文章目录
- 笔记
- 激活函数与Loss的梯度
- lesson5 手写数字识别问题
- lesson6 基本数据类型
- lesson7 创建tensor
- lesson8 索引和切片
- lesson9 维度变换
- lesson10 broadcasting
- lesson11 分割和合并
- lesson12 数学运算
- lesson13 Tensor统计
- lesson14 Tensor高阶
- lesson16 什么是梯度
- lesson17 常见函数的梯度
- lesson18 激活函数与Loss的梯度
- lesson19 感知机的梯度推导
- 单一输出感知机
- 多输出感知机
- MLP反向传播推导过程
- lesson22 优化小实例
- 2D函数优化实例
- lesson24 logistic regression
- lesson25 交叉熵
- lesson26 LR多分类问题实战
- lesson28 激活函数与GPU加速
- lesson29 MNIST
- lesson30 Visdom可视化
- lesson32 Train-Val-Test-交叉验证
- lesson32 正则化
- lesson34 动量和学习率衰减
- 学习率
- lesson35 early-stopping & dropout
- Stochastic Gradient Descent
- lesson38 卷积神经网络
- Batch Normalization
- nn.Moudle
- 数据增强
- 经典神经网络
- RNN
- LSTM
- 如何理解Embeding
- KL散度
笔记
- 分类Classification适用于离散的数据,回归Regression适用于连续的数据
- 一个epoch是对一个数据集迭代一次,一个step是对一个batch迭代一次
- 类型判断:
a = torch.tensor(2.2)
# 判断类型的两种方法:
# 1
a.type()
type(a) # 这是调用的python自带的方法,返回 torch.Tensor
# 2
isinstance(a, torch.FloatTensor) # 判断a的类型是否为torch.FloatTensor
- 一个标量的维度只有0维。表示它是一个标量。
- 一维向量在数学中叫vector向量,在pytorch中叫tensor张量
深度学习中norm表示什么意思
在深度学习中,"norm"通常表示范数(norm)的概念。范数是一种衡量向量或矩阵大小的方法,它可以用来度量向量的长度或矩阵的大小。
在深度学习中,常见的范数有以下几种:
L1范数(L1 Norm):也称为曼哈顿范数(Manhattan Norm),它计算向量中各个元素绝对值之和。对于向量x=(x₁, x₂, …, xn),L1范数定义为||x||₁ = |x₁| + |x₂| + … + |xn|。
L2范数(L2 Norm):也称为欧几里德范数(Euclidean Norm),它计算向量各个元素平方和的平方根。对于向量x=(x₁, x₂, …, xn),L2范数定义为||x||₂ = √(x₁² + x₂² + … + xn²)。
无穷范数(Infinity Norm):它计算向量中各个元素绝对值的最大值。对于向量x=(x₁, x₂, …, xn),无穷范数定义为||x||∞ = max(|x₁|, |x₂|, …, |xn|)。
这些范数在深度学习中经常用于正则化、损失函数的定义、优化算法等方面。例如,L1范数正则化可以用于稀疏性推断,L2范数正则化可以用于权重衰减(weight decay),无穷范数可以用于约束梯度的大小。
在深度学习中,范数的概念还可以扩展到矩阵或张量上,用于度量它们的大小或复杂度。例如,矩阵的Frobenius范数用于度量矩阵的大小,核范数(Nuclear Norm)用于度量矩阵的低秩性质。
使用 iter() 函数可以将可迭代对象转换为迭代器。例如:
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list)print(next(my_iter)) # 输出:1
print(next(my_iter)) # 输出:2
print(next(my_iter)) # 输出:3
enumerate()函数
enumerate返回索引值和对应的元素
fruits = ['apple', 'banana', 'orange']for index, fruit in enumerate(fruits):print(index, fruit)
"""
0 apple
1 banana
2 orange
"""
如何用pytorch表示String
1. one-hot编码:
one-hot编码是一种常用的数据编码方式,它将离散的类别型特征转化为一组二进制向量,用于机器学习等任务中。
eg,如果有男,女,中性,则分别用[1, 0, 0], [0, 1, 0], [0, 0, 1]表示。这样表示称为one-hot编码
2. Embedding
- Word2vec
- glove
# 随机正态分布
torch.randn()
# 随机均匀分布,[0, 1]Resnet:最大的特点使用了残差连接。
optimizer.zero_grad() :参数梯度的清零
loss.backward() :反向传播,计算梯度optimizer.step(): 根据梯度更新模型参数
这三行代码分别代表什么意思

上面是基础
激活函数与Loss的梯度
为什么要计算梯度w.requires_grad_(requires_grad=True), 有什么用?
梯度是一个向量,它指示了函数在给定点的变化率最大的方向。通过计算梯度,可以实现反向传播(Backpropagation),参数优化,特征选择等。
p[1].backward(retain_graph=True)
计算p[1]对张量a的梯度,并将该梯度存在a.grad中
mse = F.mse_loss(torch.ones(1), x*w)
F.mse_loss() 函数的输入参数是两个张量,分别表示预测值和目标值。它将计算这两个张量之间的均方误差,并返回一个标量张量作为结果。
torch.autograd.grad(mse, [w])
torch.autograd.grad() 函数用于计算给定标量张量 mse 相对于指定参数张量 w 的梯度。
retain_graph=True 表示保留中间的计算图,以便在第二调用backward时不会引发错误
import torch
from torch.nn import functional as F# autograd.grad 自动求导
x = torch.ones(1)
print(x)
w = torch.full([1], 2) # 创建了一个包含一个元素且值为2的PyTorch Tensor
print(w)
w = w.type(torch.float32)
w.requires_grad_(requires_grad=True) # w初始化时设置需要求导信息
mse = F.mse_loss(torch.ones(1), x*w)
# torch.autograd.grad(y,w) 表示y对w求导。
torch.autograd.grad(mse, [w], retain_graph=True) # retain_graph=True 表示保留中间的计算图,以便在第二调用backward时不会引发错误
# mse = F.mse_loss(torch.ones(1), x*w)
print(torch.autograd.grad(mse, [w]))# F.softmax 放缩到0-1且和为1
a = torch.rand(3) # 生成3个0-1的随机数
print(a)
a.requires_grad_()
p = F.softmax(a, dim=0) # 将给定的数据转化为0-1范围内,且和为1
print(p)
p[1].backward(retain_graph=True) # 计算p[1]对张量a的梯度,并将该梯度存在a.grad中
print(p[1])
p1 = torch.autograd.grad(p[1], [a], retain_graph=True) # 计算p1对张量a的梯度,返回梯度值
print(p1)
print(a.grad)
p[2].backward(retain_graph=True)
print(p[2])
p2 = torch.autograd.grad(p[2], [a], retain_graph=True) # 计算p2对张量a的梯度,返回梯度值
print(p2)
print(a.grad)"""
tensor([1.])
tensor([2])
(tensor([2.]),)
tensor([0.9741, 0.7026, 0.0407])
tensor([0.4639, 0.3536, 0.1824], grad_fn=<SoftmaxBackward0>)
tensor(0.3536, grad_fn=<SelectBackward0>)
(tensor([-0.1641, 0.2286, -0.0645]),)
tensor([-0.1641, 0.2286, -0.0645])
tensor(0.1824, grad_fn=<SelectBackward0>)
(tensor([-0.0846, -0.0645, 0.1491]),)
tensor([-0.2487, 0.1641, 0.0846])
"""
lesson5 手写数字识别问题
# mnist_train.py
import torch
from torch import nn
from torch.nn import functional as F # 常用函数
from torch import optim # 优化数据包import torchvision
from matplotlib import pyplot as pltfrom utils import plot_image, plot_curve, one_hot # image是图片,curve是曲线batch_size = 512 # 一次可以处理的图片数# step1. load dataset 非重点
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True, # train=True表示采用的训练集transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data/', train=False, download=True, # train=False表示采用的测试集transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(), # 下载下的为numpy格式,转为tensor格式torchvision.transforms.Normalize( # 使数据从0-1之间转为0附近均匀分布,使性能更好(0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=False)x, y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
plot_image(x, y, 'image sample')# 创建网络
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# xw+bself.fc1 = nn.Linear(28*28, 256) # 线性层 256是随机决定的 28*28是图片尺寸self.fc2 = nn.Linear(256, 64) # 256是fc2的输入,应为fc1的输出。self.fc3 = nn.Linear(64, 10) # 64是fc3的输入,应为fc2的输出。10是0-9十个数字。def forward(self, x):# x: [b, 1, 28, 28]# h1 = relu(xw1+b1)x = F.relu(self.fc1(x))# h2 = relu(h1w2+b2)x = F.relu(self.fc2(x))# h3 = h2w3+b3x = self.fc3(x)return xnet = Net()
# [w1, b1, w2, b2, w3, b3]
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)train_loss = []for epoch in range(3): # 对整个数据集迭代3次for batch_idx, (x, y) in enumerate(train_loader): # 对一个batch迭代一次# x: [batch_size, 1, 28, 28], y: [batch_size] x是图像输入,y是输出结果0-9# [batch_size, 1, 28, 28] => [batch_size, 784]x = x.view(x.size(0), 28*28)# => [b, 10]out = net(x) # net是个全连接层,只能接受dimension=2的输入,即[b, feature]的特征(b=batch_size)。因此要view成新的shape。# [b, 10]y_onehot = one_hot(y)# loss = mse(out, y_onehot)loss = F.mse_loss(out, y_onehot)optimizer.zero_grad()loss.backward()# w' = w - lr*gradoptimizer.step() # 更新参数信息train_loss.append(loss.item())if batch_idx % 10==0:print(epoch, batch_idx, loss.item())plot_curve(train_loss)
# we get optimal [w1, b1, w2, b2, w3, b3]total_correct = 0
for x,y in test_loader:x = x.view(x.size(0), 28*28)out = net(x)# out: [b, 10] => pred: [b]pred = out.argmax(dim=1)correct = pred.eq(y).sum().float().item()total_correct += correcttotal_num = len(test_loader.dataset)
acc = total_correct / total_num
print('test acc:', acc)x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')# utils.py
# 封装了一些函数
import torch
from matplotlib import pyplot as pltdef plot_curve(data):fig = plt.figure()plt.plot(range(len(data)), data, color='blue')plt.legend(['value'], loc='upper right')plt.xlabel('step')plt.ylabel('value')plt.show()def plot_image(img, label, name):fig = plt.figure()for i in range(6):plt.subplot(2, 3, i + 1)plt.tight_layout()plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')plt.title("{}: {}".format(name, label[i].item()))plt.xticks([])plt.yticks([])plt.show()def one_hot(label, depth=10):# convert label to one-hot encodingout = torch.zeros(label.size(0), depth)idx = torch.LongTensor(label).view(-1, 1)out.scatter_(dim=1, index=idx, value=1)return outlesson6 基本数据类型
# 判断数据类型方法
a.type() //
type(a) # python自带的
isinstance(a, torch.FloatTensor) # 判断是否为某种类型的# dimension为0的标量表示方法: (dimension为0的标量常用于表示loss)
a = torch.tensor(1.) # tensor(1.)# dimension为1的张量表示方法,常用于表示bias偏置
torch.tensor([1.1]) # tensor([1.1000])
torch.tensor([1.1, 2.2]) # tensor([1.1000, 2.2000])
# FloatTensor的参数为张量的长度,而内容为随机初始化的。
torch.FloatTensor(1) # tensor([3.2239e-25])
torch.FloatTensor(2) # tensor([3.2239e-25, 4.59e-41])# 从numpy转为tensor
data = np.ones(2) # array([1., 1.])
torch.from_numpy(data) # tensor([1., 1.], dtype=torch.float64)# dimension为2的张量常用于表示多张图片的时候。比如有100张图片,每张图片是28*28=784的,所以可以用[100, 784]表示多张图片 # 求size,shape
a = torch.tensor(2.2)
a.shape # torch.Size([])
len(a.shape) # 0
a.size() # torch.Size([])# dimension为3适用于RNN,自然语言处理# dimension为4适用于图片,卷积神经网络。
[b, c, h, w] => [图片数, 通道数, 高度, 宽度]# 其他
a.numel() #tensor占用的内存的数量
a.dim() # 返回维度dimensionlesson7 创建tensor
import numpy as np
import torch# import from numpy
a = np.array([2, 3.3])
a = torch.from_numpy(a)
print(a)
# 全1矩阵,[a, b]表示创建a行b列的矩阵
a = np.ones([2, 3])
a = torch.from_numpy(a)
print(a)# torch.tensor 使用现成的数据, tensor.Tensor接收数据的shape维度
# import from list
a = torch.tensor([2., 3.2]) # a就是tensor类型的[2, 3.2]
print(a)
a = torch.Tensor(2, 3) # 生成2行3列的数据
print(a)
# 如果出现torch.nan 或者torch.inf可能是没有初始化# 随机初始化
a = torch.rand(3, 3) # 生成一个3行3列的,均匀采样于[0, 1]之间的数
print(a)# 生成相同shape的tensor
a = torch .rand_like(a)
print(a)
# int的随机初始化
a = torch.randint(1, 10, [3, 3]) # [1, 9] shape:(3,3)
print(a)# 正态分布 N(0, 1) 作为bias的初始化
a = torch.randn(3, 3) # 生成(3, 3)的,均值为0 方差为1的tensor
print(a)# full: 全部赋值为1个元素
a = torch.full([2, 3], 7) # 2*3, 用7来填充
print(a)
# [] 表示生成标量 用7来填充
a = torch.full([], 7)
print(a) # tensor(7)
# [1] 表示生成dimension为1的tensor
a = torch.full([1], 7)
print(a) # tensor([7])# arange
a = torch.arange(0, 10) # 生成0-9的数字,默认步长是1
print(a)
a = torch.arange(0, 10, 2) # 步长是2
print(a)# linespace /logspace
a = torch.linspace(0, 10, steps=4) # 0,10分别表示第一个和最后一个元素 steps表示元素数量
print(a)
a = torch.linspace(0, 10, steps=11)
print(a)
a = torch.logspace(0, -1, steps=10) # 这个是logspace, 0表示10的0次方,-1表示10的-1次方
print(a) # a的第一个数是1,最后一个数是0# ones zeros eye
a = torch.ones(3, 3) # 生成3*3的全1矩阵
a = torch.zeros(3, 3) # 生成3*3的全0矩阵
a = torch.eye(3, 4) # 生成主对角全1的矩阵# randperm随机打散 重新排序 ★★
a = torch.randperm(10) # 0-9之间的所有数随机打散a = torch.rand(2, 3)
b = torch.rand(2, 2)
idx = torch.randperm(2)
print(idx)
print("a=\n", a)
a = a[idx] # 将a的行按照idx重新排序 (整个行重新换)
print("new_a=\n",a)
print("b=\n", b)
b = b[idx]
print("new_b=\n", b) # 将b的行按照idx重新排序lesson8 索引和切片
import numpy
import torch# index: dim 0 first
a = torch.rand(4, 3, 28, 30)
print(a[0].shape) # torch.Size([3, 28, 30])
print(a[0, 0].shape) # torch.Size([28, 30])
print(a[0, 0, 2, 4]) # 用下标索引元素值# 隔行采样:
print(a[:, :, 0:28:2, 0:30:2].shape) # torch.Size([4, 3, 14, 14])
# ::2 等价于start:end:2# index_select
"""
a.index_select(idx, torch.arange(k))
将第idx个维度变为k
"""
print(a.index_select(0, torch.arange(2)).shape)
print(a.index_select(2, torch.arange(13)).shape)
lesson9 维度变换
import numpy as np
import torch# view / reshape
# view能干的reshape都能干。reshape更强大
a = torch.rand(4, 1, 28, 28)
print(a.shape) # torch.Size([4, 1, 28, 28])
b = a.view(4, 28*28)
print(b.shape) # torch.Size([4, 784])
c = a.reshape(4*28, 28)
print(c.shape)# squeeze / unsqueeze
# unsqueeze(idx) 将shape在idx维度多插上一维。
# 指定压缩第n位,如果它的维数为1,则压缩,反之不对该维度操作。
# unsqueeze(-1) 使shape从[2] => [2, 1], 再unsqueeze变成[2,1,1] -1表示插到最后面
# unsqueeze(1) 使shape从[4,2] => [4, 1,2]
a = torch.tensor([1.2, 2.3])
print(a.unsqueeze(-1)) # shape变成[2,1]
"""
tensor([[1.2000],[2.3000]])
"""
print(a.unsqueeze(0)) # 变成[1, 2] tensor([[1.2000, 2.3000]])
# 实在案例
b = torch.rand(32) # b是在channel上的bias。
f = torch.rand(4, 32, 14, 14)
b = b.unsqueeze(0).unsqueeze(2).unsqueeze(3)
print(b.shape) # torch.Size([1, 32, 1, 1])# squeeze(n)用法
# 指定压缩第n位,如果它的维数为1,则压缩,反之不对该维度操作。
b = torch.Tensor(1, 32, 1, 1)
print(b.shape)
print(b.squeeze().shape) # torch.Size([32]) b.squeeze表示默认将所有维度为1的全部squeeze
print(b.squeeze(0).shape) # torch.Size([32, 1, 1]) 将第0维挤压# 维度扩展expand / repeat
# expand: boradcasting 不主动复制数据,推荐使用。
a = torch.rand(4, 32, 14, 14)
b = torch.Tensor(1, 32, 1, 1)
print(b.expand(4, 32, 14, 14).shape) # torch.Size([4, 32, 14, 14]) expand从1到n可行,从n到m不太好# repeat
# repeat: memory copied
# repeat的参数表示倍数,在原来的基础上乘
b = torch.Tensor(1, 32, 1, 1)
print(b.repeat(4, 32, 1, 1).shape) # torch.Size([4, 1024, 1, 1])# .t 转置
a = torch.randn(3, 4) # 生成3行4列的矩阵
print(a.t().shape, a.t()) # torch.Size([4, 3])# permute
# 按照参数的顺序交换维度。
b = torch.rand(4, 3, 28, 32)
print(b.permute(0, 2, 3, 1).shape) # torch.Size([4, 28, 32, 3])
lesson10 broadcasting
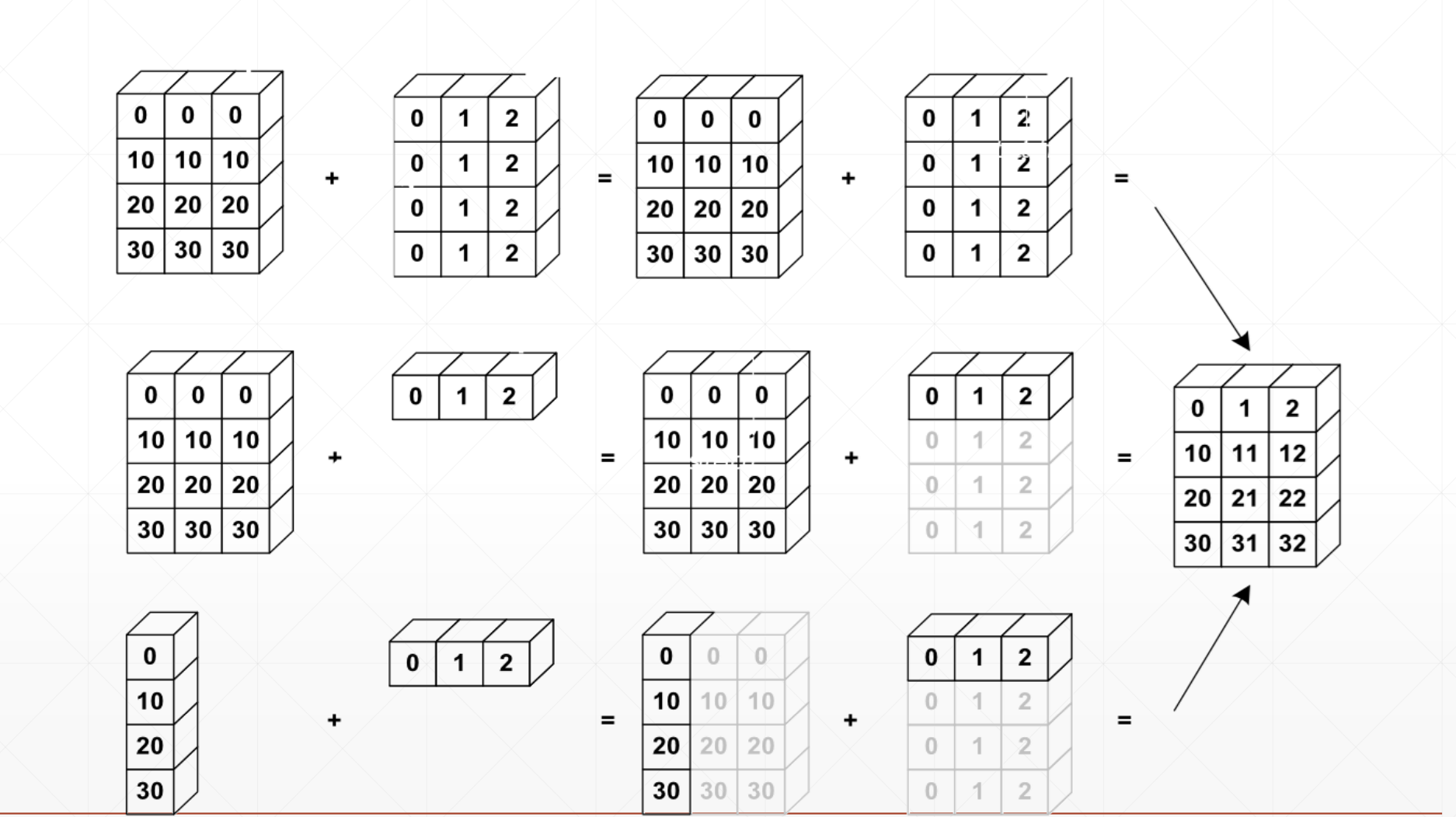
关于是否可以用广播机制:
如果当前维度dim=1,则可直接expand到相同dim
如果没有dim,就插入一个dim,然后expand到相同dim
否则不能broadcasting:

