🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1数据探索
4.2数据预处理
4.3标记文本
4.4创建N-gram序列
4.5填充序列
4.6词嵌入
4.7模型设计
4.8回调
4.8编译并训练模型
4.9文本生成
4.9.1贪婪搜索文本生成
4.9.2束搜索文本生成
4.9.3随机抽样文本生成
4.9.4带温度的随机采样文本生成
4.9.5Top-k采样文本生成
4.9.6核(Top-p)文本生成采样
5.总结
文末推荐与福利
1.项目背景
英文文本生成是自然语言处理领域中的一个重要问题,其目标是通过计算机模型生成与人类书写风格相似的连贯文本。这一问题的研究具有广泛的应用,包括机器翻译、智能对话系统、自动摘要、文本创作等领域。随着深度学习技术的不断发展,基于神经网络的文本生成模型取得了显著的进展。
在文本生成任务中,长短时记忆网络(LSTM)是一种特别适用的神经网络结构。LSTM能够捕捉文本中的长距离依赖关系,有助于生成更加连贯和语义丰富的文本。然而,单独使用LSTM模型可能会面临词汇多样性不足、生成文本过于平滑等问题。
为了解决这些问题,研究者们常常结合传统的N-gram模型与LSTM等深度学习模型,以期在生成文本的同时兼顾语法规律和语义关联。N-gram模型能够考虑局部的词汇顺序信息,对于捕捉短期依赖关系和提高词汇多样性有一定的帮助。将N-gram与LSTM相结合,可以在长距离依赖关系和短期依赖关系之间找到平衡,提高文本生成的质量。
此外,通过深入研究N-gram和LSTM在文本生成任务中的协同作用,我们可以更好地理解它们之间的关系,为设计更高效、更精准的文本生成模型提供理论指导。因此,本实验旨在探索基于LSTM和N-gram序列的英文文本生成方法,提高生成文本的流畅性、多样性和语义准确性,为自然语言处理领域的相关研究和应用提供有益的参考。
2.数据集介绍
此数据集提供有关莎士比亚戏剧的结构化信息,包括有关行为、场景和人物对话的详细信息。数据集中的每一行都对应于剧中角色所说的特定台词。原始数据共有111396条,6个变量,各变量含义如下:
Dataline:数据集中每一行的唯一标识符。
Play:剧名。
PlayerLinenumber:在某些情况下,它表示与玩家讲话相关的行号,有助于维持对话的顺序。
ActSceneLine:这一栏结合了动作、场景和台词信息,提供了剧中每条台词的位置的结构化参考。
Player:传递台词的角色,例如本数据集中的“亨利四世”。
PlayerLine:角色所说的实际对话或台词,提供他们的演讲文本。
此数据集可用于各种目的,例如文本分析、角色研究或戏剧“亨利四世”的场景提取。对戏剧内容和结构感兴趣的研究人员和爱好者可以利用这些数据来深入了解戏剧的对话、角色和整体流程。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1数据探索
首先需要导入本次实验用到的第三方库并加载数据集,
import re
import csv
import string
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloudimport tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import regularizers
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
import tensorflow.keras.utils df = pd.read_csv('Shakespeare_data.csv')
df.head()

print("Number of PlayerLines:", len(df['PlayerLine']))
print("First Few PlayerLines:")
print(df['PlayerLine'].head())
print("\nText Length Statistics:")
print(df['PlayerLine'].apply(len).describe())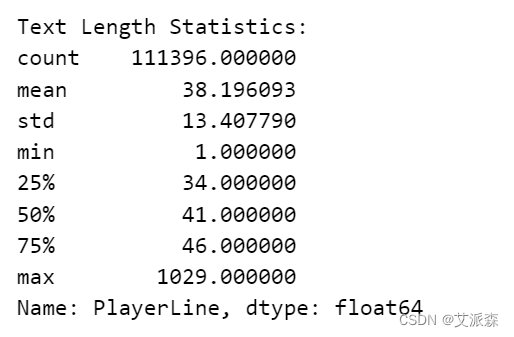
plt.figure(figsize=(10, 6))
plt.hist(df['PlayerLine'].apply(len), bins=10, color='skyblue')
plt.title('PlayerLine Text Length Distribution')
plt.xlabel('Text Length')
plt.ylabel('Frequency')plt.tight_layout()
plt.show()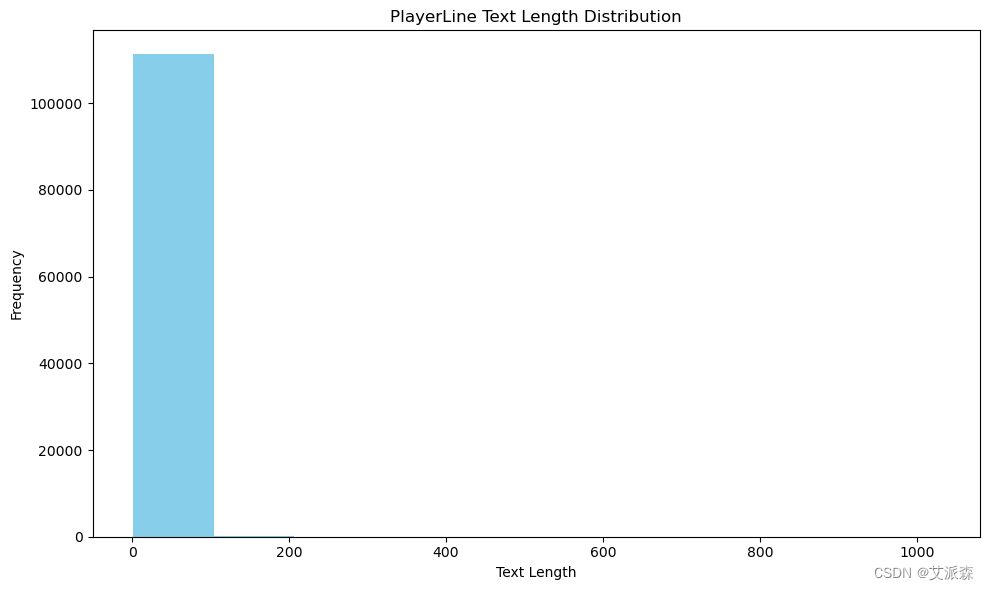
text = ' '.join(df['PlayerLine'])
