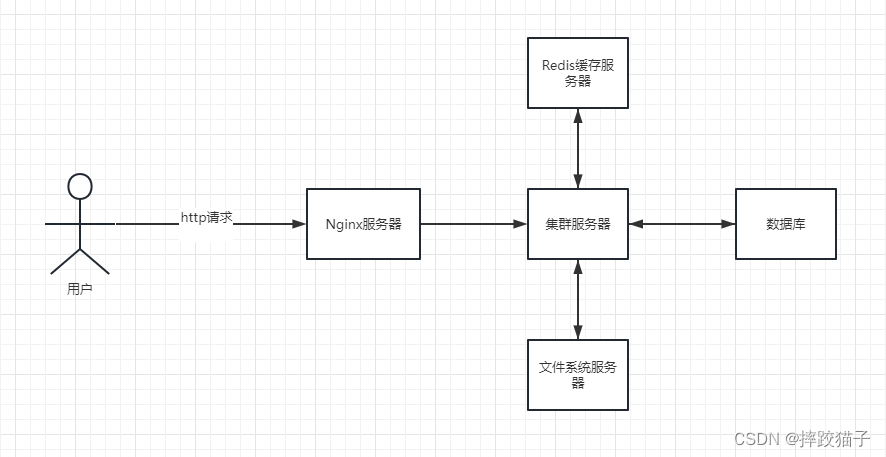
一个系统被拆分成N多个模块,这些模块负责不同的功能,组合成一套系统,最终可以提供丰富的功能。在这种分布式架构中,一次请求往往需要涉及到多个服务,如下图:
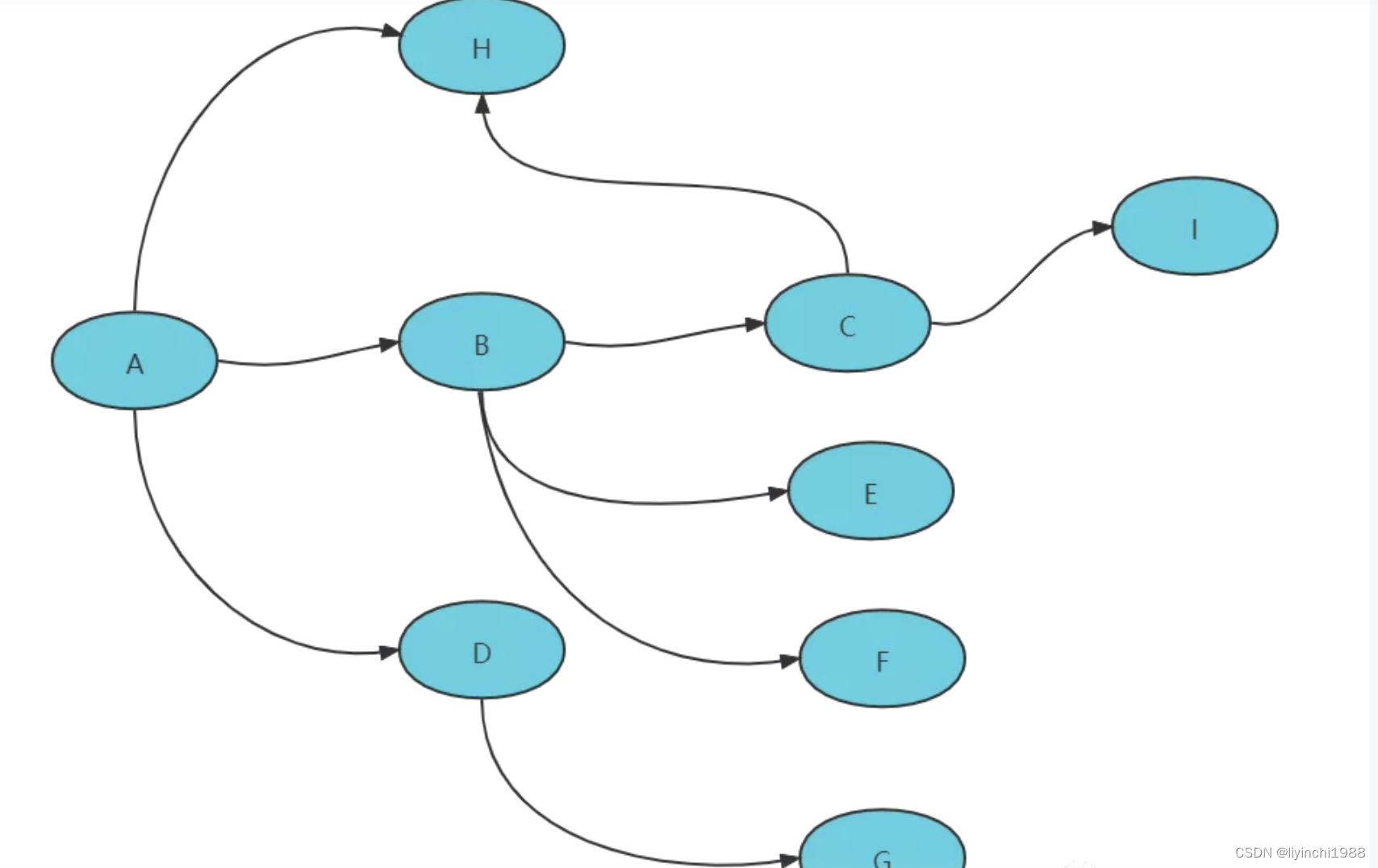
服务之间的调用错综复杂,对于维护的成本成倍增加,势必存在以下几个问题:
服务之间的依赖与被依赖的关系如何能够清晰的看到?
出现异常时如何能够快速定位到异常服务?
出现性能瓶颈时如何能够迅速定位哪个服务影响的?
为了能够在分布式架构中快速定位问题,分布式链路追踪应运而生。将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
在典型的微服务体系结构中,我们有许多单独部署的小型应用程序,它们经常需要相互通信。开发人员面临的挑战之一是要跟踪日志的完整请求,以调试或检查下游服务中的延迟。
一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求流经的哪个服务出了故障或者处理过慢都会对前端造成影响。