lesson11 分割和合并
import numpy as np
import torch# cat concat 要求除了拼接外的维度之外都不一样
a1 = torch.rand(4, 3, 32, 32)
a2 = torch.rand(5, 3, 32, 32)
print(torch.cat([a1, a2], dim=0).shape) # torch.Size([9, 3, 32, 32])a2 = torch.rand(4, 1, 32, 32)
print(torch.cat([a1, a2], dim=1).shape) # torch.Size([4, 4, 32, 32])a1 = torch.rand(4, 3, 16, 32)
a2 = torch.rand(4, 3, 20, 32)
print(torch.cat([a1, a2], dim=2).shape) # torch.Size([4, 3, 36, 32])# stack: create new dim 要求a和b的shape完全一样。
a1 = torch.rand(4, 3, 16, 32)
a2 = torch.rand(4, 3, 16, 32)
print(torch.stack([a1, a2], dim=2).shape) # torch.Size([4, 3, 2, 16, 32]) 在dim=2处插一个维度b = torch.randn(32, 8)
a = torch.randn(32, 8)
c = torch.stack([a, b], dim=0)
print(c.shape) # torch.Size([2, 32, 8])# split: by len
a = torch.rand([5, 6])
print(a)
aa, bb = torch.split(a, [2, 3], dim=0) # 按行去split,本来是[5,6], split成[2,6]和[3,6]
print(aa.shape, bb.shape) # torch.Size([2, 6]) torch.Size([3, 6])
lesson12 数学运算
import numpy as np
import torcha = torch.rand(3,4)
b = torch.rand(4)
torch.all(torch.eq(a-b, torch.sub(a,b)))
print(a + b)
print(torch.add(a, b)) # 等价于a+b# 同理,torch.sub(a,b) 等价于a-b# 矩阵的乘法
# matmul:
# torch.mm : 只适用于2d
# torch.matmul
# @
a = torch.full([2, 2], 3)
b = torch.ones(2, 2)
# 矩阵乘法的三种表示方法
torch.mm(a, b) # 等价于
torch.matmul(a, b) # 等价于
print(a@b)a = torch.rand(4, 784)
x = torch.rand(4, 784)
w = torch.rand(512, 784) # w:(channel.out, channel.in)
print(torch.matmul(x, w.t()).shape) # torch.Size([4, 512])# >>> a = torch.rand(4,3, 28, 64)
# >>> b = torch.rand(4,1,64,32)
# >>> torch.matmul(a,b).shape
# torch.Size([4, 3, 28, 32])# 次方
# a.pow(k) : a的k次方
# a**k
# a.sqrt(): 开根号
# a.rsqrt(): 取倒数再开方# e的几次方 & ln
a = torch.exp(torch.ones(2, 2))
print(torch.log(a)) # 对a的所有元素再取ln# 近似值
a = torch.tensor(3.14)
a.floor() # 取地板
a.ceil() # 取天花板
a.trunc() # 取整数
a.frac() # 取小数# clamp
# 将值限制在给定参数的范围内
# a.clamp(min, max) : 将a的值限定在min-max之间。a中的值小于min的变成min,大于max的变成max,介于二者之间的不变。
grad = torch.rand(2, 3) * 15
lesson13 Tensor统计
import torch"""
tensor统计:
norm: 求范数
mean : 平均值 sum : 求和
prod : 连乘
max, min, argmin, argmax : 最大最小值,最大最小值的idx(默认先打平,再求第几个数)
kthvalue, topk : 第k大的数的位置及其值
"""# 1范数表示 |x|求和。 2范数表示平方和再开根号。
a = torch.tensor([1,2,3,4,5,6,7,8], dtype=float)
b = a.view(2, 4)
c = a.view(2, 2, 2)
print(c)
print(c.norm(1, dim=0)) # 参数1表示1范数。 2表示2范数
print(c.norm(1, dim=1))
print(c.norm(1, dim=2))
print(c.norm(2, dim=0))
"""
c: tensor([[[1., 2.],[3., 4.]],[[5., 6.],[7., 8.]]], dtype=torch.float64)c.norm(1, dim=0):
tensor([[ 6., 8.],[10., 12.]], dtype=torch.float64)c.norm(1, dim=1):
tensor([[ 4., 6.],[12., 14.]], dtype=torch.float64)c.norm(1, dim=2):
tensor([[ 3., 7.],[11., 15.]], dtype=torch.float64)
"""a = torch.randn(4, 10)
print(a.argmax()) # tensor(28)
print(a.argmax(dim=1)) # tensor([1, 0, 8, 2]) 每行10个数,求10个数中的最大值的idx,即按照dim=1求最大值# dim, keepdim
a = torch.rand(4, 10)
b = a.max(dim=1) # b[0]是value的max, b[1]是value对应的idx
c = a.max(dim=1, keepdim=True)
print(b[0].shape) # torch.Size([4])
print(c[0].shape) # torch.Size([4, 1]) 保持竖着的a = torch.rand(4, 10)
print(a)
print(a.topk(3, dim=1)) # 共4行,返回每一行前3大的元素及下标
print(a.topk(3, dim=1, largest=False)) # largest=False表示求最小的。
print(a.kthvalue(8, dim=1)) # 默认是第8小的元素"""
tensor([[0.7841, 0.5202, 0.5160, 0.4788, 0.6427, 0.1049, 0.5161, 0.3836, 0.1677, 0.4653],[0.4838, 0.4054, 0.4336, 0.1541, 0.4228, 0.4602, 0.5819, 0.3031, 0.0749, 0.7695],[0.2420, 0.7969, 0.7428, 0.4675, 0.3132, 0.7516, 0.6356, 0.4277, 0.7945, 0.1089],[0.0475, 0.6876, 0.4313, 0.2479, 0.8423, 0.2280, 0.3918, 0.2062, 0.9654, 0.9479]])
torch.return_types.topk(
values=tensor([[0.7841, 0.6427, 0.5202],[0.7695, 0.5819, 0.4838],[0.7969, 0.7945, 0.7516],[0.9654, 0.9479, 0.8423]]),
indices=tensor([[0, 4, 1],[9, 6, 0],[1, 8, 5],[8, 9, 4]]))
torch.return_types.topk(
values=tensor([[0.1049, 0.1677, 0.3836],[0.0749, 0.1541, 0.3031],[0.1089, 0.2420, 0.3132],[0.0475, 0.2062, 0.2280]]),
indices=tensor([[5, 8, 7],[8, 3, 7],[9, 0, 4],[0, 7, 5]]))torch.return_types.kthvalue(
values=tensor([0.5202, 0.4838, 0.7516, 0.8423]),
indices=tensor([1, 0, 5, 4]))
"""# torch.equal() 用的更多一些
# torch.eq(a,b) 返回相同类型的矩阵,相等的位置为1,不等的位置为0
# torch.equal(a,b) 返回True或False
lesson14 Tensor高阶
where
gather
import torch# where
# torch.where(cond>0.5, a, b) 大于0.5选a,小于0.5选b的值
cond = torch.rand(2, 2)
print(cond)
a = torch.zeros(2, 2)
print(a)
b = torch.ones(2, 2)
print(b)
c = torch.where(cond>0.5, a, b)
print(c)
"""
#### where
tensor([[0.4118, 0.6295],[0.1647, 0.2860]])
tensor([[0., 0.],[0., 0.]])
tensor([[1., 1.],[1., 1.]])
c = torch.where(cond>0.5, a, b) 大于0.5选a,小于0.5选b的值
tensor([[1., 0.],[1., 1.]])进程已结束,退出代码0
"""# gather
prob = torch.randn(4, 10)
topk = prob.topk(dim=1, k=3)
print("idx=\n", topk)
idx = topk[1] # 取到下标。 topk[1]表示
print("idx=\n", idx)
label = torch.arange(10) + 100
# 根据idx索引,在label张量中收集对应 位置的值。
res = torch.gather(label.expand(4, 10), dim=1, index=idx.long()) # idx.long()表示转为长整型
print("res=\n", res)
"""
idx=torch.return_types.topk(
values=tensor([[1.1974, 0.6872, 0.6593],[1.5346, 0.4412, 0.4348],[1.8746, 1.3127, 0.5541],[1.9470, 0.8821, 0.5151]]),
indices=tensor([[1, 3, 4],[9, 6, 5],[0, 9, 2],[9, 7, 8]]))
idx=tensor([[1, 3, 4],[9, 6, 5],[0, 9, 2],[9, 7, 8]])
res=tensor([[101, 103, 104],[109, 106, 105],[100, 109, 102],[109, 107, 108]])
"""
lesson16 什么是梯度
梯度的长度反应趋势
梯度的方向反应增长的方向。