wordcloud = WordCloud(width=800, height=400, background_color='black').generate(text)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud for PlayerLine Column')
plt.tight_layout()
plt.show()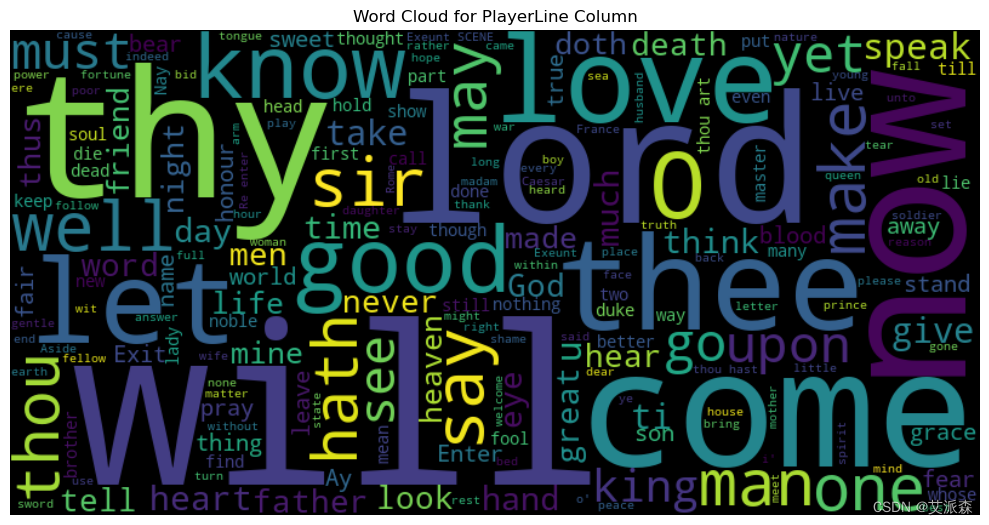
构建语料库
corpus = []
with open('Shakespeare_data.csv') as f:reader = csv.reader(f, delimiter=',')next(reader) for row in reader:corpus.append(row[5])print(len(corpus))
print(corpus[:3])
4.2数据预处理
数据清理是为自然语言处理(NLP)任务准备文本数据的重要步骤。它涉及到几个过程,以确保文本数据是一致的、标准化的、便于分析和建模的更易于管理的形式。以下是对数据清理过程的解释:文本数据中经常出现额外的空格和换行符,特别是当它来自不同的来源时。这些多余的空格可以被删除,以确保文本更简洁和统一。
文本数据可能包含与分析无关的特殊字符、符号或非字母数字字符。删除这些字符有助于简化文本,并将重点放在重要内容上。标点符号,如句号、逗号、感叹号和问号,通常会从文本数据中删除。如果分析的重点是单词级别的模式,这一步尤其重要,因为标点符号可能会干扰单词标记化。将所有文本转换为小写可确保文本不区分大小写。这一步有助于标准化数据和简化模式识别,因为“word”和“Word”被视为同一个单词。
在某些情况下,文本数据可能包含非ascii字符或编码问题。将文本编码为特定格式(例如,UTF-8),然后将其解码回ASCII,同时忽略有问题的字符有助于处理与编码相关的挑战。通过执行这些清理操作,文本数据变得更适合各种NLP任务,例如文本分类、情感分析、文本生成等等。干净的数据噪音更少,与NLP模型更兼容,确保模型可以专注于文本中的潜在模式和含义,而不是无关的噪音或不一致。此外,干净的数据简化了文本处理管道,使其更易于使用和分析。
def text_cleaner(text):text = re.sub(r'\s+\n+', ' ', text)text = re.sub(r'[^a-zA-Z0-9\.]', ' ', text)text = "".join(car for car in text if car not in string.punctuation).lower()text = text.encode("utf8").decode("ascii",'ignore')return textcorpus = [text_cleaner(line) for line in corpus]4.3标记文本
在下一步中,我们将设置一个标记器,并使用它来处理清理后的文本数据。标记器的作用是将每个单词映射到一个数值。由于许多机器学习操作基本上都是矩阵操作,因此我们需要将文本数据转换为与这些操作兼容的数字格式。
corpus = corpus[:5000]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
word_index = tokenizer.word_index
total_words = len(word_index) + 1
total_words4.4创建N-gram序列
在为文本生成准备文本数据的过程中,我们将首先根据前面建立的单词到数字的映射将句子转换为数字序列。随后,我们将深入研究N-gram处理,这是文本生成的关键步骤。
在机器学习领域,我们的目标是根据可用数据做出预测。在这个特殊的任务中,我们的目标是在给定初始单词的情况下预测句子中的下一个单词。因此,我们必须相应地构建我们的数据。
下面是我们要做的:我们将把每个句子转换成N-gram格式。这包括将文本分割成序列,最后一个单词作为目标。
例如,考虑源数据“I love Artificial Intelligence”:
I love
I love Artificial
I love Artificial Intelligence
本质上,我们从一个句子的第一个单词作为初始特征,后面的单词成为目标(标签)。我们对句子中的每个单词重复这个过程。因此,我们的模型提供了一个数据集,该数据集指示下一个单词应该给出一个特定的序列。在后面的文本生成过程中,我们将引入填充以确保每个特征标签对具有相同的大小,这是训练机器学习模型的必要步骤。
input_sequences =[]for sentence in corpus:token_list = tokenizer.texts_to_sequences([sentence])[0]for i in range(1, len(token_list)):n_gram_sequence = token_list[:i+1]input_sequences.append(n_gram_sequence)
len(input_sequences)