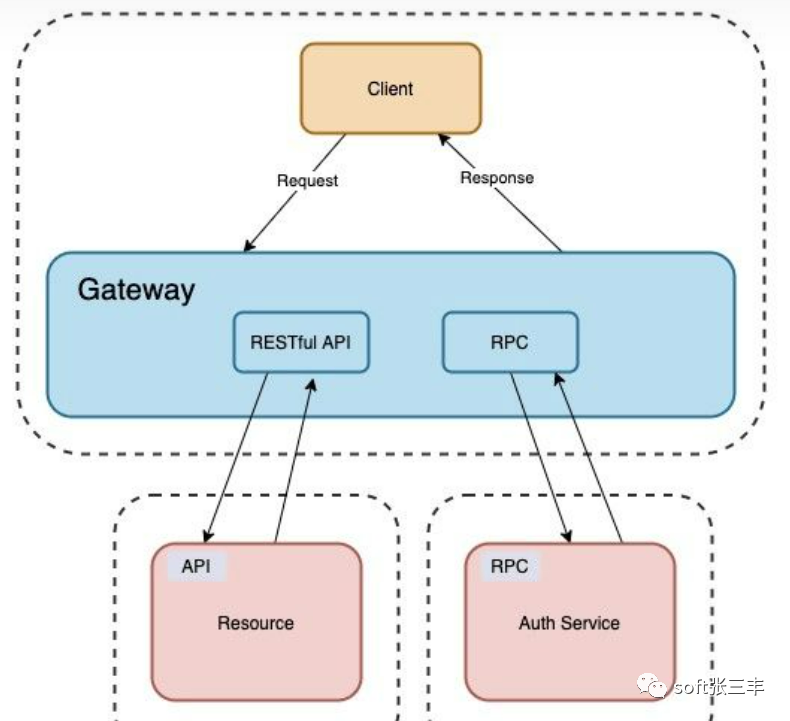
为了进一步增加复杂性,某些服务可以运行多个实例。很难在多个服务中跟踪特定的请求日志,尤其是在特定服务具有多个实例的情况下。
核心思想:将trace_id设置到请求头中透传给下游服务,下游服务按同样的方式再透传给下游服务。
步骤:
当请求达到网关时,网关中的拦截器会从请求头中获取trace_id,如果为空,则生成一个trace_id,并设置到SLF4J的MDC中,在网关转发请求时将trace_id设置到请求头中。
当请求达到服务A时,应用中的拦截器会从请求头中获取trace_id,如果为空,则生成一个trace_id,并设置到SLF4J的MDC中,如果服务A调用服务B/服务C,那么需要将trace_id设置到请求头中。
其他服务(服务B/服务C)的处理方式与步骤2的处理方式一致。将trace_id设置到MDC中的目的是为了SLF4J在打印日志时将trace_id打印出来。
常见的链路追踪技术有哪些?
