,普通变量v的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
累加器
累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器(counter)和求和(sum)。Spark原生地支持数值型(numeric)的累加器,可以编写对新类型的支持。如果创建累加器时指定了名字,则可以在Spark UI界面看到,这有利于理解每个执行阶段的进程。
一个数值型的累加器,可以通过调用SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建。运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是,这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
代码实例
下面是一个代码实例,演示了使用累加器来对一个数组中的元素进行求和:
//在Driver端定义累加器,赋初始值
scala> val amulator = sc.longAccumulator("My Accumulator")
amulator: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
//在Executor端读取数组进行想加
scala> sc.parallelize(Array(12,23,45,67)).foreach(elem => amulator.add(elem))
//在Driver获取累加器的结果
scala> amulator.value
res3: Long = 147
注意点:
使用累加器的时候,要注意,因为rdd是过程数据,如果rdd被多次使用可能会重新构建此rdd,如果累加器累加代码,存在重新构建的步骤中,累加器累加代码可能被多次执行。可以采取加缓存或Checkpoint即可
参考博客:
1、厦门大学林子雨
2、PySpark 共享变量之 广播变量和累加器_pyspark 广播变量_不忘初欣丶的博客-CSDN博客