句子排序后是什么样子?

在提供的输出中,序列,如[159,3],[159,3,312],[159,3,312,1],[159,3,312,1,812]等,表示从输入数据生成的n-gram短语。这些序列中的每个整数对应于文本中存在的完整词汇表中特定单词的索引。
例如,短语“And breathe short-winded accent of new broils”被转换成以下n-gram序列:
“i stand”表示为[30,507]。这意味着在词汇表中,单词“i”与索引30相关联,而“stand”与索引507相关联。
“i stand with”表示为[30,507,11]。在词汇表中,“i”的索引为30,“stand”的索引为507,“with”的索引为11。
“i stand with the”表示为[30,507,11,1]。这里,“i”在索引30处,“stand”在507处,“with”在11处,“the”在索引1处。
“i stand with the shedevils”表示为[30,507,11,1,975]。在词汇表中,“i”对应索引30,“stand”对应索引507,“with”对应索引11,“the”对应索引1,“shedevils”对应索引975。
这些序列有助于以机器学习模型可以理解的格式表示文本。整数作为指向词汇表中特定单词的索引,允许模型学习文本数据中的模式和关系。
max_sequence_len = max([len(x) for x in input_sequences])
print(max_sequence_len)![]()
4.5填充序列
我们生成的n元序列的一个挑战是它们的长度是不同的。在涉及矩阵操作的任务中,具有一致的大小和形状对于有效处理至关重要。为了确保一致性,我们将通过向每个序列添加“零”值来合并填充,使它们的长度相同。这就是我们的最大序列长度参数变得有价值的地方。
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
before = input_sequences[1]
after = input_sequences[1]为了说明填充对序列的影响,让我们比较填充操作前后的序列。
print(f'Before: {before}')
print(f'After: {after}')
正如你所看到的,零被添加到原始序列的开头(例如,[159,3])。这种填充确保数据集中的每个条目都具有相同的长度。当使用机器学习模型时,统一的序列长度对于一致和有效的处理非常重要。
生成特征标签对
有了清理和准备好的文本语料库,现在是时候创建特征标签对的核心数据集了。该数据集将作为训练文本生成模型的基础。你可能还记得为什么我们在原始序列的开头添加填充的问题。这一步很重要,因为它使我们能够有效地构建训练数据集。该方法包括将序列的最后一个值设置为标签,前面的值成为特征。从本质上讲,我们训练模型来学习遵循文本中特定模式的典型单词。一旦模型完成训练,它将拥有根据前一个单词提供的上下文预测序列中的下一个单词来生成文本的能力。
predictors, label = input_sequences[:,:-1],input_sequences[:,-1]
label = tensorflow.keras.utils.to_categorical(label, num_classes=total_words)
print(label[0])
print(label[0].shape)
4.6词嵌入
词嵌入,如Word2Vec、GloVe和FastText,是自然语言处理(NLP)和文本生成的基本工具。它们将单词或符号表示为连续向量空间中的多维向量。每个单词被映射到这个空间中的一个点,单词在向量空间中的位置捕获它们之间的语义关系和上下文信息。
在文本生成中,嵌入层通常是神经网络模型的第一层。它将输入文本(单词或标记)转换为相应的嵌入,从而允许模型在连续向量空间中操作。这种连续表示使文本生成模型能够生成连贯、上下文相关且语义准确的类似人类的文本。嵌入是文本生成的基本组成部分,因为它们弥合了单词与其语义之间的差距,从而能够生成自然的和上下文感知的文本。
glove_path = "glove.twitter.27B.200d.txt"
embeddings_index = dict()
with open(glove_path,encoding="utf8") as glove:for line in glove:values = line.split()word = values[0]coefs = np.asarray(values[1:], dtype='float32')embeddings_index[word] = coefsglove.close()embedding_matrix = np.zeros((total_words, 200))