市面上有很多链路追踪的项目,其中也不乏一些优秀的,如下:
cat:由大众点评开源,基于Java开发的实时应用监控平台,包括实时应用监控,业务监控 。 集成方案是通过代码埋点的方式来实现监控,比如: 拦截器,过滤器等。 对代码的侵入性很大,集成成本较高,风险较大。
zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。该产品结合spring-cloud-sleuth使用较为简单, 集成很方便, 但是功能较简单。
pinpoint:韩国人开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能强大,接入端无代码侵入
skywalking:SkyWalking是本土开源的基于字节码注入的调用链分析,以及应用监控分析工具。特点是支持多种插件,UI功能较强,接入端无代码侵入。目前已加入Apache孵化器。
Sleuth:SpringCloud 提供的分布式系统中链路追踪解决方案。很可惜的是阿里系并没有链路追踪相关的开源项目,我们可以采用Spring Cloud Sleuth+Zipkin来做链路追踪的解决方案。
Spring Cloud Sleuth会自动向您的日志和服务间通信中添加一些跟踪/元数据(通过请求标头),因此可以通过Zipkins,ELK等日志聚合器轻松跟踪请求。

Spring Cloud Sleuth
学习Sleuth之前必须了解它的几个概念:
Span:基本的工作单元,相当于链表中的一个节点,通过一个唯一ID标记它的开始、具体过程和结束。我们可以通过其中存储的开始和结束的时间戳来统计服务调用的耗时。除此之外还可以获取事件的名称、请求信息等。
Trace:一系列的Span串联形成的一个树状结构,当请求到达系统的入口时就会创建一个唯一ID(traceId),唯一标识一条链路。这个traceId始终在服务之间传递,直到请求的返回,那么就可以使用这个traceId将整个请求串联起来,形成一条完整的链路。
Annotation:一些核心注解用来标注微服务调用之间的事件,重要的几个注解如下:
cs(Client Send):客户端发出请求,开始一个请求的生命周期
sr(Server Received):服务端接受请求并处理;sr-cs = 网络延迟 = 服务调用的时间
ss(Server Send):服务端处理完毕准备发送到客户端;ss - sr = 服务器上的请求处理时间
cr(Client Reveived):客户端接受到服务端的响应,请求结束; cr - sr = 请求的总时间
Spring Cloud Sleuth在您的日志中添加了唯一的ID,这些ID在许多微服务之间保持不变,并且可由普通的日志聚合器用来查看请求的流向。
要添加此功能,我们需要在pom.xml每个下游服务的文件中添加一个依赖项:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
Spring Cloud Sleuth将两种类型的ID添加到您的日志记录中:
- 跟踪ID:唯一的ID,在包含多个微服务的整个请求中保持不变。
- Span ID:每个微服务的唯一ID。
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和traceid一起传递给下游服务。
基本上,跟踪ID将包含多个Span ID,日志聚合工具可以轻松使用它们。
Sleuth不仅将这些ID添加到我们的日志中,还将它们传播到下一个服务调用(基于HTTP或MQ)。而且,它可以将随机样本日志发送到开箱即用的Zipkins等外部应用程序。
traceid 在请求的整个调用链中始终保持不变,所以在日志中可以通过 traceid 查询到整个请求期间系统记录下来的所有日志。
请求到达每个服务后,服务都会为请求生成spanid,而随请求一起从上游传过来的上游服务的 spanid 会被记录成parent-spanid或者叫 pspanid。当前服务生成的 spanid 随着请求一起再传到下游服务时,这个spanid 又会被下游服务当做 pspanid 记录。
之后,我们需要在application.properties每个服务的文件中添加以下属性:
spring.sleuth.sampler.probability=100
spring.zipkin.baseUrl= http://localhost:9411/
通过在访问日志和业务日志里记录的traceid、spanid 和 pspanid 能完整的还原出整个请求的调用链路视图,对错误排查能起到很大的帮助。
该spring.zipkin.baseUrl属性告诉Spring和Sleuth将数据推送到何处。另外,默认情况下,Spring Cloud Sleuth会将所有范围设置为nonexportable。这意味着这些跟踪(跟踪ID和跨度ID)会显示在日志中,但不会导出到其他远程存储(如Zipkin)。
想要跟踪请求,第一个想到的就是当请求来时生成一个traceId放在ThreadLocal里,然后打印时去取就行了。但在不改动原有输出语句的前提下自然需要日志框架的支持了,搜索的一番发现主流日志框架都提供了MDC功能。
MDC
MDC 介绍 MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。MDC 可以看成是一个与当前线程绑定的Map,可以往其中添加键值对。MDC 中包含的内容可以被同一线程中执行的代码所访问。当前线程的子线程会继承其父线程中的 MDC 的内容。当需要记录日志时,只需要从 MDC 中获取所需的信息即可。MDC 的内容则由程序在适当的时候保存进去。对于一个 Web 应用来说,通常是在请求被处理的最开始保存这些数据。
简而言之,MDC就是日志框架提供的一个InheritableThreadLocal,项目代码中可以将键值对放入其中,然后使用指定方式取出打印即可。
首先创建拦截器,加入拦截列表中,在请求到达时生成traceId。当然你还可以根据需求在此处后或后续流程中放入spanId、订单流水号等需要打印的信息。
