文章目录
- 一、集群规划
- 二、安装前准备(所有节点操作)
- 创建数据目录
- 修改系统配置文件/etc/sysctl.conf
- 创建用户组
- 设置limits.conf
- 三、初始化配置(在节点1上操作)
- 下载安装包
- 解压安装包
- 修改jvm.options文件下配置的所占内存
- 修改集群配置文件elasticsearch.yml
- 将安装包传到另外两个节点
- 在另外两个节点上修改elasticsearch.yml
- 四、配置开机自启动(所有节点操作)
- 五、启动集群(在所有节点依次操作)
- 六、查看集群状态
一、集群规划
| IP | 角色 |
|---|---|
| 192.168.1.10 | node-1 |
| 192.168.1.20 | node-2 |
| 192.168.1.30 | node-3 |
二、安装前准备(所有节点操作)
创建数据目录
mkdir /data
修改系统配置文件/etc/sysctl.conf
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
sysctl -p #重新加载
创建用户组
groupadd elastics
useradd -r -g elastics elastics
mkdir /home/elastics
chown -R elastics:elastics /home/elastics
设置limits.conf
vi /etc/security/limits.conf
在最后增加:
elastics soft nofile 655360 #solf是软限制的意思,hard是硬限制;软限制可以在程序的进程中自行改变(突破限制),而硬限制则不行(除非程序进程有root权限)
elastics hard nofile 655360 #nofile 文件描述符
elastics soft nproc 655360 #nproc 进程的限制
elastics hard nproc 655360
elastics soft memlock unlimited
elastics hard memlock unlimited
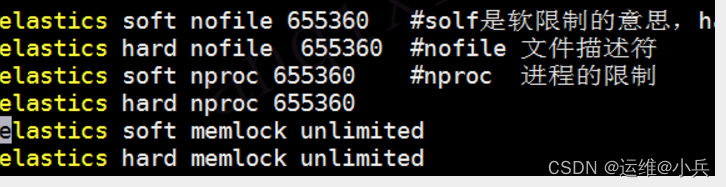
注意:该配置需要重新登录方可生效
三、初始化配置(在节点1上操作)
下载安装包
官网下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.4-linux-x86_64.tar.gz
解压安装包
tar xvf elasticsearch-7.13.4-linux-x86_64.tar.gz -C /data/
cd /data/
mv elasticsearch-7.13.4 elasticsearch
mkdir -p /data/elasticsearch/{data,logs}
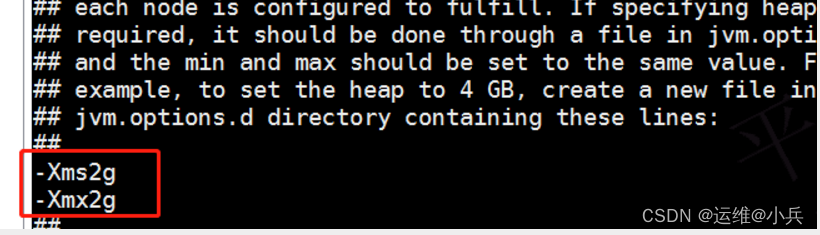
修改jvm.options文件下配置的所占内存
vi /data/elasticsearch/config/jvm.options
修改为:(按照实际情况来定,一般为内存的一半)
-Xms2g
-Xmx2g
修改集群配置文件elasticsearch.yml
vi /data/elasticsearch/config/elasticsearch.yml
增加如下配置
#集群名称
cluster.name: my-application
#节点名称,三台不能一样
node.name: node-1
#是否有资格竞选主节点
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
#节点发现,填写对应节点虚机地址,单机部署只有一个
discovery.seed_hosts: ["192.168.1.10","192.168.1.10","192.168.1.10"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
gateway.expected_nodes: 2
search.max_buckets: 90000000
indices.query.bool.max_clause_count: 10240
#cluster.routing.allocation.same_shard.hos: true
bootstrap.memory_lock: true
http.cors.enabled: true
http.cors.allow-origin: "*"
将安装包传到另外两个节点
rsync -avzP /data/elasticsearch 192.168.1.20:/data/
rsync -avzP /data/elasticsearch 192.168.1.30:/data/
在另外两个节点上修改elasticsearch.yml
只需将node.name的值分别修改为node-2和node-3即可
四、配置开机自启动(所有节点操作)
vi /etc/init.d/elasticsearch
修改文件内容为:(需在非root用户执行,若为root用户,则切换为别的用户)
#!/bin/sh
#chkconfig: - 85 15
#description: elasticsearch
export ES_HOME=/data/elasticsearch
case "$1" in
start)cd $ES_HOME./bin/elasticsearch -d -p pidecho "elasticsearch startup";;
stop)kill -9 `cat $ES_HOME/pid`echo "elasticsearch stopped";;
restart)kill -9 `cat $ES_HOME/pid`echo "elasticsearch stopped"cd $ES_HOME./bin/elasticsearch -d -p pidecho "elasticsearch startup";;
*)echo "start|stop|restart";;
esac
exit $?
设置开机自启
chmod 777 /etc/init.d/elasticsearch
chkconfig --add elasticsearch
chkconfig elasticsearch on
五、启动集群(在所有节点依次操作)
chown -R elastics:elastics /data/elasticsearch
su - elastics
service elasticsearch start
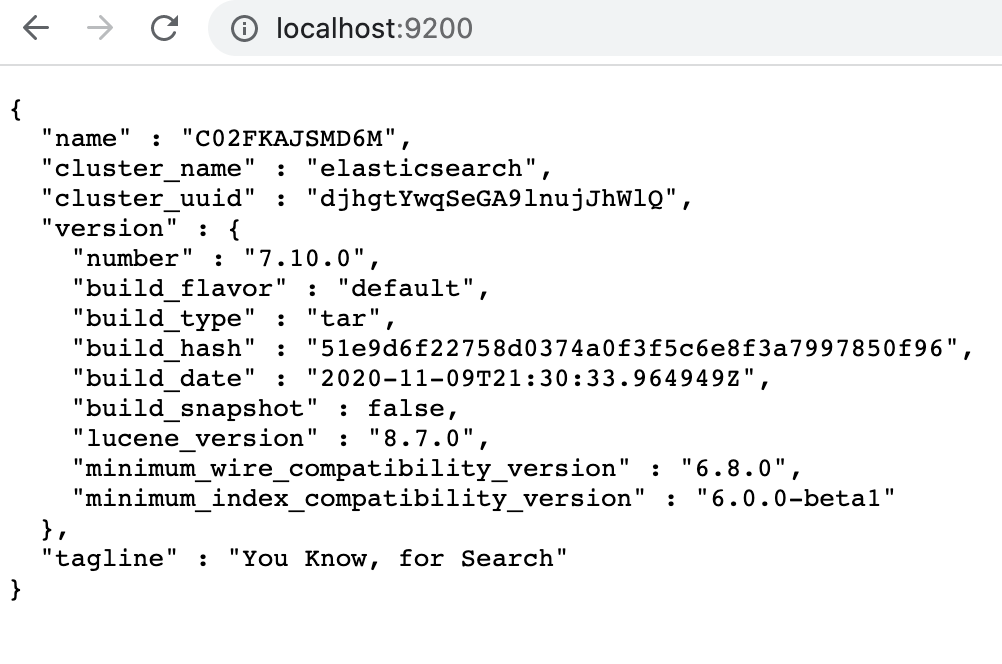
六、查看集群状态
http://192.168.1.10:9200/_cat/nodes?v

http://192.168.1.10:9200/_cat/health?v