for word, index in tokenizer.word_index.items():if index > total_words - 1:breakelse:embedding_vector = embeddings_index.get(word)if embedding_vector is not None:embedding_matrix[index] = embedding_vector4.7模型设计
模型设计在文本生成过程中起着至关重要的作用。该体系结构旨在获得有效生成文本的能力。它将单词序列转换为向量嵌入,利用双向lstm处理序列,并使用softmax输出层来预测下一个单词。从本质上讲,它是一个用于理解上下文并生成连贯且与上下文相关的文本的健壮框架。
model = Sequential()
model.add(Embedding(total_words, 200, weights = [embedding_matrix],input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(512)))
model.add(Dropout(0.3))
model.add(Dense(total_words, activation='softmax'))
print(model.summary())
tensorflow.keras.utils.plot_model(model,show_shapes=True)
4.8回调
在深度学习中,回调是在模型训练过程中的特定点调用的函数或对象。它们有各种用途,可以定制以添加功能或在培训期间执行操作。以下是回调常用用例的概述:
自定义回调,如“MyCallback”允许您在训练的特定点实现您的逻辑和操作。这可以包括自定义评估、日志记录或您认为必要的任何其他操作。
“earlystopped”回调监视指定的度量(例如,验证丢失),并在度量停止改进时停止训练。它有助于防止过度拟合,并在不太可能进一步改善的情况下提前结束训练,从而节省时间。
“ModelCheckpoint”回调在训练期间保存模型检查点,通常基于所选指标的最佳性能。这确保了您可以访问最佳的模型权重以供以后使用。
“TensorBoard”回调记录了TensorBoard的各种指标和可视化,TensorBoard是一个用于监控和可视化训练过程的强大工具。它有助于跟踪模型性能和调试。
“learningratesscheduler”回调在训练期间调整学习率。学习率计划可以通过调整特定时期或条件下的学习率来帮助优化训练过程。
“LambdaCallback”允许您在培训过程中的特定点定义自定义操作。这是一个通用的回调,您可以将其用于自定义打印语句或基于训练进度的操作等任务。
回调增强了机器学习模型的灵活性和功能性。它们使您能够控制和定制训练过程的各个方面,从而使在训练期间更容易监视、优化和与模型交互。
class MyCallback(tf.keras.callbacks.Callback):def __init__(self,x,y):self.x=xself.y=ydef on_epoch_end(self,batch, logs=None): print("\nEpochs Ending Custom Callbacks:Intiation Predicting on test set:::")logs['from custom callback']=self.model.evaluate(self.x,self.y)[0]
def scheduler(epoch, lr):if epoch %2 == 0 :print("Epoch:",epoch,"Learning Rate:",lr)return lrelse:print("Epoch:",epoch,"Learning Rate:", lr * tf.math.exp(-0.1))lr_updated= lr * tf.math.exp(-0.1)return lr_updatedfilename = "log_callbackscsvlogger.csv"
monitor_metric = "loss"
file_path = 'model.{epoch:02d}-{loss:.2f}.h5'my_callbacks = [MyCallback(predictors, label),tf.keras.callbacks.EarlyStopping(monitor=monitor_metric, min_delta=0, patience=5, verbose=0, mode="min", baseline=None, restore_best_weights=True),tf.keras.callbacks.ModelCheckpoint(filepath=file_path, monitor=monitor_metric, save_best_only=True),tf.keras.callbacks.TensorBoard(log_dir="./tensorboardlogs"),tf.keras.callbacks.LearningRateScheduler(scheduler, verbose=0),tf.keras.callbacks.LambdaCallback(on_epoch_begin=lambda epoch, logs: print("Lambdacallback in epoch begin:: Epoch count", epoch))