public class Constants {/*** 日志跟踪id名。*/public static final String LOG_TRACE_ID = "traceid";/*** 请求头跟踪id名。*/public static final String HTTP_HEADER_TRACE_ID = "app_trace_id";
}
import org.slf4j.MDC;public class TraceInterceptor extends HandlerInterceptorAdapter {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {// "traceId"MDC.put(Constants.LOG_TRACE_ID, TraceLogUtils.getTraceId());return true;}
}
然后在日志配置xml文件中添加traceId打印:
<property name="normal-pattern" value="[%p][%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ,Asia/Shanghai}][%X{traceid}][%15.15t][%c:%L] %msg%n"/>
1.仅仅这样的改造在实际使用过程中会遇到以下问题:
线程池中的线程会打印错误的traceId
调用下游服务后会生成新的traceId,无法继续跟踪
MDC使用的InheritableThreadLocal只是在线程被创建时继承,但是线程池中的线程是复用的,后续请求使用已有的线程将打印出之前请求的traceId。这时候就需要对线程池进行一定的包装,在线程在执行时读取之前保存的MDC内容。
ThreadPoolExecutor的包装也类似,注意为了严谨考虑,需要对连接池中的所有调用方法进行封装。
提供一下我的工具类:
public class ThreadMdcUtil {public static void setTraceIdIfAbsent() {if (MDC.get(Constants.LOG_TRACE_ID) == null) {MDC.put(Constants.LOG_TRACE_ID, TraceLogUtils.getTraceId());}}public static void setTraceId() {MDC.put(Constants.LOG_TRACE_ID, TraceLogUtils.getTraceId());}public static void setTraceId(String traceId) {MDC.put(Constants.LOG_TRACE_ID, traceId);}public static <T> Callable<T> wrap(final Callable<T> callable, final Map<String, String> context) {return () -> {if (context == null) {MDC.clear();} else {MDC.setContextMap(context);}setTraceIdIfAbsent();try {return callable.call();} finally {MDC.clear();}};}public static Runnable wrap(final Runnable runnable, final Map<String, String> context) {return () -> {if (context == null) {MDC.clear();} else {MDC.setContextMap(context);}setTraceIdIfAbsent();try {runnable.run();} finally {MDC.clear();}};}public static class ThreadPoolTaskExecutorMdcWrapper extends ThreadPoolTaskExecutor {@Overridepublic void execute(Runnable task) {super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic void execute(Runnable task, long startTimeout) {super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()), startTimeout);}@Overridepublic <T> Future<T> submit(Callable<T> task) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic Future<?> submit(Runnable task) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic ListenableFuture<?> submitListenable(Runnable task) {return super.submitListenable(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic <T> ListenableFuture<T> submitListenable(Callable<T> task) {return super.submitListenable(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}}public static class ThreadPoolExecutorMdcWrapper extends ThreadPoolExecutor {public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);}public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);}public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);}public