哪些因素会影响搜索过程?
- 初始状态
- 学习率
- 动量(如何逃离局部极小值):可以理解为惯性。
lesson17 常见函数的梯度
导数偏导数都是在一个方向上的求导。梯度是所有方向上的导数。
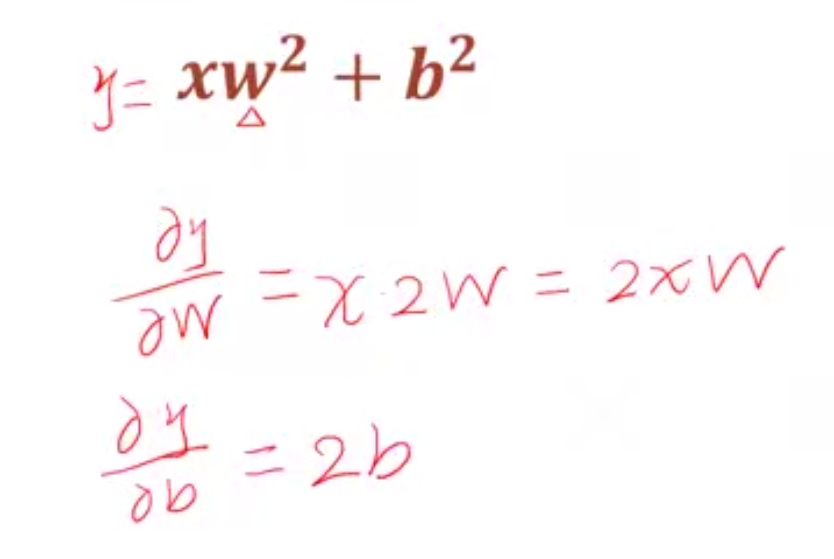
lesson18 激活函数与Loss的梯度
Sigmoid激活函数
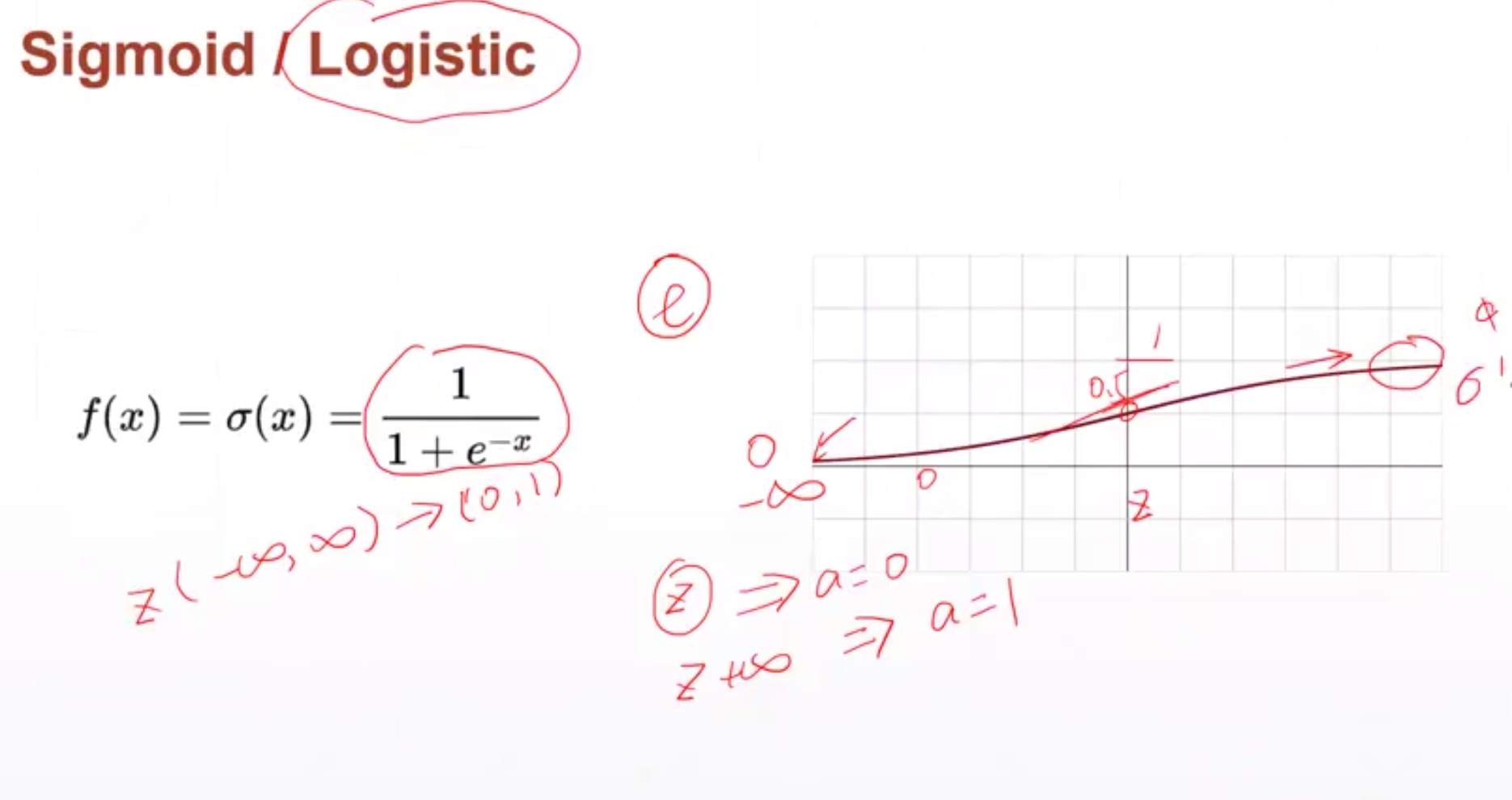
对于Sigmoid函数,f' = f * (1-f)。
当x趋于正无穷或负无穷时,其导数值变为0,梯度无法更新。
Tanh激活函数
适用于RNN
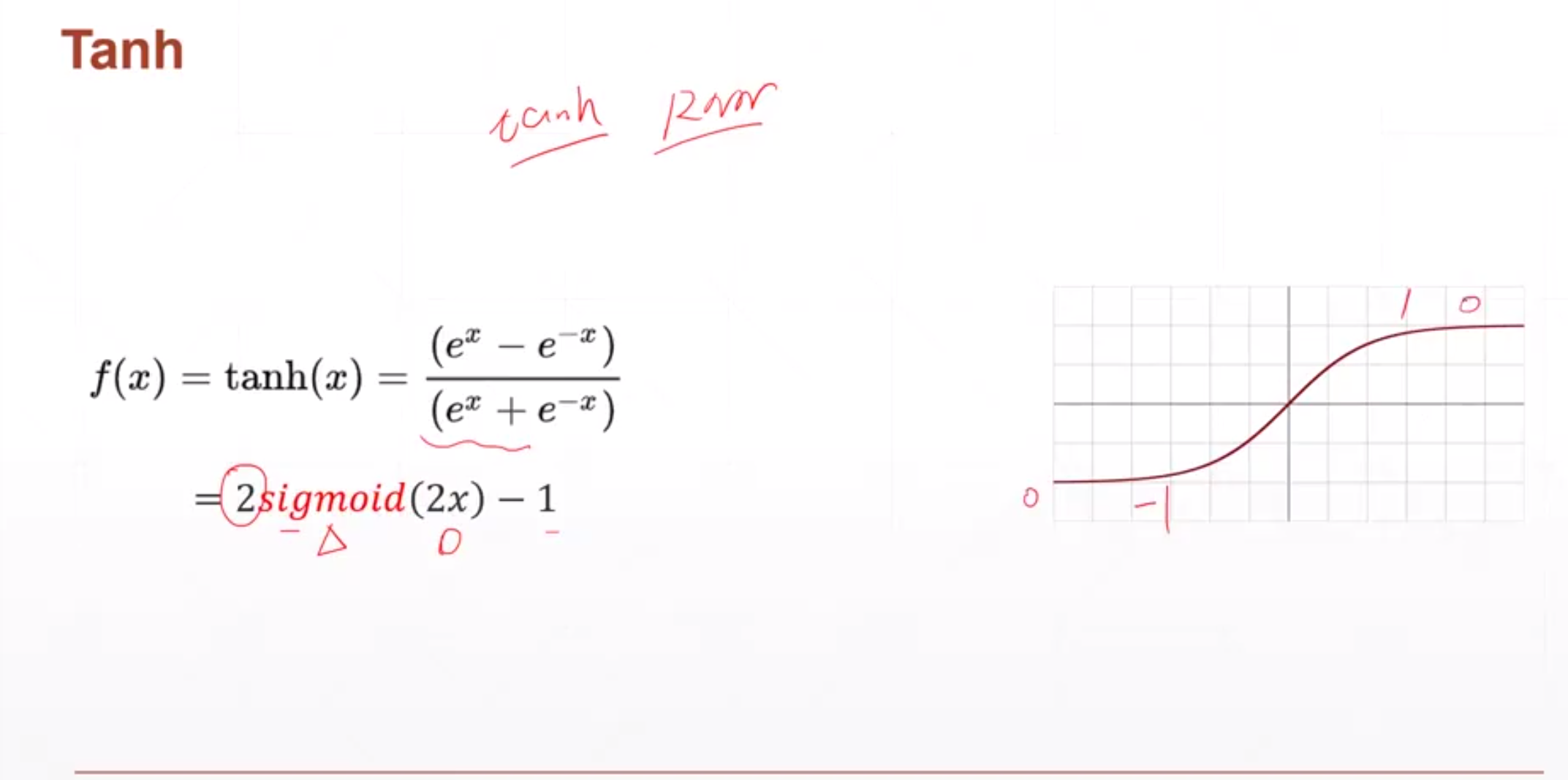
ReLU激活函数