]4.8编译并训练模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])history = model.fit(predictors, label,epochs=100,batch_size=64,verbose=1,callbacks=my_callbacks)
model.save('shakespeare_model.h5')训练结果可视化
plt.figure(figsize=(10,7))
plt.plot(history.history['loss'],label='Training Loss')
plt.title("Training Loss")
plt.show()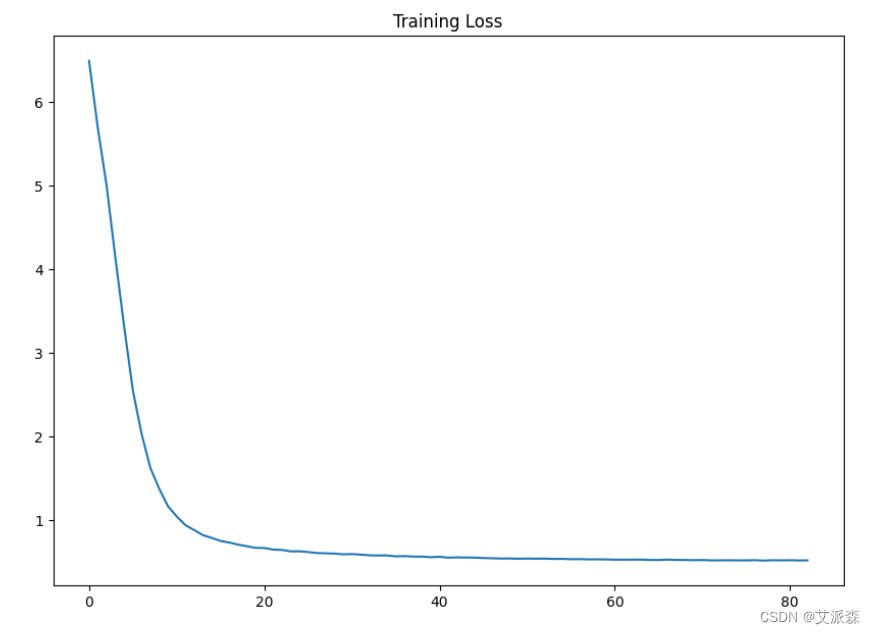
plt.figure(figsize=(10,7))
plt.plot(history.history['accuracy'],label='Training Accuracy')
plt.title("Training Accuracy")
plt.show()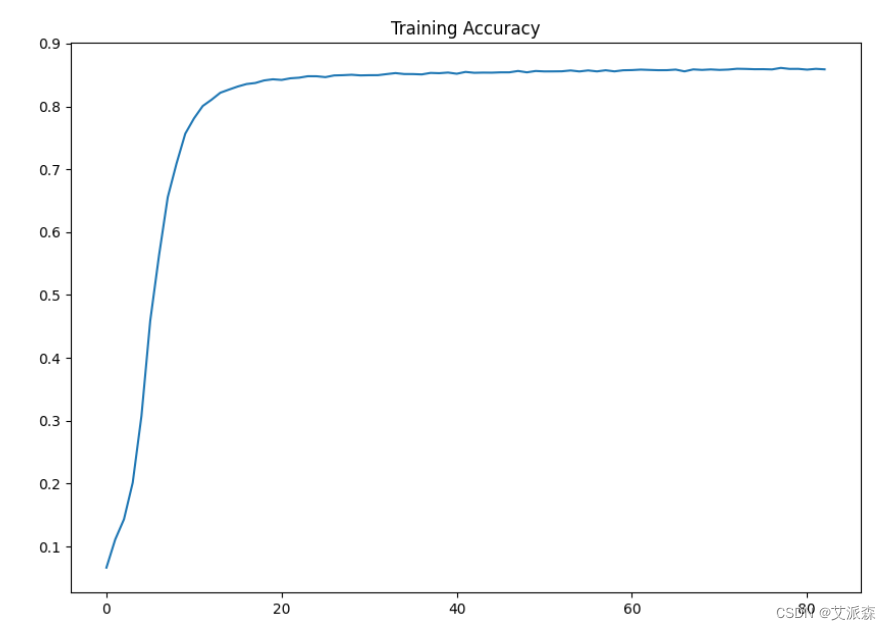
4.9文本生成
4.9.1贪婪搜索文本生成
贪婪搜索是一种简单直接的算法,可用于各种优化和决策问题。在自然语言处理和机器学习的背景下,它通常用于生成序列,例如文本生成或解码任务。贪婪搜索背后的基本思想是在每一步都做出局部最优选择,而不考虑该选择对未来决策的影响。
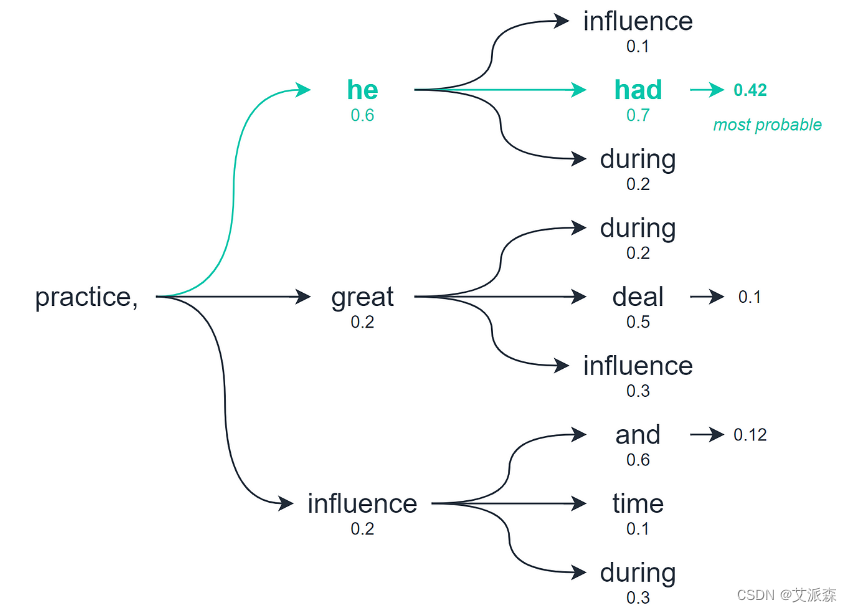
例如,在文本生成中,当选择序列中的下一个单词时,贪婪算法根据语言模型选择下一个出现概率最高的单词,而不考虑该选择如何影响生成文本的整体一致性和质量。贪婪搜索虽然简单且计算效率高,但可能并不总是产生最佳的整体解决方案,而且可能导致次优结果,特别是在复杂和微妙的任务中。
def greedy_search_generator(seed_text, num):if len(seed_text) == 0:print("Error: No word found")returnfor _ in range(num):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding="pre")predicted = model.predict(token_list, verbose=0)predicted_word_index = np.argmax(predicted)predicted_word = tokenizer.index_word[predicted_word_index]seed_text += " " + predicted_wordprint(seed_text)greedy_search_generator("my gentle cousin Westmoreland", 10)
4.9.2束搜索文本生成
束搜索是一种文本生成技术,通常用于自然语言处理和机器学习,特别是在机器翻译和文本生成等任务中。这是对贪婪搜索的改进,贪婪搜索倾向于产生局部最优解,但可能不会产生最佳的整体序列。波束搜索旨在通过在每一步考虑多个候选序列并保留固定数量的最可能的候选序列(称为“波束宽度”)来找到一个更全局的最优解。

束搜索是一种广泛使用的技术,因为与贪婪搜索相比,它通常产生更连贯和上下文相关的文本。生成文本的质量可以通过改变波束宽度来调整,较大的波束宽度考虑到更广泛的可能性,但需要更多的计算。然而,即使使用光束搜索,也必须记住,它可能并不总是找到绝对最佳的解决方案,并且在某些情况下仍然可能生成缺乏全局一致性的文本。
def beam_search_generator(seed_text, num_words, beam_width=3):if len(seed_text) == 0:print("Error: No word found")returninput_sequence = tokenizer.texts_to_sequences([seed_text])[0]input_sequence = pad_sequences([input_sequence], maxlen=max_sequence_len - 1, padding="pre")sequences = [{'text': seed_text, 'sequence': input_sequence, 'score': 1.0}]for _ in range(num_words):next_candidates = []for candidate in sequences:input_sequence = candidate['sequence']predicted_probabilities = model.predict(input_sequence, verbose=0)top_words = np.argsort(predicted_probabilities[0])[-beam_width:]for word in top_words:if word != 0:new_sequence = input_sequence.copy()new_sequence[0][-1] = wordgenerated_word = tokenizer.index_word[word]new_text = candidate['text'] + " " + generated_wordnew_score = candidate['score'] * predicted_probabilities[0][word]next_candidates.append({'text': new_text, 'sequence': new_sequence, 'score': new_score})next_candidates.sort(key=lambda x: -x['score'])sequences = next_candidates[:beam_width]for candidate in sequences:print(candidate['text'])beam_search_generator("my gentle cousin Westmoreland", num_words=10, beam_width=3)
4.9.3随机抽样文本生成
在文本生成上下文中,随机抽样是一种技术,涉及根据词汇表的概率分布在序列中选择下一个单词或标记。随机抽样不像贪婪搜索那样总是选择最可能的单词,也不像束搜索那样总是考虑固定数量的候选词,而是在文本生成过程中引入了随机性元素。它通过随机选择单词来允许生成文本的多样性,并根据其可能性为每个单词提供被选择的概率。虽然随机抽样可以产生更多样化和更有创意的输出,但它也可能导致文本缺乏连贯性或质量控制,因为它没有优先考虑最有可能的选择。这种技术通常用于创造性文本生成任务,如诗歌或艺术语言生成,其中多样性和不可预测性是期望的结果。
def random_sampling_generator(seed_text, num_words):generated_text = seed_textfor _ in range(num_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding="pre")predicted = model.predict(token_list, verbose=0)predicted_word_index = np.random.choice(len(predicted[0]), p=predicted[0])predicted_word = tokenizer.index_word[predicted_word_index]seed_text += " " + predicted_wordgenerated_text += " " + predicted_wordreturn generated_textgenerated_text_random = random_sampling_generator("my gentle cousin Westmoreland", num_words=10)
print(generated_text_random)
4.9.4带温度的随机采样文本生成
在文本生成中,“temperature”参数充当调节旋钮,控制输出中的随机性水平。较高的温度会引入更多的随机性和多样性,从而导致更少的可预测性和更具创造性的文本。相反,较低的温度使生成过程更具确定性,重点放在最可能的单词上,从而产生更可控和可预测的输出。温度的选择是使用概率语言模型(如GPT)的一个关键方面,允许用户微调一致性和创造性之间的权衡,以适应他们的特定应用和要求。
def generate_text_random(seed_text, num_words, temperature):generated_text = seed_textfor _ in range(num_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding="pre")predicted = model.predict(token_list, verbose=0)predicted = np.log(predicted) / temperaturepredicted = np.exp(predicted) / np.sum(np.exp(predicted))predicted_word_index = np.random.choice(len(predicted[0]), p=predicted[0])predicted_word = tokenizer.index_word[predicted_word_index]seed_text += " " + predicted_wordgenerated_text += " " + predicted_wordreturn generated_textgenerated_text_random = generate_text_random("my gentle cousin Westmoreland", num_words=10, temperature=0.7)