ThreadPoolExecutorMdcWrapper(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,RejectedExecutionHandler handler) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);}@Overridepublic void execute(Runnable task) {super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic <T> Future<T> submit(Runnable task, T result) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()), result);}@Overridepublic <T> Future<T> submit(Callable<T> task) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic Future<?> submit(Runnable task) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}}public static class ForkJoinPoolMdcWrapper extends ForkJoinPool {public ForkJoinPoolMdcWrapper() {super();}public ForkJoinPoolMdcWrapper(int parallelism) {super(parallelism);}public ForkJoinPoolMdcWrapper(int parallelism, ForkJoinWorkerThreadFactory factory,Thread.UncaughtExceptionHandler handler, boolean asyncMode) {super(parallelism, factory, handler, asyncMode);}@Overridepublic void execute(Runnable task) {super.execute(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}@Overridepublic <T> ForkJoinTask<T> submit(Runnable task, T result) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()), result);}@Overridepublic <T> ForkJoinTask<T> submit(Callable<T> task) {return super.submit(ThreadMdcUtil.wrap(task, MDC.getCopyOfContextMap()));}}
}
以上方式在多级服务调用中每个服务都会生成新的traceId,导致无法衔接跟踪。这时就需要对http调用工具进行相应的改造了,在发送http请求时自动将traceId添加到header中,以RestTemplate为例,注册拦截器:
// 以下省略其他相关配置
RestTemplate restTemplate = new RestTemplate();
// 使用拦截器包装http header
restTemplate.setInterceptors(new ArrayList<ClientHttpRequestInterceptor>() {{add((request, body, execution) -> {String traceId = MDC.get(Constants.LOG_TRACE_ID);if (StringUtils.isNotEmpty(traceId)) {request.getHeaders().add(Constants.HTTP_HEADER_TRACE_ID, traceId);}return execution.execute(request, body);});}
});HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory();
// 注意此处需开启缓存,否则会报getBodyInternal方法“getBody not supported”错误
factory.setBufferRequestBody(true);
restTemplate.setRequestFactory(factory);
下游服务的拦截器改为:
public class TraceInterceptor extends HandlerInterceptorAdapter {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {String traceId = request.getHeader(Constants.HTTP_HEADER_TRACE_ID);if (StringUtils.isEmpty(traceId)) {traceId = TraceLogUtils.getTraceId();}MDC.put(Constants.LOG_TRACE_ID, traceId);return true;}
}
若使用自定义的http客户端,则直接修改其工具类即可。






![使用亚马逊(AWS)云服务在S3上实现图片缩放功能(CloudFront/S3[AccessPoint/LambdaAccessPoint])](https://img-blog.csdnimg.cn/04a5e453d8db44eda6d526c9a452be2a.png)