** Gradient API **
求损失函数对参数的梯度信息

- torch.autograd.grad(loss, [w1, w2…])
-
Softmax
让数据转化为概率,使用softmax可以将所有的数据转为0-1内且数据求和为1
还可以使大的更大 小的更小。

softmax 求导



import torch
from torch.nn import functional as F# 常见激活函数
a = torch.randn(10)
print(a)
print(torch.sigmoid(a))
print(torch.tanh(a))
print(torch.relu(a))# autograd.grad 自动求导
x = torch.ones(1)
print(x)
w = torch.full([1], 2,) # 创建了一个包含一个元素且值为2的PyTorch Tensor
print(w)
w = w.type(torch.float32) # 更改w的类型
w.requires_grad_(requires_grad=True) # w初始化时设置需要求导信息
mse = F.mse_loss(torch.ones(1), x*w) # 求平均绝对误差。 torch.ones()是真实值,x*w是预测值
# torch.autograd.grad(y,[w]) 表示y对w求导。
torch.autograd.grad(mse, [w], retain_graph=True) # retain_graph=True 表示保留中间的计算图,以便在第二调用backward时不会引发错误
print(torch.autograd.grad(mse, [w]))# loss.backward ?
x = torch.ones(1)
w = torch.full([1], 2)
w = w.type(torch.float32) # 下一行的需要梯度信息需要浮点类型数据才能有梯度信息,所以将w改为浮点类型。
w.requires_grad_()
mse = F.mse_loss(torch.ones(1), x*w)
print(mse)
mse.backward() # 对loss向后传播,把梯度信息存在.grad中。每个参数的梯度信息存储在.grad中
print(w.grad)# softmax 求导
# F.softmax 放缩到0-1且和为10
a = torch.rand(3) # 生成3个0-1的随机数
print(a)
a.requires_grad_()
p = F.softmax(a, dim=0) # 将给定的数据转化为0-1范围内,且和为1
print(p)
p[1].backward(retain_graph=True) # 计算p[1]对张量a的梯度,并将该梯度存在a.grad中
print(p[1])
p1 = torch.autograd.grad(p[1], [a], retain_graph=True) # 计算p[1]对张量a的梯度,返回梯度值
print(p1) # (tensor([-0.1025, 0.2275, -0.1249]),) 只有p[1]的下标为正
print(a.grad) # tensor([-0.1025, 0.2275, -0.1249])
p[2].backward(retain_graph=True)
print(p[2]) # tensor(0.3571, grad_fn=<SelectBackward0>)
p2 = torch.autograd.grad(p[2], [a], retain_graph=True) # 计算p2对张量a的梯度,返回梯度值 只有p[2]的下标为正
print(p2) # (tensor([-0.1046, -0.1249, 0.2296]),)
print(a.grad) # tensor([-0.2072, 0.1025, 0.1046]) 这里的梯度累加了p[1]的和p[2]的梯度lesson19 感知机的梯度推导
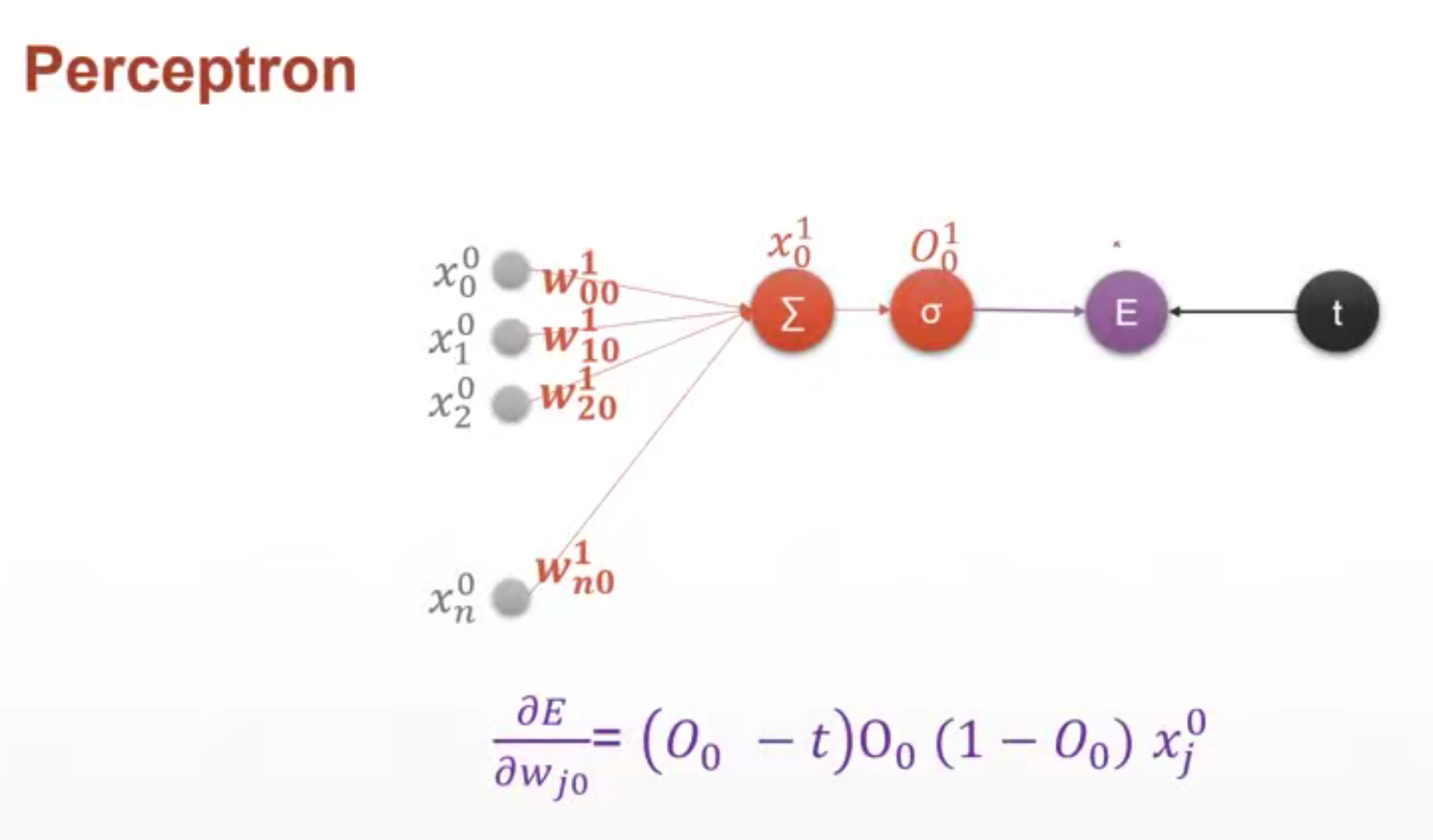
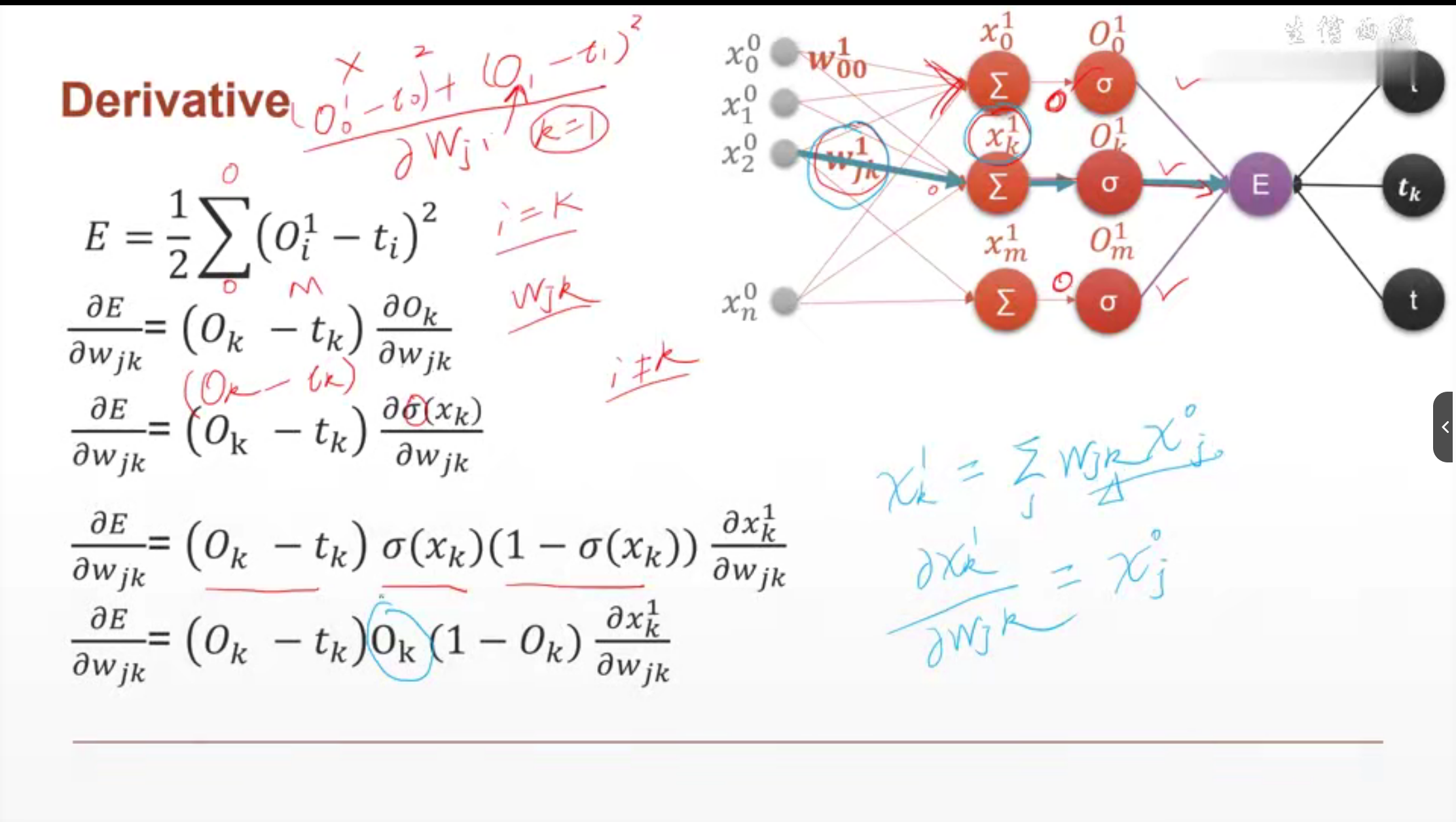
单一输出感知机