print(generated_text_random)
4.9.5Top-k采样文本生成
Top-k采样是一种文本生成方法,可以提高生成文本的可预测性和质量。它包括从k个最有可能的候选词的精简集中选择下一个词,而不是考虑整个词汇表。通过将选择范围缩小到预测概率最高的前k个单词,前k个采样在确定性和随机性之间取得了平衡。较小的k值导致文本生成更具确定性和重点,而较大的k值则引入多样性和创造力。该技术广泛应用于各种自然语言处理应用,以生成连贯的、与上下文相关的文本,并控制变化水平。
def top_k_sampling(logits, k=10):values, indices = tf.math.top_k(logits, k)values /= tf.reduce_sum(values)chosen_index = tf.random.categorical(tf.math.log(values), 1)[0, 0]return indices[0, chosen_index].numpy()def generate_text_top_k(seed_text, num_words, k=10):generated_text = seed_textfor _ in range(num_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding="pre")predicted = model.predict(token_list, verbose=0)predicted_word_index = top_k_sampling(predicted, k)predicted_word = tokenizer.index_word[predicted_word_index]seed_text += " " + predicted_wordgenerated_text += " " + predicted_wordreturn generated_textgenerated_text_top_k = generate_text_top_k("my gentle cousin Westmoreland", num_words=10, k=10)
print(generated_text_top_k)
4.9.6核(Top-p)文本生成采样
核采样,也称为top-p采样,是一种文本生成技术,用于提高生成文本的质量和控制。它涉及到从单词子集中选择下一个单词,这些单词共同构成一个预定义的累积概率,表示为“p”。核抽样不是考虑整个词汇表或固定数量的候选词,而是关注一组动态的词,这些词占累积概率质量的大部分。这种技术允许更可控和连贯的文本生成,因为选择的单词更有可能与上下文相关,同时仍然引入多样性和适应性。核采样在语言建模等任务中很有价值,在这些任务中,精确和灵活地生成文本是必不可少的。调整“p”的值允许用户在生成的文本中微调确定性和随机性之间的权衡。
def nucleus_sampling(logits, p=0.9):sorted_logits, sorted_indices = tf.math.top_k(logits, len(logits))cumulative_probs = tf.cumsum(tf.math.softmax(sorted_logits, axis=-1))sorted_indices_to_remove = cumulative_probs > pindices_to_remove = tf.range(0, len(logits)) > tf.reduce_sum(tf.cast(sorted_indices_to_remove, tf.int32))filtered_logits = logits - tf.reduce_max(logits)filtered_logits = tf.where(indices_to_remove, -np.inf, filtered_logits)sampled_word_index = tf.argmax(filtered_logits)return sampled_word_indexreverse_word_index = {value: key for key, value in tokenizer.word_index.items()}def generate_text_nucleus(seed_text, num_words, p=0.9):generated_text = seed_textfor _ in