文章目录
- 缓冲区
- 什么是缓冲区?
- 缓冲区的意义是什么?
- 缓冲区的刷新方式
- 理解缓冲区
- 用户缓冲区和内核缓冲区
- 缓冲区在哪里?
本篇主要总结的是关于缓冲区的概念理解,以及再次基础上对文件的常用接口进行一定程度的封装
缓冲区
什么是缓冲区?
如何理解缓冲区?简单来说,缓冲区就是一段内存,用来存放一些信息,这就是对于缓冲区最初步的理解。那如何证明缓冲区的存在?用下面的代码来验证缓冲区
#include <stdio.h>
#include <unistd.h>void buffertest()
{printf("hello linux");sleep(3);
}int main()
{buffertest();return 0;
}

现象
运行结果如上所示,会先休眠三秒再输出结果,按程序的顺序结构来说,sleep一定是在printf之后执行的,也就意味着当执行到sleep的时候运行结果已经被写到了某个地方,只是还没有刷新到显示器上,因此用户看不见显示的内容,而当sleep执行完毕后,此时会把内容刷新到显示器上,这样就能看到运行的结果了
解释
而在执行了printf函数后其实就已经把内容输出了,输出的地方其实就是缓冲区中,只是还没有将信息存储到显示器这个文件内,因此没有输出结果,而当进程结束后,就会把缓冲区中的信息都刷新到显示器中,此时就实现了把信息打印到显示器上,所以才会看到,程序运行后没有输出结果,而是在执行完sleep后才会输出到显示器上
缓冲区的意义是什么?
如何理解缓冲区?有了这个缓冲区能干什么呢?答案是提高效率,对于这个答案其实并不陌生,在前面的学习中也存在有关于缓冲区的概念,只是对于缓冲区的认知程度比较低
举个例子来说,现在用户在上层使用C语言打印了很多信息,但是没有发出要刷新的需求,那么此时这些信息就都会存储在缓冲区中,而当缓冲区满了或者触发其他的刷新策略的时候,就会统一把缓冲区中的信息转移到内存中,再由内存进行其他后续的操作,在本文的后面会对这一整体的操作进行分析,此处只进行初步的描述
从外部把信息存储到内存中是需要成本的,而缓冲区的存在就是把这些信息积攒到一定程度再进行发送,既然设计出缓冲区的存在,那么就意味着把信息从缓冲区发送到内存中比直接把信息发送到内存中需要付出的成本低,这样可以提高运输的效率
缓冲区的刷新方式
缓冲区可以暂存数据,就意味着一定会有对应的刷新方式
- 无缓冲(立即刷新)
- 行缓冲(行刷新)
- 全缓冲(缓冲区满了才刷新)
一般而言是可以使用上面的刷新策略的,但是在实际的进程运行过程中可能会出现其他的意外情况,例如:
- 强制刷新
- 进程退出了,一般会刷新缓冲区
一般而言,对于显示器文件会采用的是行刷新策略,而对于磁盘上的文件会采用全缓冲的策略,对于这两种不同的刷新策略下一个模块就进行分析
理解缓冲区
下面来看这样的测试代码样例
void buffertest2()
{fprintf(stdout, "C:hello fprintf\n");printf("C:hello printf\n");fputs("C:hello fputs\n", stdout);const char* str = "system call: hello write\n";write(1, str, strlen(str));fork();
}
运行结果:
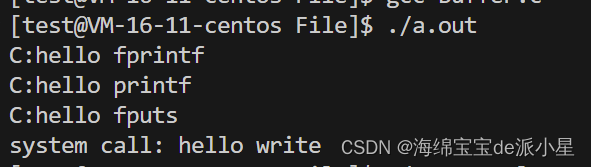
将运行结果输出到另外一个文件中
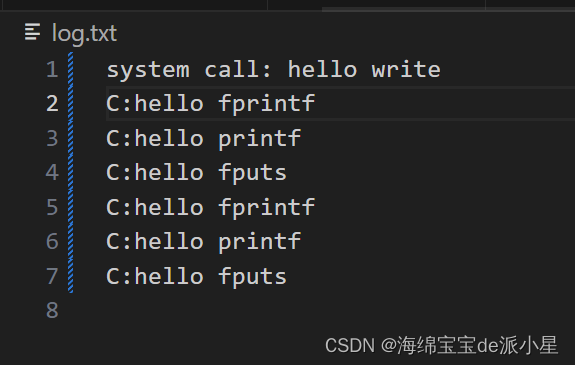
此时会发现有异常现象出现了,对于C语言的接口会打印输出两套,而对于系统调用的接口只会输出一套,那么这是为什么呢?为什么要在代码中进行fork的操作呢?fork的操作会带来怎样的影响?这两种现象出现的原因是什么呢?