上标1表示第1层
下标i表示上一层结点是为i,j表示当前层的结点是j

O应该表示输出预测值,t表示true真实值。
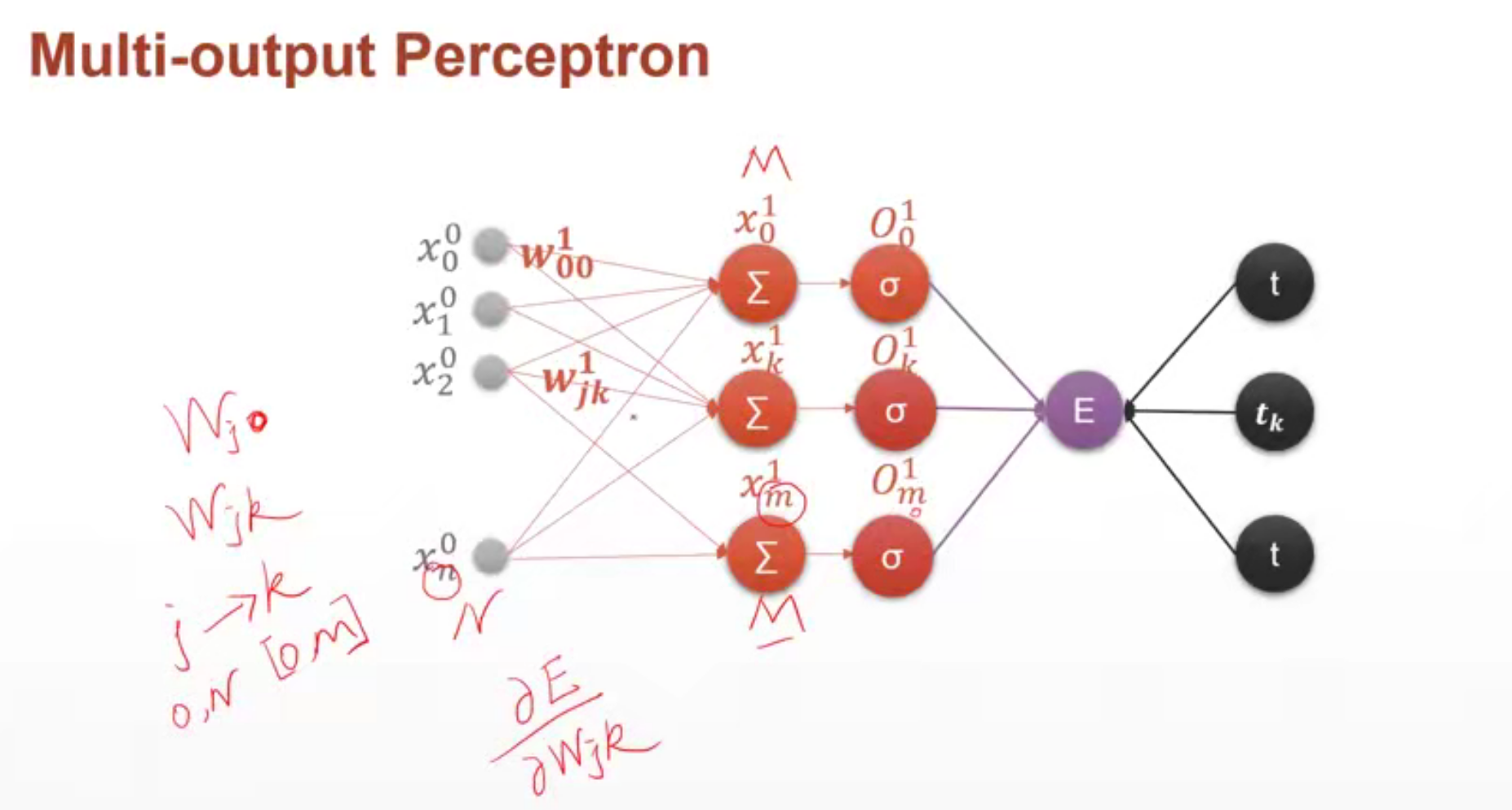
多输出感知机
import torch
from torch.nn import functional as F# 单一输出感知机推导
x = torch.randn(1, 10)
w = torch.randn(1, 10, requires_grad=True) # 设置w需要保存梯度信息
o = torch.sigmoid(x@w.t()) # 得到1*1的输出结果
print(o.shape) # torch.Size([1, 1])
loss = F.mse_loss(torch.ones(1, 1), o) # 计算平均绝对误差。 真实值是(1, 1),预测值是o
print(loss.shape) # loss是个标量,所以shape是torch.Size([])
loss.backward() # 计算损失函数对参数的梯度信息
print(w.grad) # 输出损失函数对w的梯度。w是[1, 10]的tensor,所以w的梯度信息也是[1, 10]的。# 多输出感知机
x = torch.randn(1, 10)
w = torch.randn(2, 10, requires_grad=True)
o = torch.sigmoid(x@w.t()) # 得到[1, 2]的输出
print(o.shape)
loss = F.mse_loss(torch.ones(1, 2), o)
print(loss.shape)
loss.backward() # 可以得到损失函数对所有需要梯度信息的参数的梯度信息
print(w.grad)
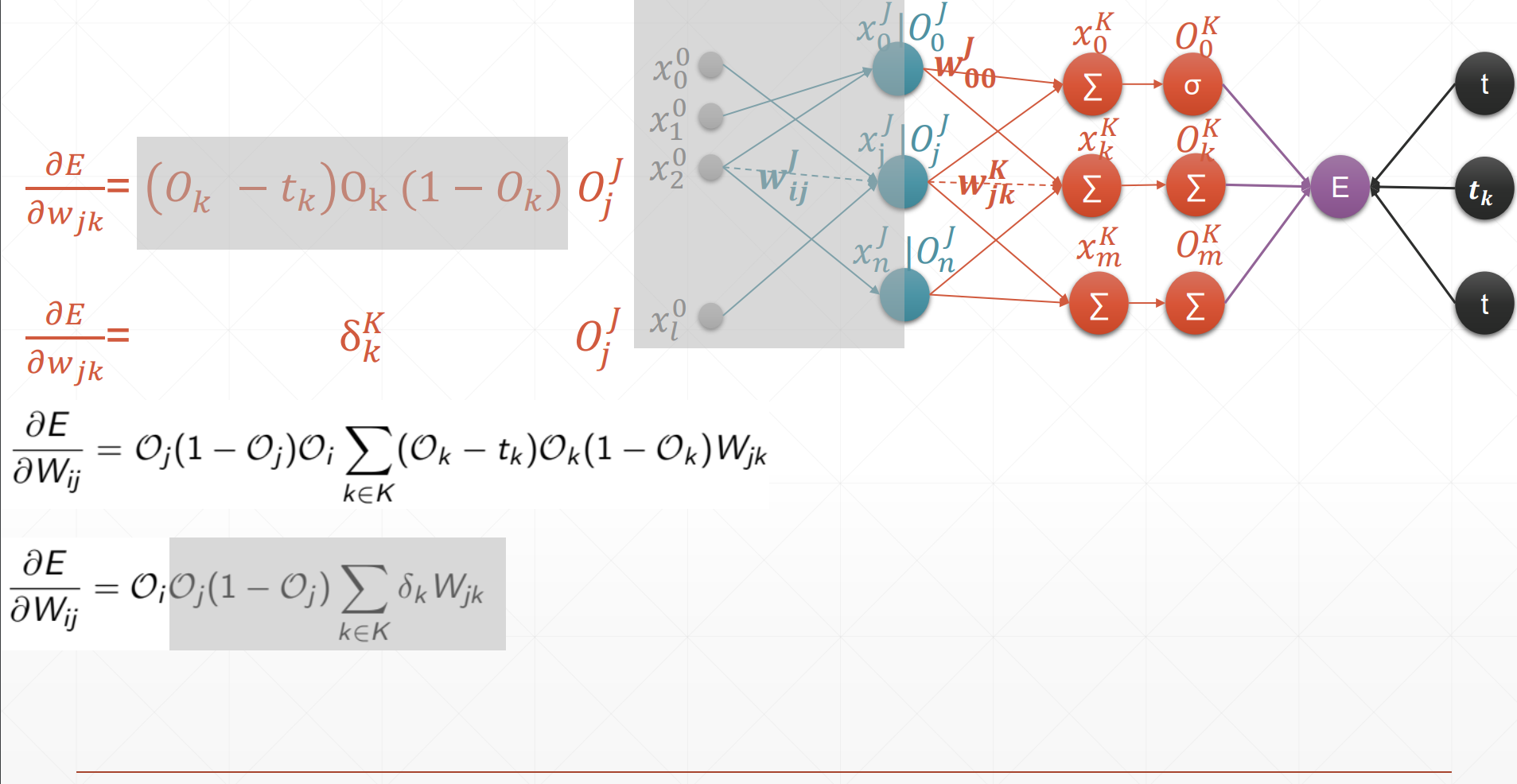
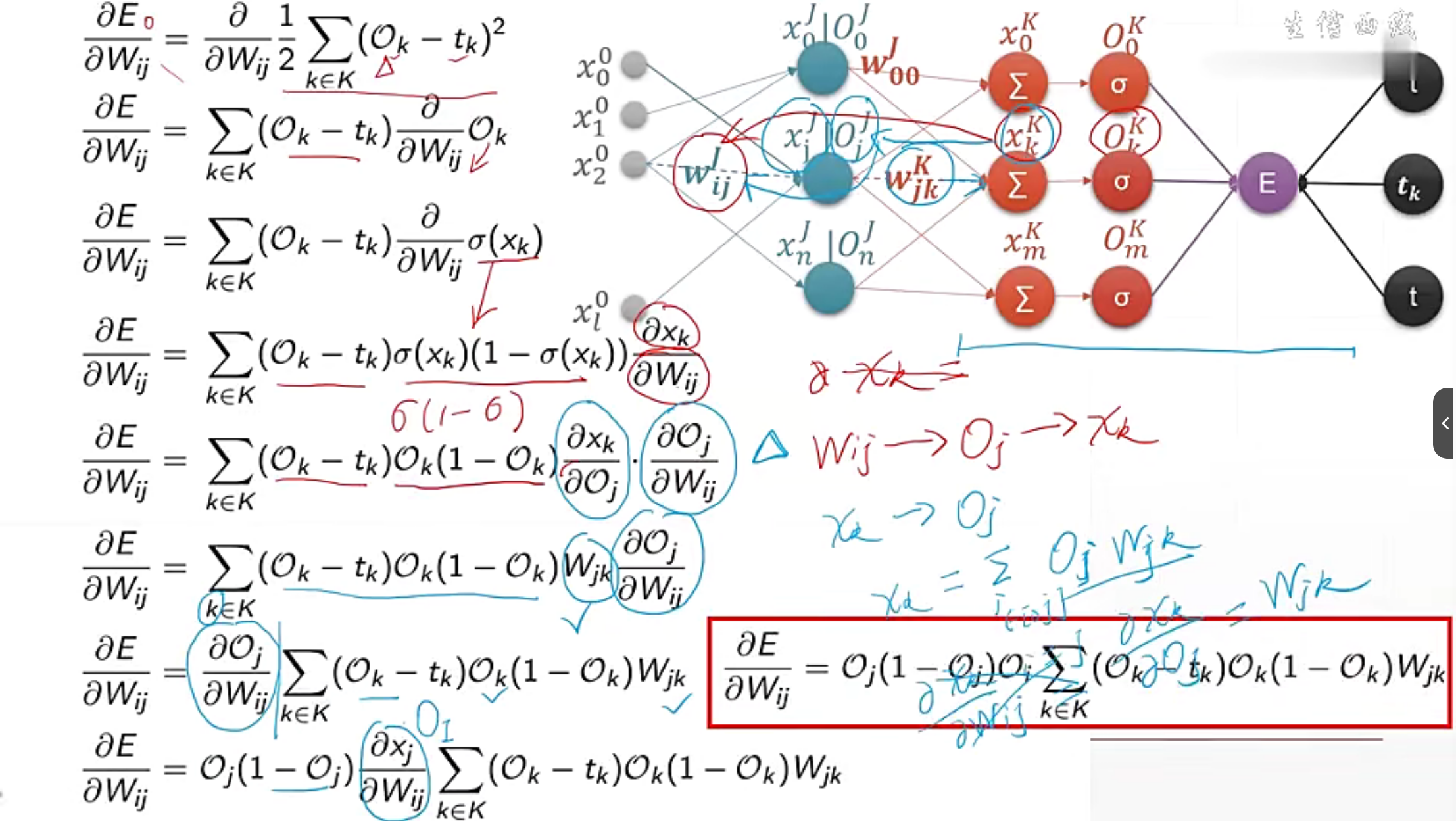
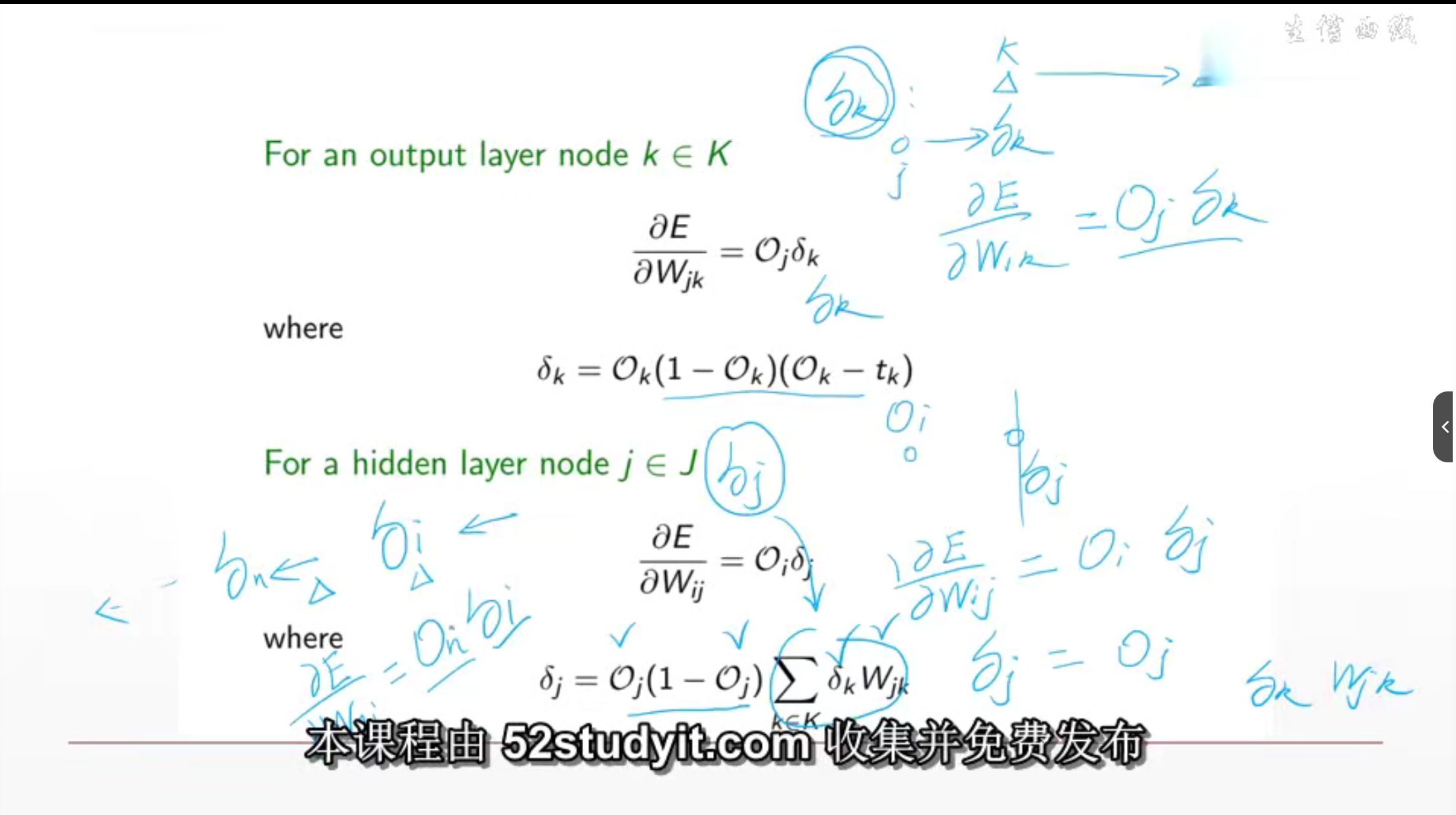
MLP反向传播推导过程
这是在求每个参数的反向传播的误差来更新参数。
lesson22 优化小实例
2D函数优化实例
view_init() 用于设置三维坐标轴的视角
x.tolist() 将numpy转为list列表 pred.item返回值而不是tensor
tensor.item() 返回一维张量的数值而非tensor类型。
eg: a = torch.tensor(1.234) a.item()是个数值。a是张量。
# 2D函数优化实例
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import pyplot as plt
import torchdef himmelblau(x):# f = (x^2 + y - 11)^2 + (x + y^2 - 7)^2return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2 # x[0]是x,x[1]是y# Plot
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print("x,y range:", x.shape, y.shape)
X, Y = np.meshgrid(x, y)
Z = himmelblau([X, Y])fig = plt.figure('himmelblau')
ax = fig.add_subplot(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30) # view_init() 用于设置三维坐标轴的视角
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()# 梯度下降法求
x = torch.tensor([-4., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3) # Adam优化器,学习率1e-3
for step in range(20000):pred = himmelblau(x)optimizer.zero_grad() # 梯度清零pred.backward() # 生成x[0], x[1]的梯度信息optimizer.step() # 更新参数信息if step % 2000 == 0:print(f"step={step}, x = {x.tolist()}, f(x) = {pred.item()} ") # x.tolist() 将numpy转为list列表 pred.item返回值而不是tensor
lesson24 logistic regression
逻辑回归,之前的叫法。现在是叫classification.
逻辑回归和分类的区别在于逻辑回归不能直接用accuracy当作Error。
如果使用MSE,做真实值和预测值之间的差使二者之间的值越来越小,则解读为regression问题
如果使用Cross Entropy, 则解读为classification。
lesson25 交叉熵
是用于衡量两个之间间隔的Loss。间隔的越小,交叉熵越小。间隔的越大,交叉熵越大。