range(num_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding="pre")predicted = model.predict(token_list, verbose=0)predicted_word_index = int(nucleus_sampling(predicted[0], p))predicted_word = reverse_word_index[predicted_word_index]seed_text += " " + predicted_wordgenerated_text += " " + predicted_wordreturn generated_textgenerated_text_nucleus = generate_text_nucleus("They lost", num_words=20, p=0.9)
print(generated_text_nucleus)
with open('tokenizer.pkl', 'wb') as tokenizer_file:pickle.dump(tokenizer, tokenizer_file)5.总结
文本生成技术,如贪婪搜索、束搜索、随机抽样、温度随机抽样、Top-k抽样和核(Top-p)抽样,在增强LSTM模型在各种应用中的能力方面发挥着至关重要的作用。
贪婪搜索简单有效,但可能缺乏多样性,使其适合于翻译和摘要等任务。Beam Search提供了更加平衡的方法,提高了翻译和摘要的质量。随机抽样引入了创造力,但可能缺乏控制,而带有温度的随机抽样平衡了多样性和连贯性,在创意写作中特别有用。Top-k Sampling增强了确定性和随机性之间的平衡,使其适用于各种任务。核抽样或Top-p抽样结合了可预测性和多样性,有利于语言建模。多样波束搜索有助于释义和图像字幕,而约束波束搜索则用于释义、文案和SEO优化。Topk、TopP、TopKP的组合在创意写作方面表现出色。这些技术使LSTM模型能够在一系列应用程序中生成适合特定需求的文本,从准确性和一致性到创造性和多样性。
文末推荐与福利
《AI时代Python量化交易实战》免费包邮送出3本!

内容简介:
《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》是一本旨在帮助架构师在人工智能时代展翅高飞的实用指南。全书以ChatGPT为核心工具,揭示了人工智能技术对架构师的角色和职责进行颠覆和重塑的关键点。《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》通过共计 13 章的系统内容,深入探讨AI技术在架构设计中的应用,以及AI对传统架构师工作方式的影响。通过学习,读者将了解如何利用ChatGPT这一强大的智能辅助工具,提升架构师的工作效率和创造力。
《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》的读者主要是架构师及相关从业人员。无论你是初入职场的新手架构师还是经验丰富的专业人士,《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》都将成为你的指南,帮助你在人工智能时代展现卓越的架构设计能力。通过《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》的指导,你将学习如何运用ChatGPT等工具和技术,以创新的方式构建高效、可靠、可扩展的软件架构。
同时,《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》也适用于对架构设计感兴趣的其他技术类从业人员,如软件工程师、系统分析师、技术顾问等。通过学习《AI时代Python量化交易实战:ChatGPT让量化交易插上翅膀》的内容,你可以深入了解人工智能对架构设计的影响和带来的挑战,拓展自己的技术视野,提升对软件系统整体架构的理解和把握能力。编辑推荐:
1.量化交易新模式:让量化交易更高效、更快捷、更完美。
2.全流程解析:涵盖量化交易的不同应用场景,介绍从发量化交易Python语言基础、工具库、可视化库、数据采集与分析,再到量化交易、套利策略等关键环节。
3.实战检验:ChatGPT结合多种量化交易工具及案例实操讲解,理解更加透彻。
4.100%提高量化交易效率:揭秘ChatGPT与量化交易高效融合的核心方法论和实践经验。
5.赠送资源:赠送教学视频及配套工具,供读者下载学习。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-12-10 20:00:00
当当购买链接:http://product.dangdang.com/29658180.html
京东购买链接:https://item.jd.com/14297538.html
名单公布时间:2023-12-10 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取