对于上述现象的理解和解释
- 首先,对于上面的异常现象,要从出现异常的操作出发,为什么会出现异常?原因是一个是将内容直接执行,运行到显示器上,一个是把执行的结果输出到一个文件中,那么这两个操作会带来区别吗?答案是一定会的,原因就是前面提到的刷新方式的变换,对于显示器来说是行刷新策略,对于磁盘来说是全刷新策略,那么这就会带来不一样的结果,具体的原因后续分析
- 全缓冲意味着缓冲区会变大,实际写入的简单数据不会把缓冲区写满,因此在执行
fork操作的时候,数据依旧在缓冲区中,没有被刷新到文件中 - 在上述的代码中所使用到的缓冲区,全部都是
C语言的缓冲区,这个缓冲区是C语言本身给我们提供的,因此和操作系统内部提供的缓冲区是两种缓冲区,没有关系 - 那么问题来了,这和
fork有什么关系呢?fork会带来什么结果呢? - 那么现在就要思考的是,
fork会带来什么结果,根据前面的思想不难想到,fork带来的第一个直观的效果就是创建一个子进程,这是不需要质疑的事,而对于这个进程来说,fork结束后带来的另外一个结果就是结束进程,而结束进程带来的结果就是会刷新缓冲区,既然刷新缓冲区了,那么就会把这个进程所对应的缓冲区内容清空,那么下一个问题就是关于写时拷贝的问题,缓冲区清空算不算进程的数据发生改变了呢?如果算发生改变就会发生写时拷贝,如果不算改变就不会,那么下一个问题就是进程的数据在清空缓冲区的时候算不算发生了修改 - 要解决上面的这个问题,本质上是思考
C语言的缓冲区中的数据算不算进程运行时候的数据,因为写时拷贝的触发原理就是进程运行时候,父进程和子进程中只要有一个进程中的数据被修改,就会给另外一个进程发生写时拷贝,而这里的缓冲区的数据一定是属于进程运行时的数据的,而与此同时需要注意的是,当把数据已经交给操作系统之后,此时数据就是操作系统的,而不是进程本身的数据了,对于这样的数据即使发生修改也并不隶属于写时拷贝的范畴 - 那么分析到这里,其实对于上面的这个现象已经理解的很到位了,现在还有最后一个问题,为什么这个进程中对于使用系统调用的数据没有发生写时拷贝,难道这个不算是
C语言缓冲区的数据,以至于这个数据不算进程的数据就不会发生写时拷贝吗?答案是肯定的,这是因为缓冲区也有很多类,而除了系统调用外的其他写入的方式都是使用的是C语言自身所提供的一个缓冲区,因此在这样的基础下进行的数据是属于进程的数据的,而使用系统调用的接口使用的数据其实并不属于,它没有使用C语言缓冲区
总结
经过上面的这几条分析,其实已经把缓冲区的概念总结的算是比较到位了,刷新其实就是把C缓冲区的数据写入操作系统
用户缓冲区和内核缓冲区
什么是用户缓冲区,什么是内核缓冲区?
用户缓冲区
用户缓冲区其实就是平时日常的使用中提供的语言级别的缓冲区,在用户层面把信息进行写入,这样的级别就是用户缓冲区所做的事,作为用户上层,进行了一系列的各种写入,这些操作都是在给用户缓冲区中写入信息,而从用户缓冲区再向着操作系统写入信息这个过程,就是刷新,经过刷新就可以把信息写入操作系统,而在操作系统内部,又会有一套完整的文件系统,关于文件系统在上一篇文章中已经完整的描述过内部的过程,这里就不再详细叙述了
内核缓冲区
既然将内容从C语言写到操作系统中需要缓冲区,那么把读取的信息刷新到磁盘中是不是也是需要缓冲区的介入呢?答案是肯定的,这是一定会有的,而这其实也是刷新,把内核缓冲区的数据写到磁盘中,也是一种刷新,只不过刷新策略和前面的C缓冲区不太一样而已,这里就对内核缓冲区不再进行过多的介绍了,它本质和硬件设备相关更多一些
缓冲区在哪里?