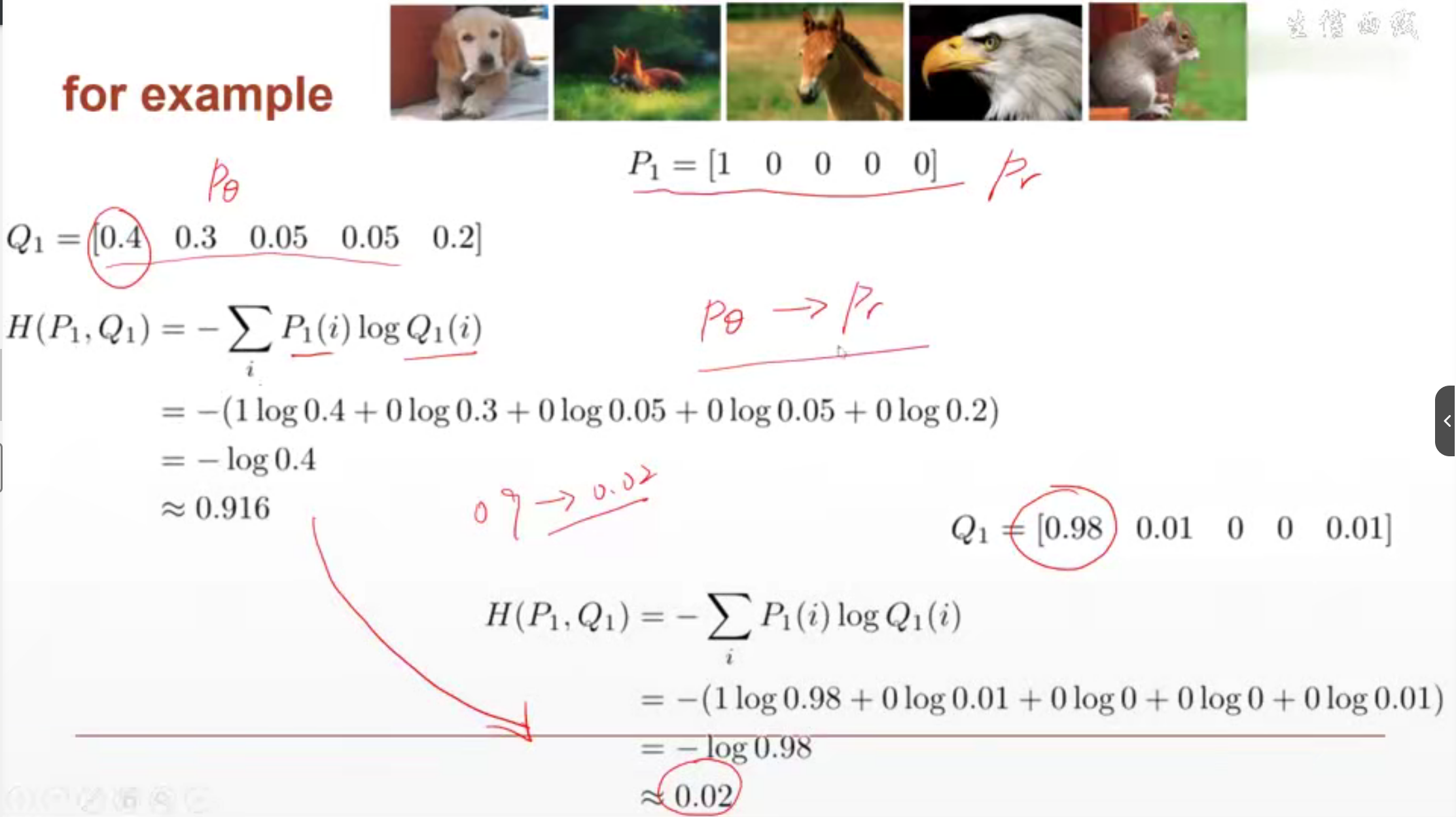
# practise
import torch
from torch.nn import functional as F# Cross Entropy = softmax + log + nll_loss
x = torch.randn(1, 784)
w = torch.randn(10, 784)
logits = x@w.t()pred = F.softmax(logits, dim=1)
pred_log = torch.log(pred)print(F.cross_entropy(logits, torch.tensor([3])))print(F.nll_loss(pred_log, torch.tensor([3]))) # 之前的softmax和log都做了,所以只需要nll_loss即可得到与上面一样的结果
lesson26 LR多分类问题实战
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsbatch_size = 200
learning_rate = 0.01
epochs = 10# 加载数据集
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)# 参数信息# 784是输入,200是输出 前后相反
w1, b1 = torch.randn(200, 784, requires_grad=True),\torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),\torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\torch.zeros(10, requires_grad=True)torch.nn.init.kaiming_normal_(w1) # 用于对张量进行Kaiming正态分布初始化
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)# 向前传播
def forward(x):x = x@w1.t() + b1x = F.relu(x)x = x@w2.t() + b2x = F.relu(x)x = x@w3.t() + b3x = F.relu(x)return xoptimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) # SGD: 随机梯度下降
criteon = nn.CrossEntropyLoss() # 交叉熵做lossfor eopch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)logits = forward(data) # 模型得到的预测值logitsloss = criteon(logits, target) # 真实值target和预测值logits之间的交叉熵损失函数optimizer.zero_grad() # 清零梯度 每次计算前都要清零梯度,不让梯度累计loss.backward() # 计算交叉熵损失函数对参数的梯度信息 (参数有w1 b1 w2 b2 w3 b3)optimizer.step() # 更新参数梯度信息if batch_idx % 100 == 0:print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}".format(eopch, batch_idx*len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28*28)logits = forward(data) # # 模型得到的预测值logitstest_loss += criteon(logits, target).item() # 测试误差累加交叉熵损失函数值pred = logits.data.max(1)[1] # logits.data 是获取 logits 张量的数据部分,即去除梯度信息,得到一个新的张量。# .max(1) 是对 logits.data 进行操作,这个操作会返回两个值:最大值和最大值所在的索引。[1] 表示选择返回最大值所在的索引。correct += pred.eq(target.data).sum() # 判断pred和target.data是否相等(eq),将相等的求和得到预测正确的数量。test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
lesson28 激活函数与GPU加速
# 使用GPU的code
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsbatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()# print(w1.grad.norm(), w2.grad.norm())optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item()"""logits是模型的输出,通常是一个包含每个类别的得分张量,通常是[batch_size, num_classes], 分别表示批量大小、类别数量logits.data是去除梯度信息只保留张量的数值数据。.max(1)用于在张量的指定维度上找到最大值。多分类问题的得分分布在第二个维度上。 为什么找最大值? 找最大值是每个预测结果都有个值,取最可能的就是取得分值最大的。[1]用于获取最大值的索引,即得分最高的类别的索引。"""pred = logits.data.max(1)[1]correct += pred.eq(target.data).sum()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))lesson29 MNIST
import torch
import torch.nn.functional as F# 计算Accuracy的流程
logits = torch.rand(4, 10)
print(logits)
pred = F.softmax(logits, dim=1)
pred_label = pred.argmax(dim=1)
print(pred_label)
print(logits.argmax(dim=1))
label = torch.tensor([9, 3, 2, 4]) # 真实值
correct = torch.eq(pred_label, label) # 这是一个类型为byte的tensor
print("Accuracy: {}".format(correct.sum().float().item() / 4)) # 先求和,再将byte转为float,再取值,再/4# MNIST测试集
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transformsbatch_size=200
learning_rate=0.01
epochs=10train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)loss = criteon(logits, target)optimizer.zero_grad()loss.backward()# print(w1.grad.norm(), w2.grad.norm())optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28 * 28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item()pred = logits.argmax(dim=1)correct += pred.eq(target).float().sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))lesson30 Visdom可视化
我真哭了 破代码!!!
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdombatch_size = 200
learning_rate = 0.01
epochs = 10# 导入数据
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),# transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, transform=transforms.Compose([transforms.ToTensor(),# transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)# print(len(train_loader)) # 返回的是批次数,即总样本数/batch_size
# print(len(train_loader.dataset)) # 返回总样本数# 创建多层感知机模型
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.model = nn.Sequential(nn.Linear(784, 200),nn.LeakyReLU(inplace=True), # inplace=True表示就地操作nn.Linear(200, 200),nn.LeakyReLU(inplace=True),nn.Linear(200, 10),nn.LeakyReLU(inplace=True),)# 重写了父类的方法def forward(self, x):x = self.model(x)return xdevice = torch.device('cuda:0') # 使用索引为0的设备
net = MLP().to(device) # 将MLP导入device上计算。
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device) # 将交叉熵Loss导入device上计算。# 创建visdom可视化
"""
viz.line: 创建一个折线图窗口
[0.] 指定初始x y轴的数据点
win='train_loss':指定窗口名称为train_loss。
opts 用于指定折线图选项。这里设置了标题为train loss"""
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',legend=['loss', 'acc.']))
global_step = 0 # 步长# 开始训练
for epoch in range(epochs):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)data, target = data.to(device), target.cuda() # 将图片数据和真实值挪到GPU(device)上进行运算logits = net(data) # 预测值 结果loss = criteon(logits, target) # 损失optimizer.zero_grad() # 清零梯度loss.backward() # 保留参数的梯度信息optimizer.step() # 根据参数的梯度信息以更新参数global_step += 1# 画折线。 纵坐标是loss的值。横坐标是步长viz.line([loss.item()], [global_step], win='train_loss', update='append') # 更新方式为在后面append# 输出if batch_idx % 100 == 0:print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}".format(epoch, batch_idx*len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))# 测试集上的数据test_loss = 0 # 测试集上的Losscorrect = 0 # 预测正确的个数for data, target in test_loader:data = data.view(-1, 28*28)data, target = data.to(device), target.cuda()logits = net(data)test_loss += criteon(logits, target).item() # 取item取值pred = logits.argmax(dim=1) # 0-9每个都可能预测到。取概率最大的就是取得分最高的。得到其下标就是该值。dim=1表示求第一个维度。correct += pred.eq(target).float().sum().item()viz.line([[test_loss, correct / len(test_loader.dataset)]],[global_step], win='test', update='append')viz.images(data.view(-1, 1, 28, 28), win='x') # images是可视化函数 用于显示图像诗句# detach是将张量从计算图中分离出来。.cpu是转到cpu上。.numpy是转为numpy格式。viz.text(str(pred.detach().cpu().numpy()), win='pred',opts=dict(title='pred'))test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))lesson32 Train-Val-Test-交叉验证
在训练集上训练更新参数θ。在验证集上看哪个时间戳是最好的,在哪个时间戳结束。测试集是测试模型效果的好坏
验证集是在原来的训练集中划分出来的。
pred = logits.data.max(1)[1] # max(1) 表示在第一个维度上找到最大值。[1]用于返回最大值的索引,[0]用于返回最大值的数值。lesson32 正则化