那这个缓冲区在哪里呢?其实也是可以找到的,调用指令进行搜索:
whereis stdio.h
打开文件,寻找FILE有关的内容

那么下一步就是寻找这个结构体究竟在哪里
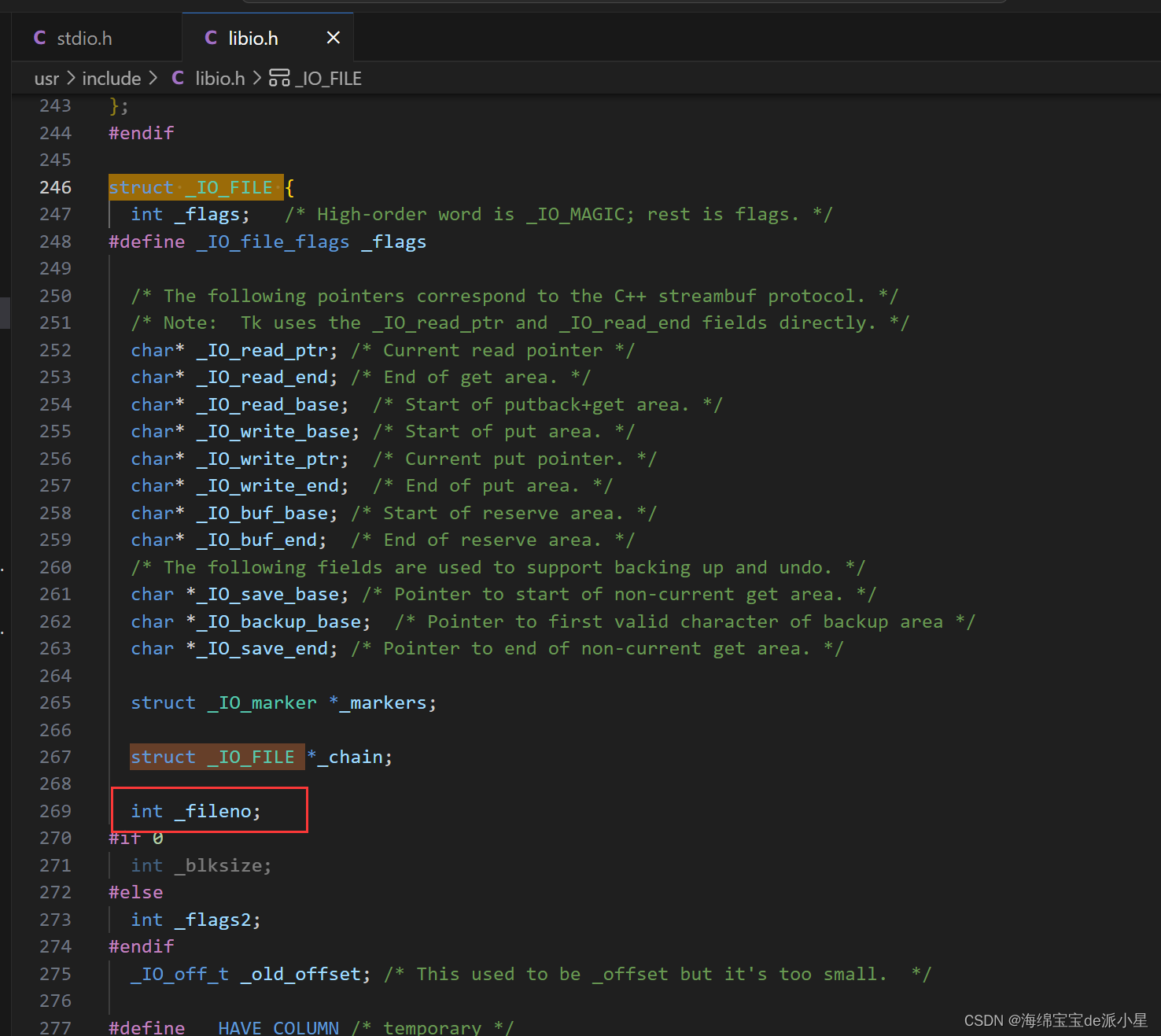
在这个libio.h文件中,寻找到了这个内容,而在进行输入和输出的时候,就会有一个FILE,而FILE本质上就是一个结构体,这个结构体叫FILE里面就包含了fd,这个FILE结构体就会提供一段缓冲区