正则化是强制让权重weights变为0或趋近于0,降低模型的复杂度。
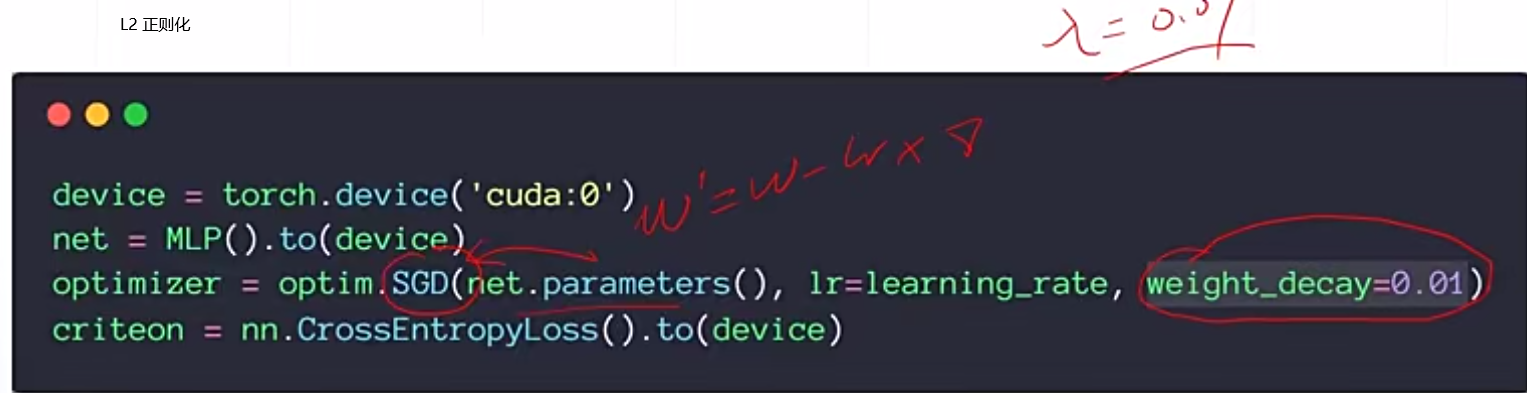

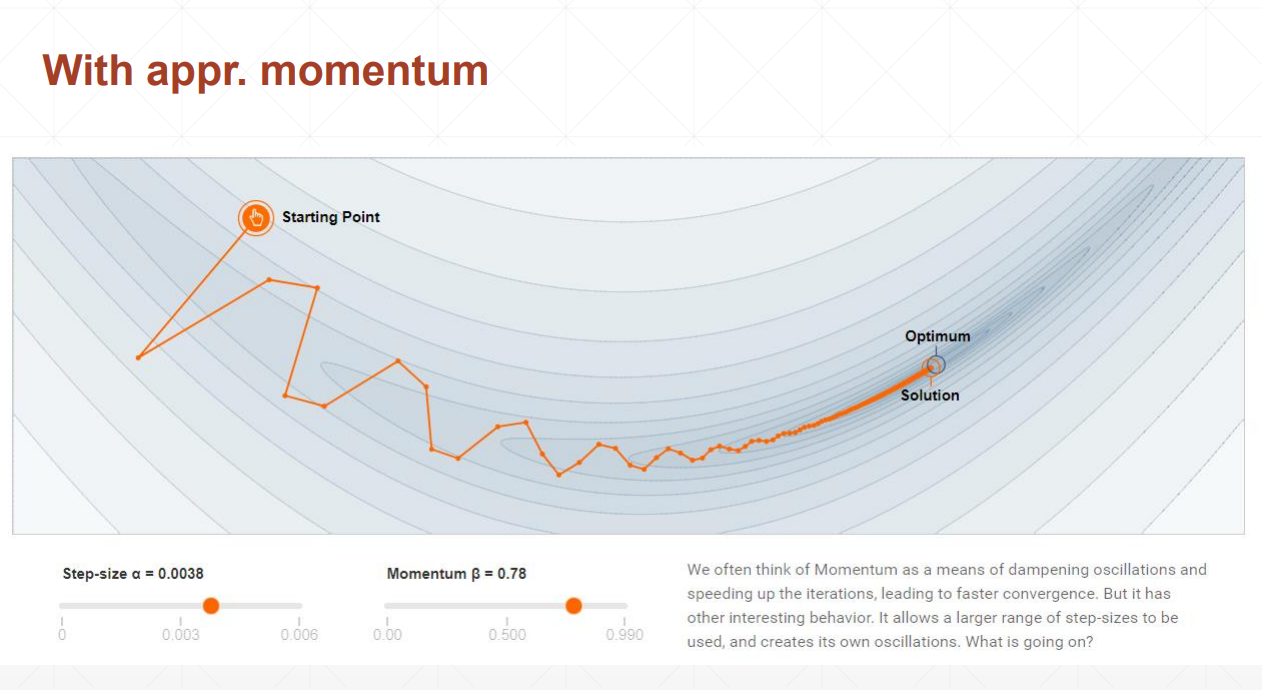
lesson34 动量和学习率衰减
动量理解为惯性。
没有动量,梯度变化很大,loss也变化的很大。
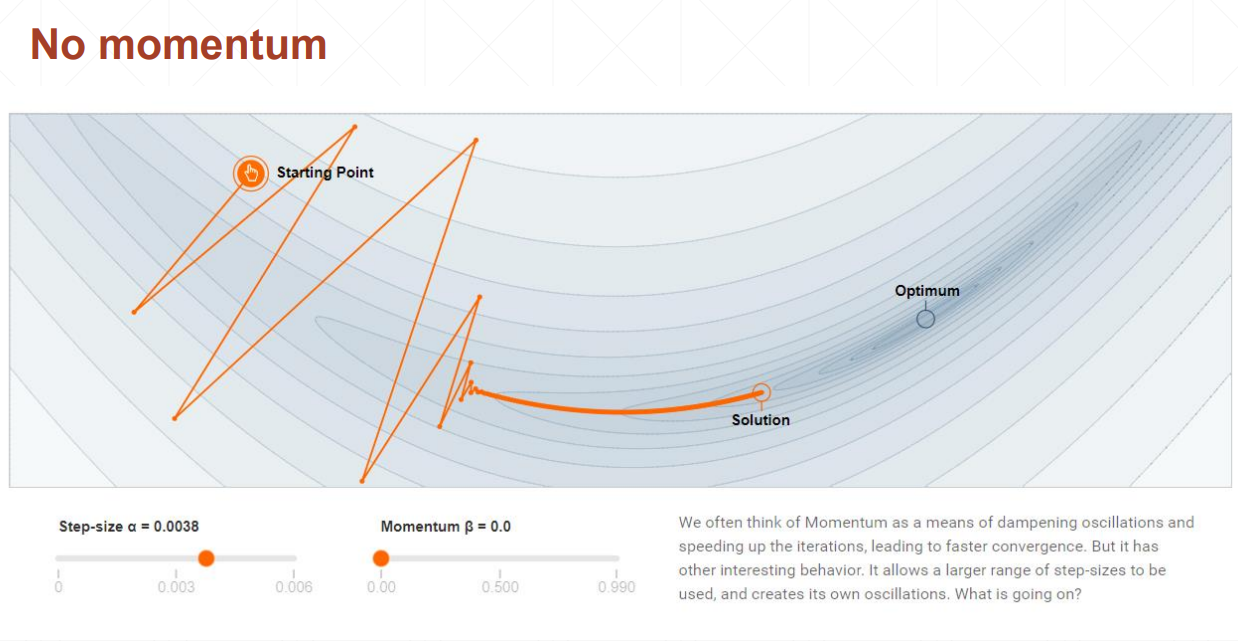
有动量,梯度变化会很小。
学习率
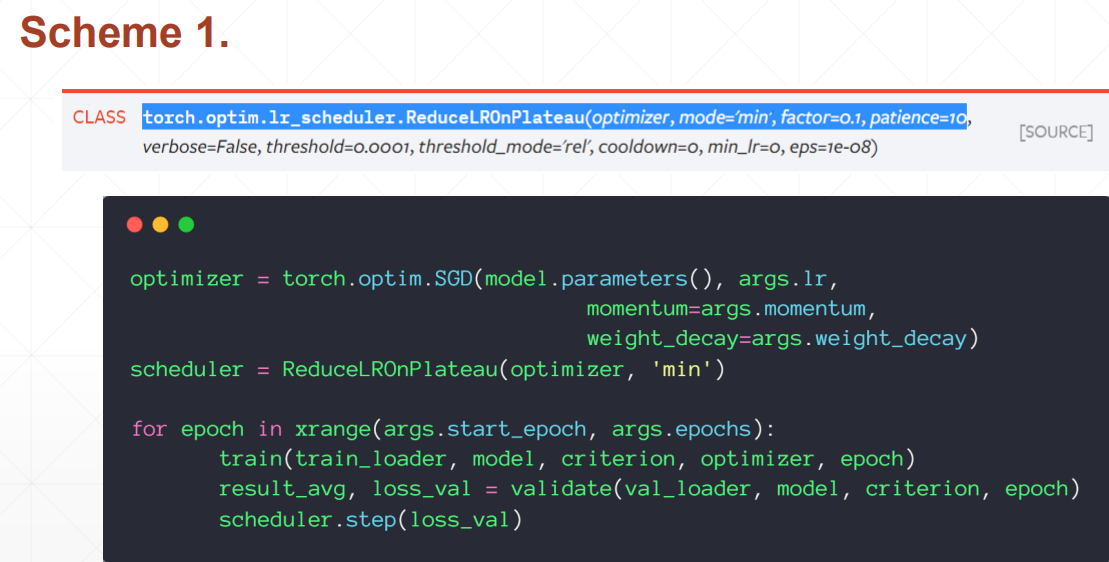
如果一段步骤内学习率没变,则设置学习率减半(ReduceLROnPlateau).
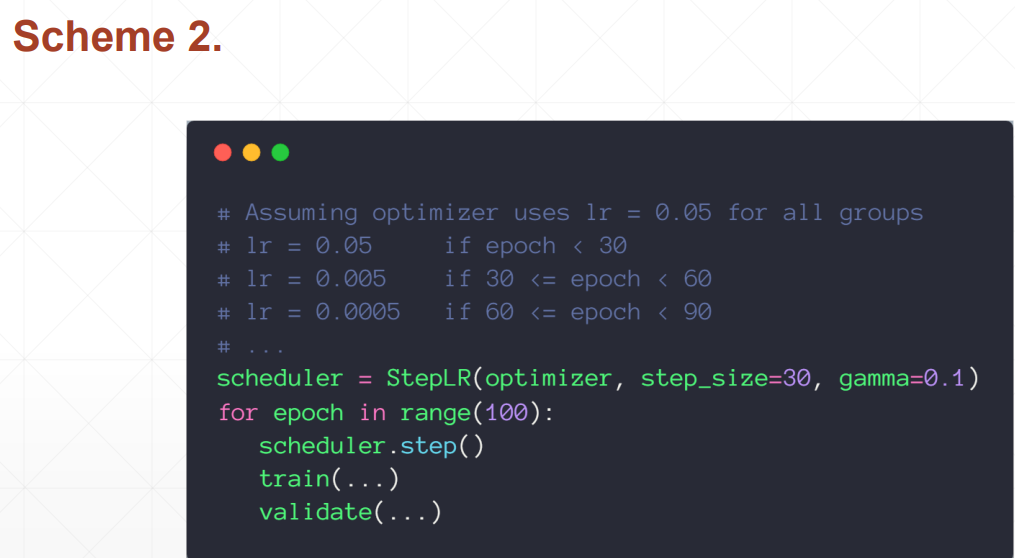
按照规定每走几步就让学习率变成多少。
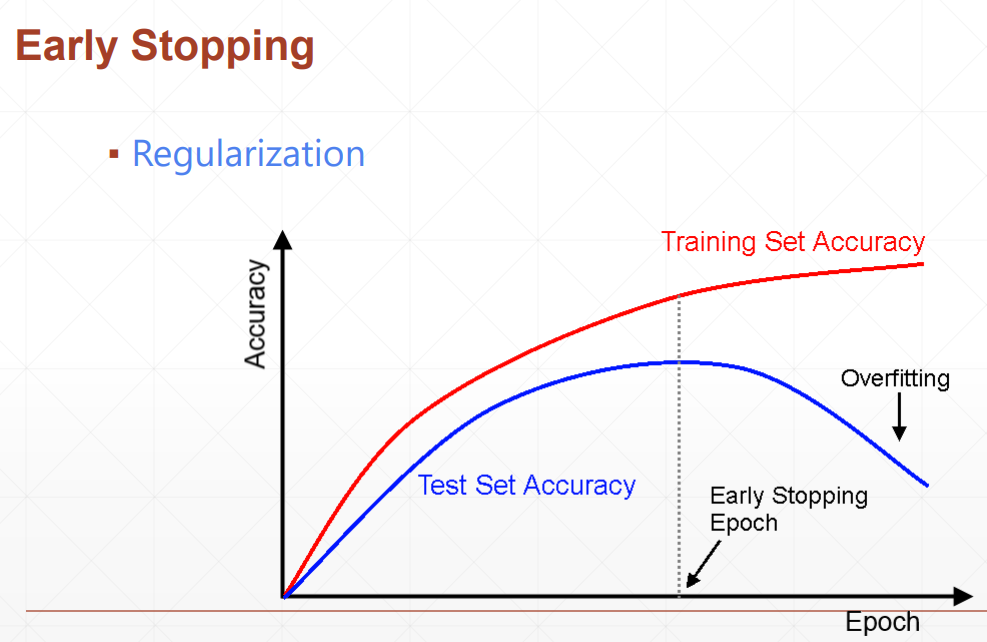
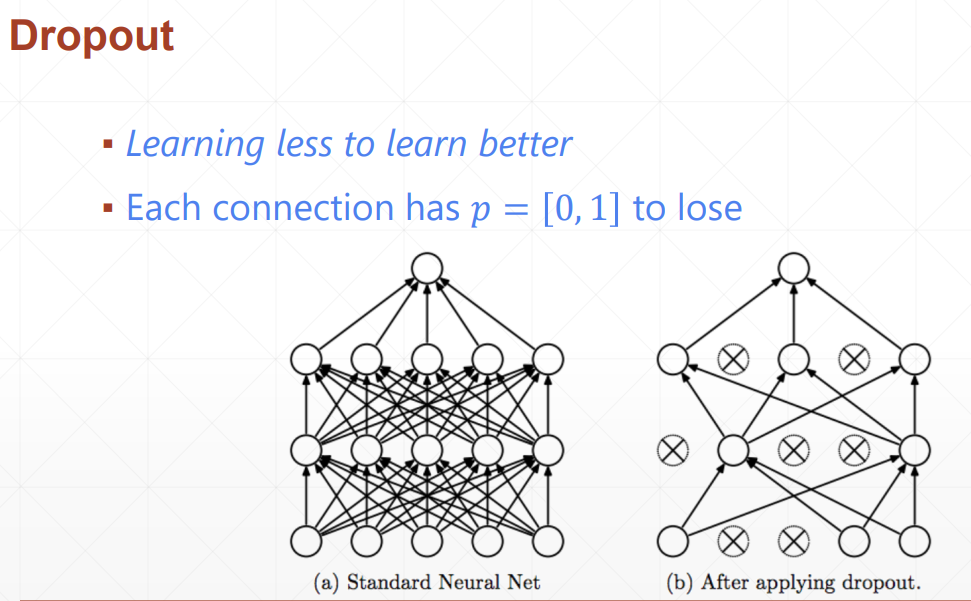
lesson35 early-stopping & dropout

dropout



net_dropped.eval() 是 PyTorch 中用于将神经网络模型切换到评估模式的方法。在评估模式下,模型的行为会发生一些变化,通常用于在不训练模型的情况下进行推断或测试。
当你调用 net_dropped.eval() 时,它会做以下事情:
批归一化层(Batch Normalization):在训练模式下,批归一化层会根据每个批次的统计信息进行批次归一化。但在评估模式下,它会使用固定的统计信息,通常是在训练集上计算的统计信息。这确保了评估模式下的一致性,不受输入数据的影响。
Dropout:如果在模型中使用了 Dropout 层,评估模式下 Dropout 不会丢弃任何神经元的输出。这是因为在测试或推断时,你通常不需要进行随机丢弃。
tensorflow的参数是保留结点的概率,Torch是删掉结点的概率!
梯度计算:评估模式下,PyTorch 不会计算梯度,因为你通常不会在评估模式下进行反向传播(即不会进行训练)。
通常,在训练完模型后,你会调用 model.eval() 来确保在执行推断或测试时模型处于一致的状态。这有助于确保模型在不同模式下的一致性行为。如果你希望恢复到训练模式,可以调用 model.train()。
Stochastic Gradient Descent
Stochastic Gradient Descent 是在一个batch中对参数进行求导。一般都是在一整个数据集上对参数进行求导。
随机梯度下降(Stochastic Gradient Descent,简称 SGD) 是机器学习和深度学习中最常用的优化算法之一,用于训练模型的权重以最小化损失函数。与传统的梯度下降算法不同,SGD 在每一步更新权重时都使用一小部分训练数据,而不是整个数据集。这使得它特别适用于大规模数据集和深度神经网络。
以下是 SGD 的主要特点和工作原理:
随机性:SGD 是随机的,因为它每次迭代都从训练数据中随机选择一小批样本来计算梯度。这种随机性有助于避免陷入局部极小值,并且使算法能够在训练过程中跳出局部最优解。
计算效率:由于 SGD 仅使用一小批数据进行梯度计算,因此它通常比使用整个数据集的批量梯度下降更快。这对于大规模数据集尤其重要。
学习率:SGD 使用一个称为学习率的超参数来控制每次权重更新的步长。较小的学习率会导致收敛较慢,但更稳定,而较大的学习率可能导致不稳定的训练。
随机梯度计算:在每次迭代中,SGD 计算损失函数相对于一小批数据的梯度,并使用该梯度来更新模型的权重。这个梯度计算是通过反向传播算法来完成的。
Mini-Batch:SGD 中的小批量数据通常被称为 mini-batch。mini-batch 的大小是一个重要的超参数,它影响到算法的性能和收敛速度。较小的 mini-batch 可能导致更多的随机性,但也会增加计算开销。
收敛性:SGD 不保证全局最优解,但通常能够收敛到一个合理的解决方案,特别是在使用适当的学习率调度策略时。
学习率调度:为了提高 SGD 的性能,可以使用学习率调度策略,即在训练过程中逐渐降低学习率的大小。
lesson38 卷积神经网络


import torch
from torch import nn
layer = nn.Conv2d(1, 3, kernel_size=3, stride=1, padding=1) # 1表示通道数,3表示卷积核数量
x = torch.rand(1, 1, 28, 28)
out = layer.forward(x) # 完成一次前向传播,即计算一次卷积结果
out = layer(x) # 推荐使用这个方法 完成一次前向传播,同时做pytorch自带的一些工作。
print(out)layer.weight # 权重,需要梯度信息
layer.weight.shape # 权重的shape
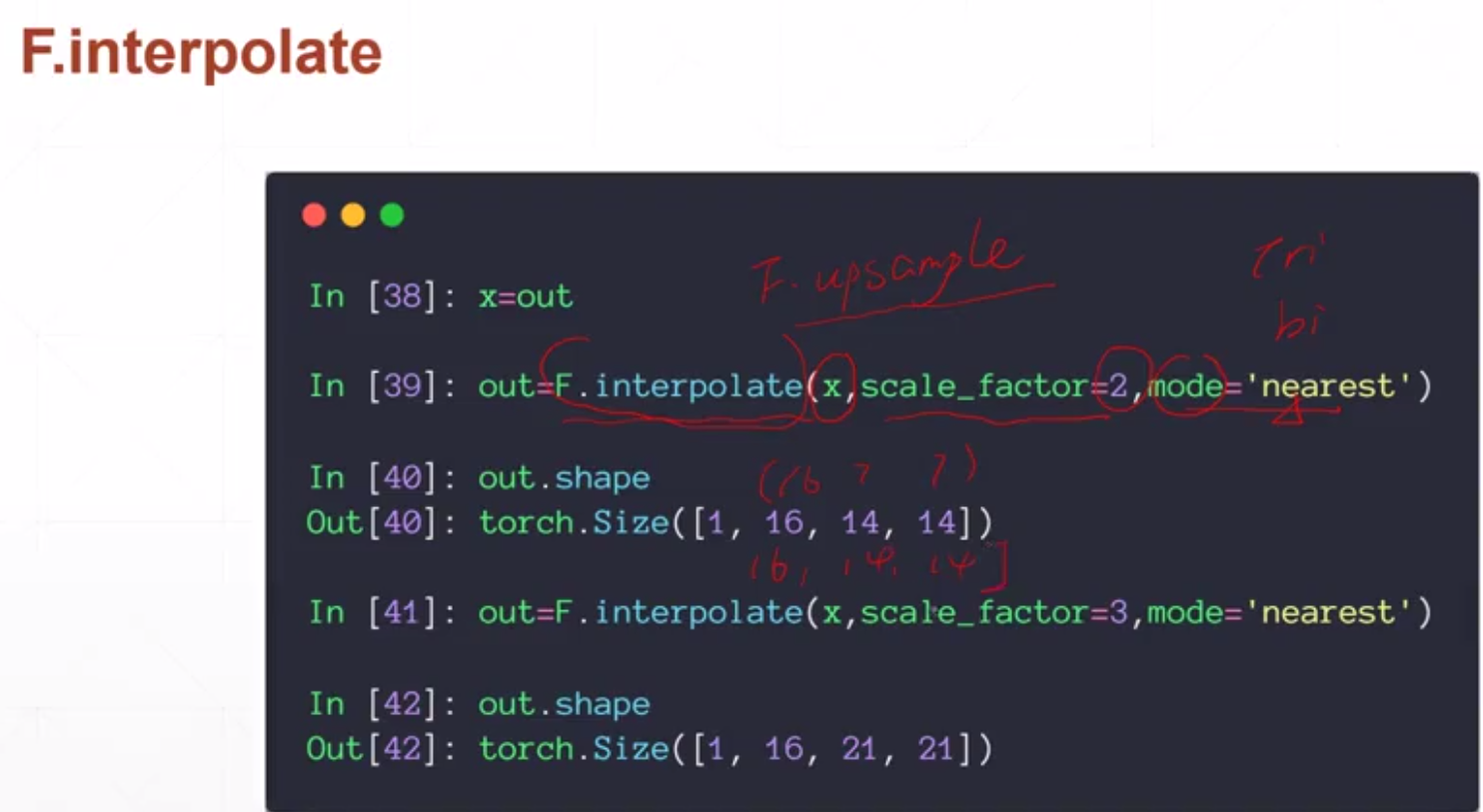
池化层和采样
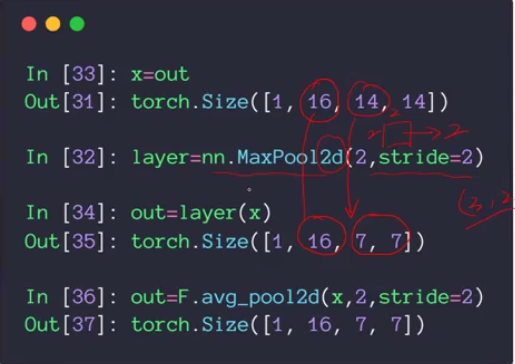
采样
Batch Normalization
为什么要使用批量归一化?
使用浅层模型时,随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。对深层神经网络来说,随着网络训练的进行,前一层参数的调整使得后一层输入数据的分布发生变化,各层在训练的过程中就需要不断的改变以适应学习这种新的数据分布。所以即使输入数据已做标准化,训练中模型参数的更新依然很容易导致后面层输入数据分布的变化,只要网络的前面几层发生微小的改变,那么后面几层就会被累积放大下去。最终造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。如果训练过程中,训练数据的分布一直在发生变化,那么将不仅会增大训练的复杂度,影响网络的训练速度而且增加了过拟合的风险。
nn.Moudle
# 常用的flatten操作
class Flatten(nn.Module):def __init__(self):super(Flatten, self).__init__()def forward(self, input):return input.view(input.size(0), -1)数据增强
train_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=True, download=True,transform=transforms.Compose([transforms.RandomHorizontalFlip(), # 水平翻转transforms.RandomVerticalFlip(), # 垂直反转transforms.RandomRotation(15), # 旋转,-15°~ 15°transforms.RandomRotation([90, 180, 270]), # 旋转transforms.Resize([32, 32]), # 裁切,变成大小为32*32transforms.RandomCrop([28, 28]), # 裁剪部分transforms.ToTensor(), # 转为tensor类型# transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)# 转到一个transform的list中,会对数据进行上面的操作。但是操作是随机的,并不一定会进行该操作。
经典神经网络
LeNet-5
AlexNet
RNN
RNN 跟传统神经网络最大的区别在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。
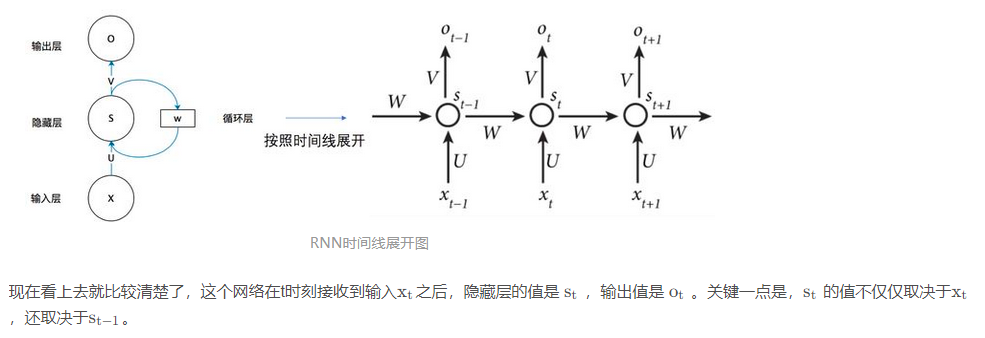
LSTM

如何理解Embeding
KL散度
相对熵可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零,当两个随机分布的差别增大
KL divergence和JSdivergence区别
其中,KL是非对称的度量,JS是对称的,W是对称的。另外,我们假设两个分布的“差异”是变量x(x>0),那么:
x越大,KL越大,且大到一定程度的时候,例如不交叉时,恒无意义(或理解恒为无穷大)。
x越大,JS越大,且大到一定程度的时候,例如不交叉时,不变,恒为log2。
x越大,w越大。